HashMap解析
HashMap1.8之后是数组加链表红黑树结构,内部是一个Node[]table数组,每个数组node或是链表的头结点,或者红黑树的根节点,有两个静态内部类Node和TreeNode。
HashMap的默认容量是16,负载因子是0.75f,它的容量总是2的幂,有一个构造方式可以指定负载因子和初始容量,HashMap(int initCapacity,float loadFactor);这个方法里面有一个tableSizeFor会返回一个指定的大于initCapacity的最小的2的幂。
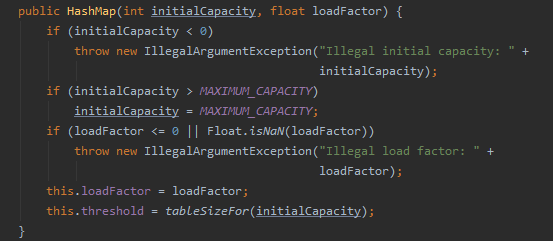
HashMap的putVal()方法:
1:若第一次插入,则执行resize()初始化容量和阈值。
2:若当前要插入table的位置没有元素就直接插入
3:如果当前要插入table的位置已有元素且要插入的key与当前位置的key相同则替换当前元素。
4:如果当前要插入table的位置已有元素且要插入的key与当前位置的key不同,判断当前table位置是链表还是树,如果是树执行TreeNode.putTreeVal();如果是链表,则插入链表尾部。如果插入后链表长度大于8则进行treeifyBin操作。
