我叫你不要重试,你非得重试。这下玩坏了吧?

批评一下
前几天和一个读者聊天,聊到了 Dubbo 。
他说他之前遇到了一个 Dubbo 的坑。
我问发生甚么事儿了?
然后他给我描述了一下前因后果,总结起来就八个字吧:超时之后,自动重试。
对此我就表达了两个观点。
读者对于使用框架的不熟悉,不知道 Dubbo 还有自动重试这回事。 是关于 Dubbo 这个自动重试功能,我觉得出发点很好,但是设计的不好。
第一个没啥说的,学艺不精,继续深造。
主要说说第二个。
有一说一,作为一个使用 Dubbo 多年的用户,根据我的使用经验我觉得 Dubbo 提供重试功能的想法是很好的,但是它错就错在不应该进行自动重试。
大部分情况下,我都会手动设置为 retries=0。
作为一个框架,当然可以要求使用者在充分了解相关特性的情况下再去使用,其中就包含需要了解它的自动重试的功能。
但是,是否需要进行重试,应该是由使用者自行决定的,框架或者工具类,不应该主动帮使用者去做这件事。
等等,这句话说的有点太绝对了。我改一下。

是否需要进行重试,应该是由使用者经过场景分析后自行决定的,框架或者工具类,不应该介入到业务层面,帮使用者去做这件事。
本文就拿出两个大家比较熟悉的例子,来进行一个简单的对比。
第一个例子就是 Dubbo 默认的集群容错策略 Failover Cluster,即失败自动切换。
第二个例子就是 apache 的 HttpClient。
一个是框架,一个是工具类,它们都支持重试,且都是默认开启了重试的。
但是从我的使用感受说来,Dubbo 的自动重试介入到了业务中,对于使用者是有感知的。HttpClient 的自动重试是网络层面的,对于使用者是无感知的。
但是,必须要再次强调的一点是:
Dubbo 在官网上声明的清清楚楚的,默认自动重试,通常用于读操作。
如果你使用不当导致数据错误,这事你不能怪官方,只能说这个设计有利有弊。

Dubbo重试几次
都说 Dubbo 会自动重试,那么是重试几次呢?
先直接看个例子,演示一下。
首先看看接口定义:
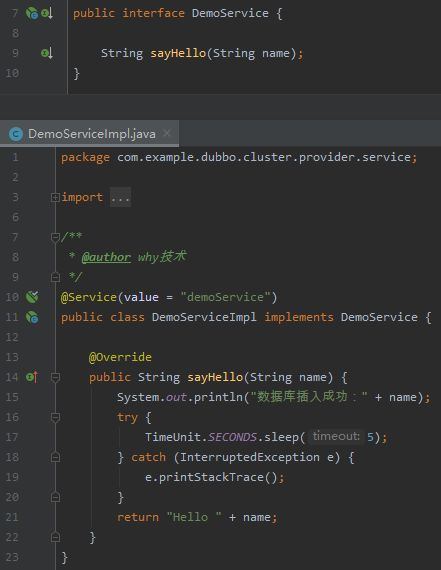
可以看到在接口实现里面,我睡眠了 5s ,目的是模拟接口超时的情况。
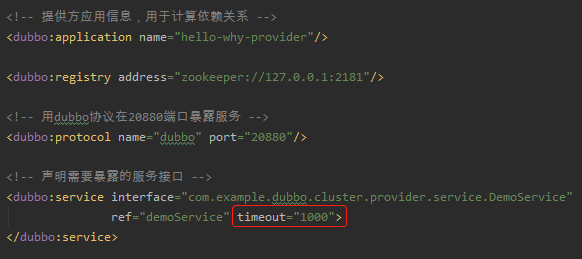
服务端的 xml 文件里面是这样配置的,超时时间设置为了 1000ms:
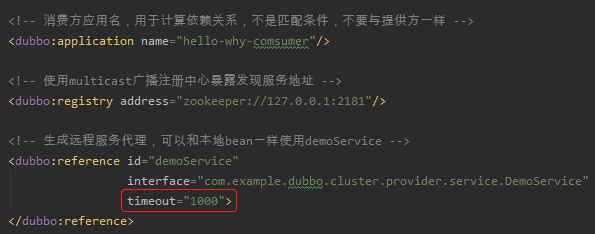
客户端的 xml 文件是这样配置的,超时时间也设置为了 1000ms:
然后我们在单元测试里面模拟远程调用一次:
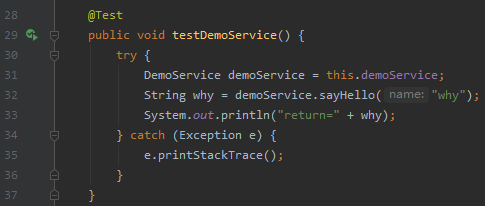
这就是一个原生态的 Dubbo Demo 项目。由于我们超时时间是 1000ms,即 1s,但接口处理需要 5s,所以调用必定会超时。
那么 Dubbo 默认的集群容错策略(Failover Cluster),到底会重试几次,跑一下测试用例,一眼就能看出来:

你看这个测试用例的时间,跑了 3 s 226 ms,你先记住这个时间,我等下再说。
我们先关注重试次数。
有点看不太清楚,我把关键日志单独拿出来给大家看看:

从日志可以出,客户端重试了 3 次。最后一次重试的开始时间是:2020-12-11 22:41:05.094。
我们看看服务端的输出:
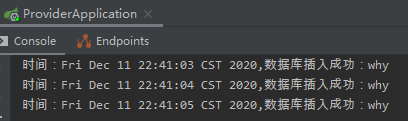
我就调用一次,这里数据库插入三次。凉凉。

而且你关注一下请求时间,每隔 1s 来一个请求。
我这里一直强调时间是为什么呢?
