【译】可扩展前端3 — 状态层
目录
引子
继 Scalable Frontend 2 — Common Patterns 第三篇,继续翻译记录。
原文:Scalable Frontend #3 — The State Layer
正文

状态树,实际上就是单一来源
在处理用户界面时,无论我们使用的应用程序的规模有多大,必须要管理显示给用户或由用户更改的状态。来源可能是从 API 获取的列表、从用户的输入获得、来自本地存储的数据等等。不管这些数据来自何处,我们都必须对其进行处理,并使用持久化方法使其保持同步,无论是远程服务器还是浏览器存储。
准确地说,这就是我们所说的 本地状态 (local state),我们应用程序使用和依赖的特定的一部分数据。有很多原因可以解释为什么、何时、何地更新和使用状态,如果我们不恰当地管理它,它可能很快失控。即使是一张简单的报名表单,也可能需要处理很多状态:
- 当用户与字段交互时,检查是否填写了有效数据;
- 跳过未触及字段的验证,直到表单提交;
- 当下拉选择一个国家时,触发获取该国家下州的请求,然后缓存响应;
- 根据所选国家,更改语言下拉可选项。
噢!听起来很棘手,对吧?
在本文中,我们将讨论如何以合理的方式管理本地状态,始终牢记代码库的可扩展性和架构设计原则,以避免状态层和其它层之间的耦合。应用程序的其余部分不应该知道状态层或正在使用的库,如果有的话。我们只需要告诉视图层如何从状态中获取数据,以及如何分发 actions ,它们将调用组成我们应用程序行为的用例。
在过去的几年中,JavaScript 社区中出现了许多用于管理本地状态的库,这些库以前主要由双向数据绑定竞争者控制,例如 Backbone、Ember 和 Angular 。直到随着 Flux 和 React 的出现,单向数据流才变得流行起来,人们意识到 MVC 对于前端应用程序并不很适用。随着在前端开发中大量采用函数式编程技术,我们可以理解为什么像 Redux 这样的库如此流行并影响了整整一代的状态管理库。
如果你想要更多了解这个主题,这里有个很好的关于 Flux 思维模式的演示。
现在,有好几个流行的状态管理库,其中一些特定于某些生态系统,比如 NgRx 是用于 Angular 。为了熟悉起见,我们将使用 Redux ,但是本文中提到的所有概念适用于所有的库,甚至没有库的情况。记住这一点,你应该使用最适合你和你的团队的方案。不要因为一个库到处有宣传,使用它就感到有压力。如果对你适用,那就去用吧。
公民:actions、action 创建者、reducers 和 store
在现代前端应用程序的状态管理中,我们会发现这四个是最常见的对象类型。用 actions 将事件从副作用的影响中分离出来的想法并不新鲜。事实上,这些公民都是基于成熟的想法,例如 event sourcing、CQRS 和 mediator 设计模式。
它们共同运作的方式是,通过集中存储和更改状态的方式,限制在一个地方并分发 actions(又称事件)来触发状态更改。一旦更改应用于状态,我们会通知对其感兴趣的部分,它们会更新自己以反映新的状态。这是单向数据流循环。
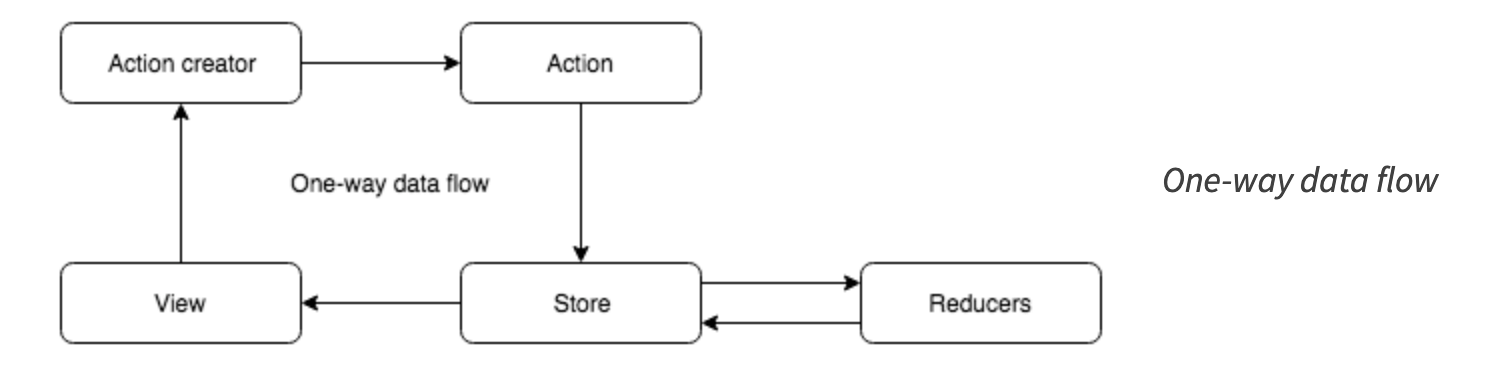
循环
Actions and action 创建者
Actions 通常被实现为具有两个属性的对象:type 属性和传递给 store 执行对应操作的数据 data 。例如,触发创建用户的 action 可能是以下格式:
{
type: 'CREATE_USER',
userData: { name: 'Aragorn', birthday: '03/01/2931' }
}
需要注意的是,type 属性的实现因所使用的状态管理库而异,但大多数情况下它都是一个字符串。另外,请记住,示例中的 action 本身并不创建用户;它只是一条消息,告诉 store 使用 userData 创建用户。
