【Go】优雅的读取http请求或响应的数据
【Go】优雅的读取http请求或响应的数据
原文链接:https://blog.thinkeridea.com/201901/go/you_ya_de_du_qu_http_qing_qiu_huo_xiang_ying_de_shu_ju.html
从 http.Request.Body 或 http.Response.Body 中读取数据方法或许很多,标准库中大多数使用 ioutil.ReadAll 方法一次读取所有数据,如果是 json 格式的数据还可以使用 json.NewDecoder 从 io.Reader 创建一个解析器,假使使用 pprof 来分析程序总是会发现 bytes.makeSlice 分配了大量内存,且总是排行第一,今天就这个问题来说一下如何高效优雅的读取 http 中的数据。
背景介绍
我们有许多 api 服务,全部采用 json 数据格式,请求体就是整个 json 字符串,当一个请求到服务端会经过一些业务处理,然后再请求后面更多的服务,所有的服务之间都用 http 协议来通信(啊, 为啥不用 RPC,因为所有的服务都会对第三方开放,http + json 更好对接),大多数请求数据大小在 1K~4K,响应的数据在 1K~8K,早期所有的服务都使用 ioutil.ReadAll 来读取数据,随着流量增加使用 pprof 来分析发现 bytes.makeSlice 总是排在第一,并且占用了整个程序 1/10 的内存分配,我决定针对这个问题进行优化,下面是整个优化过程的记录。
pprof 分析
这里使用 https://github.com/thinkeridea/go-extend/blob/master/exnet/exhttp/expprof/pprof.go 中的 API 来实现生产环境的 /debug/pprof 监测接口,没有使用标准库的 net/http/pprof 包因为会自动注册路由,且长期开放 API,这个包可以设定 API 是否开放,并在规定时间后自动关闭接口,避免存在工具嗅探。
服务部署上线稳定后(大约过了一天半),通过 curl 下载 allocs 数据,然后使用下面的命令查看分析。
$ go tool pprof allocs
File: xxx
Type: alloc_space
Time: Jan 25, 2019 at 3:02pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 604.62GB, 44.50% of 1358.61GB total
Dropped 776 nodes (cum <= 6.79GB)
Showing top 10 nodes out of 155
flat flat% sum% cum cum%
111.40GB 8.20% 8.20% 111.40GB 8.20% bytes.makeSlice
107.72GB 7.93% 16.13% 107.72GB 7.93% github.com/sirupsen/logrus.(*Entry).WithFields
65.94GB 4.85% 20.98% 65.94GB 4.85% strings.Replace
54.10GB 3.98% 24.96% 56.03GB 4.12% github.com/json-iterator/go.(*frozenConfig).Marshal
47.54GB 3.50% 28.46% 47.54GB 3.50% net/url.unescape
47.11GB 3.47% 31.93% 48.16GB 3.55% github.com/json-iterator/go.(*Iterator).readStringSlowPath
46.63GB 3.43% 35.36% 103.04GB 7.58% handlers.(*AdserviceHandler).returnAd
42.43GB 3.12% 38.49% 84.62GB 6.23% models.LogItemsToBytes
42.22GB 3.11% 41.59% 42.22GB 3.11% strings.Join
39.52GB 2.91% 44.50% 87.06GB 6.41% net/url.parseQuery