因为这里有一个知识点:1000ms 的超时时间,是一次调用的时间,而不是整个重试请求(三次)的时间。
之前面试的时候,有人问过我这个关于时间的问题。所以我就单独写一下。
然后我们把客户端的 xml 文件改造一下,指定 retries=0:
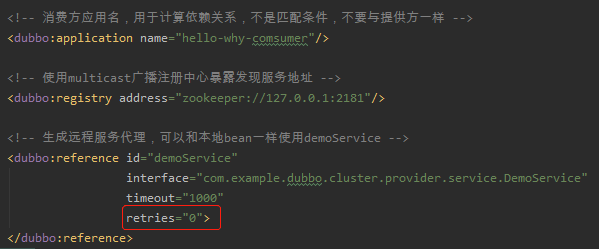
再次调用:

可以看到,只进行了一次调用。
到这里,我们还是把 Dubbo 当个黑盒在用。测试出来了它的自动重试次数是 3 次,可以通过 retries 参数进行指定。
接下来,我们扒一扒源码。
FailoverCluster源码
源码位于org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker中:
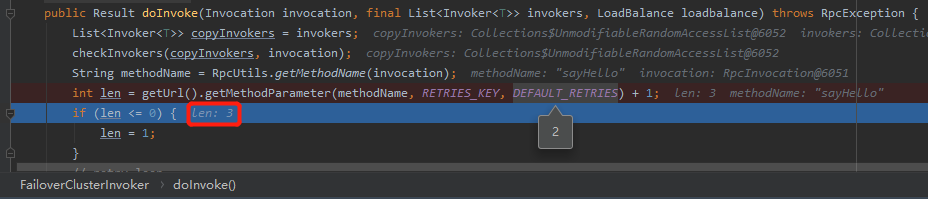
通过源码,我们可以知道默认的重试次数是2次:
等等,不对啊,前面刚刚说的是 3 次,怎么一转眼就是 2 次了呢?
你别急啊。

你看第 61 行的最后还有一个 "+1" 呢?
你想一想。我们想要在接口调用失败后,重试 n 次,这个 n 就是 DEFAULT_RETRIES ,默认为 2 。那么我们总的调用次数就是 n+1 次了。
所以这个 "+1" 是这样来的,很小的一个知识点,送给大家。
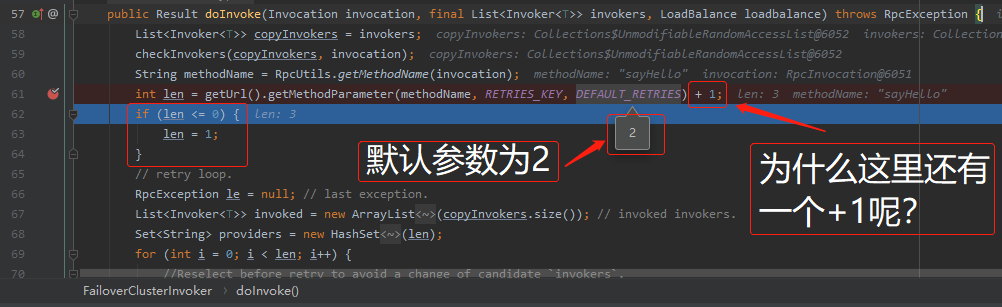
另外图中标记了红色五角星★的地方,第62到64行。也是很关键的地方。对于 retries 参数,在官网上的描述是这样的:
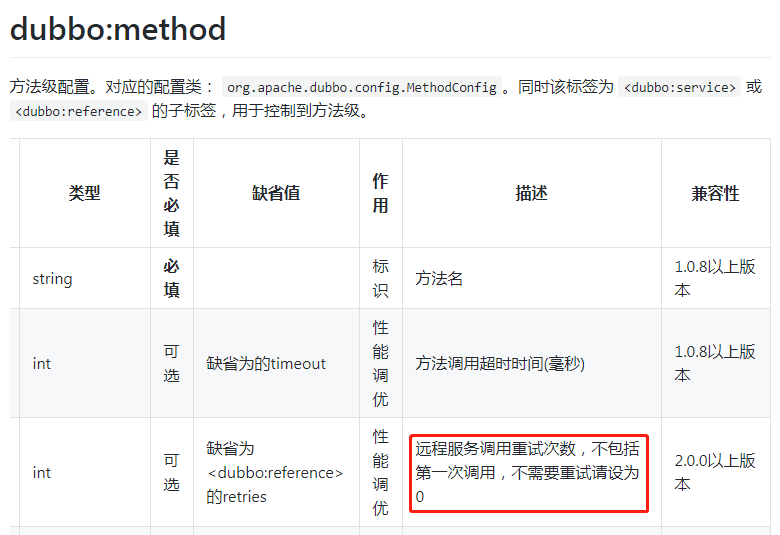
不需要重试,请设为 0 。我们前面分析了,当设置为 0 的时候,只会调用一次。
但是我也看见过retries配置为 -1 的。-1+1=0。调用0次明显是一个错误的含义。但是程序也正常运行,且只调用一次。
这就是标记了红色五角星的地方的功劳了。
防御性编程。哪怕你设置为 -10000 也只会调用一次。
下面这个图片是我对 doInvoke 方法进行一个全面的解读,基本上每一行主要的代码都加了注释,可以点开大图查看:
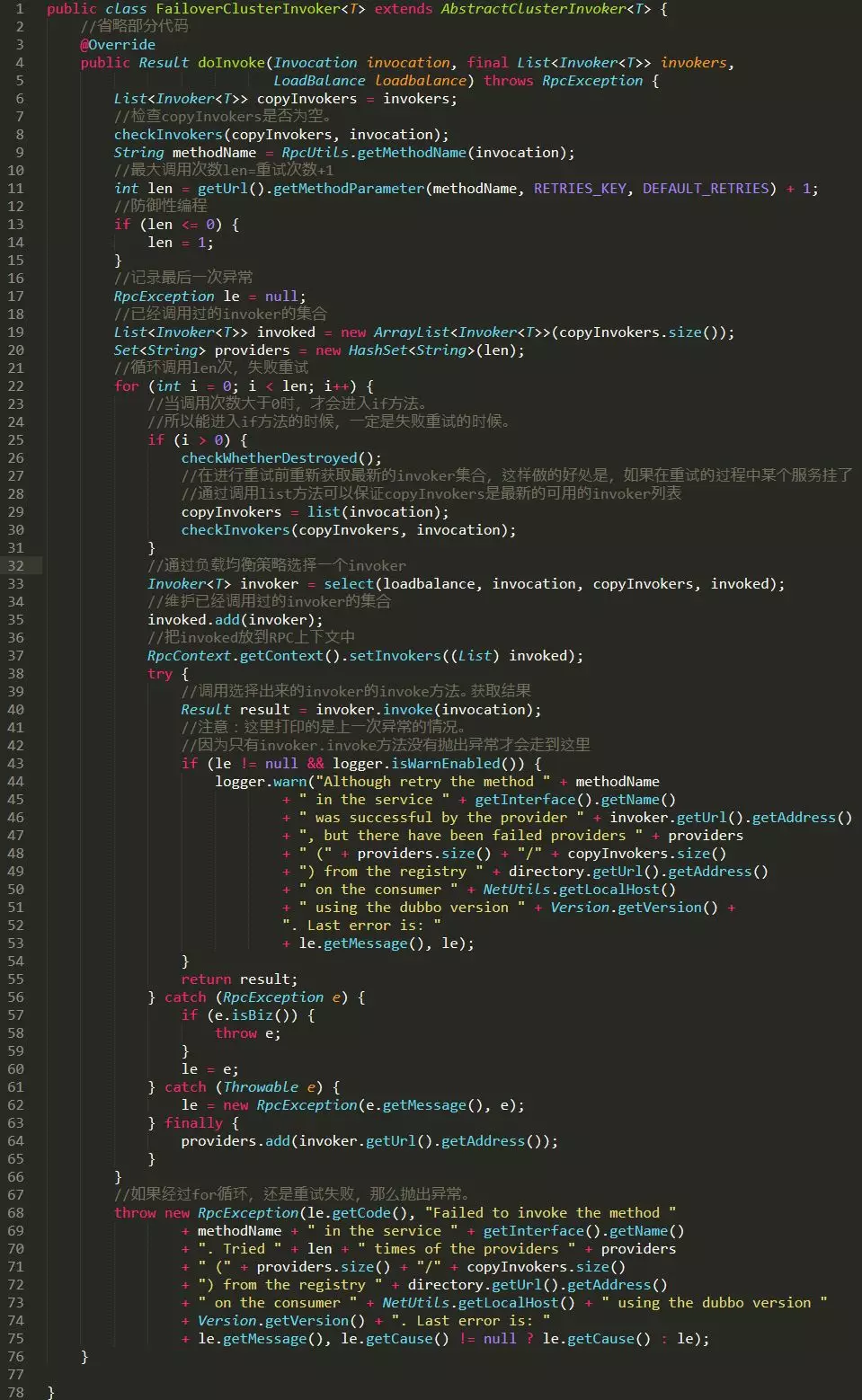
如上所示,FailoverClusterInvoker 的 doInvoke 方法主要的工作流程是:
首先是获取重试次数,然后根据重试次数进行循环调用,在循环体内,如果失败,则进行重试。 在循环体内,首先是调用父类 AbstractClusterInvoker 的 select 方法,通过负载均衡组件选择一个 Invoker,然后再通过这个 Invoker 的 invoke 方法进行远程调用。 如果失败了,记录下异常,并进行重试。