Action 创建者是把创建 action 对象抽象为一个可复用单元的函数
但是,如果我们需要从代码中的多个位置触发相同的 action ,比如测试套件或另一个文件,该怎么办?我们如何使其可重用,并对分发它的单元隐藏 action 类型?我们使用 action 创建者!Action 创建者是把创建 action 对象抽象为一个可复用单元的函数。我们前面的示例可以由下面的 action 创建者封装:
const createUser = (userData) => ({
type: 'CREATE_USER',
userData
});
现在,每当我们需要分发 CREATE_USER 的 action 时,我们导入这个函数并使用它来创建将分发到我们 store 的 action 对象。
Store
store 是我们真实状态的唯一来源,是我们存储和修改状态的唯一的地方。每次更改状态时,我们都会向 store 分发一个 action ,描述想要执行的更改,并在需要时提供额外的信息(分别对应示例中的 type 和 userData)。这意味着我们永远不应该在同一位置使用和更改状态,而是让 store 来更新状态。在这种模式的大多数实现中,我们都会 订阅 ,当 store 执行变更时会得到相应通知,以便对更改做出反应。
store 是我们真实状态的唯一来源。
好了,现在我们知道 store 可以用于两个主要目的:分发 actions 和向订阅者触发事件。在 React 应用程序中,通常用 Redux 创建 store ,使用 react-redux’ connect 分发 actions(mapDispatchToProps)和监听变更(mapStateToProps)。但我们也可以用一个根组件,使用 Context API 来存储状态,相应的使用 Context.Consumer 来分发 actions 和监听变更。或者我们可以用一个更简单的方式:状态提升。对于 Vue ,有一个跟 Redux 很类似的库 Vuex ,我们使用 dispatch 触发 actions ,用 mapState 来监听 store 。同样的,我们可以用 @ngrx/store 在 Angular 应用程序中做同样的事情。
尽管存在差异,但所有这些库都有一个共同的理念:单向循环。每次需要更新状态时,我们都会将 actions 发送到 store ,然后进行执行并通知监听者。千万不要回头或跳过这些步骤。
Reducers
但 store 如何更新状态并处理每个 action 类型?这就是 reducers 派上用场的地方。老实说,它们并不总是被称为“reducers”,例如,在 Vuex 中,它们被称为“mutations”。但中心思想是一样的:一个获取应用程序当前状态和正在处理的 action ,返回一个全新的状态,或者使用设置器对当前状态进行修改的函数。store 将更新委托给此函数,然后将新状态通知给监听者。这就结束了循环!
每个 reducer 都应该能够处理我们应用中的任何 action 。
在结束这部分之前,有一条非常重要的规则需要强调:每个 reducer 都应该能够处理我们应用中的任何 action 。换句话说,一个 action 可以同时由多个 reducer 处理。因此,这条规则允许单个 action 在状态的不同部分触发多个更改。这里有个很好的例子:在一个 AJAX 请求完成后,我们可以在 reducer X 中的根据响应更新本地状态,在 reducer Y 中隐藏提示器,甚至在 reducer Z 中显示一条成功的消息,其中每个 reducer 都有更新状态不同部分的单一责任。
状态设计
当我们开始编写应用程序时,总会想到一些问题:
- 状态应该是什么样的?
- 应该放什么进去?
- 应该有什么样的形态?
