“堆外缓存”这玩意是真不错,我要写进简历了。
你好呀,我是歪歪。
之前在《3 招将吞吐量提升了 100%,现在它是我的了》这篇文章中,我在 OHC 堆外缓存上插了个眼:

这次就把这个眼给回收了吧,给你盘一下 OHC。
之前的文章里面说的是啥场景呢,我们先简单回顾一下。
就是一个服务的各项 JVM 的配置都比较合理的情况下,它的 GC 情况还是不容乐观。
然后 dump 了一把内存,一顿分析之后发现有 2 个对象特别巨大,占了总存活堆内存的 76.8%。其中第 1 大对象是本地缓存, GC 之后依旧存活,干都干不掉。
怎么办呢?
把缓存对象移到堆外。
因为堆外内存并不在 GC 的工作范围内,所以避免了缓存过大对 GC 的影响。
堆外内存不受堆内内存大小的限制,只受服务器物理内存的大小限制。这三者之间的关系是这样的:物理内存=堆外内存+堆内内存。
对于堆外内存的使用,有个现成开源项目就是 OHC,开箱即用,香的一比。
当时就是这样做了一个简单的介绍,也没有深入的去分析,我个人对这个 OHC 还是比较感兴趣,但是有一说一,这玩意应用场景是真的不丰富,但是如果恰巧碰到了可以使用的应用场景。就可以开始你的表(装)演(逼)了
什么是可以使用的应用场景?
就是你的本地缓存对象特别多,多到都把你“堆”里面都快塞满了,从而 GC 频繁、时间长,都影响到服务的正常运行了。
这个时候一拨人说:我要求调整 JVM 参数,调大堆内存。
还有一拨人说:依我看,这个本地缓存干脆就别滥用了,非必要,不缓存,减少内存占用。
另外一拨人说:又不是不能用?
大家争得面红耳赤的时候,你轻飘飘的来一句:这个问题我觉得可以用堆外内存来解决,比如有个开源项目叫做 OHC,就比较好,可以调研一下。
事了拂衣去,深藏身与名。
所以为了以后能更好的装这个逼,这篇文章我准备盘一盘它,但是先说好,本文不会带你去盘源码,只是让你知道有这个框架的存在,做个简单的导读而已。
Demo
老规矩,对于自己不了解的技术,都是先会简单使用,再深入了解。
所以还是得搞个 Demo 才行,直接到它的 github 上找 Quickstart 就完事它的 Quickstart 就这么一行代码:
https://github.com/snazy/ohc
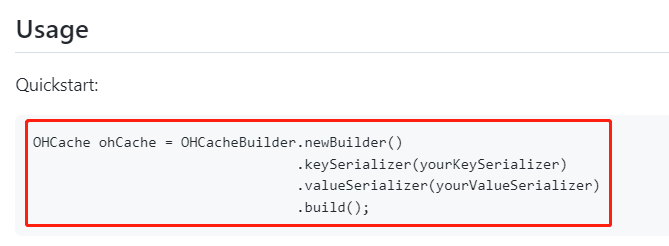
我看到的第一眼就是觉得这也太简陋了,在我想象中,一个好的 Quickstart 是我自己粘贴过来就能直接跑,很显然,它这个不行,本资深白嫖党表示强烈的谴责以及极度愤怒。

但是没办法,还是先粘过来再说。
对了,记得先导入 maven 依赖:
<dependency>
<groupId>org.caffinitas.ohc</groupId>
<artifactId>ohc-core</artifactId>
<version>0.7.4</version>
</dependency>
粘贴过来之后,我发现它这属于一个填空题啊:
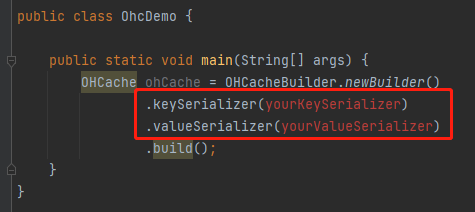
key 和 value 的序列化方式并没有给我们提供,而是需要我们进行自定义,这一点在它的 README 中也提到了:

它说 key 和 value 的序列化需要去实现 CacheSerializer 接口,这个接口三个方法,分别是对象序列化之后的长度,序列化和反序列化方法。
需要自己去实现一个序列化方式,一瞬间我的脑海里面蹦出了好几个关键词:Protobuf、Thrift、kryo、hessian 什么的。
但是都太麻烦了,还得自己去编码,我只是想搞个 Demo 尝个味道而已,要是能从哪儿直接借鉴一个过来就好了。
所以,我把 OHC 的源码拉下来了,因为直觉告诉我,它的测试用例里面肯定有现成的序列化方案。
