SHAP:以淘宝展示广告点击率预估做可视化分析解释
前两次用SHAP框架可视化解释了bitcoin price预测和credit fraud detection这种anomaly detection,今天继续以推荐系统为样本对SHAP的使用做可视化分析!
1、数据集还是来自天池:https://tianchi.aliyun.com/dataset/56
代码:
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import roc_auc_score from xgboost import XGBClassifier import shap import matplotlib.pyplot as plt # ----------------------------- # 1. 加载数据 # ----------------------------- RAW_SAMPLE_PATH = "raw_sample.csv" AD_FEATURE_PATH = "ad_feature.csv" USER_PROFILE_PATH = "user_profile.csv" BEHAVIOR_LOG_PATH = "behavior_log.csv" # 加载原始样本骨架 raw_sample = pd.read_csv(RAW_SAMPLE_PATH) # 加载广告信息 ad_feature = pd.read_csv(AD_FEATURE_PATH) # 加载用户信息 user_profile = pd.read_csv(USER_PROFILE_PATH) # 加载行为日志(可选限制加载数量) behavior_log = pd.read_csv(BEHAVIOR_LOG_PATH, nrows=10_000_000) # 控制内存使用 # ----------------------------- # 2. 数据预处理与特征工程 # ----------------------------- # 合并广告信息 df = raw_sample.merge(ad_feature, on="adgroup_id", how="left") print(raw_sample.head()) # 合并用户信息(注意列名:user vs userid) df = df.merge(user_profile, left_on="user", right_on="userid", how="left") # 删除冗余字段 df.drop(columns=["userid"], inplace=True) # 设置目标变量 df["label"] = df["clk"] df['date'] = pd.to_datetime(df['time_stamp'], unit='s', errors='coerce') pd.set_option('future.no_silent_downcasting', True) # 这样 .fillna() 不会触发自动 downcasting 的警告 # 在后续 fillna 时跳过 date 列 for col in df.columns: if col == "date": continue if df[col].dtype == "object": df[col] = df[col].fillna("unknown") else: df[col] = df[col].fillna(-1).infer_objects() # 使用 infer_objects 避免 downcasting 警告 # 安全地转换类别字段为整数 for col in df.select_dtypes(include=['object']).columns: df[col] = pd.to_numeric(df[col].astype(str), errors='coerce').fillna(-1).astype(int) # ----------------------------- # 3. 行为日志特征提取(behavior_log) # ----------------------------- # 提取用户行为统计特征 behavior_log["btag"] = behavior_log["btag"].astype(str) behavior_log["btag_code"] = behavior_log["btag"].map({ "ipv": 0, "cart": 1, "fav": 2, "buy": 3 }) # 用户行为计数特征 user_behavior_stats = behavior_log.groupby("user")["btag"].value_counts().unstack(fill_value=0) user_behavior_stats.columns = [f"user_btag_{col}" for col in user_behavior_stats.columns] # 用户行为时间间隔特征 behavior_log["time_stamp"] = pd.to_datetime(behavior_log["time_stamp"], format="%Y%m%d%H%M%S", errors='coerce') behavior_log["last_action"] = behavior_log.groupby("user")["time_stamp"].shift() behavior_log["time_diff"] = (behavior_log["time_stamp"] - behavior_log["last_action"]).dt.total_seconds() user_time_diff_stats = behavior_log.groupby("user")["time_diff"].agg(["mean", "std", "min", "max"]) user_time_diff_stats.columns = [f"user_time_diff_{col}" for col in user_time_diff_stats.columns] # 合并行为特征到主表 df = df.merge(user_behavior_stats, left_on="user", right_index=True, how="left") df = df.merge(user_time_diff_stats, left_on="user", right_index=True, how="left") # 填充行为特征缺失值 df.fillna(0, inplace=True) # 最后再删除 user、adgroup_id 等冗余字段 df.drop(columns=["nonclk", "clk", "user", "adgroup_id"], inplace=True, errors='ignore') print(df.head) # ----------------------------- # 4. 