
hive是什么
hive入门(一) 什么是hive
1、Hive 基本概念
Hive是基于Hadoop的一个 数据仓库工具,可以将结构化的数据文件映射
成一张表,并提供类SQL查询功能;
Hive是构建在Hadoop 之上的数据仓库;
使用HQL作为查询接口;
使用HDFS存储;
使用MapReduce计算;
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
2、hive优缺点
优点: 入门简单,避免了去写MapReduce,减少开发人员的学习成本;
统一的元数据管理,可与impala/spark等共享元数据;
灵活性和扩展性比较好:支持UDF,自定义存储格式等;
适合离线数据处理
缺点: Hive的效率比较低,由于hive是基于hadoop,Hadoop本身是一个批处理,高延迟的计算框架
其计算是通过MapReduce来作业,具有高延迟性
Hive适合对非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即查询,统计分析
3、Hive 架构
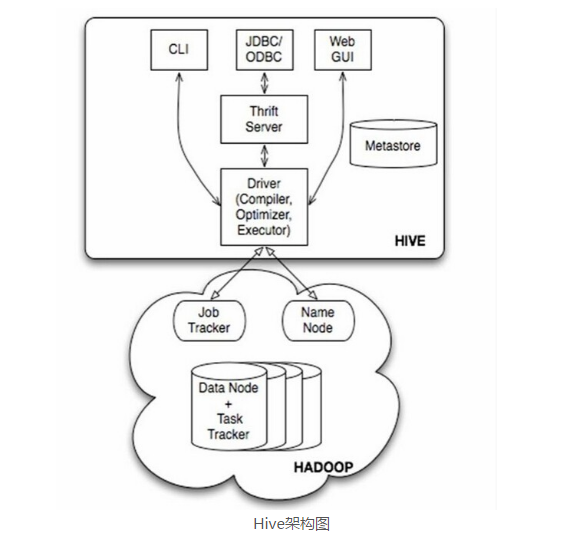
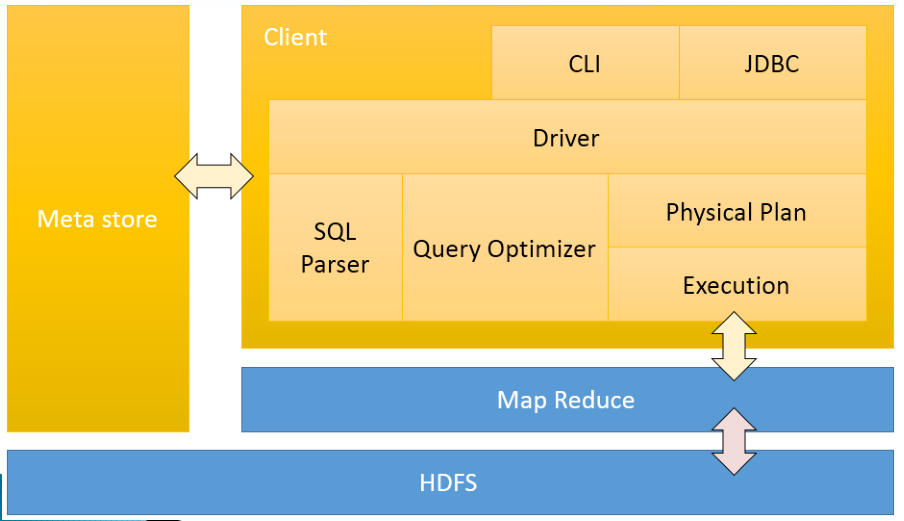
用户接口: Client
CLI(hive shell)、JDBC/ODBC(java访问hive),WEBUI(浏览器访问hive)
元数据: Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/
分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用采用MySQL存储Metastore;
Hadoop
使用HDFS进行存储,使用MapReduce进行计算;
原文:https://www.cnblogs.com/linzhong/p/8288210.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号