果不其然,测试案例非常的多,而我找到了这个:
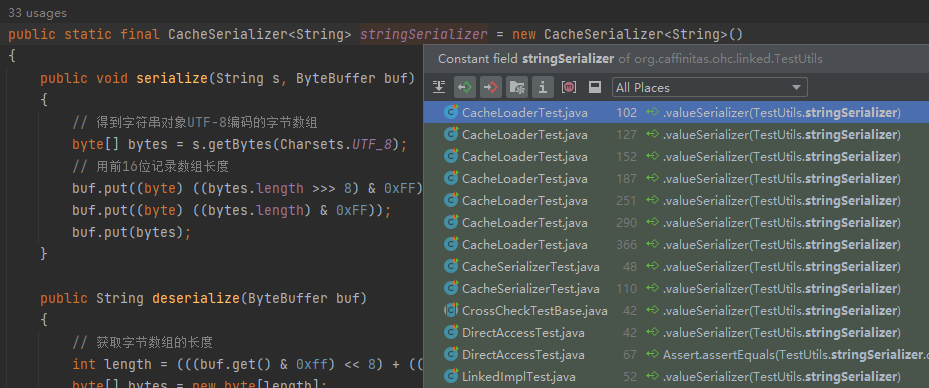
org.caffinitas.ohc.linked.TestUtils
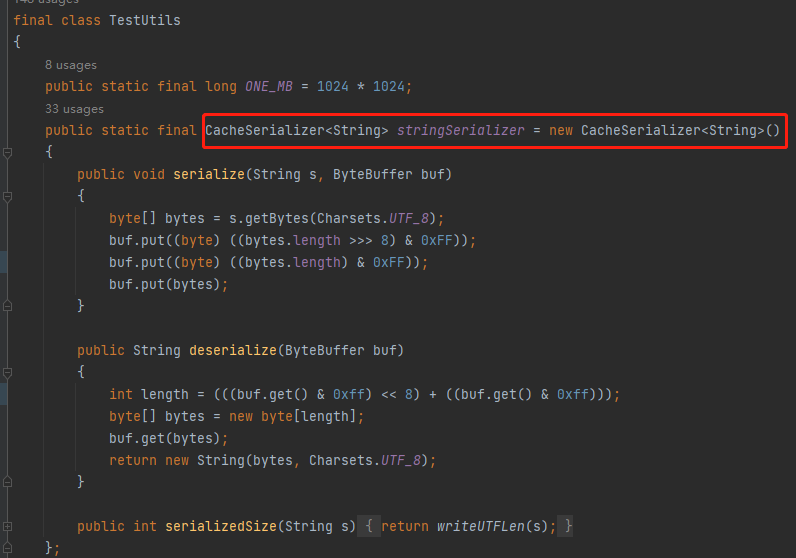
这个序列化方式就是测试用例里面广泛使用的方式:
现在序列化方式有了,那么整个完整的代码就是这样的,我也给你搞个舒服的 Quickstart,粘过去就能用那种:
public class OhcDemo {
public static void main(String[] args) {
OHCache ohCache = OHCacheBuilder.<String, String>newBuilder()
.keySerializer(OhcDemo.stringSerializer)
.valueSerializer(OhcDemo.stringSerializer)
.build();
ohCache.put("hello","why");
System.out.println("ohCache.get(hello) = " + ohCache.get("hello"));
}
public static final CacheSerializer<String> stringSerializer = new CacheSerializer<String>() {
public void serialize(String s, ByteBuffer buf) {
// 得到字符串对象UTF-8编码的字节数组
byte[] bytes = s.getBytes(Charsets.UTF_8);
// 用前16位记录数组长度
buf.put((byte) ((bytes.length >>> 8) & 0xFF));
buf.put((byte) ((bytes.length) & 0xFF));
buf.put(bytes);
}
public String deserialize(ByteBuffer buf) {
// 获取字节数组的长度
int length = (((buf.get() & 0xff) << 8) + ((buf.get() & 0xff)));
byte[] bytes = new byte[length];
// 读取字节数组
buf.get(bytes);
// 返回字符串对象
return new String(bytes, Charsets.UTF_8);
}
public int serializedSize(String s) {
byte[] bytes = s.getBytes(Charsets.UTF_8);
// 设置字符串长度限制,2^16 = 65536
if (bytes.length > 65535)
throw new RuntimeException("encoded string too long: " + bytes.length + " bytes");
return bytes.length + 2;
}
};
}
从上面的 Demo 你也能看出来,OHCache 这个东西,和 Map 差不多,基本方法也是 put,get。
只是 put 的对象,也就是缓存的对象,是由用户自定义的序列化方法决定的。比如我上面这个只能缓存字符串类型,如果你想要放个自定义对象进去,就得实现一个自定义对象的系列化方法,很简单的,网上搜一下,多的很。
现在我们已经有一个可以运行的 Demo 了,运行之后输出是这样的,没有任何毛病:
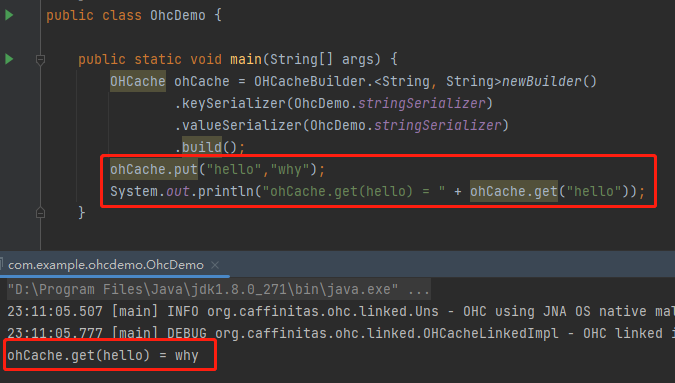
Demo 跑起来了,我们就算是找到“抓手”了,接下来就是分析它,结合自己的实际业务,沉淀出一套“可迁移、可复用”的组合拳,用来给自己“赋能”。