这些问题恐怕没有正确的答案。我们唯一有把握的是一些特定于库的规则,这些规则规定了如何更新状态。例如,在 Redux 中,reducer 函数应该是单一确定的,并且具有 (state,action) => state 签名。
也就是说,我们可以遵循一些实践来摆脱复杂性并提高 UI 性能,其中的一些是通用的,适用于我们选择的任何状态管理技术。其它的一些则适用于像 Redux 这样的特定的工具,与具有很强函数特性的辅助函数结合,用来分解 reducer 逻辑。
在深入研究之前,我建议你先查看你用来管理状态的库的文档。在大多数情况下,你会发现你不知道的高级技术和辅助方法,甚至本篇文章中没有介绍,但更适用你正在使用的状态管理方案的概念。除此之外,你可以查看第三方库,或者自己构建函数来实现这一点。
状态形态
状态指的是我们需要管理的数据,形态指的是我们如何构造和组织这些数据。形态与数据源无关,但与我们如何构造 reducer 逻辑密切有关。
通常,这个形态是用一个普通的 JavaScript 对象表示,它形成了初始状态树,但也可以使用任何其它值,比如纯数字、数组或字符串。对象的优点是允许将状态组织和划分为有意义的片段,其中根对象的每个键都一个子树,可以表示公共或部分数据。在包含文章和作者的基本博客应用程序中,状态的形态可能如下所示:
{
articles: [
{
id: 1,
title: 'Managing all state in one reducer',
author: {
id: 1,
name: 'Iago Dahlem Lorensini',
email: 'iagodahlemlorensini@gmail.com'
},
},
{
id: 2,
title: 'Using combineReducers to manage reducer logic',
author: {
id: 2,
name: 'Talysson de Oliveira Cassiano',
email: 'talyssonoc@gmail.com'
},
},
{
id: 3,
title: 'Normalizing the state shape',
author: {
id: 1,
name: 'Iago Dahlem Lorensini',
email: 'iagodahlemlorensini@gmail.com'
},
},
],
}
请注意,articles 是状态的顶级键,它形成了一个代表相同概念数据的子树。我们在每篇文章中也都有一个嵌套的子树来表示作者。一般来说,我们应该避免嵌套数据,因为它增加了 reducer 的复杂性。
Redux 的这篇文档介绍了如何根据你的定义域层和应用程序状态,将数据类型构造到状态形态上。即使你没有使用 Redux ,也去看看!数据管理对于任何类型的应用程序来说都是司空见惯的,对于学习如何对数据进行分类并组织形成你的状态形态,那是一篇非常好的文章。
Reducers 合并
上一个示例的状态形态中只显示了一个键,但实际应用程序通常有多个定义域要表示,这意味着一个 reducer 函数中将有更多的更新逻辑。然而,这违背了一个重要的规则:reducer 函数应该精简且聚焦(单一责任原则),以便易于阅读、理解和维护。
在 Redux 中,我们可以通过内置的 combineReducers 函数实现这一点。这个函数接受一个对象,其中每个键表示状态的一个子树,并返回一个带有描述名称的组合 reducer 函数。让我们将 authors 和 articles 的 reducer 合并到一个 rootReducer 中:
import { combineReducers } from 'redux'
const authorsReducer = (state, action) => newState
const articlesReducer = (state, action) => newState
const rootReducer = combineReducers({
authors: authorsReducer,
articles: articlesReducer,
})
传递给 combineReducer 的键将用于形成状态的最终形态,其数据将由与各自键相关联的 reducer 函数进行转换。因此,如果我们传递 authors 键和 authorsReducer 函数,rootReducer 返回的将是由 authorsReducer 函数管理的 state.authors 。
当我们更深入的拆分 reducer 函数时,合并 reducers 也很棒。假设 articlesReducer 需要处理这种情况:跟踪在获取文章的过程中发生的错误。所以现在我们状态中 articles 的键将不再是一个数组,而是一个如下的对象:
{
isLoading: false,
error: null,
list: [] // <- this is the array of articles itself
}
我们可以在 articlesReducer 内部处理这种新情况,但在同一个地方我们会有更多的声明要处理。幸运的是,这可以通过将 articlesReducer 分解成更小的部分来解决:
const isLoadingReducer = (state, action) => newState
const errorReducer = (state, action) => newState
const listReducer = (state, action) => newState
const articlesReducer = combineReducers({
isLoading: isLoadingReducer,
error: errorReducer,
list: listReducer,
})
除了 combinerReducers ,还有其它方法可以分解 reducer 逻辑,但我们将说明转交给 Redux 文档,文档对可复用技术例如高阶 reducer 、切片 reducer ,和减少样板代码的方法进行了很好的描述。请注意,这些方法也适用于 VueX 模块(本文将再次提及)和 NgRx 。
归一化(Normalization)
你注意到在我们的博客示例中,每篇文章都嵌套了一个作者吗?不幸的是,当一个作者关联多篇文章时,这会导致数据重复,这样使更新作者的行为成为一场噩梦,因为我们需要确保重复的作者数据也得到更新。更糟糕的是,由于不必要的重新渲染,性能会下降。
但有一个解决方案:我们可以像数据库那样归一化关联的数据。该技术关键在于为每个数据类型或定义域提供一个“表”,通过它们的 ID 引用关联的实体。Redux 建议如下:
- 把所有的实体保存在一个叫
byId的对象中,实体的 ID 作为键,实体作为值, - 一个称为
allIds的 ID 数组,表示实体的顺序。
在我们的示例中,在对数据进行标准化后,我们会得到如下结果:
{
articles: {
byId: {
'1': {
id: '1',
title: 'Managing all state in one reducer',
author: '1',
},
'2': {
id: '2',
title: 'Using combineReducers to manage reducer logic',
author: '2',
},
'3': {
id: '3',
title: 'Normalizing the state shape',
author: '1',
},
},
allIds: ['1', '2', '3'],
},
authors: {
byId: {
'1': {
id: '1',
name: 'Iago Dahlem Lorensini',
email: 'iagodahlemlorensini@gmail.com',
},
'2': {
id: '2',
name: 'Talysson de Oliveira Cassiano',
email: 'talyssonoc@gmail.com',
}
},
allIds: ['1', '2'],
},
}
这种结构更轻量。由于没有重复项,作者只在一个地方进行更新,因此触发的 UI 更新更少。我们的 reducer 更简单,对应项一致且便于查找。
开始归一化数据时一个常见问题是:
如何将这些数据的关联部分塑造成我们的状态?