划分训练集和测试集 # ----------------------------- df['date'] = pd.to_datetime(df['date'], errors='coerce') print(df['date'].dtype) # 确保显示为 datetime64[ns] # 过滤掉可能转换失败导致的 NaT df = df[df['date'].notna()] # 筛掉没有时间戳的样本 # 再进行时间切分 cutoff_date = pd.to_datetime('2017-05-13') train_df = df[df['date'] < cutoff_date] test_df = df[df['date'] == cutoff_date] X_train = train_df.drop(columns=["label", "date"], errors='ignore') y_train = train_df["label"] X_test = test_df.drop(columns=["label", "date"], errors='ignore') y_test = test_df["label"] # ----------------------------- # 5. 模型训练 # ----------------------------- model = XGBClassifier( n_estimators=100, max_depth=5, learning_rate=0.1, subsample=0.8, colsample_bytree=0.7, eval_metric='logloss', use_label_encoder=False ) model.fit(X_train, y_train) # 预测 y_proba = model.predict_proba(X_test)[:, 1] print("AUC Score:", roc_auc_score(y_test, y_proba)) # ----------------------------- # 6. SHAP 解释 # ----------------------------- explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X_test) # 摘要图(Summary Plot) shap.summary_plot(shap_values, X_test, plot_type="bar") shap.summary_plot(shap_values, X_test) # 力图(Force Plot) - 单个样本 shap.initjs() shap.force_plot(explainer.expected_value, shap_values[0, :], X_test.iloc[0, :]) # 依赖图(Dependence Plot) for feature in X_test.columns: try: shap.dependence_plot(feature, shap_values, X_test) except Exception as e: print(f"Skipping {feature} due to error: {e}") # 决策图(Decision Plot) shap.decision_plot(explainer.expected_value, shap_values[:10], feature_names=X_test.columns.tolist()) # 交互作用图(Interaction Plot) shap_interaction_values = explainer.shap_interaction_values(X_test) shap.summary_plot(shap_interaction_values, X_test) # 特征重要性排序(Feature Importance) plt.figure(figsize=(10, 6)) shap.summary_plot(shap_values, X_test, plot_type="bar") plt.title("Feature Importance (SHAP)") plt.show()
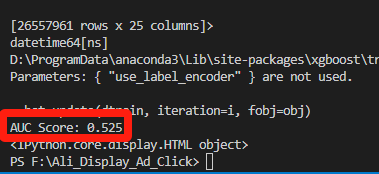
最终的AUC:感觉结果很一般,估计还有很多参数可以调整,很多列可以做清洗,这里主要做SHAP的可视化解释,所以这些工作暂时不做了!
2、还是挨个看分析结果:
(1)每个feather的SHAP值:
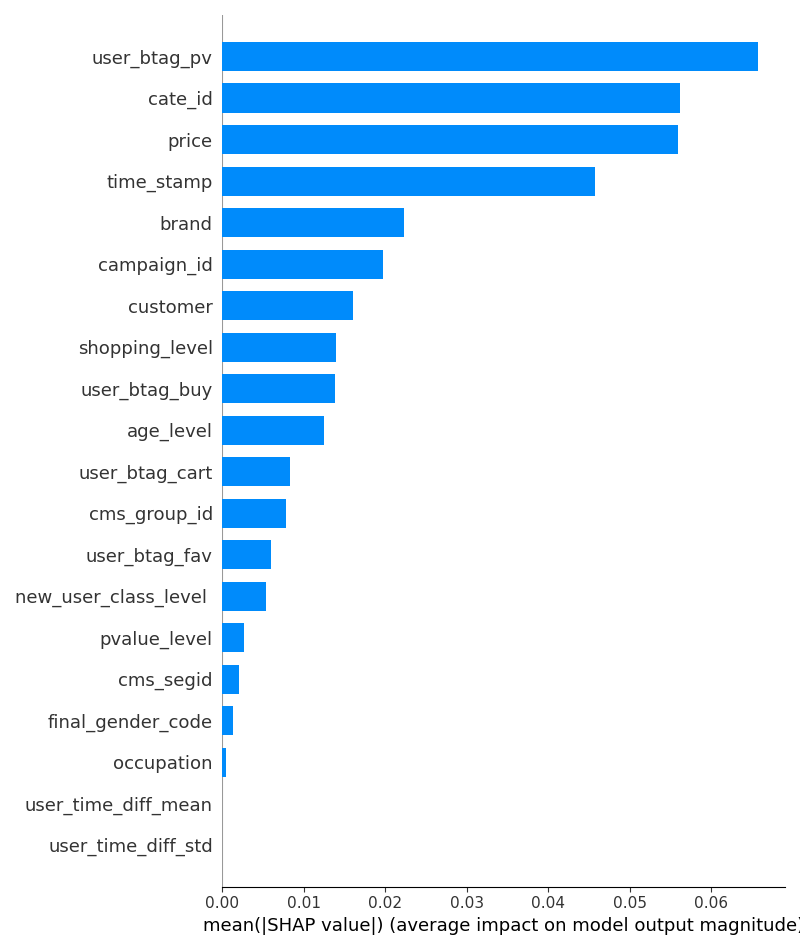
对于结果的广告是否点击,重要的feather有:
- user_btag_pv:用户过去浏览过越多广告,越可能继续点击新广告,是最重要的预测因子;(或则还有另一种可能:是不是故意刷流量的爬虫干的?)
- cate_id:某些类目的商品天然更吸引用户点击(如美妆、电子产品)
- price:价格敏感型用户可能更关注低价商品,或高价商品具有更高转化价值
- time_stamp:用户在特定时间段(如晚间、周末)的活跃度更高?
