faiss简单测试方法
2. 运行方法
先把仓库克隆到本地,我这边还需要改cmake环境,在project上面加
set(CMAKE_CUDA_COMPILER /usr/local/cuda-11.8/bin/nvcc)
构建
mkdir build
cmake -B build .
编译,只需要编译faiss这部分就可以,(主目录下有很多测试代码,编译很慢,只编译faiss会快很多)
cd build
make -j faiss
这时候可以运行tutorial中的测试文件试试
还是在build文件夹内
make -j 2-IVFFlat
./tutorial/cpp/2-IVFFlat
运行结果为
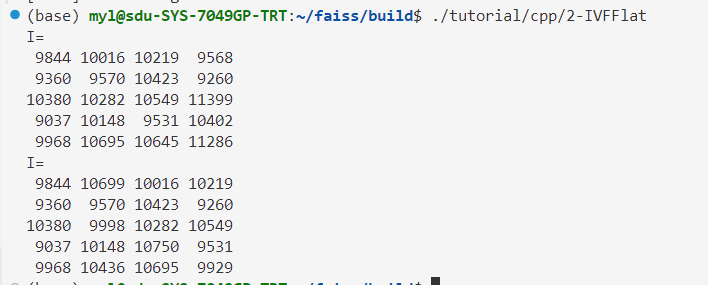
同样的,可以自己编写测试代码进行测试。
然后如果修改了faiss的代码,需要重新编译运行
make -j 2-IVFFlat
./tutorial/cpp/2-IVFFlat
这就实现了在本地修改测试faiss,可以输出faiss的运行中间结果以及执行时间
2. 测试方法
如果要用源码运行benchmark,可以在faiss目录下(不是faiss/faiss)新建文件夹”test_by_myl“
其中test_gpu.cpp文件可以参考


/** * Copyright (c) Facebook, Inc. and its affiliates. * * This source code is licensed under the MIT license found in the * LICENSE file in the root directory of this source tree. */ #include <cmath> #include <cstdio> #include <cstdlib> #include <random> #include <string> #include <fstream> #include <iomanip> #include <iostream> #include <algorithm> #include <sys/time.h> #include <faiss/gpu/GpuAutoTune.h> #include <faiss/gpu/GpuCloner.h> #include <faiss/gpu/GpuIndexIVFPQ.h> #include <faiss/gpu/StandardGpuResources.h> #include <faiss/index_io.h> #include <faiss/IndexFlat.h> #include <faiss/IndexIVFPQ.h> using namespace std; double elapsed() { struct timeval tv; gettimeofday(&tv, NULL); return tv.tv_sec + tv.tv_usec * 1e-6; } size_t SizeOf(ifstream &file){ file.seekg(0, ios::end); size_t file_size = file.tellg(); file.seekg(0, ios::beg); return file_size; } int main() { // freopen("/home/myl/data/sift1m/pcatest/output.txt","w",stdout); double t0 = elapsed(); string db_name = "/home/myl/test/data/sift1m/sift/sift_base.fvecs"; string train_name = "/home/myl/test/data/sift1m/sift/sift_learn.fvecs"; string query_name = "/home/myl/test/data/sift1m/sift/sift_query.fvecs"; string truth_name = "/home/myl/test/data/sift1m/sift/sift_groundtruth.ivecs"; // string db_name = "/home/myl/data/sift1m/pcatest/test_base.fvecs"; // string train_name = "/home/myl/test/data/sift1m/sift/sift_learn.fvecs"; // string query_name = "/home/myl/data/sift1m/pcatest/test_query.fvecs"; // string truth_name = "/home/myl/data/sift1m/pcatest/test_gt.ivecs"; ifstream db_infile(db_name, ios::binary); if(!db_infile){ std::cerr << "Error opening file db_name." << std::endl; exit(1); } ifstream train_infile(train_name, ios::binary); if(!db_infile){ std::cerr << "Error opening file db_name." << std::endl; exit(1); } // ifstream learn_infile(learn_name, ios::binary); ifstream query_infile(query_name, ios::binary); if(!query_infile){ std::cerr << "Error opening file query_name." << std::endl; exit(1); } ifstream truth_infile(truth_name, ios::binary); if(!truth_infile){ std::cerr << "Error opening file truth_name." << std::endl; exit(1); } // dimension of the vectors to index size_t d = 128; size_t nq = SizeOf(query_infile)/((d+1)*4); int k = SizeOf(truth_infile)/(nq * 4) - 1; float t; // size of the database we plan to index size_t nb = SizeOf(db_infile)/((d+1)*4); // make a set of nt training vectors in the unit cube // (could be the database) size_t nt = SizeOf(train_infile)/((d+1)*4); cerr<<"nq="<<nq<<" k="<<k<<" nb="<<nb<<" nt="<<nt<<endl; /* printf ("[%.3f s] Begin d=%d nb=%ld nt=%nt dev_no=%d\n", elapsed() - t0, d, nb, nt, dev_no); */ // a reasonable number of centroids to index nb vectors // int ncentroids = int(3 * sqrt(nb)); faiss::gpu::StandardGpuResources resources; int nlist = 2048;//划分的聚类中心数目 int m = 16;//PQ码的子聚类中心数目 int nbits = 8;//每个PQ码的字节数 int nprobe = 50;//查询时要访问的倒排列表的数量 int dev_no = 1;//GPU设备编号 faiss::gpu::GpuIndexIVFPQConfig config; config.device = dev_no; //创建GPU索引 faiss::gpu::GpuIndexIVFPQ* index_gpu = new faiss::gpu::GpuIndexIVFPQ( &resources, d, nlist, m, nbits, faiss::METRIC_L2, config); //将学习集添加到CPU索引中,进行聚类 { // training printf("[%.3f s] Reading %ld vectors from sift_learn.fvecs in %dD for