对比
为了让你能更加直观的看到堆外内存和堆内内存的区别,我给你搞两段程序跑跑。
首先是我们堆内内存的代表选手,HashMap:
/**
* -Xms100m -Xmx100m
*/
public class HashMapCacheExample {
private static HashMap<String, String> HASHMAP = new HashMap<>();
public static void main(String[] args) throws InterruptedException {
hashMapOOM();
}
private static void hashMapOOM() throws InterruptedException {
//准备时间,方便观察
TimeUnit.SECONDS.sleep(10);
int num = 0;
while (true) {
//往 map 中存放 1M 大小的字符串
String big = new String(new byte[1024 * 1024]);
HASHMAP.put(num + "", big);
num++;
}
}
}
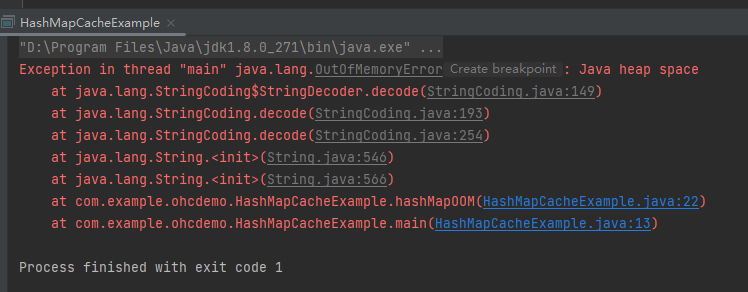
通过 JVM 参数控制堆内存大小为 100m,然后不断的往 Map 中存放 1M 大小的字符串,那么这个程序很快就会出现 OOM:
其对应的在 visualvm 里面的内存走势图是这样的:
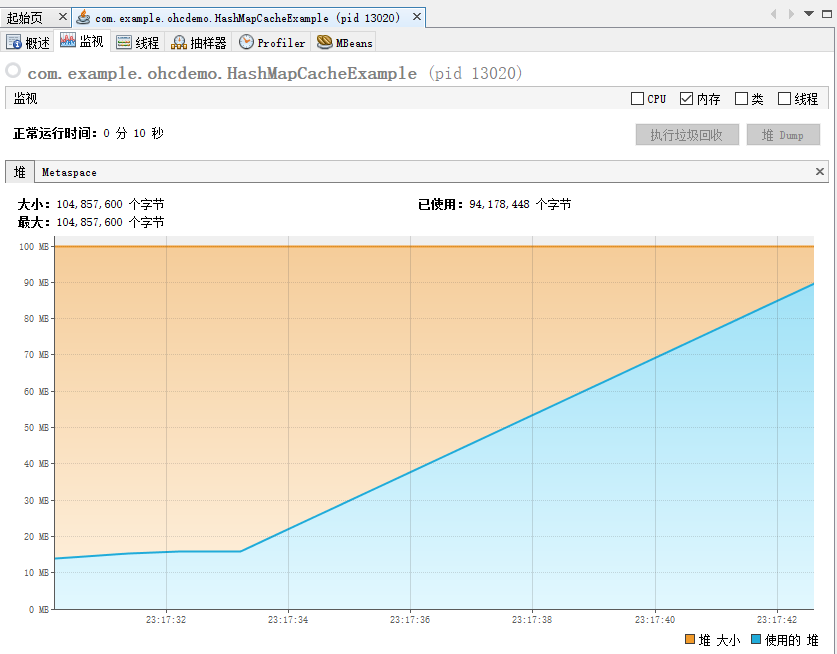
程序基本上属于一启动,然后内存就被塞满了,接着立马就凉了。
属于秒了,被秒杀了。
但是,当我们同样的逻辑,用堆外内存的时候,情况就不一样了:
/**
* -Xms100m -Xmx100m
*/
public class OhcCacheDemo {
public static void main(String[] args) throws InterruptedException {
//准备时间,方便观察
TimeUnit.SECONDS.sleep(10);
OHCache ohCache = OHCacheBuilder.<String, String>newBuilder()
.keySerializer(stringSerializer)
.valueSerializer(stringSerializer)
.build();
int num = 0;
while (true) {
String big = new String(new byte[1024 * 1024]);
ohCache.put(num + "", big);
num++;
}
}
public static final CacheSerializer<String> stringSerializer = new CacheSerializer<String>() {//前面写过,这里略了};
}
关于上面程序中的 stringSerializer 需要注意一点的是我做测试的时候把这个大小的限制取消掉了,目的是和 HashMap 做测试是用同样大小为 1M 的字符串:
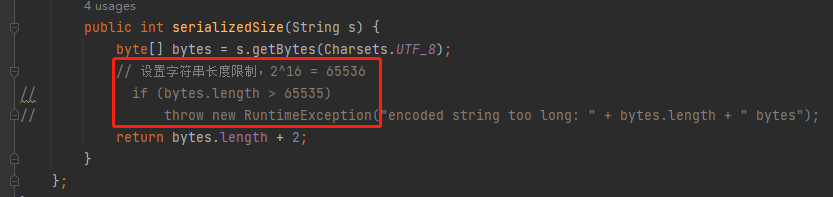
这是程序运行了 3 分钟之后的内存走势图:
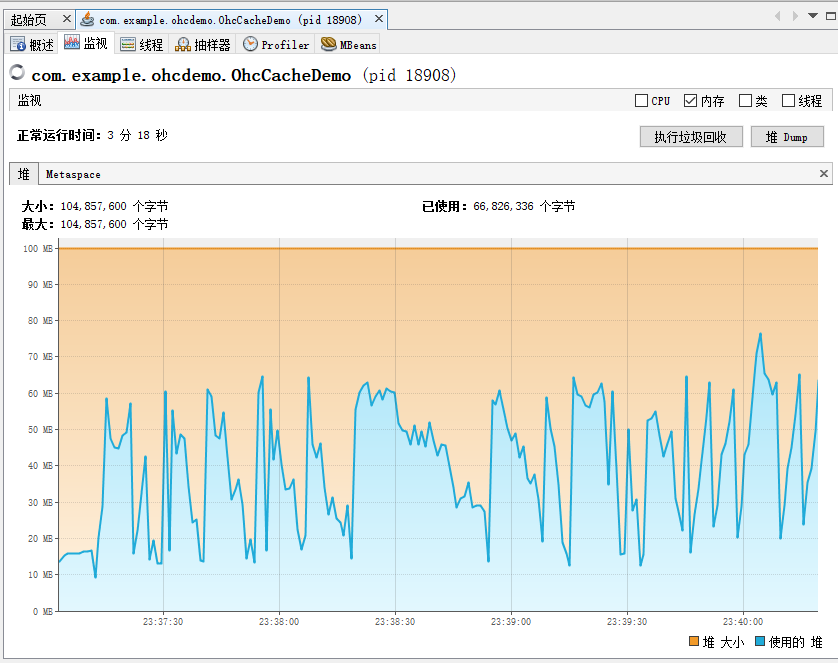
这个图怎么说呢?
丑是丑了点,但是咱就是说至少没秒,程序没崩。
当这两个内存走势图一对比,是不是稍微就有那么一点点感觉了。
但是另外一个问题就随之而来了:我怎么看 OHCache 这个玩意占用的内存呢?