虽然没有硬性规定,但通常将定义域的“表”放在名为 entities 的顶级对象中。在我们的文章示例中,将会是这样的:
{
currentUser: {},
entities: {
articles: {},
authors: {},
},
ui: {},
}
那么 API 发送的数据怎么处理?因为数据通常以嵌套格式返回,所以在存储到状态树之前需要对其进行归一化。我们可以使用 Normalizer 库来实现这一点,它允许根据定义模式类型和关系来返回归一化的数据。去查看他们的文档,了解更多关于它用法的详细信息。
对于使用较小应用程序或不想使用库的一些人,可以通过以下几个函数手动实现归一化:
replaceRelationById函数用嵌套对象的 ID 替换自身,extractRelation函数从主要实体中提取嵌套对象,byId函数按照 ID 对实体进行分组,allIds函数收集所有的 ID 。
所以让我们创建这些函数:
const replaceRelationById = (entities, relation, idKey = 'id') => entities.map(item => ({
...item,
[relation]: item[relation][idKey],
}))
const extractRelation = (entities, relation) => entities.map(entity => entity[relation])
const byId = (entities, idKey = 'id') => entities
.reduce((obj, entity) => ({
...obj,
[entity[idKey]]: entity,
}), {})
const allIds = (entities, idKey = 'id') => [...new Set(entities.map(entity => entity[idKey]))]
很简单,对吧?现在我们需要从相应的 reducer 中调用这些函数。让我们以第一篇文章的结构为例:
const articlesReducer = (state = initialState, action) => {
switch (action.type) {
case 'RECEIVE_DATA':
const articles = replaceRelationById(action.data, 'author')
return {
...state,
byId: byId(articles),
allIds: allIds(articles),
}
default:
return state
}
}
const authorsReducer = (state = initialState, action) => {
switch (action.type) {
case 'RECEIVE_DATA':
const authors = extractRelation(action.data, 'author')
return {
...state,
byId: byId(authors),
allIds: allIds(authors),
}
default:
return state
}
}
在 action 分发后,我们将对 articles 表中的 ID 进行了归一化,没有嵌套数据,authors 表也将被归一化,没有任何重复。
常见模式
在之前的文章中,我们讨论适用于定义域层、应用层、基础设施层和输入层的模式。现在让我们讨论一下保持状态层合理和易于理解的模式。它们中的一些只在特定的情况下使用。
选择器(Selectors)
有时我们需要的不仅仅是从状态中提取数据:我们可能需要通过过滤或分组来计算派生状态,以便在派生数据变化时重新渲染视图。例如,如果我们按已完成的项筛选 TODO 列表,如果未完成的项进行了更新,我们不需要重新渲染视图,对吧?另外,直接在用户端计算数据会使数据与其形态相耦合,如果我们需要重构状态,其副作用就是我们还需要更新用户端的代码。这正是我们用选择器可以避免的问题。
选择器顾名思义是选择与特定上下文相关数据的函数。它们接收整个状态的一部分作为参数,并按照使用者的期望进行计算。让我们回到以 React+Redux 为例的 TODO 列表。使用选择器前后的代码是什么样的?