从结果中可以看出采集期间一共分配了 1358.61GB top 10 占用了 44.50% 其中 bytes.makeSlice 占了接近 1/10,那么看看都是谁在调用 bytes.makeSlice 吧。
(pprof) web bytes.makeSlice
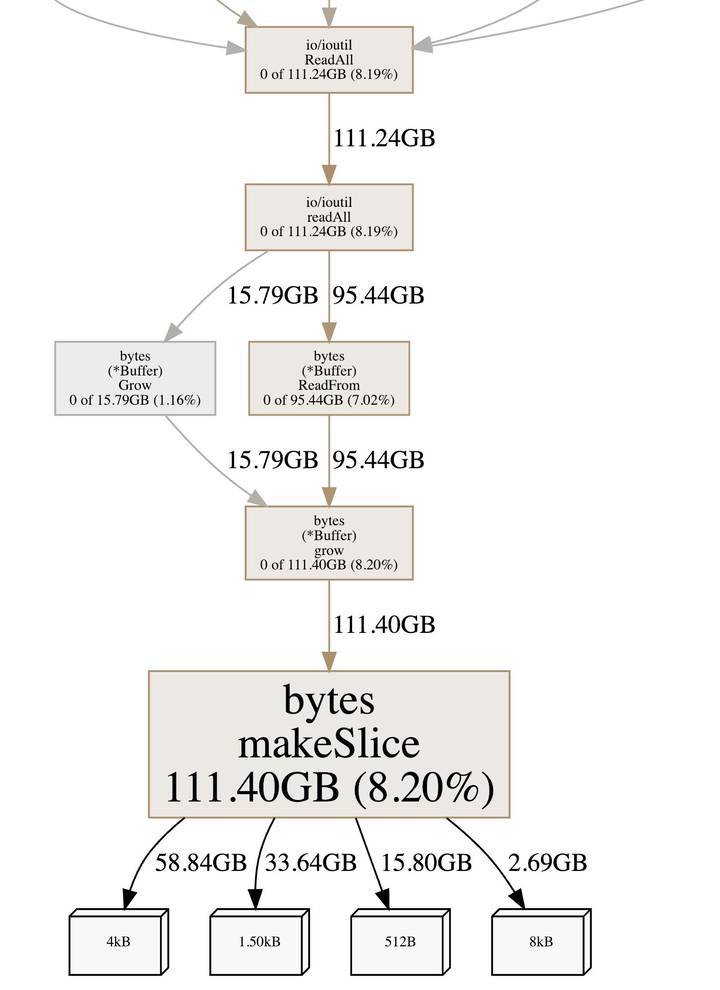
从上图可以看出调用 bytes.makeSlice 的最终方法是 ioutil.ReadAll, (受篇幅影响就没有截取 ioutil.ReadAll 上面的方法了),而 90% 都是 ioutil.ReadAll 读取 http 数据调用,找到地方先别急想优化方案,先看看为啥 ioutil.ReadAll 会导致这么多内存分配。
func readAll(r io.Reader, capacity int64) (b []byte, err error) {
var buf bytes.Buffer
// If the buffer overflows, we will get bytes.ErrTooLarge.
// Return that as an error. Any other panic remains.
defer func() {
e := recover()
if e == nil {
return
}
if panicErr, ok := e.(error); ok && panicErr == bytes.ErrTooLarge {
err = panicErr
} else {
panic(e)
}
}()
if int64(int(capacity)) == capacity {
buf.Grow(int(capacity))
}
_, err = buf.ReadFrom(r)
return buf.Bytes(), err
}
func ReadAll(r io.Reader) ([]byte, error) {
return readAll(r, bytes.MinRead)
}
以上是标准库 ioutil.ReadAll 的代码,每次会创建一个 var buf bytes.Buffer 并且初始化 buf.Grow(int(capacity)) 的大小为 bytes.MinRead, 这个值呢就是 512,按这个 buffer 的大小读取一次数据需要分配 2~16 次内存,天啊简直不能忍,我自己创建一个 buffer 好不好。
看一下火焰图🔥吧,其中红框标记的就是 ioutil.ReadAll 的部分,颜色比较鲜艳。
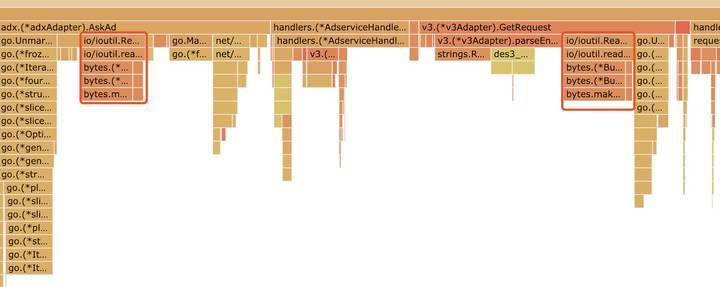
优化读取方法
自己创建足够大的 buffer 减少因为容量不够导致的多次扩容问题。
buffer := bytes.NewBuffer(make([]byte, 4096))
_, err := io.Copy(buffer, request.Body)
if err !=nil{
return nil, err
}
恩恩这样应该差不多了,为啥是初始化 4096 的大小,这是个均值,即使比 4096 大基本也就多分配一次内存即可,而且大多数数据都是比 4096 小的。
但是这样真的就算好了吗,当然不能这样,这个 buffer 个每请求都要创建一次,是不是应该考虑一下复用呢,使用 sync.Pool 建立一个缓冲池效果就更好了。
以下是优化读取请求的简化代码:
package adapter
import (
"bytes"
"io"
"net/http"
"sync"
"github.com/json-iterator/go"
"github.com/sirupsen/logrus"
"github.com/thinkeridea/go-extend/exbytes"
)
type Adapter struct {
pool sync.Pool
}
func New() *Adapter {
return &Adapter{
pool: sync.Pool{
New: func() interface{} {
return bytes.NewBuffer(make([]byte, 4096))
},
},
}
}
func (api *Adapter) GetRequest(r *http.Request) (*Request, error) {
