实现合并区间

写在前面
在工作中,还没有仔细的去研究过一些算法实现,直到最近面试才知道,自己的数据结构与算法的功底这么差。
知道总是比不知道的强,那么就一个一个的来吧,我也会通过文字的方式记录自己的算法道路,下一个目标就是LeetCode。
如题(某次面试题)
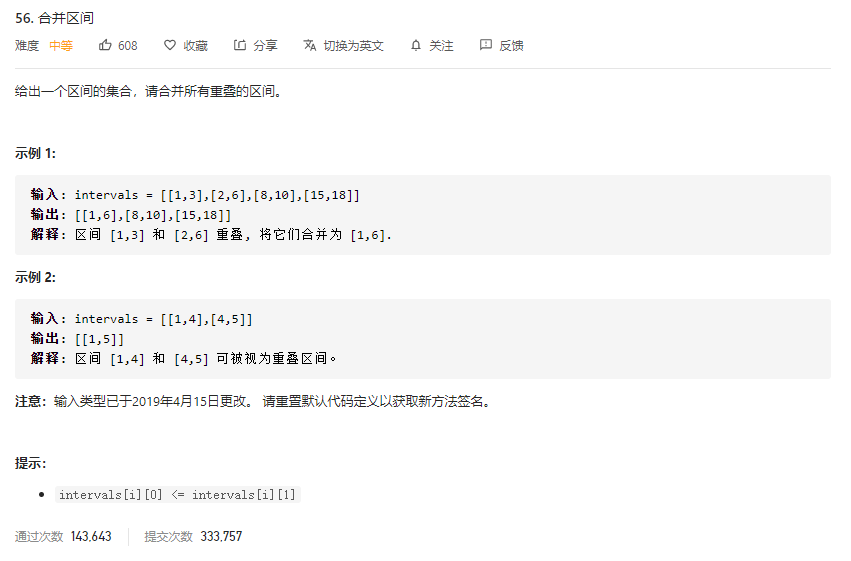
给定⼀个按开始时间从⼩到大排序的时间区间集合,请将重叠的区间合并。时间区间集合⽤用一个二维数组表示,
二维数组的每⼀行表示⼀个时间区间(闭区间),其中 0 位置元素表示时间区间开始,1 位置元素表示时间区间结束。
例 1:输入:[ [1, 3], [2, 6], [8, 10], [15, 18] ]返回: [ [1, 6], [8, 10], [15, 18]]
解释:时间区间 [1, 3] 和 [2, 6] 有部分重叠,合并之后为 [1, 6]
例 2:输入:[[1, 4], [4, 5]]返回:[[1, 5]]解释:时间区间[1,4] 和 [4,5]重叠了了⼀一个时间点,合并之后为 [1,5]
需要实现的⽅法原型:int[][] merge(int[][] intervals)
- 二维数组中的每一行表示一个时间区间(闭区间),其中0位置表示开始时间,1位置表示结束时间
- 给定的时间区间集合按照开始时间从小到大排序,即为有序
这里给出的题还是比较简单的,因为给定的时间区间集合已经是一个有序的集合了,需要实现的内容只剩下区间合并了。
由题中可知,需要合并具有重叠部分的区间,只要确定了重叠的条件,便基本完成了解答。

