CentOS7搭建Hadoop-3.3.0集群手记
前提
这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记。
基本概念
Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这里为了简化搭建集群的流程,这里使用一主多从的架构。Hadoop集群中各个角色的名称如下:
| 服务 | 主节点 | 从节点 |
|---|---|---|
HDFS |
NameNode |
DataNode |
YARN |
ResourceManager |
NodeManager |
还有SecondaryNameNode,其实是NameNode的备用节点,定时合并和处理日志并且反馈到NameNode上。一般NameNode和SecondaryNameNode尽量不要放在同一个节点。
HDFS服务和YARN其实是分离的,一者是数据存储,另一者是资源调度,Hadoop集群可以只启用YARN集群做资源调度。
测试集群服务器规划
测试的Hadoop集群使用了3台基于VirtualBox搭建的CentOS7虚拟机:
| 内网IP | 主机名 | 用户 | 虚拟磁盘空间 | HDFS角色 | YARN角色 |
|---|---|---|---|---|---|
192.168.56.200 |
hadoop01 |
hadoop |
30GB |
NameNode、DataNode |
NodeManager |
192.168.56.201 |
hadoop02 |
hadoop |
30GB |
DataNode |
NodeManager |
192.168.56.202 |
hadoop03 |
hadoop |
30GB |
SecondaryNameNode、DataNode |
ResourceManager、NodeManager |
前置软件安装或者准备工作
主要包括必要的软件安装、用户创建和网络配置等等。
关闭防火墙
为了避免出现部分端口无法访问,内网环境下每台虚拟机都可以直接关闭防火墙:
# 停止防火墙进程
systemctl stop firewalld.service
# 禁用防火墙开机启动
systemctl disable firewalld.service
JDK安装
JDK的安装比较简单,这里过程略过。笔者使用的JDK是OpenJDK,版本是1.8.0_252-b09,JDK路径配置如下:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
export PATH=$JAVA_HOME/bin:$PATH
确保集群所有机器的JDK安装位置相同,并且JDK版本尽可能大版本选择8,经过大量测试发现Hadoop暂时不兼容JDK9+。
[root@localhost]# java -version
openjdk version "1.8.0_252"
OpenJDK Runtime Environment (build 1.8.0_252-b09)
OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode)
这个JDK安装位置和安装包名称是不是看起来比较奇怪?没错,是笔者偷懒用yum直接安装的OpenJDK。
修改主机名
三个节点分别通过hostnamectl set-hostname $hostname修改主机名:
# 节点192.168.56.200
hostnamectl set-hostname hadoop01
reboot
# 节点192.168.56.201
hostnamectl set-hostname hadoop02
reboot
# 节点192.168.56.202
hostnamectl set-hostname hadoop03
reboot
最终效果如下:
Connecting to 192.168.56.200:22...
Connection established.
To escape to local shell, press 'Ctrl+Alt+]'.
WARNING! The remote SSH server rejected X11 forwarding request.
Last login: Sun Dec 13 06:42:42 2020 from 192.168.56.1
[root@hadoop01 ~]#
Connecting to 192.168.56.201:22...
Connection established.
To escape to local shell, press 'Ctrl+Alt+]'.
WARNING! The remote SSH server rejected X11 forwarding request.
Last login: Sun Dec 13 07:51:28 2020 from 192.168.56.1
[root@hadoop02 ~]#
Connecting to 192.168.56.202:22...
Connection established.
To escape to local shell, press 'Ctrl+Alt+]'.
WARNING! The remote SSH server rejected X11 forwarding request.