前面说了,它属于堆外内存。JVM 的堆外,那就是我本机的内存了。
打开任务管理器,切换到内存的走势图,正常来说走势图是这样的,非常的平稳:
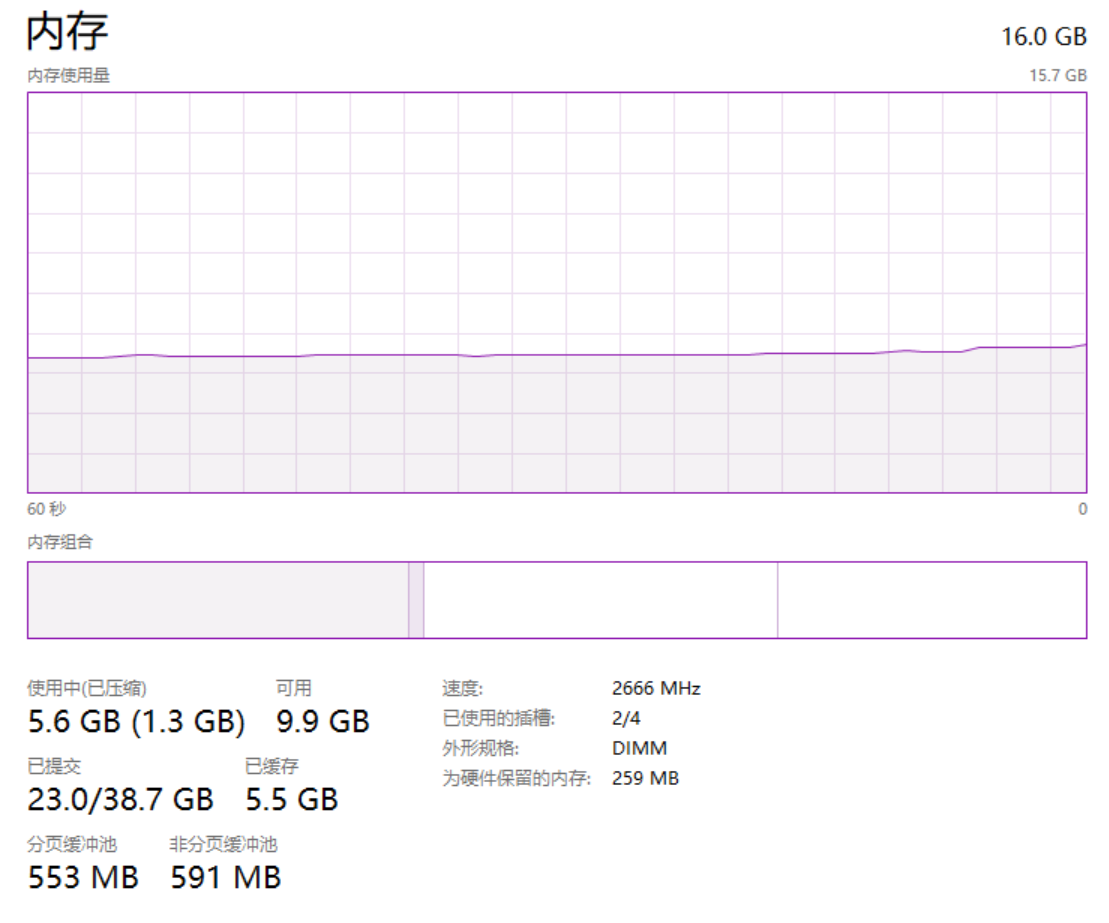
从上面截图可以看到,我本机是 16G 的内存大小,目前还有 9.9G 的内存可以使用。
也就是说截图的这个时刻,我能使用的堆外内存顶天了也就是 9.9G 这个数。
那么我先用它个 6G,程序一启动,走势图就会变成这样:
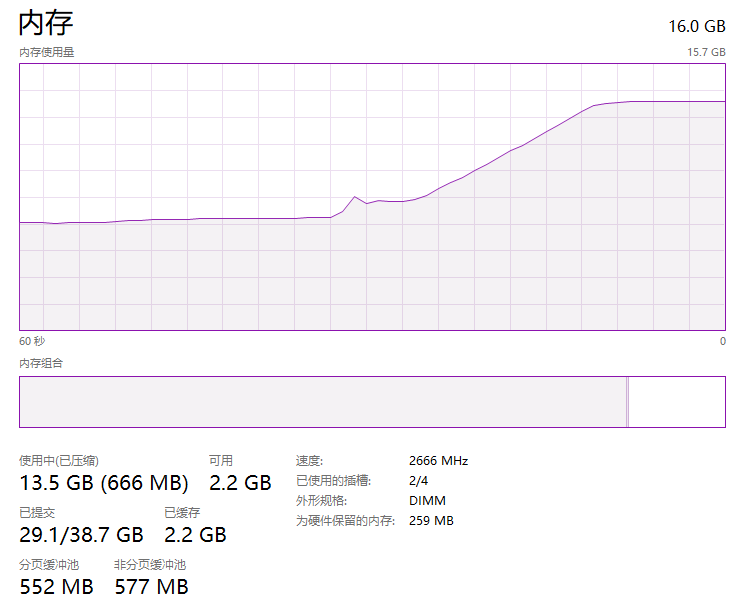
而程序一关闭,内存占用立马就释放了:
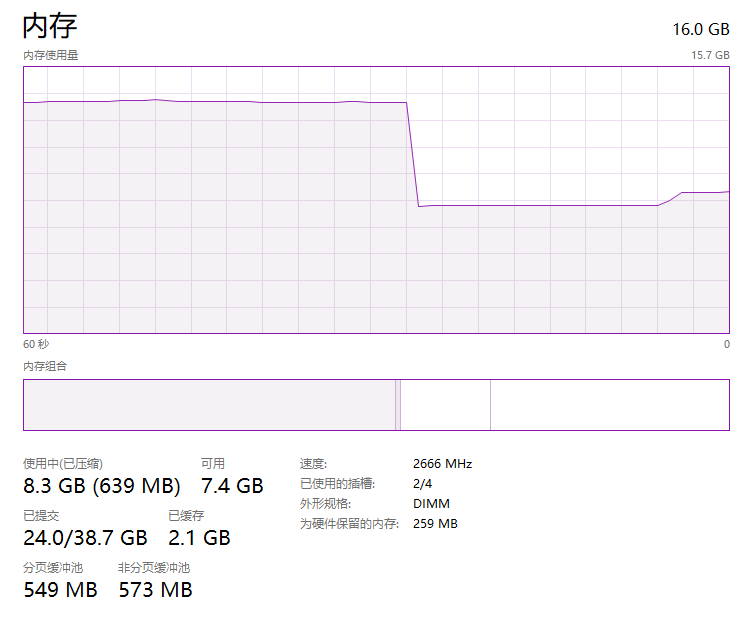
也许你没注意到,前面我说了一句“用它个 6G”,我怎么控制这个 6G 的呢?