插入完成后modCount++,判断当前元素个数是否大于阈值是否需要进行扩容操作。
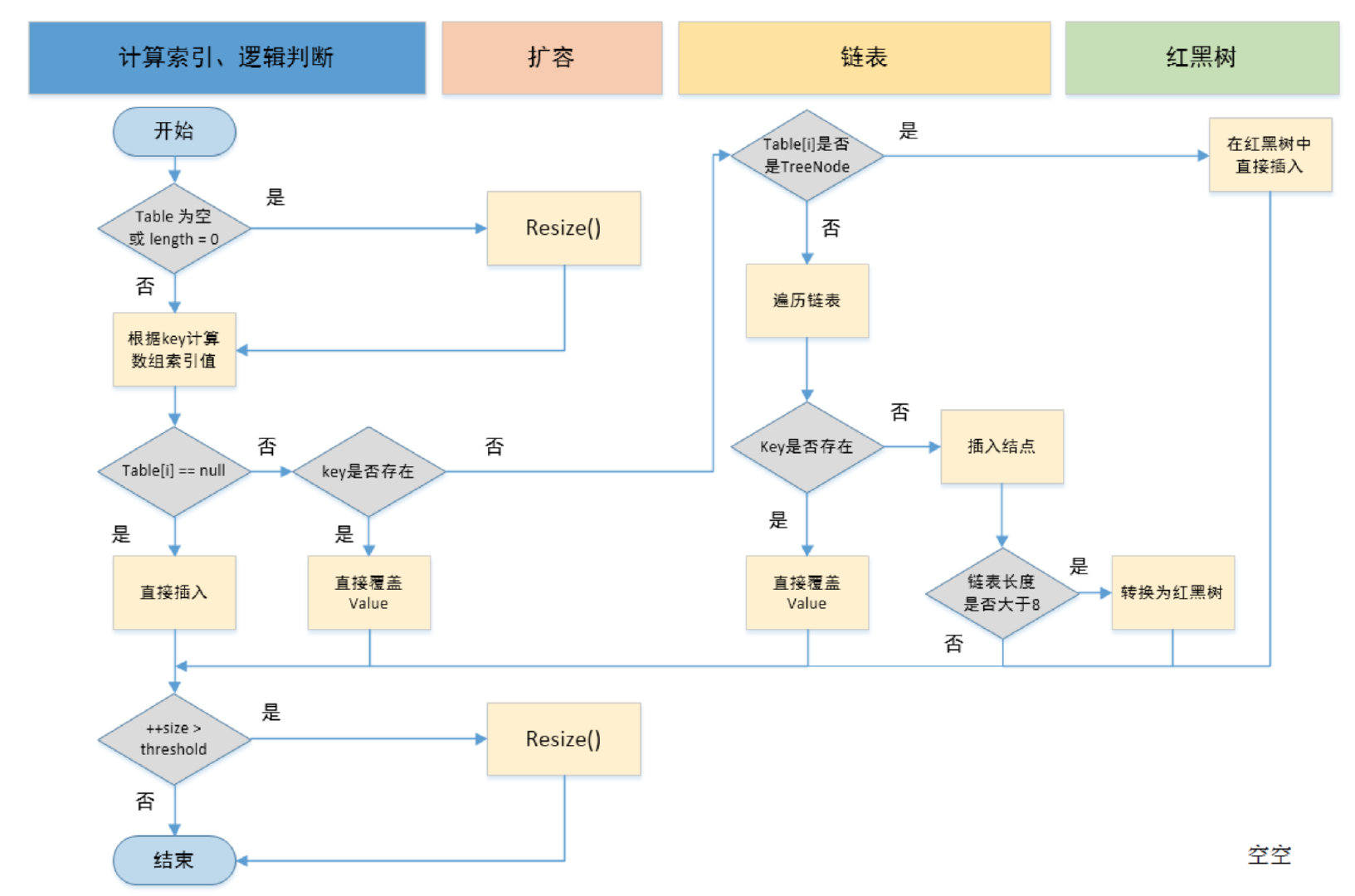
关于resize()方法:
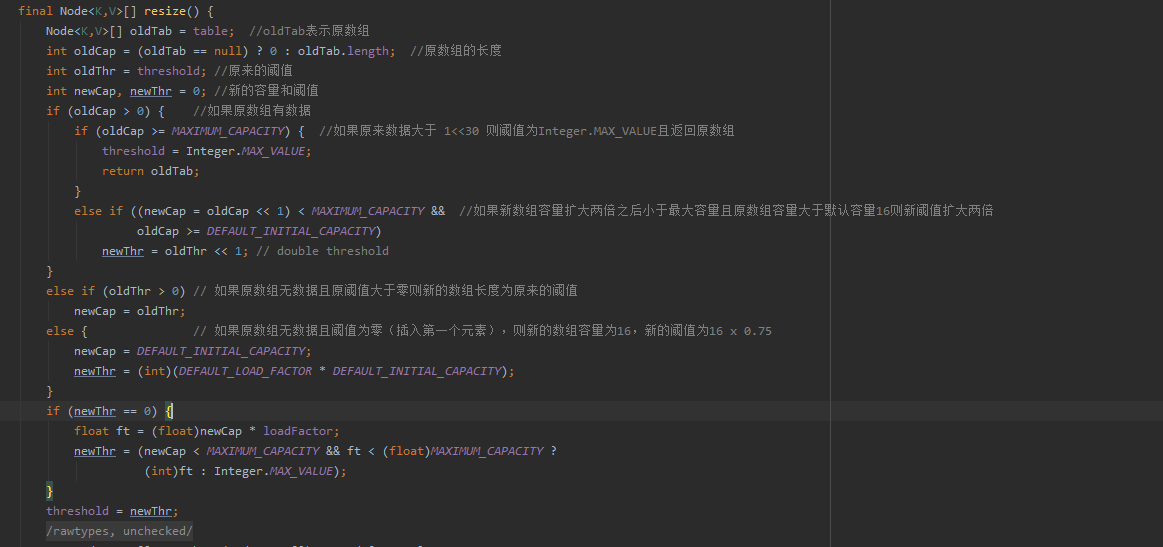
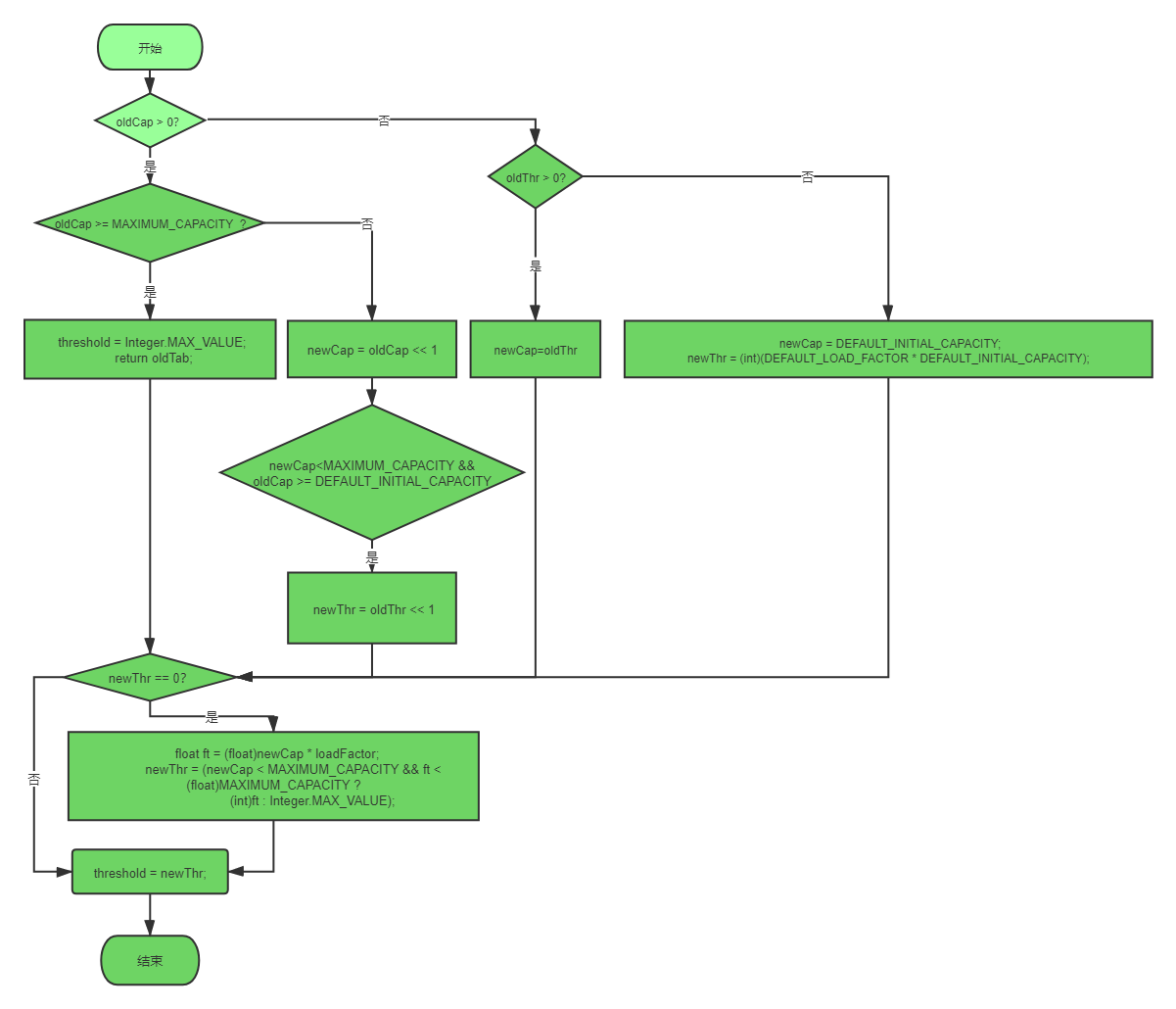
容量扩容分四种情况:
1: 当HashMap没有数据,并且没有指定初始容量和负载因子的时候,新的数组容量为16,负载因子0.75f。
2:当HashMap没有数据,有指定初始容量和负载因子的时候,新的容量等于原来的阈值,原来的阈值通过tableSizeFor(int initcapcity)返回的大于指定的初始容量的最小2的幂。
3:当HashMap有数据时,判断原的长度是否大于最大容量(1<<30),如果是,则阈值为Integer的最大值并且将原数组返回。
4:当HashMap有数据且没有超出最大容量时,新的容量等于原来的两倍,如果新的容量没有超出最大容量且原来的容量没有超出16,则新的阈值为原来的两倍。