注意一个细节:在进行重试前,重新获取最新的 invoker 集合,这样做的好处是,如果在重试的过程中某个服务挂了,可以通过调用 list 方法保证 copyInvokers 是最新的可用的 invoker 列表。
整个流程大致如此,不是很难理解。
HttpClient 使用样例
接下来,我们看看 apache 的 HttpClients 中的重试是怎么回事。
也就是这个类:org.apache.http.impl.client.HttpClients。
首先,废话少说,弄个 Demo 跑一下。
先看 Controller 的逻辑:
@RestController
public class TestController {
@PostMapping(value = "/testRetry")
public void testRetry() {
try {
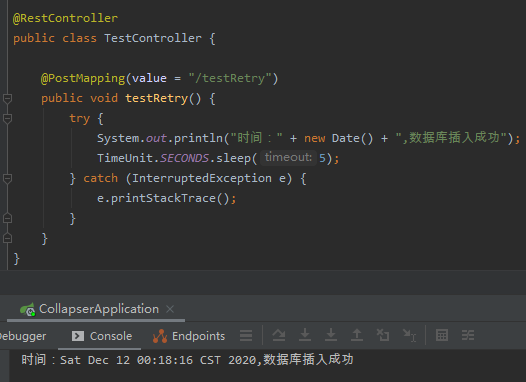
System.out.println("时间:" + new Date() + ",数据库插入成功");
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
同样是睡眠 5s,模拟超时的情况。
HttpUtils 封装如下:
public class HttpPostUtils {
public static String retryPostJson(String uri) throws Exception {
HttpPost post = new HttpPost(uri);
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(1000)
.setConnectionRequestTimeout(1000)
.setSocketTimeout(1000).build();
post.setConfig(config);
String responseContent = null;
CloseableHttpResponse response = null;
CloseableHttpClient client = null;
try {
client = HttpClients.custom().build();
response = client.execute(post, HttpClientContext.create());
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
responseContent = EntityUtils.toString(response.getEntity(), Consts.UTF_8.name());
}
} finally {
if (response != null) {
response.close();
}