/* view/todo/TodoList.js */
const TodoList = ({ todos, filter }) => (
<ul>
{
todos
.filter((todo) => todo.state === filter)
.map((todo) =>
<li key={todo.id}>{ todo.text }</li>
)
}
</ul>
);
const mapStateToProps = ({ todos, filter }) => ({
todos,
filter
});
export default connect(mapStateToProps)(TodoList);
/* state/todos.js */
import * as Todo from '../domain/todo';
export const getTodosByFilter = (todos, filter) => (
// notice that we isolate the domain rule into the domain/todo entity
// so if the shape of the todo object changes it will only affect our entity file, not here :)
todos.filter((todo) => Todo.hasState(todo, filter))
);
// ---------------------------------
/* view/todo/TodoList.js */
import { getTodosByFilter } from '../../state/todos';
const TodoList = ({ todos }) => (
<ul>
{
todos
.map((todo) =>
<li key={todo.id}>{ todo.text }</li>
)
}
</ul>
);
const mapStateToProps = ({ todos, filter }) => ({
todos: getTodosByFilter(todos, filter)
});
export default connect(mapStateToProps)(TodoList);
我们可以看到,重构后的组件不知道集合中存在什么类型的 TODO ,因为我们将此逻辑提取到一个名为 getTodosByFilter 的选择器中。这正是选择器的作用所在,所以当你注意到组件对你的状态了解得太多时,考虑下使用选择器。
当你注意到组件对你的状态了解得太多时,考虑下使用选择器。
选择器还为我们提供了利用一种称为 memoization 的性能改进技术的可能性,只要原始数据保持完整,就可以避免重新渲染和重新计算数据。在 Redux 中,我们可以使用 reselect 库来实现记忆化的选择器,你可以在 Redux 文档 中阅读相关信息。
如果你使用的是 Vuex ,已经有一种内置的选择器实现方法名为 getter 。你会发现 “getters”与 Redux 选择器的思维方式完全相同。NgRx 也有一个选择器功能,它甚至可以为你执行记忆化!
如果你想知道在哪里放置你的选择器,继续阅读,你很快就会发现!
鸭子/模块(Ducks/Modules)
我们说过架构与文件组织不是同一回事,但文件组织能反映架构这是很好的,还记得这句话吗?鸭子模式正是关于这一点:它遵循了 Common Closure Principe (CCP) 的定义,即:
一个包中的类应该是针对相同类型的变更。影响一个包的变更会影响包中所有的类。
— Robert Martin
一个鸭子(或模块)是一个聚集了属于同一功能特性的 reducer、actions、action 创建者和选择器的文件,这样如果我们需要添加或更改一个新的 action ,就只需要改动一个文件。
等等,这种模式是针对 Redux 应用程序的吗?当然不是!尽管 Ducks 这个名字的灵感来自 Redux 这个词,但是我们可以按照它的思维方式来使用任何我们想要的状态管理方法,即使不使用库。
对于 Redux 用户来说,这里有关于使用 ducks 方法的文档。对于 Vuex 应用程序,有一个叫做 modules 的东西,它基于相同的思想,但对 Vuex 来说更“原生”,因为它是核心 API 的一部分。如果你用 Angular 和 NgRx ,有一个基于 Ducks 的提议,叫做 NgRx Ducks 。
但有个缺陷。Ducks 方式建议我们在 duck 文件的顶部保留 action 名称,对吧?这可能不是最好的决策,因为这将使来自其它文件的 reducer 很难处理我们应用程序的 任何 action ,因为它们将被迫重写 action 的名称。我们可以为应用程序的所有 action 名创建一个单独的文件来避免这个问题,每个 duck 都可以导入和使用这个文件。此文件将按功能对 action 名称进行分组,并为每个 action 名指定导出。举个例子:
export const AUTH = {
SIGN_IN_REQUEST: 'SIGN_IN_REQUEST',
SIGN_IN_SUCCESS: 'SIGN_IN_SUCCESS',
SIGN_IN_ERROR: 'SIGN_IN_ERROR',
}
export const ARTICLE = {
LOAD_ARTICLE_REQUEST: 'LOAD_ARTICLE_REQUEST',
LOAD_ARTICLE_SUCCESS: 'LOAD_ARTICLE_SUCCESS',
LOAD_ARTICLE_ERROR: 'LOAD_ARTICLE_ERROR',
}
export const EDITOR = {
UPDATE_FIELD: 'UPDATE_FIELD',
ADD_TAG: 'ADD_TAG',
REMOVE_TAG: 'REMOVE_TAG',
RESET: 'RESET',
}
import { AUTH } from './actionTypes'
export const reducer = (state, action) => {
switch (action.type) {
// ...
case AUTH.SIGN_IN_SUCCESS: // <- same action for different reducers
return {
...state,
user: action.user,
}
// ...
}
}
import { AUTH } from './actionTypes'
export const reducer = (state, action) => {
switch (action.type) {
// ...
case AUTH.SIGN_IN_SUCCESS: // <- same action for different reducers
case AUTH.SIGN_IN_ERROR:
return {
...state,
showSpinner: false,
}
// ...