training\n", elapsed() - t0, nt, d); // std::vector<float> trainvecs(nt * d); float* trainvecs = new float[nt*d]; for (size_t i = 0; i < nt; i++) { train_infile.read((char*)&d, 4); for(size_t j = 0; j < d; j++){ train_infile.read((char*)&t, 4); trainvecs[i*d+j] = t; } } printf("[%.3f s] Training the index_cpu\n", elapsed() - t0); index_gpu->train(nt, trainvecs); delete[] trainvecs; } {//添加database printf("[%.3f s] Reading a dataset from sift_base.fvecs of %ld vectors to index\n", elapsed() - t0, nb); // std::vector<float> database(nb * d); float* database = new float[nb*d]; db_infile.seekg(0, ios::beg); for (size_t i = 0; i < nb; i++) { db_infile.read((char*)&d, 4); for(size_t j = 0; j < d; j++){ db_infile.read((char*)&t, 4); database[i*d+j] = t; } } printf("[%.3f s] Adding the vectors to the index\n", elapsed() - t0); index_gpu->add(nb, database); delete[] database; printf("[%.3f s] done\n", elapsed() - t0); } //将CPU索引转换为GPU索引 int gpu_device = 0; // 设定 GPU 设备编号,可以根据实际情况调整 // faiss::Index* index_gpu_base = faiss::gpu::index_cpu_to_gpu(&resources, gpu_device, index_cpu); // 将 faiss::Index 对象强制转换为 faiss::gpu::GpuIndexIVFPQ 类型 // faiss::gpu::GpuIndexIVFPQ* index_gpu = dynamic_cast<faiss::gpu::GpuIndexIVFPQ*>(index_gpu_base); // printf("The CPU index has been converted to the GPU index\n"); //执行查询 // std::vector<float> queries; float* queries = new float[nq*d]; // queries.resize(nq * d); for (size_t i = 0; i < nq; i++) { query_infile.read((char*)&d, 4); for(size_t j = 0; j < d; j++){ query_infile.read((char*)&t, 4); queries[i*d+j] = t; } } { // searching the database printf("[%.3f s] Searching the %d nearest neighbors " "of %ld vectors in the index\n", elapsed() - t0, k, nq); std::vector<faiss::idx_t> nns(k * nq); std::vector<float> dis(k * nq); //设置查询参数 index_gpu->nprobe = nprobe;//控制要访问的倒排列表的数量 index_gpu->search(nq, queries, k, dis.data(), nns.data()); printf("[%.3f s] Query results (vector ids, then distances):\n", elapsed() - t0); printf("note that the nearest neighbor is not at " "distance 0 due to quantization errors\n"); printf("[%.3f s] Compute recalls\n", elapsed() - t0); //读取groundtruth int* gt=new int[k*nq]; double recall=0; unsigned int value; // for(size_t i=0;i<nq;i++){ // truth_infile.read(reinterpret_cast<char*>(&value), sizeof(value));//读取"100" // for(size_t j=0;j<k;j++){ // truth_infile.read(reinterpret_cast<char*>(&value), sizeof(value)); // gt[i*k + j]=value; // for(size_t m=0;m<k;m++){ // if(value == nns[m + i*k]){ // recall=recall+1; // break; // } // } // } // } for(size_t i=0;i<nq;i++){ truth_infile.read(reinterpret_cast<char*>(&value), sizeof(value));//读取"100" for(size_t j=0;j<k;j++){ truth_infile.read(reinterpret_cast<char*>(&value), sizeof(value)); gt[i*k + j]=value; if(j<10){ for(size_t m=0;m<10;m++){ if(value == nns[m + i*k]){ recall=recall+1; break; } } } } } recall = recall/(1.0*10*nq); printf("recall = %.5f\n",recall); // evaluate result by hand. int n_1 = 0, n_10 = 0, n_100 = 0; for (int i = 0; i < nq; i++) { int gt_nn = gt[i * k]; for (int j = 0; j < k; j++) { if (nns[i * k + j] == gt_nn) { if (j < 1) n_1++; if (j < 10) n_10++; if (j < 100) n_100++; } } } printf("R@1 = %.4f\n", n_1 / float(nq)); printf("R@10 = %.4f\n", n_10 / float(nq)); printf("R@100 = %.4f\n", n_100 / float(nq)); delete[] gt; } db_infile.close(); train_infile.close(); query_infile.close(); truth_infile.close(); delete index_gpu; // delete[] trainvecs; // delete[] database; delete[] queries; // fclose(stdout); return 0; }
CMakeLists.txt文件可以参考
add_executable(test_gpu EXCLUDE_FROM_ALL test_gpu.cpp)
target_link_libraries(test_gpu PRIVATE faiss)
然后再在根目录中的CMakeLists.txt加入当前的目录
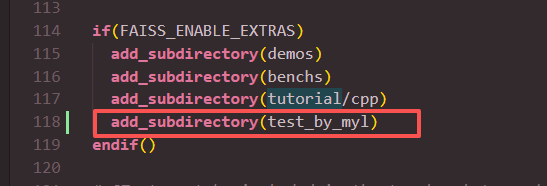
注意这里修改了CMakeLists,所以需要重新cmake
然后make -j faiss
make -j test_gpu
然后就可以运行./test_by_myl/test_gpu

 浙公网安备 33010602011771号
浙公网安备 33010602011771号