因为我在程序里面加了这样一行代码:
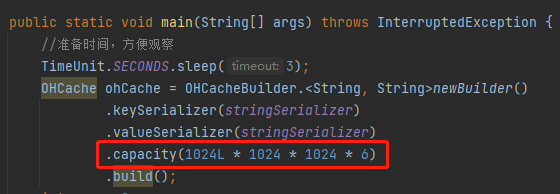
如果你不加的话,默认只会使用 64M 的堆外内存,看不出啥曲线。
如果你要想自己玩一玩,想亲眼看看这个走势图,记得加上这行代码,具体的值按照你机器的情况给就行了,个人建议是先做好保存工作,最好是意思意思就行了,别把值给的太大,电脑玩坏了你来找我,我不仅不赔钱,我还会笑你。

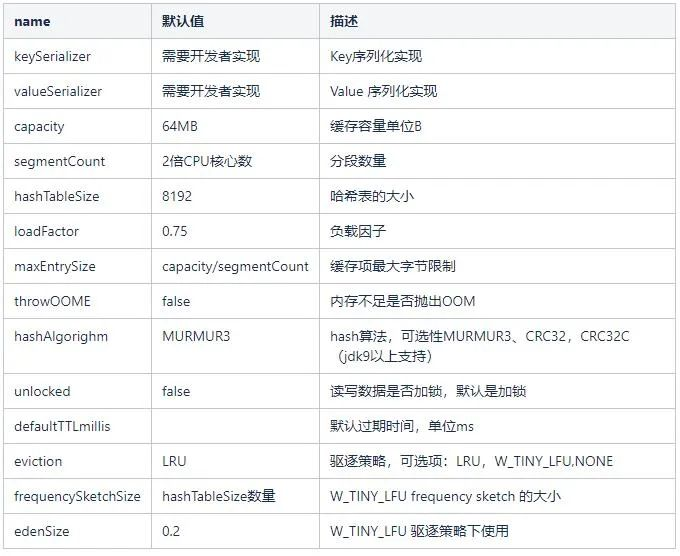
然后除了这个 “6G” 可以自定义外,还有一些很多可以自定义的参数,清单如下,可以自己研究一波:
源码
前面说了,本文也不会带你去阅读源码,因为这个项目的源码写的已经很通俗易懂了,你自己去看,就知道主干逻辑写的非常的顺畅,没必要做太多的源码解析。
我最多在这里指个路。
我看源码是从 put 方法开始看的,但是 put 方法有两个实现类:
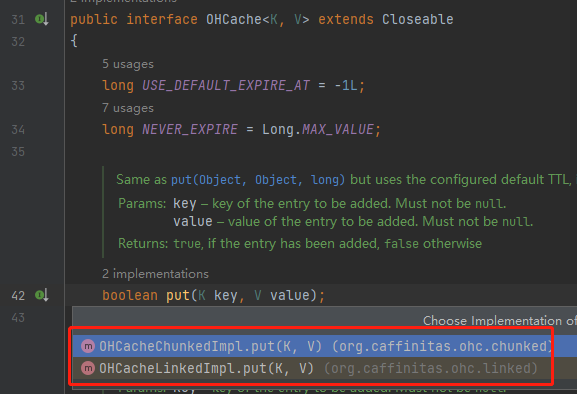
关于这两个实现类,github 上进行了介绍:
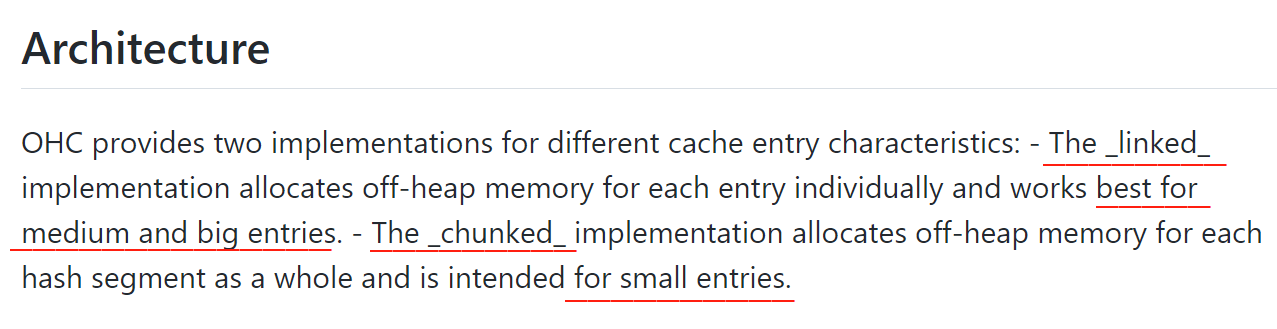
linked 实现方式:为每个需要缓存的对象单独分配堆外内存,对中、大条目效果最好。 chunked 实现方式:为每个哈希段整体分配堆外内存,相当于有个预分配的意思,适用于小条目。
但是这里你只需要看 linked 实现方式就行了。
为啥?
别问,问就是作者建议的,在 github 的 README 里面有这样一个 NOTE:
Note: the chunked implementation should still be considered experimental.
翻译一下就是说:目前,chunked 实现方式应被当做是 experimental。
experimental,放在句末,你就知道这是一个形容词了,什么意思呢?