}
}
状态机(State Machines)
有时使用我们的状态变量来管理多个布尔值或多个条件,以找出应该渲染的内容,可能过于复杂。一个表单组件可能需要考虑多种可能性:
- 字段还没有被触碰,所以不要显示验证信息;
- 字段被触碰并且无效,因此显示验证信息;
- 字段没有被触碰,但提交按钮被点击了,所以显示验证信息;
- 字段是有效的,提交按钮被点击,所以显示提示器并禁用字段;
- 请求成功,因此隐藏提示器并显示确认信息;
- 请求失败,因此隐藏提示器,激活字段,并显示错误信息。
你能想象我们会用多少个布尔值吗?可能会产生类似这样的结果:
{
(isTouched || isSubmited) && !isValid && <ErrorMessage errors={errors} />
}
{
isValid && isSubmited && !errors && <Spinner />
}
当我们试图使用数据来定义应该呈现的内容时,我们通常会得到这样的代码,所以我们添加了一堆布尔变量,并试图以一种合理的方式来协调它们——结果证明是非常困难的。但是,如果我们试图把所有这些可能性归类为一些明确的、名副其实的状态呢?想想看,我们的接口将始终处于以下状态之一:
- Pristine
- Valid
- Invalid
- Submitting
- Successful
请注意,从任何给定的状态,都有我们无法转换到的状态。我们不能从“Invalid”转变到“Submitting”,但我们可以从“Invalid”转变到“Valid”,然后再转变到“Submitting”。
状态机的理念是定义一组可能的状态以及它们之间的转换。
这种情况用计算机科学的概念来解释更为合适,称为有限状态机,或是为这种情况专门创建的一种变体,称为状态图。状态机的理念是定义一组可能的状态以及它们之间的转换。
在我们的示例中,状态机将会是这个样子:
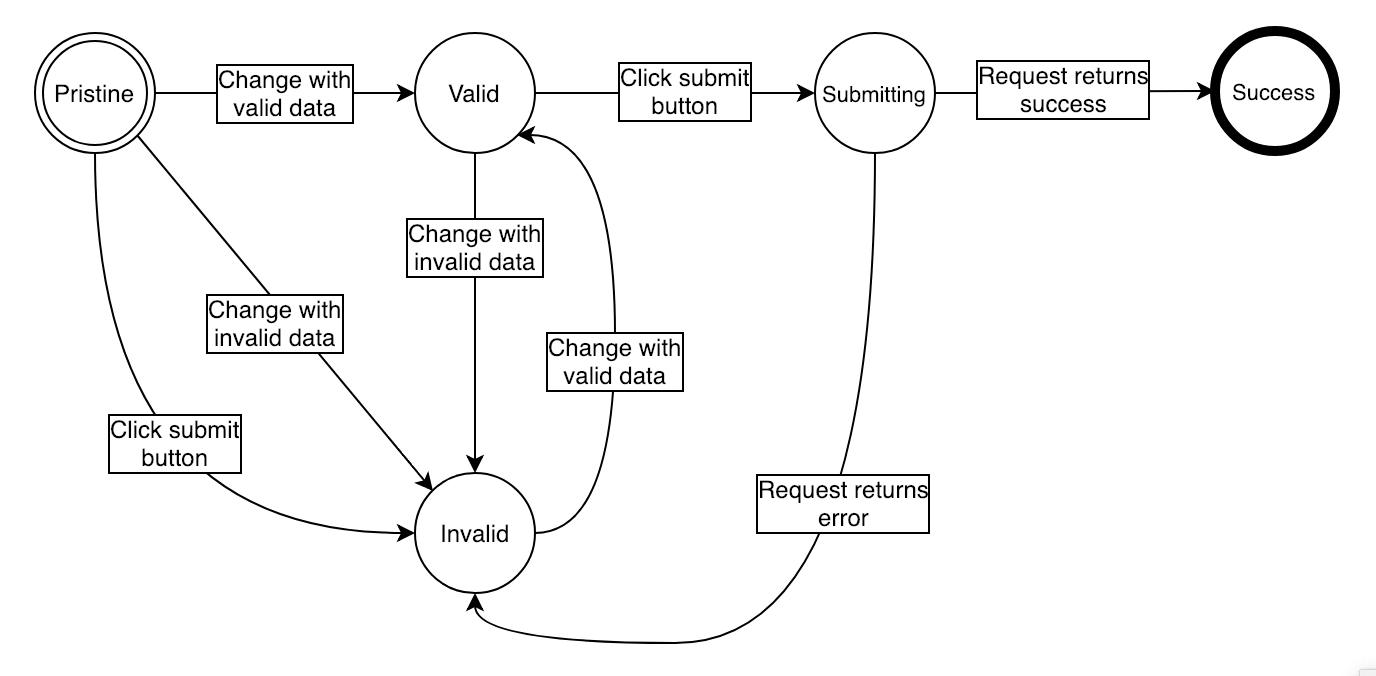
它看起来可能很复杂,但请注意,状态和转换的良好定义可以提高代码的清晰度,从而更容易以明确和简洁的方式添加新状态。现在我们的条件将只关心当前状态,我们将不再需要处理复杂的布尔表达式:
{
(currentState === States.INVALID) && <ErrorMessage errors={errors} />
}
{
(currentState === States.SUBMITTING) && <Spinner />
}
好了,那么我们如何在代码中实现状态机呢?首先要明白的是,它不必是一个复杂的实现。我们可以有一个表示当前状态名称的普通字符串,我们的 reducer 处理的每一个 action 更新该字符串。举个例子:
import Auth from '../domain/auth';
import { AUTH } from './actionTypes';
const States = {
PRISTINE: 'PRISTINE',
VALID: 'VALID',
INVALID: 'INVALID',
SUBMITTING: 'SUBMITTING',
SUCCESS: 'SUCCESS'
};
const initialState = {
currentState: States.PRISTINE,
data: {}
};
export const reducer = (state = initialState, action) => {
switch(action.type) {
case AUTH.UPDATE_AUTH_FIELD:
const newData = { ...state.data, ...action.data };
return {
...state,
// ...