- brand:知名品牌可能自带更高的用户信任度和点击意愿?
- campaign_id :广告计划 ID,可能反映不同广告策略的效果差异
- customer :广告主 ID,优质广告主可能投放更精准的广告。
- shopping_level :用户购物深度等级(如浅层、中度、深度用户)。
- user_btag_buy :用户历史购买行为次数,购买过的用户更可能再次点击。
(2)具体到每个feather,到底是正相关还是负相关了?PS:做数据挖掘,就是要找到影响大的feather,不论是正面还是负面的!从下图看,红蓝的点严格在两边隔开不混淆,说明泾渭分明,这就是好的feather(不论红蓝在左还是右,只要严格分开,说明这种feather能很好地区分target)!
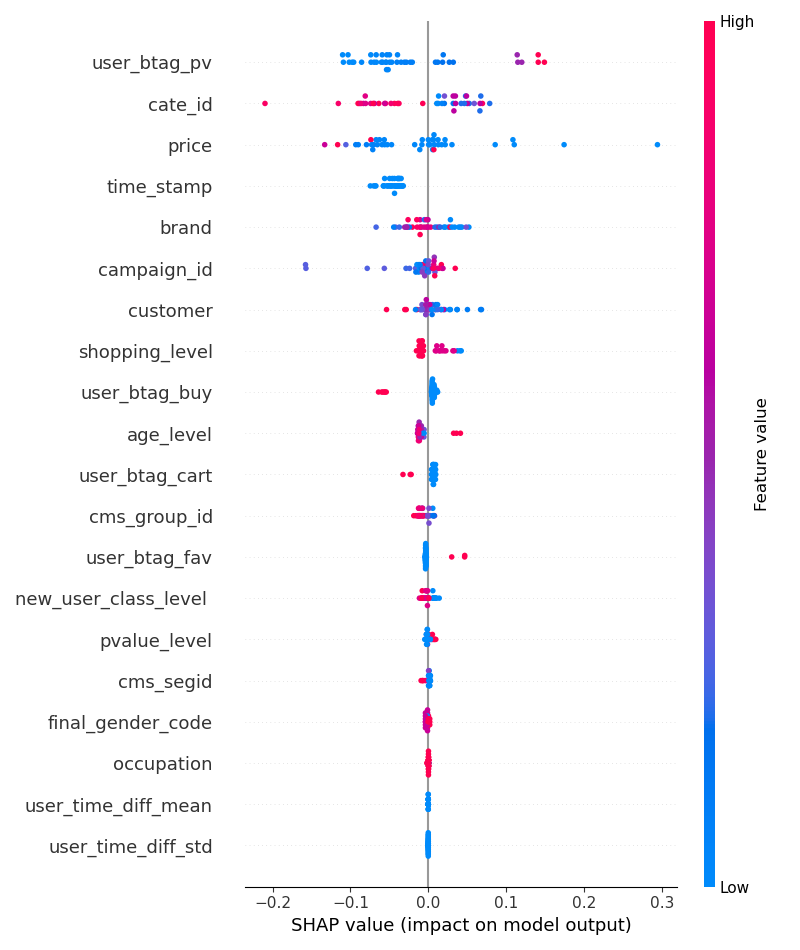
- user_btag_pv:SHAP 值跨度大(从 -0.2 到 0.3),红色(高值)多集中在右侧;说明用户历史浏览行为(PV)对点击率影响显著。高 PV 用户(红色)更可能点击广告(这部分用户本身的活跃度更高),低 PV 用户(蓝色)则相反
- cate_id:红色的全在左边,右边红蓝基本各站一半,也就是某些cate_id的商品让用户比较“讨厌”,不点击的概率较大,比如美妆给男性用户展示;相反,在右侧这些id也有较高的正面影响,估计是美妆给女性用户展示了!
- price:右边蓝色明显多,说明低价对于用户的吸引确实大;相反,红色的几乎都在左边,说明高价对用户是较大的负面影响!
- brand:大部分红色在左边,蓝色在右边,符合上述分开的说明,说明特定品牌在不同人群的点击率差异十分明显,比如电子产品在男性群体的点击率明显和女性不同!
- campaign_id:红色左、蓝色右,同上!
剩下的shopping_level、user_btag_buy等同样都是泾渭分明的好feather!