if (client != null){
client.close();
}
}
return responseContent;
}
}
先解释一下其中的三个设置为 1000ms 的参数:
connectTimeout:客户端和服务器建立连接的timeout
connectionRequestTimeout:从连接池获取连接的timeout
socketTimeout:客户端从服务器读取数据的timeout
大家都知道一次http请求,抽象来看,必定会有三个阶段
一:建立连接 二:数据传送 三:断开连接
当建立连接的操作,在规定的时间内(ConnectionTimeOut )没有完成,那么此次连接就宣告失败,抛出 ConnectTimeoutException。
后续的 SocketTimeOutException 就一定不会发生。
当连接建立起来后,才会开始进行数据传输,如果数据在规定的时间内(SocketTimeOut)沒有传输完成,则抛出 SocketTimeOutException。如果传输完成,则断开连接。
测试 Main 方法代码如下:
public class MainTest {
public static void main(String[] args) {
try {
String returnStr = HttpPostUtils.retryPostJson("http://127.0.0.1:8080/testRetry/");
System.out.println("returnStr = " + returnStr);
} catch (Exception e) {
e.printStackTrace();
}
}
}
首先我们不启动服务,那么根据刚刚的分析,客户端和服务器建立连接会超时,则抛出 ConnectTimeoutException 异常。
直接执行 main 方法,结果如下:
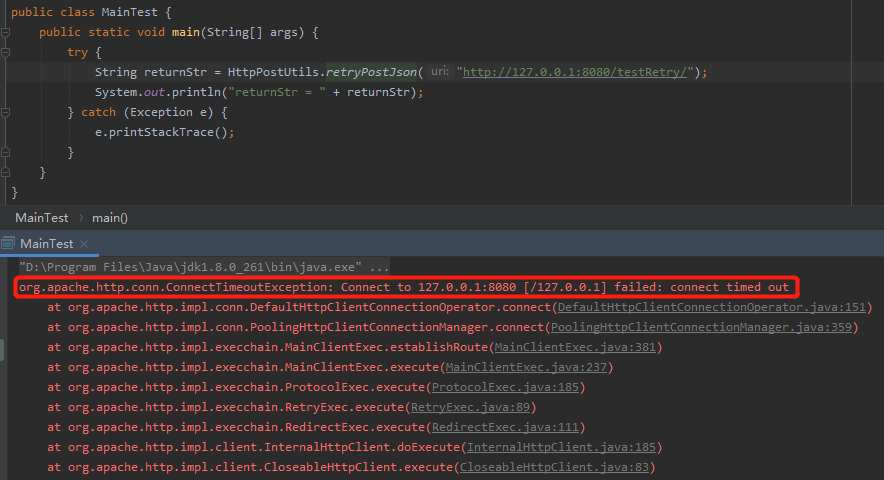
符合我们的预期。
现在我们把 Controller 接口启动起来。
由于我们的 socketTimeout 设置的时间是 1000ms,而接口里面进行了 5s 的睡眠。
根据刚刚的分析,客户端从服务器读取数据肯定会超时,则抛出 SocketTimeOutException 异常。
Controller 接口启动起来后,我们运行 main 方法输出如下:
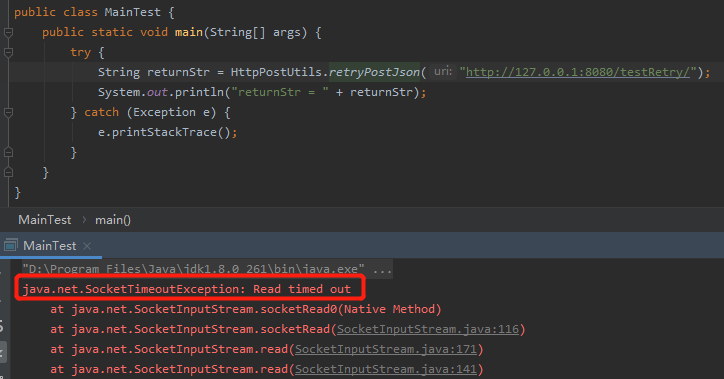
这个时候,其实接口是调用成功了,只是客户端没有拿到返回。
这个情况和我们前面说的 Dubbo 的情况一样,超时是针对客户端的。
即使客户端超时了,服务端的逻辑还是会继续执行,把此次请求处理完成。
执行结果确实抛出了 SocketTimeOutException 异常,符合预期。
但是,说好的重试呢?