Last login: Sun Dec 13 07:52:01 2020
[root@hadoop03 ~]#
修改hosts文件
在每个节点的hosts文件具体是/etc/hosts尾部添加:
192.168.56.200 hadoop01
192.168.56.201 hadoop02
192.168.56.202 hadoop03
方便后面可以直接通过主机名访问对应的机器。可以在任意一台机器用通过主机名ping任意的主机名:
ping hadoop01
ping hadoop02
ping hadoop03
添加hadoop用户
添加用户的操作需要在root用户下进行。添加一个用户分组、命名和密码都为hadoop的用户:
useradd hadoop
# 设置密码需要手动输入两次密码,笔者这里也暂时设定密码为hadoop
passwd hadoop
通过mkdir -p /data/hadoop创建一个新目录,后面的hadoop相关的数据等文件都放在/data/hadoop目录下。设置目录/data/hadoop的拥有者为hadoop用户:
chown hadoop:hadoop /data/hadoop
最后设置hadoop用户可以不输入密码直接通过sudo su提升为root用户:
chmod u+w /etc/sudoers
vim /etc/sudoers
# 在sudoers文件的root用户一行后面添加下面内容并且保存
hadoop ALL=(ALL) NOPASSWD:ALL
chmod u-w /etc/sudoers
效果如下:
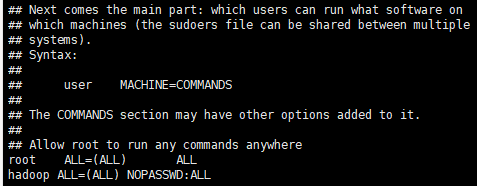
验证一下是否成功:
# 在root用户下切换hadoop用户
su hadoop
# 在hadoop用户下无密码切换root用户
sudo su
# 效果
[root@localhost]# su hadoop
[hadoop@localhost]$ sudo su
[root@localhost]#
创建hadoop用户需要在集群中每台机器操作一次。
设置集群机器SSH免登
设置集群机器SSH免登这一步十分重要,无论是scp命令去拷贝文件到各个机器,还是集群启动和通讯过程都依赖这一步。集群中每个机器都进行下面步骤操作:
- 使用
su hadoop切换到hadoop用户 - 使用
ssh-keygen -t rsa命令,接着连按几次回车,生成公钥,执行完毕后/home/hadoop/.ssh/目录下会多了一个id_rsa.pub - 收集集群中所有节点的
/home/hadoop/.ssh/id_rsa.pub内容,汇总合并成一个authorized_keys文件,再拷贝该文件到所有集群节点的/home/hadoop/.ssh/ssh目录下 - 授权
chmod 700 /home/hadoop/.ssh/ && chmod 700 /home/hadoop/ && chmod 600 /home/hadoop/.ssh/authorized_keys
最终笔者的/home/hadoop/.ssh/authorized_keys文件内容如下:

可以使用下面的脚本替代手工操作:
# 拷贝三个节点的RSA公钥到authorized_keys中,可以在第一个节点中执行即可
for a in {1..3}; do sudo ssh hadoop@hadoop0$a cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys; done
# 拷贝authorized_keys到三个节点中,可以在第一个节点中执行即可
for a in {1..3}; do sudo scp /home/hadoop/.ssh/authorized_keys hadoop@hadoop0$a:/home/hadoop/.ssh/authorized_keys ; done
最终的效果如下:

安装Hadoop
主要在hadoop01节点中安装即可,安装完毕可以通过scp命令直接拷贝文件分发到不同的节点中。赋予用户/data/hadoop目录的读写权限:
su hadoop
sudo chmod -R a+w /data/hadoop
这一步极其重要,否则容易导致运行集群的时候创建文件夹权限不足。这里记住不要主动创建Hadoop文件系统中的目录,否则容易导致DataNode启动失败。
1、解压安装
切换目录和用户:
su hadoopcd /data/hadoop
下载和解压hadoop-3.3.0:
wget https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
tar -zxvf hadoop-3.3.0.tar.gz
解压完毕后,/data/hadoop目录下会多了一个hadoop-3.3.0文件夹。
2、环境变量配置
重命名一下文件夹mv hadoop-3.3.0 app,也就是最终的HADOOP_HOME为/data/hadoop/app,可以先提前修改一下用户配置vim ~/.bashrc(所有节点都要添加),添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/data/hadoop/app
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
刷新一下用户配置source ~/.bashrc。
3、查看版本
调用hadoop version:
[hadoop@hadoop01 hadoop]$ hadoop version
Hadoop 3.3.0
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af
Compiled by brahma on 2020-07-06T18:44Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
This command was run using /data/hadoop/app/share/hadoop/common/hadoop-common-3.3.0.jar
这样就能确定JDK和Hadoop的位置配置没有问题,接着开始配置Hadoop中的应用配置。
4、Hadoop配置
配置core-site.xml(具体是/data/hadoop/app/etc/hadoop/core-site.xml):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/temp</value>