(3)各种依赖图:
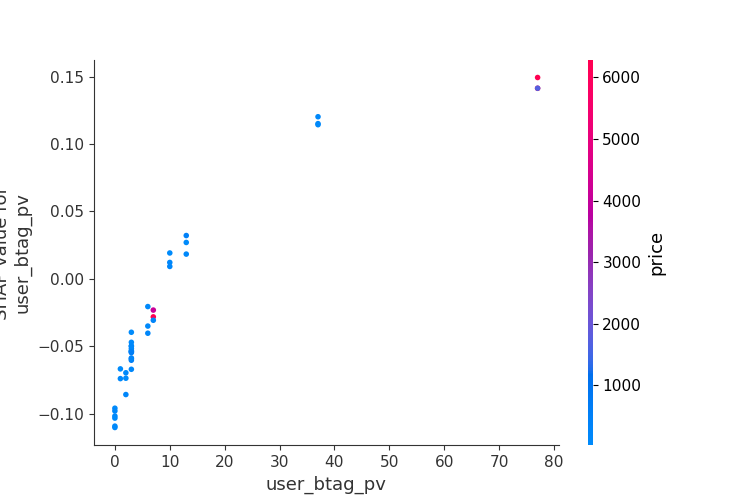
- user_btag_pv和price的dependent:随着
user_btag_pv的增加,SHAP 值整体呈上升趋势,但增长速度逐渐放缓;- 当
user_btag_pv较小时(如 0 到 10 左右),SHAP 值为负,表明这些用户的历史浏览行为较少,对点击率有轻微的负面影响 - 当
user_btag_pv较大时(如 40 到 80 左右),SHAP 值为正,表明这些用户的历史浏览行为较多,对点击率有显著的正向影响
- 当
- 蓝色区域(低价格)集中在左侧,表明低价格的商品通常对应较低的
user_btag_pv。红色区域(高价格)集中在右侧,表明高价格的商品通常对应较高的user_btag_pv。- 这表明高价格商品更可能被频繁浏览的用户点击,而低价格商品则可能被浏览较少的用户点击,后续可以用这个作为运营投放的规则!
- 针对高频浏览用户(如
user_btag_pv > 40),优先展示高价格商品; - 结合用户画像,为低频浏览用户(如
user_btag_pv < 10)提供折扣或促销活动,以激发其点击意愿。
- 针对高频浏览用户(如
- 这表明高价格商品更可能被频繁浏览的用户点击,而低价格商品则可能被浏览较少的用户点击,后续可以用这个作为运营投放的规则!
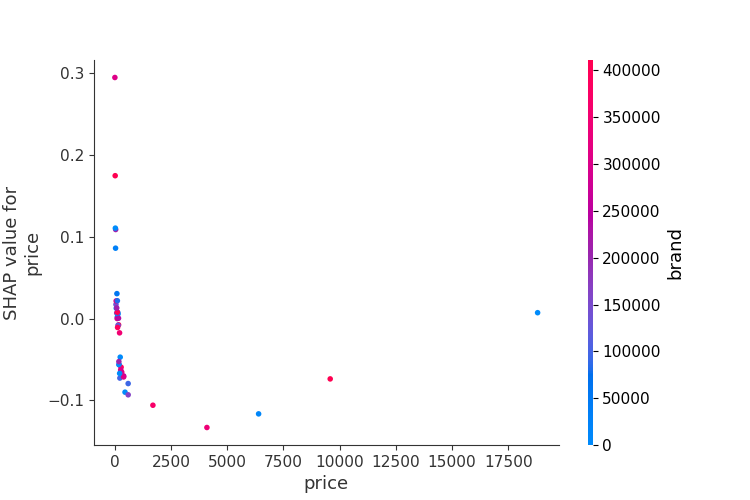
- price和brand的dependent关系:
- 随着
price的增加,SHAP 值整体呈下降趋势:- 当
price接近0时,其SHAP值明显是正的,说明低价或不标注价格,能吸引用户点击广告;- 低价商品可能通过“性价比”吸引用户;
- 当
price从0开始增加时,SHAP逐渐降低到负数,说明price增加对点击率有明显的负面影响!- 高价商品可能因“超出预算”或“不信任感”导致点击率下降。
- 当
- 红色和蓝色都集中在0~1000的price这里,说明brand的价格都不高(注意:brand用脱敏后的id表示,id值越高越红,越低就越蓝;但这个只是brand的id,仅仅只是个编号,无实际的业务意义!严格讲:这类离散数据在代码中需要指明类型)
- 后续可以引导高端brand主针对高端客户展示广告?
- 随着
3、推荐系统的发展阶段:各个公司可以根据自身的发展阶段灵活选择适合的算法!
- CF:连模型都算不上,就是个数学计算公式,没有embedding,无泛化能力
- matrix factorization:只用了user-item的interactive信息,没用到user profile、item information
- LR+特征交叉:尽可能多的使用user/iem信息
- Factorization Machine 因子分解机
- FFM:特征域组合
- GBDT用来生成离散特征,然后用LR做预测
- Factorization Machine 因子分解机
- 深度学习DNN:wide&deep、deep Cross、deep FM.....
- 提取embedding特征
- LLM:user 和item的交互是时序数据
- HLLM

 浙公网安备 33010602011771号
浙公网安备 33010602011771号