四级词汇,如果不认识的话赶紧背一背哈,考试要考的。
作者说 chunked 实现方式还是实验阶段,肯定是有什么“暗坑”在里面的,不踩坑的最好方式,就是不用它。
然后,你看着看着会发现,这个数据结构,和 ConcurrentHashMap 好像啊。是的,有 Segment,有 bucket,有 entry,所以不要怀疑自己,确实很像。
接着,你看源码的时候,肯定是 Debug 的方式效率更高嘛。
当你 debug 的对象是 put 方法的时候,要不了几下你就能看看这个地方:
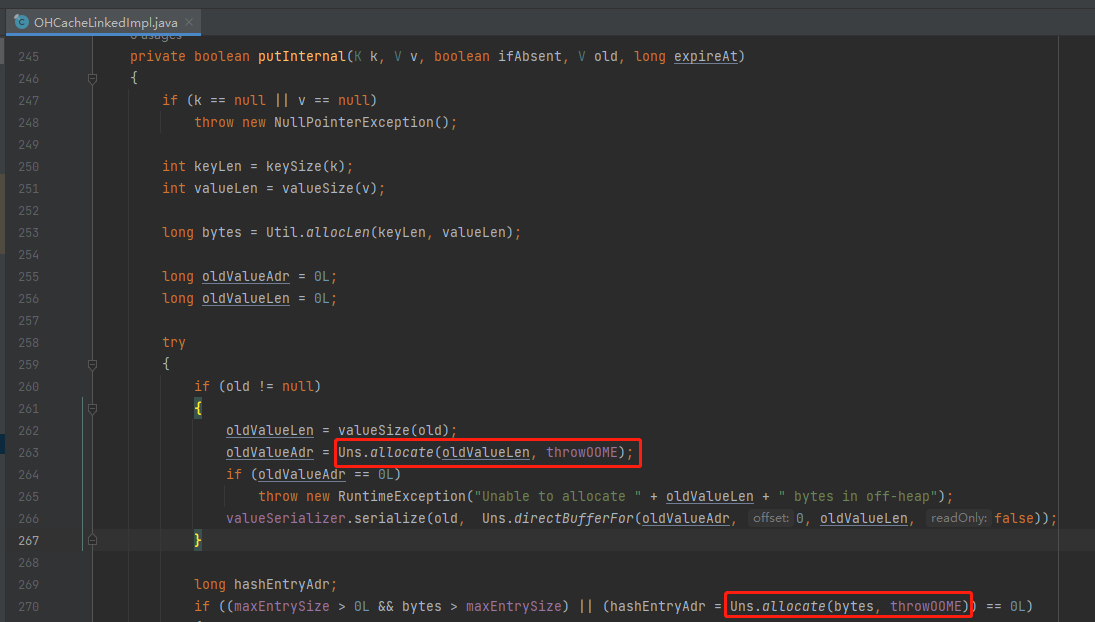
这个地方是申请堆外内存的操作,对应的是 IAllocator 这个接口:
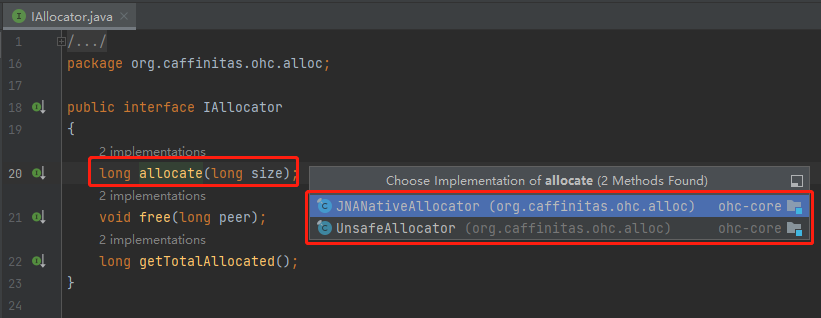
接口里面有三个方法:
allocate:申请内存 free:释放内存 getTotalAllocated:获取已申请内存(空方法,未实现)
主要关心前两个方法,因为我前面说了,这个是堆外内存,需要自己管理内存。管理就分为申请和释放,对应的就是这两个方法。
所以,这里可以说是整个 OHC 框架的核心。
带你盘一下这部分。

操作堆外内存
其实堆外内存这个东西,你一定是接触过的,只不过一般是框架封装好了,它是自己悄悄咪咪的使用,你没注意到而已罢了。
一般我们申请堆外内存,就会这样去写:

这个方法最终会调用 Unsafe 里面的 allocateMemory 这个 native 方法,它相当于 C++ 的 malloc 函数:
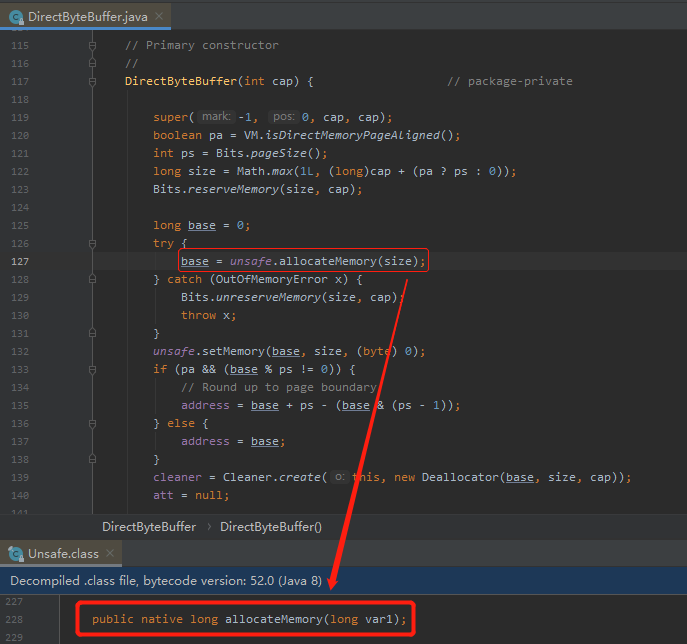
这个方法会为我们在操作系统的内存中去分配一个我们指定大小的内存供我们使用,这个内存就叫做堆外内存,不由 JVM 控制,即不在 gc 管理范围内的。
这个方法返回值是 long 类型数值,也就是申请的内存对应的首地址。
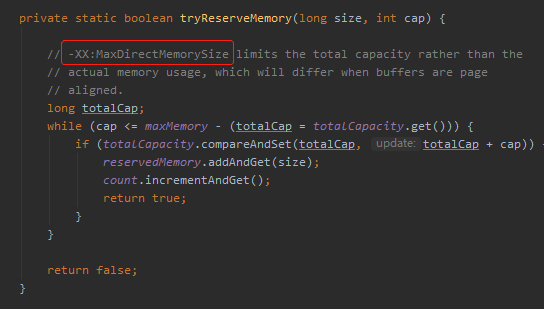
但是需要注意的是,JVM 有个叫做 -XX:MaxDirectMemorySize (最大堆外内存)的配置,如果使用 ByteBuffer.allocateDirect 申请堆外内存,大小会受到这个配置的限制,因为会调用这个方法:
OHC 要使用堆外内存,必然也是通过某个方法向操作系统申请了一部分内存,那么它申请内存的方法,是不是也是 allocateMemory 呢?