</property>
</configuration>
fs.defaultFS:nameNode的HDFS协议的文件系统通信地址hadoop.tmp.dir:Hadoop集群在工作的时候存储的一些临时文件的目录
配置hdfs-site.xml(具体是/data/hadoop/app/etc/hadoop/hdfs-site.xml):
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop03:50090</value>
</property>
<property>
<name>dfs.http.address</name>
<value>192.168.56.200:50070</value>
</property>
</configuration>
dfs.namenode.name.dir:NameNode的数据存放目录dfs.datanode.data.dir:DataNode的数据存放目录dfs.replication:HDFS的副本数dfs.secondary.http.address:SecondaryNameNode节点的HTTP入口地址dfs.http.address:通过HTTP访问HDFS的Web管理界面的地址
配置mapred-site.xml(具体是/data/hadoop/app/etc/hadoop/mapred-site.xml):
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
mapreduce.framework.name:选用yarn,也就是MR框架使用YARN进行资源调度。
配置yarn-site.xml(具体是/data/hadoop/app/etc/hadoop/yarn-site.xml):
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
yarn.resourcemanager.hostname:指定ResourceManager所在的主机名yarn.nodemanager.aux-services:指定YARN集群为MapReduce程序提供Shuffle服务
配置workers文件(这个文件在旧版本叫slaves,因为技术政治化运动被改为workers,具体是/data/hadoop/app/etc/hadoop/workers:
hadoop01
hadoop02
hadoop03
至此,核心配置基本完成。
5、分发Hadoop安装包到其他节点
重点提示三次:
- 所有节点的
Hadoop安装包位置和配置信息必须一致 - 所有节点的
Hadoop安装包位置和配置信息必须一致 - 所有节点的
Hadoop安装包位置和配置信息必须一致
在节点hadoop01使用scp命令进行分发:
## 分发节点2
scp -r /data/hadoop/app hadoop@hadoop02:/data/hadoop
## 分发节点3
scp -r /data/hadoop/app hadoop@hadoop03:/data/hadoop