data: newData,
currentState: Auth.isValid(newData) ? States.VALID : States.INVALID
};
case AUTH.SUBMIT_SIGN_IN:
if(state.currentState === States.INVALID) {
return state; // makes it impossible to submit if it's invalid
}
return {
...state,
// ...
currentState: States.SUBMITTING
};
case AUTH.SIGN_IN_SUCCESS:
return {
...state,
// ...
currentState: States.SUCCESS
};
}
return state;
};
但有时我们需要更大的具有更多状态和转换的状态机,或者出于其它原因我们只需要一个特定的工具。对于这些情况,我们可以使用类似 XState 的东西。请记住,状态机对状态管理是不可知的,因此无论使用 Redux、Context API、Vuex、NgRx,甚至没有库,我们都可以拥有它们!
如果你想了解更多,在这篇文章的最后有几个链接,提供了关于状态机和状态图的更多信息。
常见陷阱
即使遵循一个好的架构,在开发我们的前端应用程序时也有一些诱人的陷阱需要避免。我们说 诱人 是因为尽管它们看起来无害,但它们有很大的潜力最终导致反噬。我们来谈谈关于状态层的一些注意事项。
不要为不同的目的复用相同的异步操作
你还记得本系列的第一篇文章吗?当时我们谈到以后端应用程序中的控制器的方式处理 actions ,不在其中包含业务规则,并将工作委托给用例?让我们回到这个话题,但首先,让我们定义一下我们所说的“有副作用的 actions”是什么意思。
当某些操作的结果影响到本地环境之外的一些东西时,就会产生副作用。在我们的例子中,让我们考虑一个副作用,当一个 action 不仅仅是改变本地状态时,比如还发送一个 AJAX 请求或者将数据持久化到 LocalStorage 。如果我们的应用程序使用 Redux Thunk、Redux Saga、Vuex Actions、NgRx Effects ,甚至是执行请求的特殊类型的 action ,那就是我们所指的。
使 actions 类似于控制器的原因是它们都暗含了结果。它们执行整个用例和它们的副作用,这就是为什么我们不复用控制器,也不应该复用带有副作用的 action 。我们试图为不同的目的复用同一个 action 时,我们也会继承它的所有副作用,这是不可取的,因为它使代码更难理解。让我们用一个例子来简化一下。
想象一个 loadProducts action 通过 AJAX 加载一个产品列表,并在请求的过程中显示一个提示器(在我们的例子中将使用一个 Redux Thunk action):
const loadProductsAction = () => (dispatch, _, container) => {
dispatch(showSpinner());
container.loadProducts({
onSuccess: (products) => {
dispatch(receiveProducts(products));
dispatch(hideSpinner());
},
onError: (error) => {
dispatch(loadProductsError(error));
dispatch(hideSpinner());
}
});
};
好的,但是现在我们想不时地重新加载这个列表,使它始终保持最新,所以第一个念头就是复用这个操作,对吧?如果我们希望在后台进行更新而不显示提示器,该怎么办?有人可能会说,可以为此添加一个 withSpinner 标志,所以我们这样做:
const loadProductsAction = ({ withSpinner }) => (dispatch, _, container) => {
if(withSpinner) {
dispatch(showSpinner());
}
container.loadProducts({
onSuccess: (products) => {
dispatch(receiveProducts(products));
if(withSpinner) {
dispatch(hideSpinner());
}
},
onError: (error) => {
dispatch(loadProductsError(error));
if(withSpinner) {
dispatch(hideSpinner());
}
}
});
};
这已经变得很奇怪了,因为在使用标志时需要考虑一些复用,但是让我们暂时忽略它。
现在,如果我们希望为成功的情况触发另一个不同的 action ,我们应该怎么做?也将其作为参数传递?我们越是试图让一个 action 通用,它就越复杂,越不聚焦,你能发现这个吗?我们怎样才能解决这个问题,并且仍然复用这个 action ?最好的答案是:我们不用。
抵制复用有副作用 actions 的冲动。
对于这样的情况,抵制复用有副作用 actions 的冲动!它们的复杂性最终会变的难以忍受、难以理解和难以测试。相反,尝试创建两个利用相同用例的明确 actions :
const loadProductsAction = () => (dispatch, _, container) => {
dispatch(showSpinner());
container.loadProducts({
onSuccess: (products) => {
dispatch(receiveProducts(products));
dispatch(hideSpinner());
},
onError: (error) => {
dispatch(loadProductsError(error));
dispatch(hideSpinner());
}
});
};
const refreshProductsAction = () => (dispatch, _, container) => {
container.loadProducts({
onSuccess: (products) => {
dispatch(refreshProducts(products));
},
onError: (error) => {
dispatch(loadProductsError(error));
}
});
};
好极了!现在我们可以看到这两个 actions ,并确切地知道它们应该在什么时候使用。
注意,当一个有副作用的 action 使用另一个也有副作用的 action 时,同样也适用。我们不应该这样做,因为调用 action 将继承被调用 action 的所有副作用。
不要让你的视图依赖于 action 的返回
我们已经知道复用 actions 会使代码更难理解。现在想象一下,我们的组件依赖于这些 action 副作用的返回值。听起来不算太糟,对吧?