buffer := api.pool.Get().(*bytes.Buffer)
buffer.Reset()
defer func() {
if buffer != nil {
api.pool.Put(buffer)
buffer = nil
}
}()
_, err := io.Copy(buffer, r.Body)
if err != nil {
return nil, err
}
request := &Request{}
if err = jsoniter.Unmarshal(buffer.Bytes(), request); err != nil {
logrus.WithFields(logrus.Fields{
"json": exbytes.ToString(buffer.Bytes()),
}).Errorf("jsoniter.UnmarshalJSON fail. error:%v", err)
return nil, err
}
api.pool.Put(buffer)
buffer = nil
// ....
return request, nil
}
使用 sync.Pool 的方式是不是有点怪,主要是 defer 和 api.pool.Put(buffer);buffer = nil 这里解释一下,为了提高 buufer 的复用率会在不使用时尽快把 buffer 放回到缓冲池中,defer 之所以会判断 buffer != nil 主要是在业务逻辑出现错误时,但是 buffer 还没有放回缓冲池时把 buffer 放回到缓冲池,因为在每个错误处理之后都写 api.pool.Put(buffer) 不是一个好的方法,而且容易忘记,但是如果在确定不再使用时 api.pool.Put(buffer);buffer = nil 就可以尽早把 buffer 放回到缓冲池中,提高复用率,减少新建 buffer。
这样就好了吗,别急,之前说服务里面还会构建请求,看看构建请求如何优化吧。
package adapter
import (
"bytes"
"fmt"
"io"
"io/ioutil"
"net/http"
"sync"
"github.com/json-iterator/go"
"github.com/sirupsen/logrus"
"github.com/thinkeridea/go-extend/exbytes"
)
type Adapter struct {
pool sync.Pool
}
func New() *Adapter {
return &Adapter{
pool: sync.Pool{
New: func() interface{} {
return bytes.NewBuffer(make([]byte, 4096))
},
},
}
}
func (api *Adapter) Request(r *Request) (*Response, error) {
var err error
buffer := api.pool.Get().(*bytes.Buffer)
buffer.Reset()
defer func() {
if buffer != nil {
api.pool.Put(buffer)
buffer = nil
}
}()
e := jsoniter.NewEncoder(buffer)
err = e.Encode(r)
if err != nil {
logrus.WithFields(logrus.Fields{
"request": r,
}).Errorf("jsoniter.Marshal failure: %v", err)
return nil, fmt.Errorf("jsoniter.Marshal failure: %v", err)
}
data := buffer.Bytes()
req, err := http.NewRequest("POST", "http://xxx.com", buffer)
if err != nil {
logrus.WithFields(logrus.Fields{
"data": exbytes.ToString(data),
}).Errorf("http.NewRequest failed: %v", err)
