
上一次的内容 Javascript 正则表达式(Javascript Regular Expressions)—— part 1 介绍了部分正则表达式在 Javascript 中的用法,这篇将继续来深入学习。
在掌握了如何匹配特定字符串之后,来了解一下如何通过特定字符串来判断原字符串是否符合我们的要求。
1 // 字符串 2 let str = "Our aptitude may decide start of our life, but life's altitude depends on our attitude towards it."; 3 4 // 正则表达式 5 let regex = /[^aeiou]/g; 6 7 // 查找 str 中满足正则表达式的结果 8 let result = str.match(regex); 9 console.log(result);
还是用昨天的例子,区别在于正则表达式里面多了一个 ^ 插入号(caret)。当我们在字符集(Character classes)中 [ 的后面使用 ^ 意味着不查找相应字符(字符集),示例的结果便是除了元音字母(a、e、i、o、u)以外的其他字符组成的数组。
^ 除了可以用在字符集当中,还可以直接用在正则表达式里,在这种情况下又会有不同的意义。
1 // 字符串 2 let str = "Our aptitude may decide start of our life, but life's altitude depends on our attitude towards it."; 3 4 // 正则表达式 5 let regex = /^Our/; 6 7 // 查找 str 是否以 regex 开头 8 let result = regex.test(str); 9 console.log(result);
直接在正则表达式内部使用 ^ 用来判断是否以某些特定字符(字符集合)开头,是则 test() 方法返回 true,反之返回 false。
与之相对的,正则表达式还提供了判断是否以某些特定字符(字符集合)结尾的方法,需要引入一个新的字符:$(dollar)
1 // 字符串 2 let str = "Our aptitude may decide start of our life, but life's altitude depends on our attitude towards it."; 3 4 // 正则表达式 5 let regex = /it.$/; 6 7 // 查找 str 是否以 regex 结尾 8 let result = regex.test(str); 9 console.log(result);
一点需要注意的区别在于:^ 写在 [ 的后面;而 $ 写在 ] 的前面。
接下来还是一个涉及字符个数的问题。在上一篇中我们可以通过 g 来查找字符串中所有字符是否符合表达式,那么同一个字符出现的方式还可能会有所不同。
1 // 字符串 2 let str = "attitude"; 3 4 // 正则表达式 5 let regex = /t+/g; 6 7 // 查找 str 符合表达式的结果 8 let result = str.match(regex); 9 console.log(result);
先看一下 log 之后的结果:
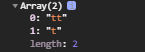
返回的数组中有两个元素,分别是 "tt" 和 "t" 。如果去掉表达式中的 + 的话,就变成了上一篇中的相对简单的一个问题。而 + 在这里所起的作用就是查找对应字符(字符集合)的一个或者多个并返回。
在查找字符 t 的过程中,在字母 A 后会有两个,所以返回 "tt";而字母 I 后还有一个, 因此再返回一个 "t" 。
与之类似的另外一个符号是 * ,作用是查找对应字符(字符集合)零个或者多个并返回。这两者的主要区别就在于零个和一个的问题,需要根据情况使用。
然后我们对上一个例子稍加改动,用来引出一个新的概念:惰性匹配(Lazy match)
1 // 字符串 2 let str = "attitude"; 3 4 // 正则表达式 5 let regex = /t+?/g; 6 7 // 查找 str 符合表达式的结果 8 let result = str.match(regex); 9 console.log(result);
还是先看一下结果:
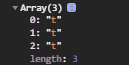
加了一个 ? 之后结果明显不同,之所以会这样从概念的名称其实也可以看出。在这里“惰性”指的就是在查找匹配的过程中以最小单位返回。因此就变成了三个单独的字母 t 。
然后来说一下正则表达式的缩写。先用一个问题介绍缩写的必要性:如果我们想要匹配所有的字母(含大小写)和数字要怎么做呢?
可以通过上一篇的字符集来表示:[a-zA-Z0-9] 。其中 a-z 为所有小写字母,A-Z为所有大写字母,0-9为所有数字。
从某种意义上讲这已经是比较简单的表示方式,然而在正则表达式里还有更简单的表达:\w。\w 实际上不仅仅可以表达字母和数字,其实还包括了下划线 _ ,因此 \w = [a-zA-Z0-9_]
然后与之相反的,\W 与 \w 的区别在于大小写,指匹配除了字母、数字、下划线以外的字符,即 \W = [^a-zA-Z0-9_]
还有只匹配数字的缩写符号:\d 和 \D,\d 匹配数字,\D 反之。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号