但这会使我们的代码更难理解。假设我们正在调试一个获取产品的 action 。调用这个 action 后,我们意识到已获取了此产品的评论列表,但我们不知道它来自何处,而且我们确定它不是来自 action 本身。现在变的越来越复杂了,不是吗?
// action
const loadProduct = (id) => (dispatch, _, container) => {
container.loadProduct({
onSuccess: (product) => dispatch(loadProductSuccess(product)),
onError: (error) => dispatch(loadProductError(error)),
})
}
// component
componentDidMount() {
const { productId, loadProduct, loadComments } = this.props
loadProduct(productId)
.then(() => loadComments(productId))
}
我们将 actions 当作控制器,但是我们会在后端应用程序中链式调用控制器吗?我不这么认为。
永远不要依赖 actions 返回的链式回调,也不要做任何其它类似的事情。如果应该在 action 调用完成后完成某些事情,则 action 本身应该处理它。
因此,作为第二条规则,永远不要依赖 actions 返回的链式回调,也不要做任何其它类似的事情。如果应该在 action 调用完成后完成某些事情,则 action 本身应该处理它——除非它是另一层的责任,比如重定向(这实际上是视图层的责任,我们将在本系列的下一篇文章中讨论),你的 actions 应该是应用程序的入口点,所以不要将重定向调用散布到所有组件上。
// action
const loadProduct = (id) => (dispatch, _, container) => {
container.loadProduct(id, {
onSuccess: (product, comments) => dispatch(loadProductSuccess(product, comments)),
onError: (error) => dispatch(loadProductError(error)),
})
}
// component
componentDidMount() {
const { productId, loadProduct } = this.props
loadProduct(productId)
}
不要存储计算数据
有时,我们需要将原始数据转换为人类可读的值,例如价格和日期。假设我们有一个产品模型,并收到类似于 {name:'product name',price:14.9} 的东西,其中包含一个普通数字形式的价格。现在我们的工作是在向用户展示之前格式化这些数据。
所以要记住,当一个值可以用一个纯函数(也就是说,给定相同的输入,我们总是得到相同的输出,)进行转换时,我们其实不需要将它存储到我们的状态中;我们可以在这个值将显示给用户的地方调用一个转换函数。在 React 视图中,它将像 <p>{formatPrice(product.price)}</p> 这样简单。
我们经常看到开发人员存储 formatPrice(product.price) 的返回值,这可能会导致缺陷。如果我们想要将此值发送回服务器,或者我们需要用它在前端进行计算,会发生什么情况?在这种情况下,我们需要将它转换回一个普通的数字,这是不理想的,不存储它可以完全避免这些。
有人可能会说,在渲染中多次调用函数可能会影响性能,但使用诸如记忆化之类的技术,我们会避免每次都对其进行处理。因此,性能不是不做的借口。可以使用 mem 这样的简单库,也可以将此函数调用抽象到一个组件中,像这样 <FormatPrice>{product.price}</FormatPrice> 并使用自带的 React.memo 函数。但请记住,只有当你的函数需要密集处理时,才需要记忆化。
接下来
这篇文章比预期的要长一点,但我们很高兴地说,这篇文章和上一篇文章一起,涵盖了我们用来开发可扩展前端应用程序的最常见模式。
当然,现代应用程序还有其它问题需要处理,如身份验证、错误处理和样式,这些将在以后的文章中讨论。在下一篇文章中,我们将讨论视图层和状态层之间的交互,以及在保持它们解耦的同时,如何使它们相互依赖,还有路由相关。再见!
推荐链接
- Rethinking Web App Development at Facebook
- Lift State Up
- Structuring Reducers
- Getting started with Redux
- Building React Applications with Idiomatic Redux
- Vuex Docs
- NgRx Docs
- Advanced Redux Patterns: Selectors
- Redux: Colocating Selectors with Reducers
- Robust React User Interfaces with Finite State Machines
- Redux modules and code-splitting
- Welcome to the world of Statecharts
- Decomposing the TodoMVC app with state diagrams
- Writing tests for Redux
- Writing tests for VueX
- Writing tests for NgRx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号