HttpClient 的重试
在 HttpClients 里面,其实也是有重试的功能,且和 Dubbo 一样,默认是开启的。
但是我们这里为什么两种异常都没有进行重试呢?
如果它可以重试,那么默认重试几次呢?
我们带着疑问,还是去源码中找找答案。
答案就藏在这个源码中,org.apache.http.impl.client.DefaultHttpRequestRetryHandler。
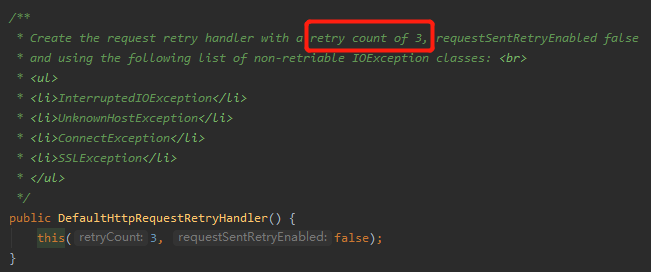
DefaultHttpRequestRetryHandler 是 Apache HttpClients 的默认重试策略。
从它的构造方法可以看出,其默认重试 3 次:
该构造方法的 this 调用的是这个方法:
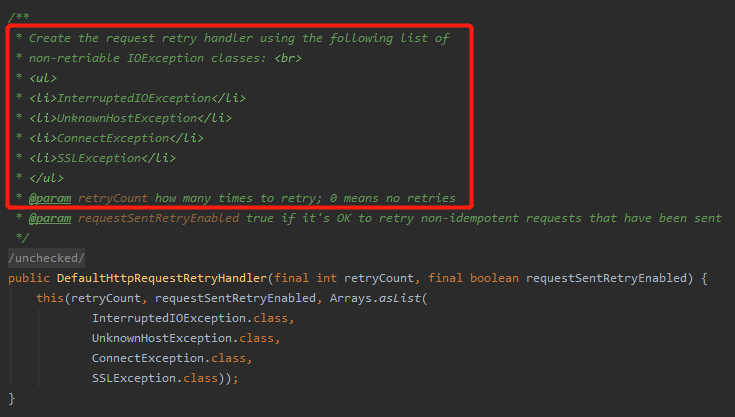
从该构造方法的注释和代码可以看出,对于这四类异常是不会进行重试的:
一:InterruptedIOException 二:UnknownHostException 三:ConnectException 四:SSLException
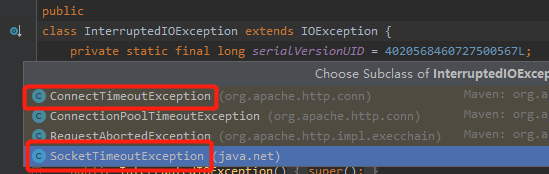
而我们前面说的 ConnectTimeoutException 和 SocketTimeOutException 都是继承自 InterruptedIOException 的:
我们关闭 Controller 接口,然后打上断点看一下:
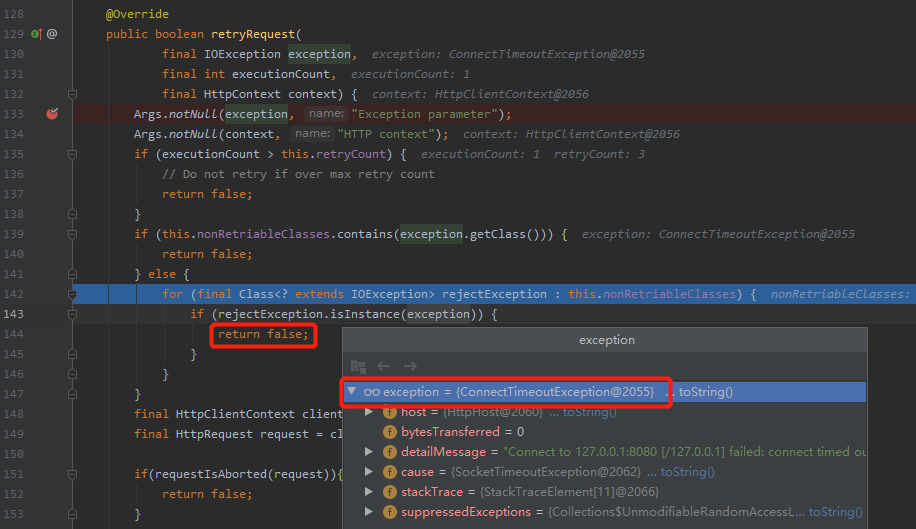
可以看到,经过 if 判断,会返回 false ,则不会发起重试。
为了模拟重试的情况,我们就得改造一下 HttpPostUtils ,来一个自定义 HttpRequestRetryHandler:
public class HttpPostUtils {
public static String retryPostJson(String uri) throws Exception {
HttpRequestRetryHandler httpRequestRetryHandler = new HttpRequestRetryHandler() {
@Override
public boolean retryRequest(IOException exception, int executionCount, HttpContext context) {
System.out.println("开始第" + executionCount + "次重试!");
if (executionCount > 3) {
System.out.println("重试次数大于3次,不再重试");
return false;
}
if (exception instanceof ConnectTimeoutException) {
System.out.println("连接超时,准备进行重新请求....");
return true;
}
HttpClientContext clientContext = HttpClientContext.adapt(context);
HttpRequest request = clientContext.getRequest();
boolean idempotent = !(request instanceof HttpEntityEnclosingRequest);
if (idempotent) {