最后判断新的阈值是否为0.如果不为0,则HashMap的阈值变为新的阈值,如果新阈值为0且新的容量小于最大容量,则hashMap的阈值为newCap * loadFactor。
扩容之后将原来的元素放入新的数组中:
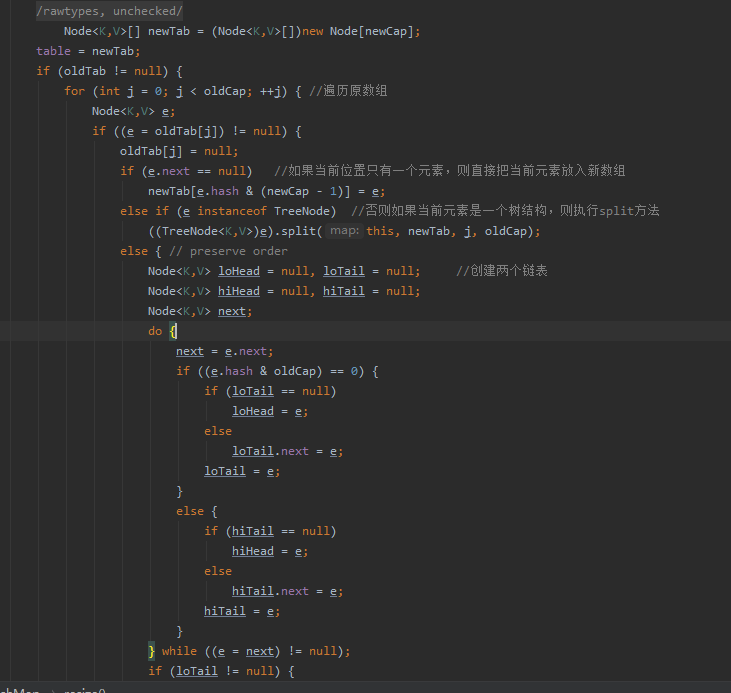
首先创建一个新的数组,数组长度为上面newCap,如果原数组不为空,则对原数组进行遍历:
1:如果数组当前位置元素不为null且当前位置只有一个元素,则直接把当前元素放入新数组,位置为 hash & (newCap-1);
2:如果当前位置的桶是一个树结构,则执行TreeNode的split();
3:如果当前位置的桶是一个链表结构,则创建两个新的链表,一个头节点是loHead,尾节点是loTail;一个头结点是hiHead,尾结点是hiTail。
这两个链表是用来拆分原链表,lo链表头结点在新的数组位置为j(j为遍历原数组的索引),hi链表头结点在新数组位置为j+oldCap。拆分的方式如下:
假设原链表当前元素为e, 若 e.hash & oldCap ==0 则该元素放入lo链表,否则放入hiTail 链表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号