这个问题,在 github 上作者给出了否认三连:
不仅告诉了你没有使用,还告诉了你为什么没有使用:

首先,开头的这个玩意 “TL;DR” 就直接把我干懵逼了。然后我查了一下,原来是 “Too long; Don't read” 的缩写,直译过来的意思就是:太长了,读不下去。
但是我觉得结合语境分析,作者放在的意思应该是一种类似于“长话短说”的意思。
这个短语,一般用于在文章开头,先给出干货。

你看,又学一个小知识。
然后,我大概给你解释一下这一段 English 在说个什么意思。
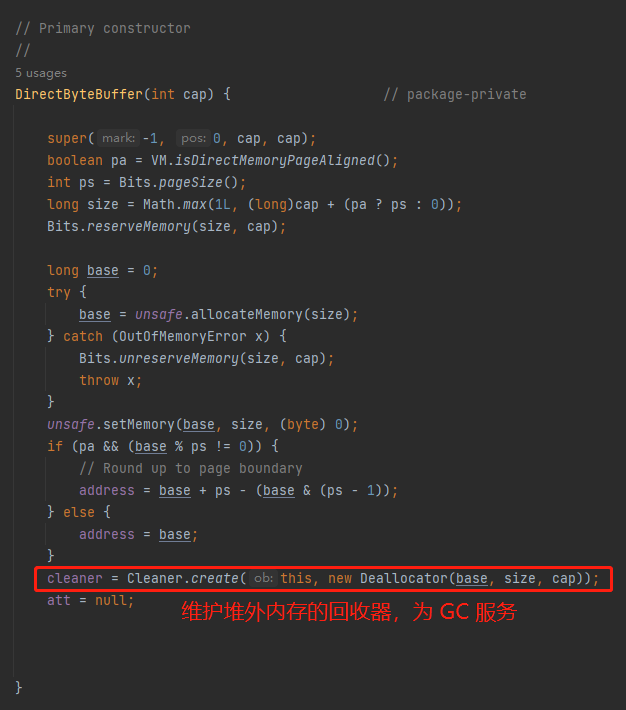
作者说,绕过 ByteBuffer.allocateDirect 方法,直接分配堆外内存,对 GC 来说是更加平稳的,因为我们可以明确控制内存分配,更重要的是可以由我们自己完全控制内存的释放。
如果使用 ByteBuffer.allocateDirect 方法,可能在垃圾回收期间,就释放了堆外内存。
这句话对应到代码中就是这里,而这样的操作,在 OHC 里面是不需要的。OHC 希望由框架自己来全权掌握什么时候应该释放:
然后作者接着说:此外,如果分配内存的时候,没有更多的堆外内存可以使用,它可能会触发一个 Full GC,如果多个申请内存的线程同时遇到这种情况,这是有问题的,因为这意味着大量 Full GC 的连续发生。
这句话对应的代码是这里:
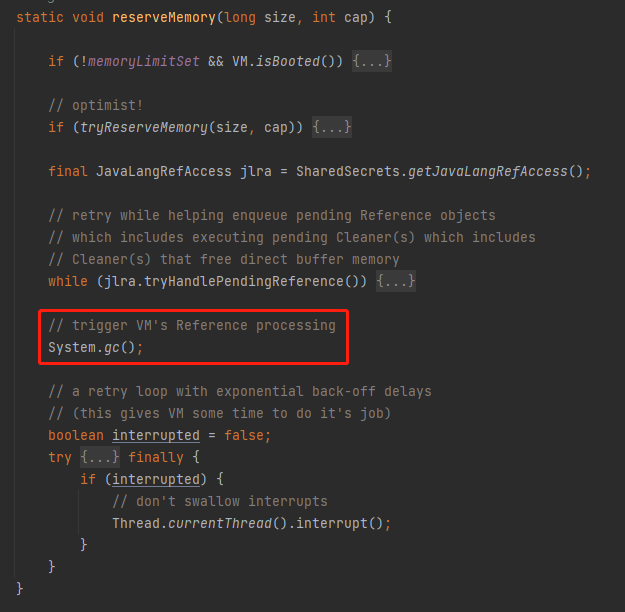
如果堆外内存不足的时候,会触发一次 Full GC。可以想象,在机器内存吃紧的时候,程序还在不停的申请堆外内存,继而导致 Full GC 的频繁出现,是一种什么样的“灾难性”的后果,基本上服务就处于不可用状态了。
OHC 需要避免这种情况的发生。
除了这两个原因之后,作者还说:
Further, the stock implementation uses a global, synchronized linked list to track off-heap memory allocations.
在 ByteBuffer.allocateDirect 方法的实现里面,还使用了一个全局的、同步的 linked List 这个数据结构来跟踪堆外内存的分配。
这里我不清楚它说的这个 “linked list” 对应具体是什么东西,所以我也不乱解释了,你要知道的话可以在评论区给我指个路,我也学习学习。
综上,作者最后一句说:这就是为什么 OHC 直接分配堆外内存的原因。
This is why OHC allocates off-heap memory directly。
然后他还提了一个建议:
and recommends to preload jemalloc on Linux systems to improve memory managment performance.
建议在 Linux 系统上预装 jemalloc 以提高内存管理性能。
弦外之音就是要拿它来替换 glibc 的 malloc 嘛,jemalloc 基本上是碾压 malloc。
关于 jemalloc 和 malloc 网上有很多相关的文章了,有兴趣的也可以去找找,我这里就不展开了。
现在我们知道 OHC 并没有使用常规的 ByteBuffer.allocateDirect 方法来完成堆外内存的申请,那么它是怎么实现这个“骚操作”的呢?