6、格式化NameNode
规划中是hadoop01作为NameNode,在该机器下进行格式化:
hadoop namenode -format
格式化NameNode成功的控制台日志如下:
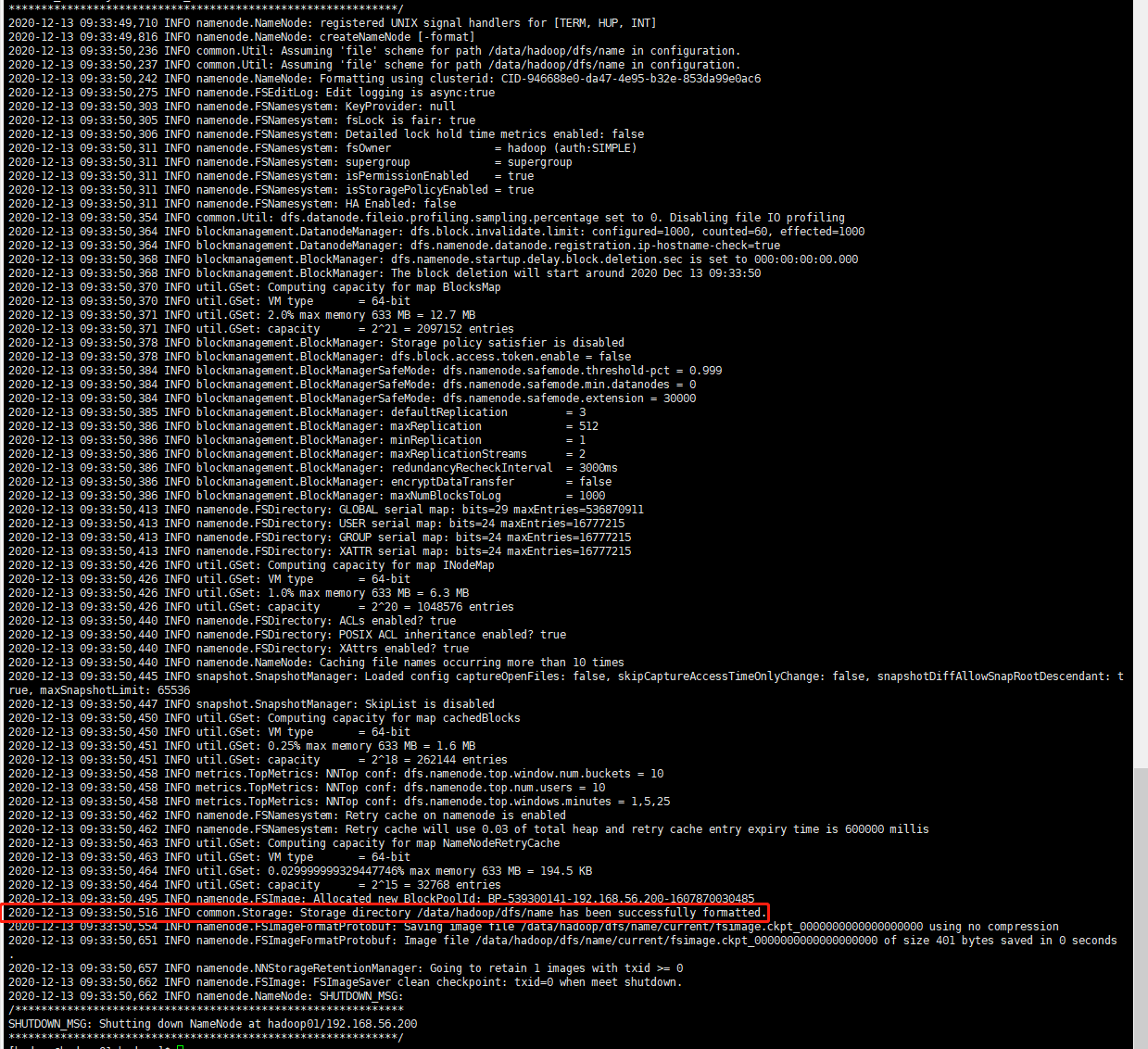
7、启动和停止HDFS
可以在任意一个节点中启动和停止HDFS,为了简单起见还是在hadoop01节点中操作:
- 启动:
start-dfs.sh - 停止:
stop-dfs.sh
调用启动命令后,控制台输出如下:
[hadoop@hadoop01 hadoop]$ start-dfs.sh
Starting namenodes on [hadoop01]
Starting datanodes
Starting secondary namenodes [hadoop03]
8、启动和停止YARN
YARN集群的启动命令必须在ResourceManager节点中调用,规划中的对应角色的节点为hadoop03,在该机器执行YARN相关命令:
- 启动:
start-yarn.sh - 停止:
stop-yarn.sh
执行启动命令后,控制台输出如下:
[hadoop@hadoop03 data]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
9、查看所有节点的进程状态
分别查看集群中所有节点的进程状态,可以直接使用jps工具,具体结果如下:
[hadoop@hadoop01 hadoop]$ jps
8673 NameNode
8823 DataNode
9383 NodeManager
9498 Jps
[hadoop@hadoop02 hadoop]$ jps
4305 DataNode
4849 Jps
4734 NodeManager
[hadoop@hadoop03 data]$ jps
9888 Jps
9554 NodeManager
5011 DataNode
9427 ResourceManager
5125 SecondaryNameNode
可见进程是正常运行的。
10、通过WEB管理界面查看集群状态
访问入口如下:
HDFS入口:http://192.168.56.200:50070(来自于hdfs-site.xml的dfs.http.address配置项)YARN入口:http://192.168.56.202:8088/cluster(ResourceManager所在节点的8088端口)
数据节点状态如下:

YARN集群状态如下:

使用Hadoop
通过几个简单的例子尝试使用Hadoop集群。
创建目录和展示目录
测试一下创建目录和展示目录:
[hadoop@hadoop01 hadoop]$ hadoop fs -mkdir -p /test
[hadoop@hadoop01 hadoop]$ hadoop fs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-12-13 10:55 /test
上传和下载文件
创建一个words.txt,写入内容并且上传到上一小节创建的test文件夹中:
cd /data/hadoop
touch words.txt
