一句话描述文献(持续更新)
1. CudaCHPre2D: A straightforward preprocessing approach for accelerating 2D convex hull computations on the GPU
2020; CCF C; Concurrency and Computation: Practice and Experience
一种凸包预处理方法,通过旋转坐标系找到4组上下左右端点,预处理产生16个点,形成初始凸包。
2. GPU accelerated convex hull computation
2012; CCF C; Computers & Graphs
GPU用QuickHull算法处理一个近似凸包(含有凹面),然后由CPU进行精确凸包计算。
3. One-Class Convex Hull-Based Algorithm for Classification in Distributed Environments
2017; CCF B; IEEE Transactions on Systems, Man, and Cybernetics: Systems
该论文是在论文One-class classification algorithm based on convex hull的基础上扩展到了分布式系统
凸包用于单类分类:通过随机投影和二维凸包模型来近似d维凸包决策,在多个映射平面下验证点是否在凸包内,然后扩展到分布式系统中。
4. ParGeo: a library for parallel computational geometry
2022; CCF A; PPoPP
作者设计了一个低维空间中计算几何并行算法库,包括三个新算法贡献:
1. 凸包算法:基于保留技术的并行凸包算法 + 随机增量算法的并行实现 + R^3中的分支凸包算法
2. 最小封闭球问题
3. BDL-tree:并行处理动态k-d树,提供并行更新和kNN查询
5. A filtering technique for fast Convex Hull construction in R2
找到上、下、左、右、上左、上右、下左、下右八个边界点,过滤掉内部点,并建立上左、上右、下左、下右四个优先队列,对每个优先队列计算四分之一凸包,按顺序连接。
6. Yinyang k-means: A drop-in replacement of the classic k-means with consistent speedup
用上下界优化K-means的计算:用上下界过滤中心点不变的点,通过分组提高过滤的强度;更新中心点坐标时,重用旧的中心点,减少计算量。
7. Ball -Means: Fast Adaptive Clustering With No Bounds
用球体描述每个聚类,通过划分稳定区域和活动区域来减少计算。(稳定区域的点不会归类到其它簇)
8. Efficient Indexing of Billion-Scale datasets of deep descriptors
面向深度神经网络产生的描述符的近似最近邻搜索(子空间之间具有显著的相关性,没有SIFT那样独立的分布)。
定义两个codebook:$S={S_1, ..., S_K}$, $T={T_1, ..., T_K}$
把数据分配到$K^2$个质心中:$C_i^j = S_i + \alpha[i,j]T_j$
$\alpha$是包含聚类信息的因子,因为first-order cell共享相同的second-order cell在数据疏密不均的情况下并不合理,所以添加$\alpha$因子来缓解这一情况
9. Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors
将反向索引区域分割成一组更小的子区域,将每个区域的subcentroids codebook构造成区域质心和它相邻质心的一组凸组合。
用质心c描述单个区域,点${x_1, ..., x_n}$是该区域中的点,c的临近质心是${s_1, ..., s_L}=NN_L(c)$,则L个subcentroids定义为${c+\alpha(s_l-c)}, l=1,...,L$,其中不同的质心c所表示的区域有不同的$\alpha$值。
在索引结构中,来自同一个子区域的点被连续有序排列,分组完成后,从subcentroids开始的位移$x_i-(c+\alpha(s_{l_i}-c))$用PQ编码。
10. Multiscale Quantization for Fast Similarity Search
没细看,大意是coarse quantization(VQ) -> residuals -> rotation -> PQ
11. Fast Adaptive Similarity Search through Variance-Aware Quantization
方差感知量化方法VAQ,通过智能地调整字典大小到子空间来编码数据。利用内在的降维性质推导子空间,根据每个子空间的重要性成比例地分配字典大小。
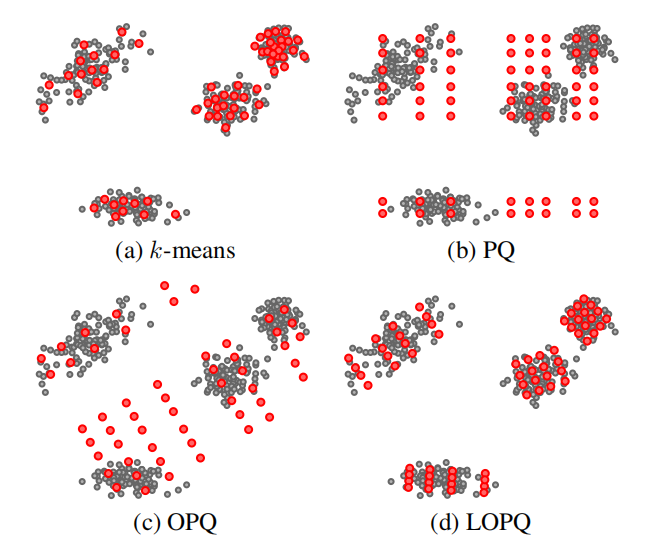
12. Locally Optimized Product Quantization for Approximate Nearest Neighbor Search
局部优化,OPQ是对全局数据进行旋转,LOPQ是对每个cell的数据分别旋转,这样可以考虑到不同聚类中的分布
13. Accelerating Large-Scale Inference with Anisotropic Vector Quantization
开发了一组各向异性量化损失函数,能够更严重地惩罚数据点的残差相对于其正交分量的平行向量
平行残差比正交残差更重要,这是因为对于给定的query,对于更接近的特征向量,它的量化误差应该被赋予更高的权重
14. SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search
这篇文章主要解决billion-scale数据在存储上的问题,提出三个方法:
1. 用多约束平衡聚类算法均衡每个倒排列表的长度
2. 把边缘的点归类到多个聚类中
3. 通过q与聚类中心的距离筛选出一些不需要访问的聚类中心
挖坑
DeepHull 凸包近似算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号