在 UnsafeAllocator 实现类里面是这样写的:
org.caffinitas.ohc.alloc.UnsafeAllocator
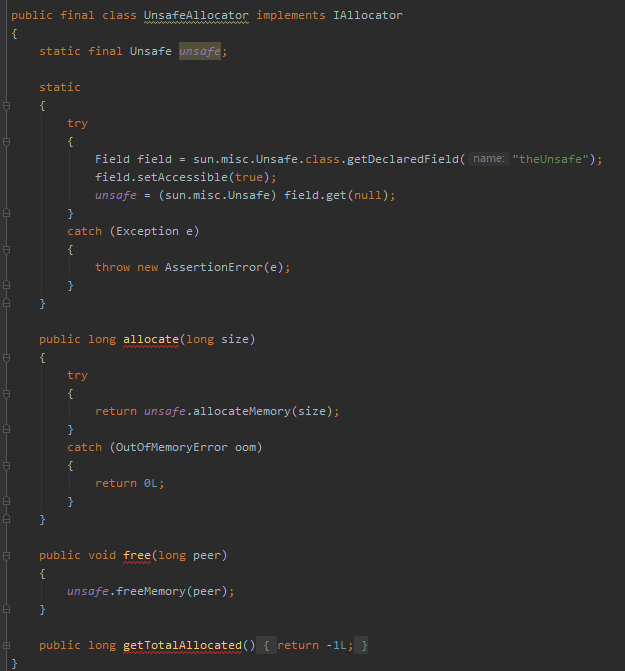
通过反射直接获取到 Unsafe 并进行操作,没有任何多余的代码。
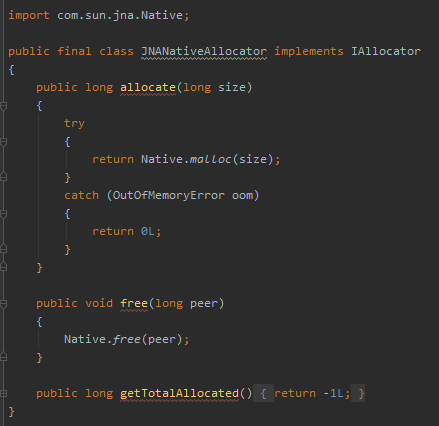
而在 JNANativeAllocator 实现类里面,则采用的是 JNA 的方式操作内存:
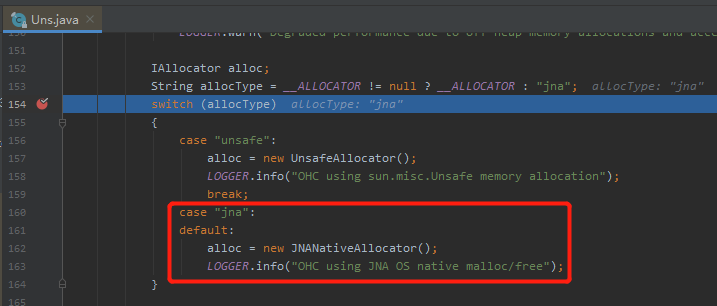
OHC 框架默认采用的是 JNA 的方式,这一点通过代码或者日志输出也能进行验证:
关于 Unsafe 和 JNA 这两种操作堆外内存的方式,到底谁更好,我在网上找到了这个链接:
https://mail.openjdk.org/pipermail/hotspot-dev/2015-February/017089.html
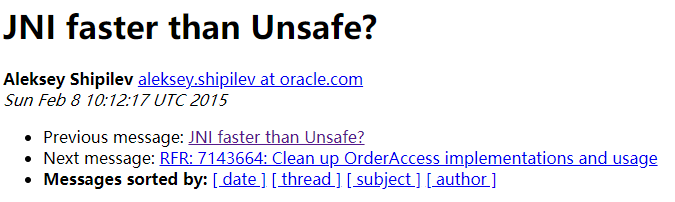
这封邮件的是 Aleksey Shipilev 针对一个叫做 Robert 的网友提出问题进行的回复。
问题是这样的,Robert 他用对 Native.malloc() 和 Unsafe.allocateMemory() 进行了基准测试,发现前者的性能是后者的三倍。想知道为什么:

然后 Aleksey Shipilev 针对这个问题进行了解析。
这哥们是谁?
他是基准测试的爸爸:
所以他的回答还是比较权威的,但是需要注意的是,他并没有正面说明两个方法岁更好,只是解释了为什么用 JMH 出现了性能差 3 倍这个现象。
另外,我必须得多说一句,通过反射拿 Unsafe 这段代码可是个好东西啊,建议熟读、理解、融会贯通:
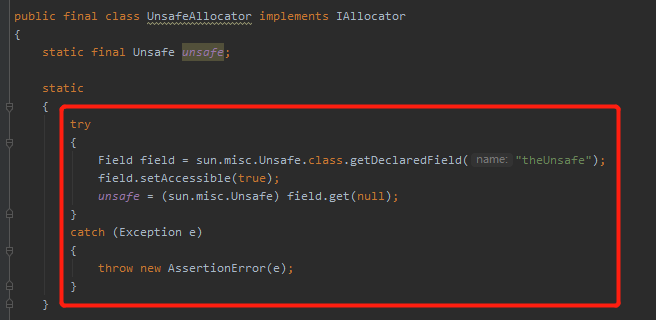
在 OHC 里面不就是一个非常好的例子嘛,虽然有现成的方法,但是和我的场景不是非常的匹配,我并不需要一些限制性的判断,只是想要简简单单的要一个堆外内存来用一用而已。
那我就绕过中间商,自己直接调用 Unsafe 里面的方法。
怎么拿到 Unsafe 呢?
就是前面这段代码,就是通过反射,你在其他的开源框架里面可以看到非常多类似的或者一模一样的代码片段。
背下来就完事。
好了,文章就到这里了,如果对你有一丝丝的帮助,帮我点个免费的赞,不过分吧?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号