缓存 缓存驱逐策略总结
前言
缓存是提升性能的通用方法,现在大多数的缓存实现都使用了经典的技术。当读多写少的情况时,通常会使用缓存来提升获取数据的性能。使用缓存的方式大概有Reids、MemoryCahce、Memcached、Dictionary等等方式来实现自己的缓存,使用缓存时可能考虑最多的时如何存储数据,而不是考虑如何淘汰数据,一般希望缓存可以命中所有的请求,在必要时候再请求底层数据,来提高性能。但是缓存数据也有存储成本,如果存储所有数据,需要在存储上付出很多成本。
在操作系统,数据库等领域中,我们会经常使用到驱逐策略算法(换出调度算法)来实现数据页面在主存与磁盘之间频繁的交换。CPU L1,L2......缓存中简述了缓存淘汰策略。本篇详细讨论一下各个驱逐策略。大概总结了如下几种驱逐策略:
- FIFO 先进先出策略,最先进入的数据,优先淘汰
- LRU 最久未使用策略,最久未使用的的数据,优先淘汰
- LFU (最不常用的)最久使用次数最少的数据,优先淘汰
Two-Queue/N-Queue概念的淘汰策略
- ARC 二级淘汰策略,结合LRU和LFU策略淘汰数据
- LIRS 在LRU的基础上添加了IRR和R记录之前和之后的访问间隔,使用LIR和HIR做淘汰策略
- W-TinyLFU 使用多个Queue实现淘汰策略
技术探索
FIFO 先进先出
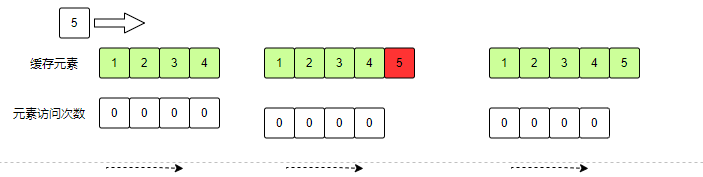
简述:当缓存溢出时,优先淘汰先进入的数据
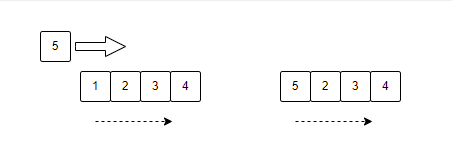
上述图例说明:
有一个容量为4的缓存,依次存入:1,2,3,4。当存入5时目前已经没有空间,在FIFO的策略下,优先淘汰1,然后将5存储到1的位置上。(一般使用环状数组实现FIFO)
优点
集中一个数据访问时,可以通过缓存获取到数据,可以应对同一个数据出现高峰时返回缓存数据
缺点
当数据量大于内存容量一定比例之后,数据的访问不会命中缓存。
LRU
简述:最久未使用的数据优先淘汰。核心思想是最近访问的元素,很有可能是目前最想访问的元素,也有可能是未来一直会访问的元素

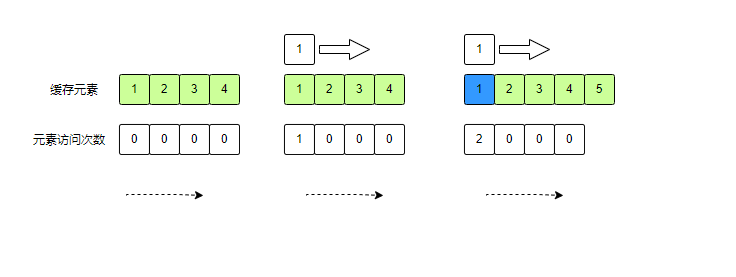
图列说明:
有一个容量为4的缓存,依次存入:1,2,3,4。图1为再次访问数据1的元素时,会将访问的元素重置为内存第一个元素,也就意味着最晚淘汰
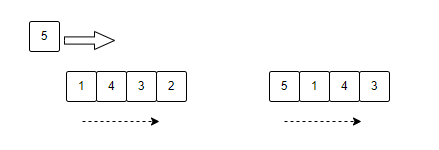
图列说明:
将数据5存入内存时,缓存溢出,优先淘汰最久未使用的元素2。
优点
存储热点数据,例如热搜等等
缺点
因为访问一次就会认为是“新鲜”的数据,在有偶发热点数据时会将历史热点数据淘汰掉,导致缓存一直在淘汰数据。
LFU
简述:最近使用频率高的数据很大概率将会再次被使用,而最近使用频率低的数据,很大概率不会再使用。
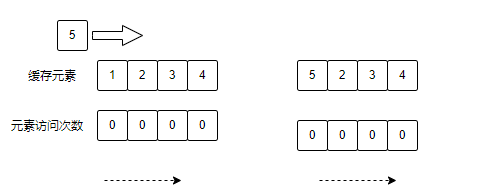