echo 'hello world' >> words.txt
hadoop fs -put words.txt /test
然后在HDFS的WEB界面中查看:
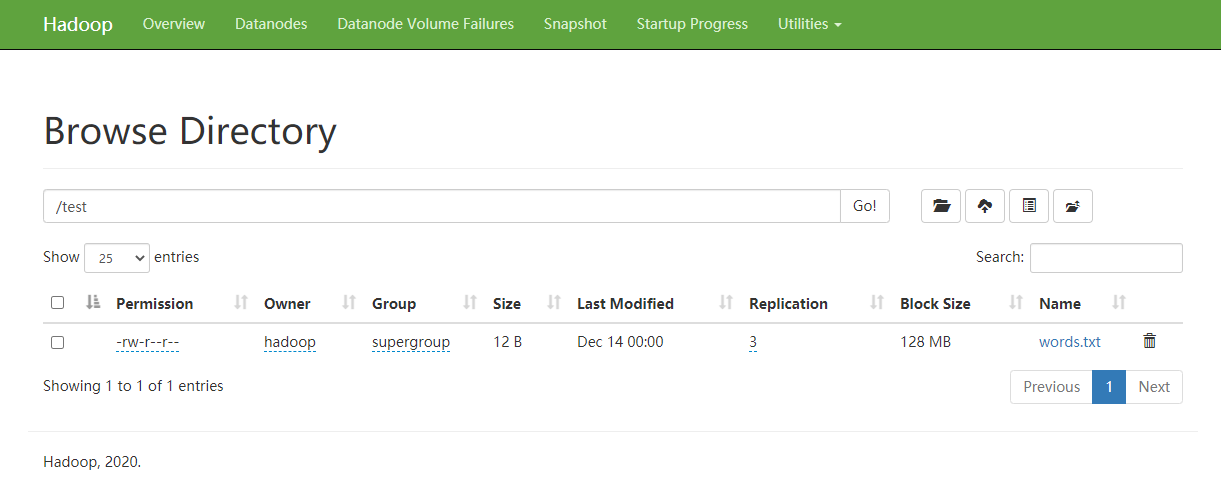
下载该文件到/data/hadoop/download.txt:
[hadoop@hadoop01 hadoop]$ hadoop fs -get /test/words.txt /data/hadoop/download.txt && \
cat /data/hadoop/download.txt
hello world
执行WordCount程序
上传一个文件到HDFS的/test/input目录:
cd /data/hadoop && \
hadoop fs -mkdir -p /test/input && \
touch words-input.txt && \
echo 'hello world' >> words-input.txt && \
echo 'hello java' >> words-input.txt && \
echo 'hello hadoop' >> words-input.txt && \
hadoop fs -put words-input.txt /test/input
自带的例子在目录/data/hadoop/app/share/hadoop/mapreduce的hadoop-mapreduce-examples-3.3.0.jar中,通过命令运行WordCount程序:
hadoop jar /data/hadoop/app/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /test/input /test/output
MR的执行过程如下:
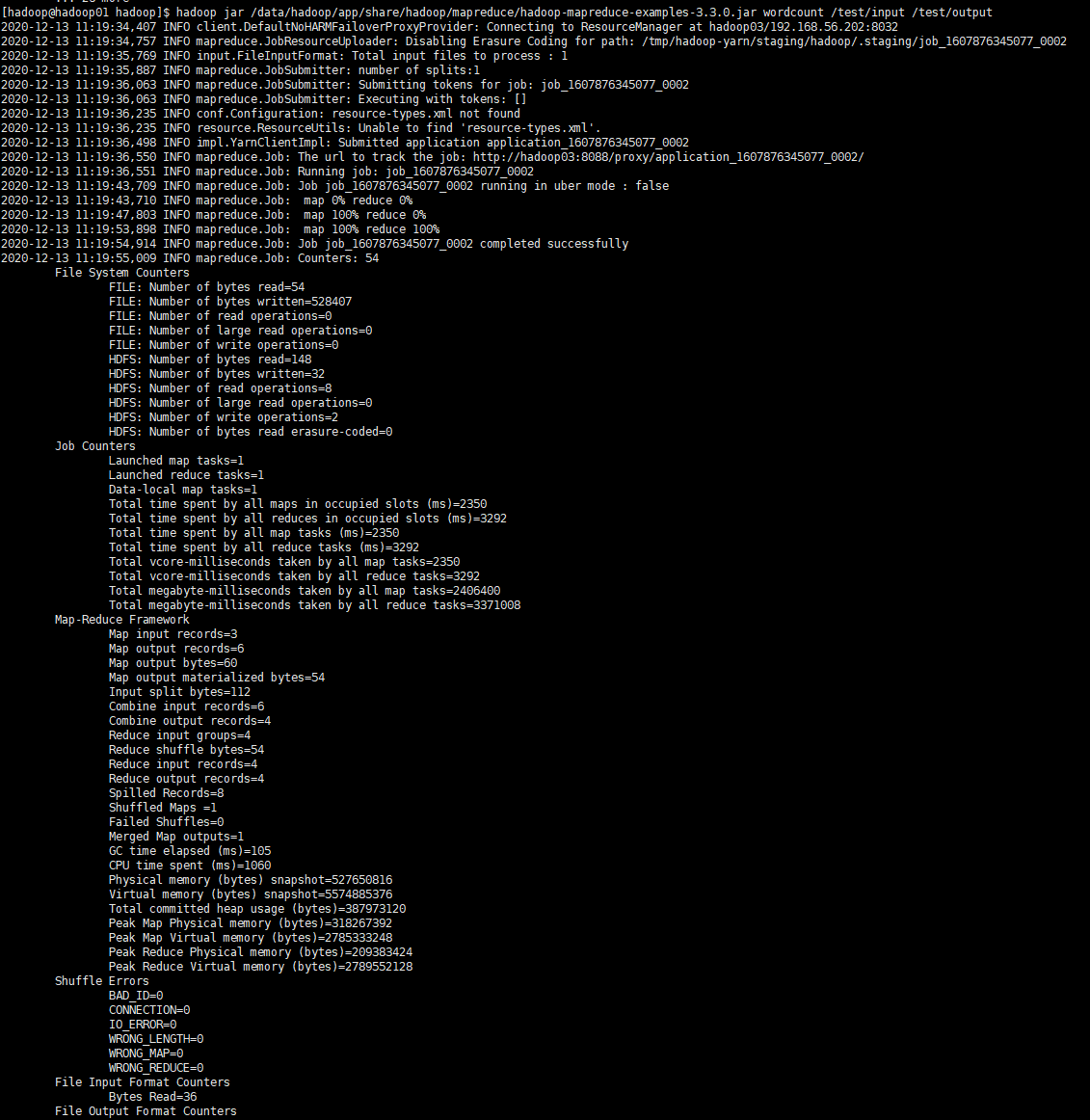
查看YARN管理界面对应的Job状态:

可知任务最终的执行状态为成功。最后可以通过hadoop fs -cat命令查看结果:
[hadoop@hadoop01 hadoop]$ hadoop fs -ls /test/output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2020-12-13 11:19 /test/output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 32 2020-12-13 11:19 /test/output/part-r-00000
[hadoop@hadoop01 hadoop]$ hadoop fs -cat /test/output/part-r-00000
hadoop 1
hello 3
java 1
world 1
小结
本文花了大量时间详细记录了如何从零开始搭建一个Hadoop集群,基于此才能进一步学习和使用Hadoop生态中的组件如Hive、Sqoop和Hbase等等,后续会逐个击破。
(本文完 c-2-d e-a-20201213)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号