在已完成时间区间开始时间从小到大的排序后,那么此时的时间区间集合在时间横轴上回呈现类似上图的情况,
此时可以从小到大遍历时间区间集合,进行合并或收集。这里需要一个容器存放目标结果,也就是没有任何交集的时间区间。
具体实现代码如下所示:
/**
* 时间区间合并方法
*
* @param intervals
* @return
*/
public static int [][] merge(int [][] intervals) {
// 二维数组行数
int rows = intervals.length;
if (rows <= 1) {
return intervals;
}
// 使用同样大小的二维数组用于存放计算结果
int [][] resultIntervals = new int[rows][2];
// 指向上一次计算出的结果区间
int resultIntervalsPosition = 0;
resultIntervals[resultIntervalsPosition] = intervals[0];
/**
* 如果给定区间集合中当前位置区间的左节点数值大于上一次计算出的结果区间的右节点,
* 那么此时必定不存在交集,将该区间放入结果集合中
* 反之,则重新计算结果并更新对应的结果区间(区间右节点取最大值)
*/
for (int i = 1; i < rows; i++) {
int[] currentResultInterval = resultIntervals[resultIntervalsPosition];
if (intervals[i][0] > currentResultInterval[1]) {
resultIntervalsPosition ++;
resultIntervals[resultIntervalsPosition] = intervals[i];
} else {
currentResultInterval[1] = Math.max(intervals[i][1], currentResultInterval[1]);
resultIntervals[resultIntervalsPosition] = currentResultInterval;
}
}
// 使用相等大小的数组作为结果集时,可能会出现结果集中存在空值情况,所以在末尾进行一次拷贝
return Arrays.copyOf(resultIntervals, resultIntervalsPosition + 1, resultIntervals.getClass());
}
LeetCode类似题
具体实现思路可参见题解,这里给出的条件相对上面的内容来说,少了有序,需要自己进行排序
具体实现如下:
package com.zhoujian.algorithm;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 合并时间区间集合
*
* 给定条件:
*
* 1、给定的时间区间集合按照开始时间从小到大排序,即为有序
*
* 2、其中每一行表示一个时间区间(闭区间),0表示时间区间的开始,1表示时间区间结束
*
* @author zhoujian
*/
public class MergeTimeIntervals {
public static void main(String[] args) {
int [][] timeIntervals = {{1, 3}, {2, 6}, {8, 10}, {15, 18}};
// int [][] timeIntervals = {{4,5}, {1,4}, {0,1}};
// int [][] timeIntervals = {{1, 4}, {4, 5}};
int [][] result = merge(timeIntervals);
System.out.println(Arrays.deepToString(result));
}
/**
* 时间区间合并方法
*
* @param intervals
* @return
*/
public static int [][] merge(int [][] intervals) {
// 二维数组行数
int rows = intervals.length;
if (rows <= 1) {
return intervals;
}
// 排序
sort(intervals, rows);
// 使用同样大小的二维数组用于存放计算结果
int [][] resultIntervals = new int[rows][2];
// 指向上一次计算出的结果区间
int resultIntervalsPosition = 0;
resultIntervals[resultIntervalsPosition] = intervals[0];
/**
* 如果给定区间集合中当前位置区间的左节点数值大于上一次计算出的结果区间的右节点,
* 那么此时必定不存在交集,将该区间放入结果集合中
* 反之,则重新计算结果并更新对应的结果区间(区间右节点取最大值)
*/
for (int i = 1; i < rows; i++) {
int[] currentResultInterval = resultIntervals[resultIntervalsPosition];
if (intervals[i][0] > currentResultInterval[1]) {
resultIntervalsPosition ++;
resultIntervals[resultIntervalsPosition] = intervals[i];
} else {
currentResultInterval[1] = Math.max(intervals[i][1], currentResultInterval[1]);
resultIntervals[resultIntervalsPosition] = currentResultInterval;
}
}
// 使用相等大小的数组作为结果集时,可能会出现结果集中存在空值情况,所以在末尾进行一次拷贝
return Arrays.copyOf(resultIntervals, resultIntervalsPosition + 1, resultIntervals.getClass());
}
/**
* 冒泡排序, 对二维数组按照开始时间节点进行排序
* @param intervals
* @param size
* @return
*/
private static int [][] sort(int [][] intervals, int size) {
if (size <= 1) {
return intervals;
}
for (int i = 0; i < size; ++i) {
boolean flag = false;
for (int j = 0; j < size - i - 1; ++j) {
if (intervals[j][0] > intervals[j + 1][0]) {
// 开始交换
int [] temp = intervals[j];
intervals[j] = intervals[j + 1];
intervals[j + 1] = temp;
// 表示存在数据交换
flag = true;
}
}
if (!flag){
// 没有数据交换,提前退出
break;
}
}
return intervals;
}
}
冒泡算法理解
冒泡排序,使用两个循环嵌套完成,外层循环为冒泡次数,控制完整的排序行为,
内层循环则是从有限的数据集合中查找最大值或最小值,并将该值传递到最右端或者是最左端。
每一次的内层循环都是在有限的数据集合中寻找,每进行一次冒泡,便相应的从有限的数据集中找到最大或最小值,
该有限数据集合在逻辑层面便少了一个需要排序的值,即下一次冒泡总是比前一次少计算一个值。
内层循环旨在寻找最大或最小,如果数据还未完全有序,那么该次冒泡必定会发生数据交换。
若是冒泡计算中未发生数据交换,则意味着本次排序已经完成。数据交换作为优化条件,
表示并不是每一次排序都需要N次冒泡(假设数据集合长度为N)。
参考
说明
本节内容涉及的完整代码地址:merge-interval

 浙公网安备 33010602011771号
浙公网安备 33010602011771号