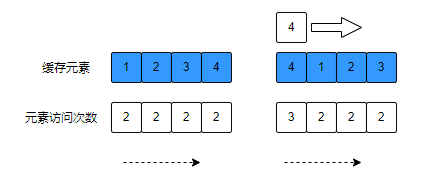
图列说明:
当元素5存入缓存时,当前缓存溢出,淘汰元素1,淘汰数据算法是:优点淘汰访问次数较低的元素,访问次数一致的,优先淘汰最久未访问过的。
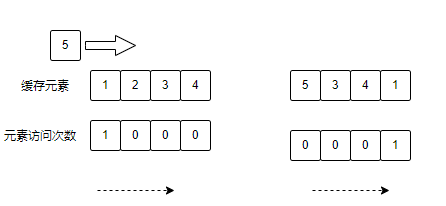
图列说明:
当元素5存入缓存时,当前缓存溢出,淘汰元素2,淘汰数据算法是:优点淘汰访问次数较低的元素,访问次数一致的,优先淘汰最久未访问过的。元素1访问次数为1,所以不能被淘汰
ARC
简述:当时访问的数据趋向于访问最近的内容,会更多地命中LRU list,这样会增大LRU的空间; 当系统趋向于访问最频繁的内容,会更多地命中LFU list,这样会增加LFU的空间。
图列说明:首先进入缓存的数据存储在LRUList中,当缓存溢出时,优先将存入的数据放入到LRU ghost List,然后LURList扩容,将新数据放到LRU第一个元素,LRU List和LFU List 共用一个空间,只是内部进行了区分,LUR List扩容之后意味着LFU List会缩小。这就是所谓的动态调整。
图列说明:第一次访问元素1,记录已存在元素的访问次数,第二次访问元素1,访问次数到达2,会进入LFU List。
图例说明:所有元素都在LFU List中,再次访问LFU中的元素时,优先将访问的元素放到LFU List中,这样可以实现热点数据一直存在于缓存中。
优点
支持各种突发和偶发的数据操作
缺点
使用Two Queue实现,实现难度比较高,IBM发明使用。
LIRS
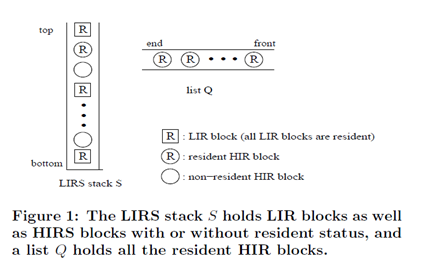
简述:LIRS 算法全称 Low Inter-reference Recency Set,LIRS 使用 IRR(Inter-Reference Recency)来表示记录数据块访问历史信息,IRR 表示最近连续访问同一个数据块之间访问其他不同数据块非重复个数
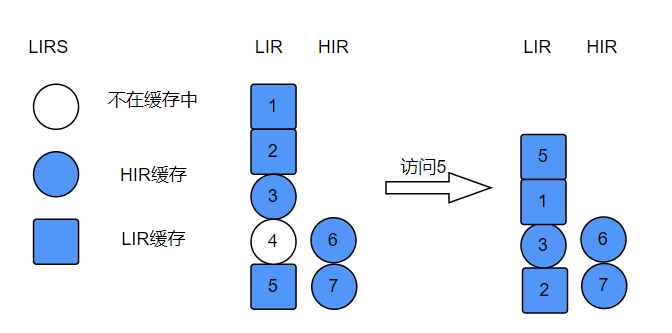
图例说明:
- LIRS 有两个队列,LIR说明recency值小,也就是访问频率较高,HIR说明recency比LIR的都大。
- 访问元素5,将5置为LIR栈顶,说明5的访问频率更高。
- 移除不在缓存中的元素4。
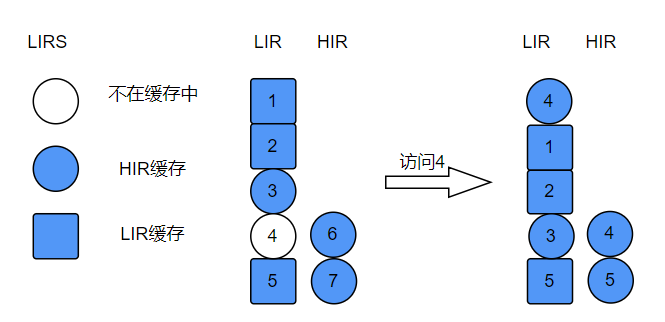
图例说明:访问存在于LIR中的失效缓存元素
- 将不存在元素置为HIR元素,放入HIR栈顶,移除HIR栈位元素,此元素在LIR中不存在,直接移除
- 将新HIR元素放入LIR栈顶
总结:LIRS中使用IRR和R记录当前数据的访问次数和访问之间的间隔,判断是否为经常使用的元素,使用Stack和Queue结合缓存元素,几乎所有元素都在缓存中,只不过有失效元素,这是因为需要计算元素访问间隔。上述图例并未全面列出LIRS的数据操作,感兴趣的小伙伴可以一一推导。