return true;
}
return false;
}
};
HttpPost post = new HttpPost(uri);
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(1000)
.setConnectionRequestTimeout(1000)
.setSocketTimeout(1000).build();
post.setConfig(config);
String responseContent = null;
CloseableHttpResponse response = null;
CloseableHttpClient client = null;
try {
client = HttpClients.custom().setRetryHandler(httpRequestRetryHandler).build();
response = client.execute(post, HttpClientContext.create());
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
responseContent = EntityUtils.toString(response.getEntity(), Consts.UTF_8.name());
}
} finally {
if (response != null) {
response.close();
}
if (client != null) {
client.close();
}
}
return responseContent;
}
}
在我们的自定义 HttpRequestRetryHandler 里面,对于 ConnectTimeoutException ,我进行了放行,让请求可以重试。
当我们不启动 Controller 接口时,程序会自动重试 3 次:
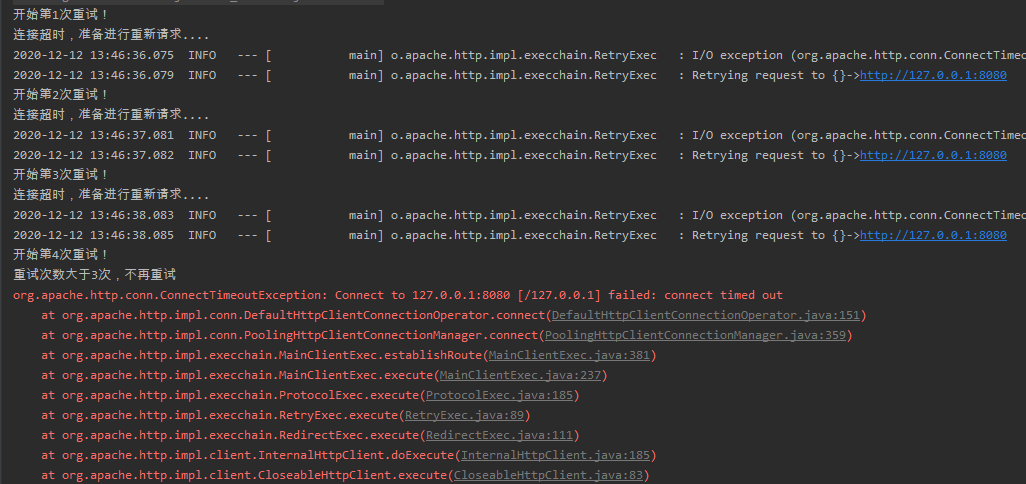
上面给大家演示了 Apache HttpClients 的默认重试策略。上面的代码大家可以直接拿出来运行一下。
如果想知道整个调用流程,可以在 debug 的模式下看调用链路:
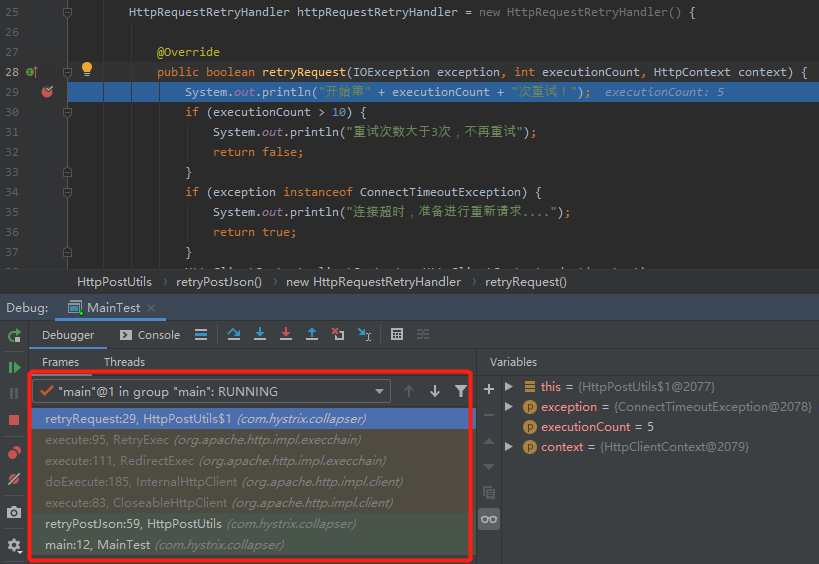
HttpClients 的自动重试,同样是默认开启的,但是我们在使用过程中是无感知的。
因为它的重试条件也是比较苛刻的,针对网络层面的重试,没有侵入到业务中。
谨慎谨慎再谨慎。
对于需要重试的功能,我们在开发过程中一定要谨慎谨慎再谨慎。

比如 Dubbo 的默认重试,我觉得它的出发点是为了保证服务的高可用。
正常来说我们的微服务至少都有两个节点。当其中一个节点不提供服务的时候,集群容错策略就会去自动重试另外一台。
但是对于服务调用超时的情况,Dubbo 也认为是需要重试的,这就相当于侵入到业务里面了。
前面我们说了服务调用超时是针对客户端的。即使客户端调用超时了,服务端还是在正常执行这次请求。
所以官方文档中才说“通常用于读操作”:
http://dubbo.apache.org/zh/docs/v2.7/user/examples/fault-tolerent-strategy/

读操作,含义是默认幂等。所以,当你的接口方法不是幂等时请记得设置 retries=0。
这个东西,我给你举一个实际的场景。
假设你去调用了微信支付接口,但是调用超时了。
这个时候你怎么办?