return nil, fmt.Errorf("http.NewRequest failed: %v", err)
}
req.Header.Set("User-Agent", "xxx")
httpResponse, err := http.DefaultClient.Do(req)
if httpResponse != nil {
defer func() {
io.Copy(ioutil.Discard, httpResponse.Body)
httpResponse.Body.Close()
}()
}
if err != nil {
logrus.WithFields(logrus.Fields{
"url": "http://xxx.com",
}).Errorf("query service failed %v", err)
return nil, fmt.Errorf("query service failed %v", err)
}
if httpResponse.StatusCode != 200 {
logrus.WithFields(logrus.Fields{
"url": "http://xxx.com",
"status": httpResponse.Status,
"status_code": httpResponse.StatusCode,
}).Errorf("invalid http status code")
return nil, fmt.Errorf("invalid http status code")
}
buffer.Reset()
_, err = io.Copy(buffer, httpResponse.Body)
if err != nil {
return nil, fmt.Errorf("adapter io.copy failure error:%v", err)
}
respData := buffer.Bytes()
logrus.WithFields(logrus.Fields{
"response_json": exbytes.ToString(respData),
}).Debug("response json")
res := &Response{}
err = jsoniter.Unmarshal(respData, res)
if err != nil {
logrus.WithFields(logrus.Fields{
"data": exbytes.ToString(respData),
"url": "http://xxx.com",
}).Errorf("adapter jsoniter.Unmarshal failed, error:%v", err)
return nil, fmt.Errorf("adapter jsoniter.Unmarshal failed, error:%v", err)
}
api.pool.Put(buffer)
buffer = nil
// ...
return res, nil
}
这个示例和之前差不多,只是不仅用来读取 http.Response.Body 还用来创建一个 jsoniter.NewEncoder 用来把请求压缩成 json 字符串,并且作为 http.NewRequest 的 body 参数, 如果直接用 jsoniter.Marshal 同样会创建很多次内存,jsoniter 也使用 buffer 做为缓冲区,并且默认大小为 512, 代码如下:
func (cfg Config) Froze() API {
api := &frozenConfig{
sortMapKeys: cfg.SortMapKeys,
indentionStep: cfg.IndentionStep,
objectFieldMustBeSimpleString: cfg.ObjectFieldMustBeSimpleString,
onlyTaggedField: cfg.OnlyTaggedField,
disallowUnknownFields: cfg.DisallowUnknownFields,
}
api.streamPool = &sync.Pool{
New: func() interface{} {
return NewStream(api, nil, 512)
},
}
// .....