优点
在LRU的基础上考虑了支持突发冷数据的影响,设计理念为缓存中的数据一定存在
缺点
占用空间较大,实现算法复杂,需要考虑各种状态。
W-TinyLFU
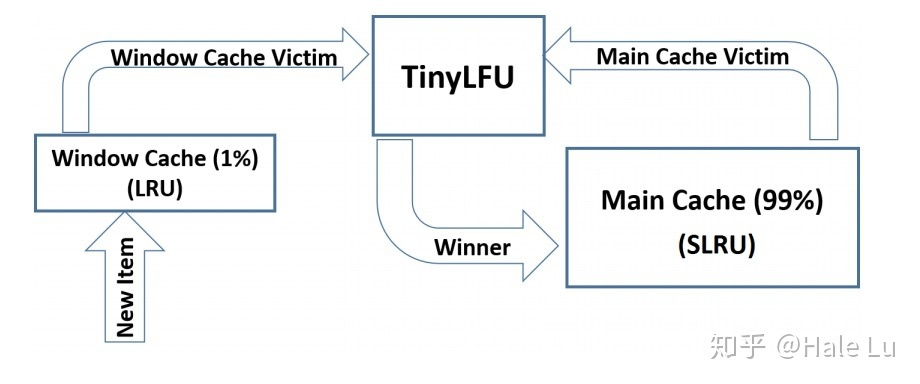
简介:内部分三个队列:windowLRU,probationLru,protectedLru,首先进入缓存的数据,进入windowLRU,当windowLRU溢出时选出首个元素叫做candidate,获取probationLru首个元素叫做victim,两个元素做比较,淘汰使用次数少的元素,两个元素使用次数一致时,随机将一个元素淘汰。当probationLru中的数据访问次数到达一定指标之后会晋升到protectedLru队列中。
优点
三阶段,支持突发数据缓存和历史数据缓存,提高命中率
缺点
实现复杂度较高,对基础知识要求高。
实战
BitFaster.Caching:https://github.com/bitfaster/BitFaster.Caching
简介:。NET 高性能,线程安全内存缓存,其中实现了LRU和LFU的缓存策略
- BitFaster.Caching.Lfu
- 使用ConcurrentDictionary + TU-Q 实现,类似于2Q
- 没有全局锁,没有后台线程,高性能
int capacity = 666; var lru = new ConcurrentLru<string, SomeItem>(capacity); var value = lru.GetOrAdd("key", (key) => new SomeItem(key));
- BitFaster.Caching.Lru
- 使用ConcurrentDictionary + W-TinyLFU 驱逐策略
- 异步计算W-TinyLFU中的windowLRU队列、probationLru队列、protectedLru队列中的数据
- 拥有极佳的命中率
int capacity = 666; var lfu = new ConcurrentLfu<string, SomeItem>(capacity); var value = lfu.GetOrAdd("key", (key) => new SomeItem(key));
扩展
Caffeine (Java中拥有多种缓存策略的缓存项目)
github:https://github.com/ben-manes/caffeine
Caffeine是一个开源的Java缓存库,它能提供高命中率和出色的并发能力 ,内部使用W-TinyLFU 策略加上并发写入的实现,在基准测试中表现优异。目前被广泛应用与游戏和电商等等项目中。此项目只有Java版本的,没有适配所有版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号