直接重试?请你回去等通知吧。
肯定是调用查询接口,判断当前这个请求对方是否收到了呀,从而进行进一步的操作吧。
对于 HttpClients,它的自动重试没有侵入到业务之中,而是在网络层面。
所以绝大部分情况下,我们系统对于它的自动重试是无感的。
甚至需要我们在程序里面去实现自动重试的功能。
由于你的改造是在最底层的 HttpClients 方法,这个时候你要注意的一个点:你要分辨出来,这个请求异常后是否支持重试。
不能直接无脑重试。
对于重试的框架,大家可以去了解一下 Guava-Retry 和 Spring-Retry。
奇闻异事
我知道大家最喜欢的就是这个环节了。

看一下 FailoverClusterInvoker 的提交记录:
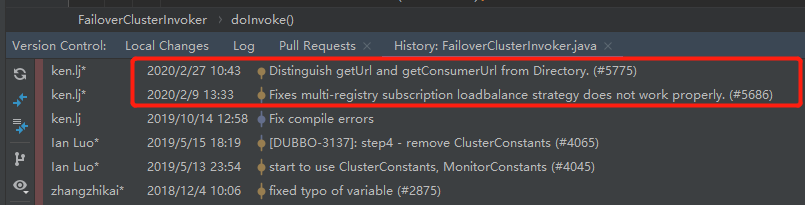
2020 年提交了两次。时间间隔还挺短的。
2 月 9 日的提交,是针对编号为 5686 的 issue 进行的修复。
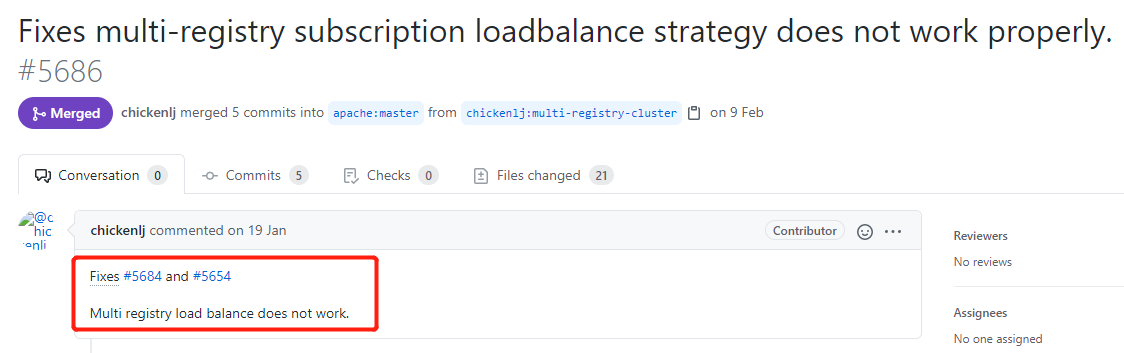
而在这个 issue 里面,针对编号为 5684 和 5654 进行了修复:
https://github.com/apache/dubbo/issues/5654
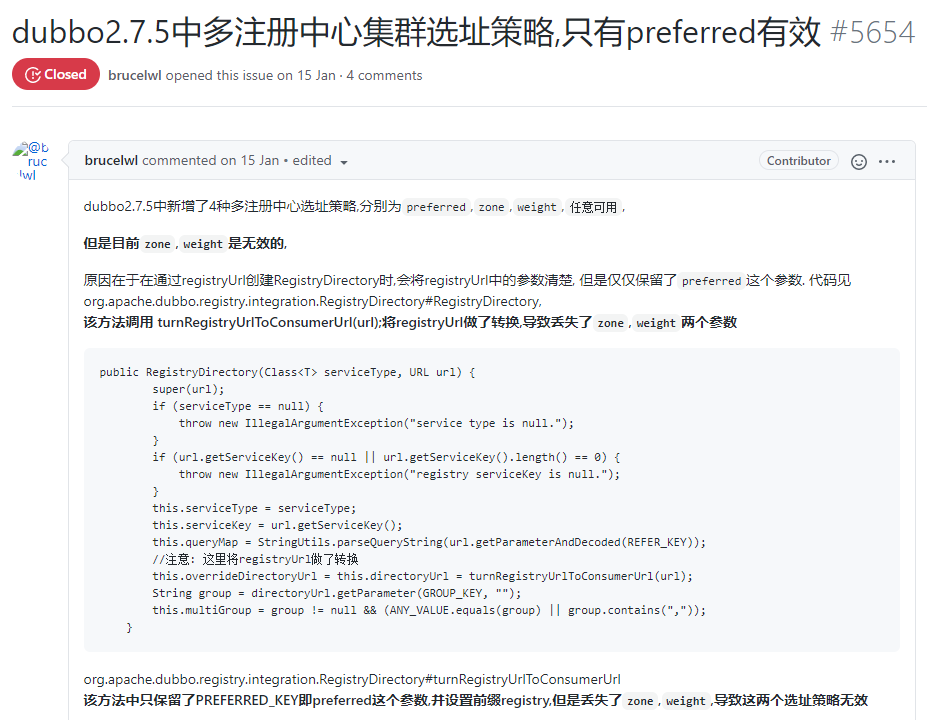
它们都指向了一个问题:
多注册中心的负载均衡不生效。
官方对这个问题修复了之后,马上就带来另外一个大问题:
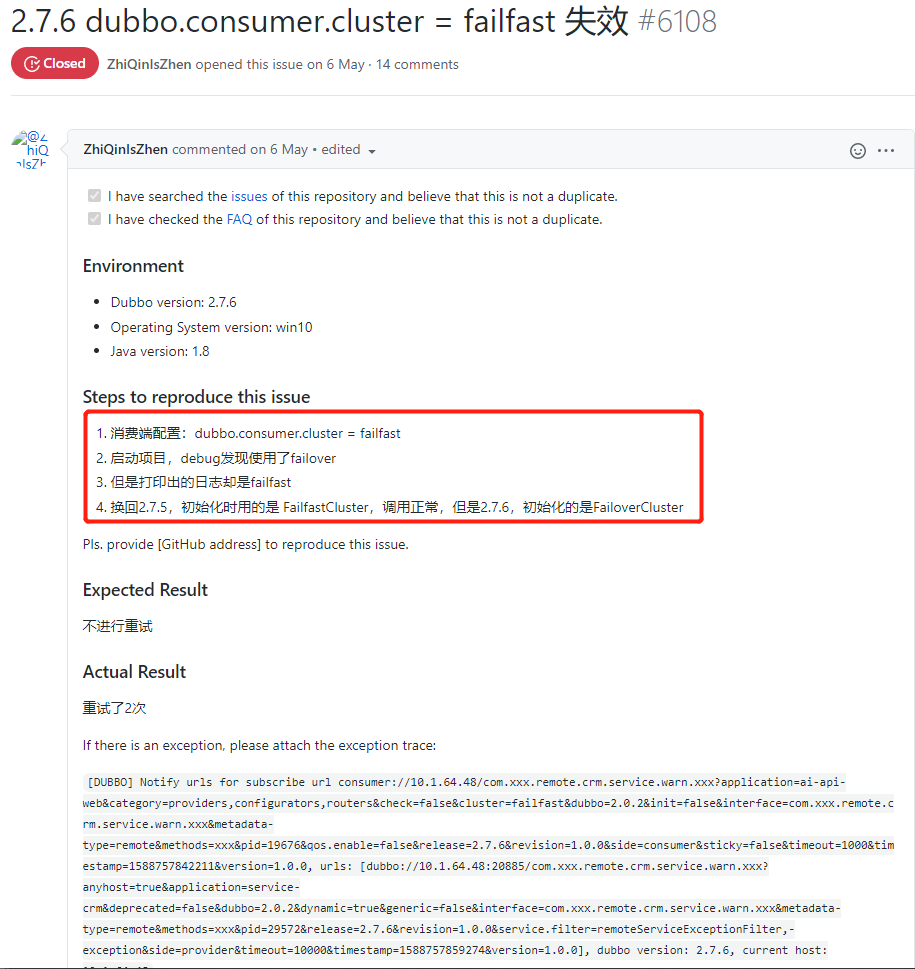
2.7.6 版本里面 failfast 负载均衡策略失效了。