return api
}
而且序列化之后会进行一次数据拷贝:
func (cfg *frozenConfig) Marshal(v interface{}) ([]byte, error) {
stream := cfg.BorrowStream(nil)
defer cfg.ReturnStream(stream)
stream.WriteVal(v)
if stream.Error != nil {
return nil, stream.Error
}
result := stream.Buffer()
copied := make([]byte, len(result))
copy(copied, result)
return copied, nil
}
既然要用 buffer 那就一起吧_,这样可以减少多次内存分配,下读取 http.Response.Body 之前一定要记得 buffer.Reset(), 这样基本就已经完成了 http.Request.Body 和 http.Response.Body 的数据读取优化了,具体效果等上线跑一段时间稳定之后来查看吧。
效果分析
上线跑了一天,来看看效果吧
$ go tool pprof allocs2
File: connect_server
Type: alloc_space
Time: Jan 26, 2019 at 10:27am (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 295.40GB, 40.62% of 727.32GB total
Dropped 738 nodes (cum <= 3.64GB)
Showing top 10 nodes out of 174
flat flat% sum% cum cum%
73.52GB 10.11% 10.11% 73.52GB 10.11% git.tvblack.com/tvblack/connect_server/vendor/github.com/sirupsen/logrus.(*Entry).WithFields
31.70GB 4.36% 14.47% 31.70GB 4.36% net/url.unescape
27.49GB 3.78% 18.25% 54.87GB 7.54% git.tvblack.com/tvblack/connect_server/models.LogItemsToBytes
27.41GB 3.77% 22.01% 27.41GB 3.77% strings.Join
25.04GB 3.44% 25.46% 25.04GB 3.44% bufio.NewWriterSize
24.81GB 3.41% 28.87% 24.81GB 3.41% bufio.NewReaderSize
23.91GB 3.29% 32.15% 23.91GB 3.29% regexp.(*bitState).reset
23.06GB 3.17% 35.32% 23.06GB 3.17% math/big.nat.make
19.90GB 2.74% 38.06% 20.35GB 2.80% git.tvblack.com/tvblack/connect_server/vendor/github.com/json-iterator/go.(*Iterator).readStringSlowPath
18.58GB 2.56% 40.62% 19.12GB 2.63% net/textproto.(*Reader).ReadMIMEHeader
哇塞 bytes.makeSlice 终于从前十中消失了,真的太棒了,还是看看 bytes.makeSlice 的其它调用情况吧。
(pprof) web bytes.makeSlice
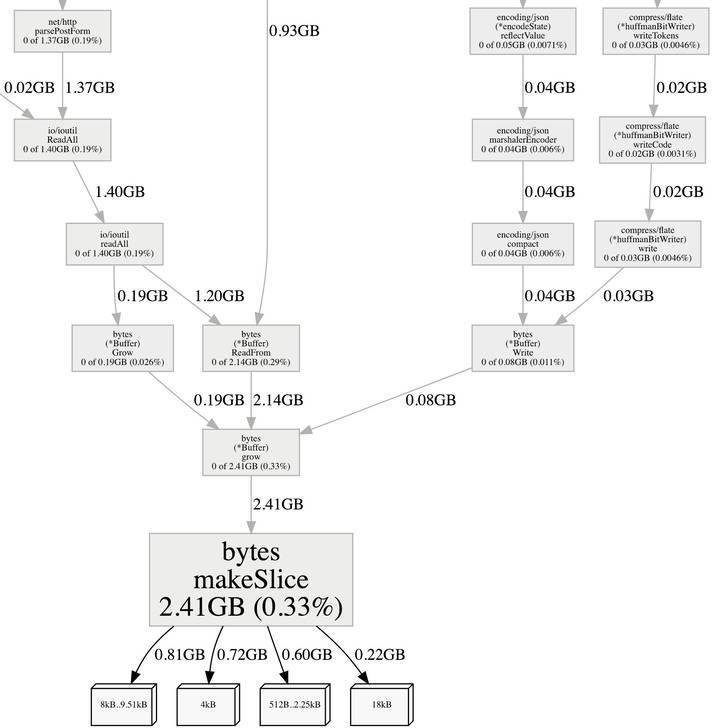
从图中可以发现 bytes.makeSlice 的分配已经很小了, 且大多数是 http.Request.ParseForm 读取 http.Request.Body 使用 ioutil.ReadAll 原因,这次优化的效果非常的好。
看一下更直观的火焰图🔥吧,和优化前对比一下很明显 ioutil.ReadAll 看不到了
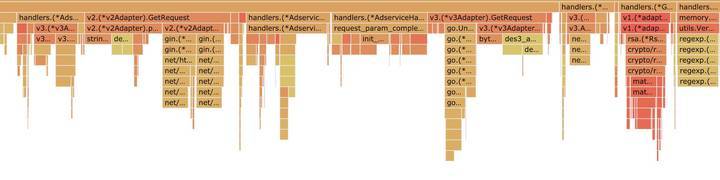
优化期间遇到的问题
比较惭愧在优化的过程出现了一个过失,导致生产环境2分钟故障,通过自动部署立即回滚才得以快速恢复,之后分析代码解决之后上线才完美优化,下面总结一下出现的问题吧。
在构建 http 请求时我分了两个部分优化,序列化 json 和读取 http.Response.Body 数据,保持一个观点就是尽早把 buffer 放回到缓冲池,因为 http.DefaultClient.Do(req) 是网络请求会相对耗时,在这个之前我把 buffer 放回到缓冲池中,之后读取 http.Response.Body 时在重新获取一个 buffer,大概代码如下:
package adapter
import (
"bytes"
"fmt"
"io"
"io/ioutil"
"net/http"
"sync"
"github.com/json-iterator/go"
"github.com/sirupsen/logrus"
"github.com/thinkeridea/go-extend/exbytes"
)
type Adapter struct {
pool sync.Pool
}
func New() *Adapter {
return &Adapter{
pool: sync.Pool{
New: func() interface{} {
return bytes.NewBuffer(make([]byte, 4096))
},
},
}
}
func (api *Adapter) Request(r *Request) (*Response, error) {
var err error
buffer := api.pool.Get().(*bytes.Buffer)
buffer.Reset()
defer func() {
if buffer != nil {
api.pool.Put(buffer)
buffer = nil
}
}()
e := jsoniter.NewEncoder(buffer)
err = e.Encode(r)
if err != nil {
return nil, fmt.Errorf("jsoniter.Marshal failure: %v", err)
}
data := buffer.Bytes()
req, err := http.NewRequest("POST", "http://xxx.com", buffer)
if err != nil {
return nil, fmt.Errorf("http.NewRequest failed: %v", err)
}
req.Header.Set("User-Agent", "xxx")
api.pool.Put(buffer)
buffer = nil
httpResponse, err := http.DefaultClient.Do(req)
// ....
buffer = api.pool.Get().(*bytes.Buffer)
buffer.Reset()
defer func() {
if buffer != nil {
api.pool.Put(buffer)
buffer = nil
}
}()
_, err = io.Copy(buffer, httpResponse.Body)
if err != nil {
return nil, fmt.Errorf("adapter io.copy failure error:%v", err)
}
// ....
api.pool.Put(buffer)
buffer = nil
// ...
return res, nil
}
上线之后马上发生了错误 http: ContentLength=2090 with Body length 0 发送请求的时候从 buffer 读取数据发现数据不见了或者数据不够了,我去这是什么鬼,马上回滚恢复业务,然后分析 http.DefaultClient.Do(req) 和 http.NewRequest,在调用 http.NewRequest 是并没有从 buffer 读取数据,而只是创建了一个 req.GetBody 之后在 http.DefaultClient.Do 是才读取数据,因为在 http.DefaultClient.Do 之前把 buffer 放回到缓冲池中,其它 goroutine 获取到 buffer 并进行 Reset 就发生了数据争用,当然会导致数据读取不完整了,真实汗颜,对 http.Client 了解太少,争取有空撸一遍源码。
总结
使用合适大小的 buffer 来减少内存分配,sync.Pool 可以帮助复用 buffer, 一定要自己写这些逻辑,避免使用三方包,三方包即使使用同样的技巧为了避免数据争用,在返回数据时候必然会拷贝一个新的数据返回,就像 jsoniter 虽然使用了 sync.Pool 和 buffer 但是返回数据时还需要拷贝,另外这种通用包并不能给一个非常贴合业务的初始 buffer 大小,过小会导致数据发生拷贝,过大会太过浪费内存。
程序中善用 buffer 和 sync.Pool 可以大大的改善程序的性能,并且这两个组合在一起使用非常的简单,并不会使代码变的复杂。
转载:
本文作者: 戚银(thinkeridea)
本文链接: https://blog.thinkeridea.com/201901/go/you_ya_de_du_qu_http_qing_qiu_huo_xiang_ying_de_shu_ju.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY 4.0 CN协议 许可协议。转载请注明出处!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号