你想,我知道我一个接口不能失败重试,所以我故意改成了 failfast 策略。
但是实际框架用的还是 failover,进行了重试 2 次?

而实际情况更加糟糕, 2.7.6 版本里面负载均衡策略只支持 failover 了。
这玩意就有点坑了。
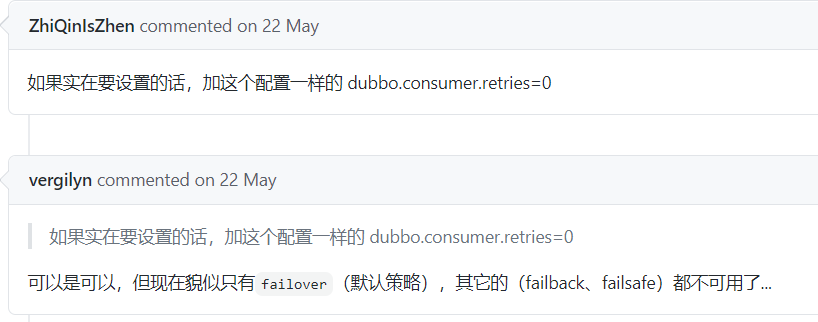
而这个 bug 一直到 2.7.8 版本才修复好。
所以,如果你使用的 Dubbo 版本是 2.7.5 或者 2.7.6 版本。一定要注意一下,是否用了其他的集群容错策略。如果用了,实际上是没有生效的。
可以说,这确实是一个比较大的 bug。
但是开源项目,共同维护。
我们当然知道 Dubbo 不是一个完美的框架,但我们也知道,它的背后有一群知道它不完美,但是仍然不言乏力、不言放弃的工程师。
他们在努力改造它,让它趋于完美。
我们作为使用者,我们少一点"吐槽",多一点鼓励,提出实质性的建议。
只有这样我才能骄傲的说,我们为开源世界贡献了一点点的力量,我们相信它的明天会更好。
向开源致敬,向开源工程师致敬。
总之,牛逼。
好了,这次的文章就到这里了。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以提出来,我对其加以修改。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。
我是 why,一个被代码耽误的文学创作者,一个又暖又有料的四川好男人。
还有,欢迎关注我呀。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号