LLM大模型:Absolute Zero: Reinforced Self-play Reasoning with Zero Data 0数据做post train RL
RL的领域越来越炸裂了,近期又有团队开源了 Zero Data 做reinforcement learning的方法:在post train阶段,做RL时 Absolute Zero data,听名字是不是很炸裂啊!先来回顾一下LLM领域做RL的历史阶段:
- 最早是PPO/DPO等方式,需要人工标注数据(主要是对其人类偏好),然后用这些标注好的数据做RL训练;打个比方:做数学题的时候有题目要求、解题过程和最终答案
- 2025.1时,deepseek R1爆火,用的是GRPO的方式:有question和ground truth,但是没有cot过程,需要LLM自己摸索cot的过程;打个比方:做数学题的时候有题目要求和最终答案,解题过程需要LLM自己explore摸索
- 2025.4时,有一篇paper发布(详见:https://www.cnblogs.com/theseventhson/p/18850484) ,作者提出了Test-Time Reinforcement Learning:在post train的RL阶段,连ground truth都省了,让LLM自己生成多个答案,做majority voting得到reward信号来训练;打个比方:做数学题的时候有题目要求,没有解题过程,也没有标准答案,LLM自己猜答案,自己通过majority voting找到“正确”答案,从而产生reward信号!
- 2025.5更炸裂的来了:Absolute Zero: Reinforced Self-play Reasoning with Zero Data;在post train阶段,上述几种方法至少还需要使用人工生成或标注的data,这里的AZR连data都不需要人工准备了!训练时候使用的data都是LLM生成的,完全不用人工标记;打个比方:做数学题的时候题目、解题过程cot都是其他LLM生成的,完全不需要人工生成或标注数据了!
这么炸裂的方案,都是怎么实现的了?
1、先说近期遇到的所有RL paper用到的data:无一例外都是math或code,原因很简单:结果对错容易判定,reward信号容易生成!AZR用的也是code类数据验证方案是否有效,很多人可能有疑问:就算在code上的表现好,在其他领域表现咋样了?是不是只能解决code的问题了?能泛化么?AI agenbt只要code写的正确,其他领域的大多数问题都能迎刃而解:比如做数学题、分析图片、量化投资等!传统的agent是这么干的:根据用户的prompt生成json,在json的字段中输出需要调用的function;如果一个任务比较复杂,可能需要逐步生成多个json,输出多个function call,图示如下(来自 Executable Code Actions Elicit Better LLM Agents):
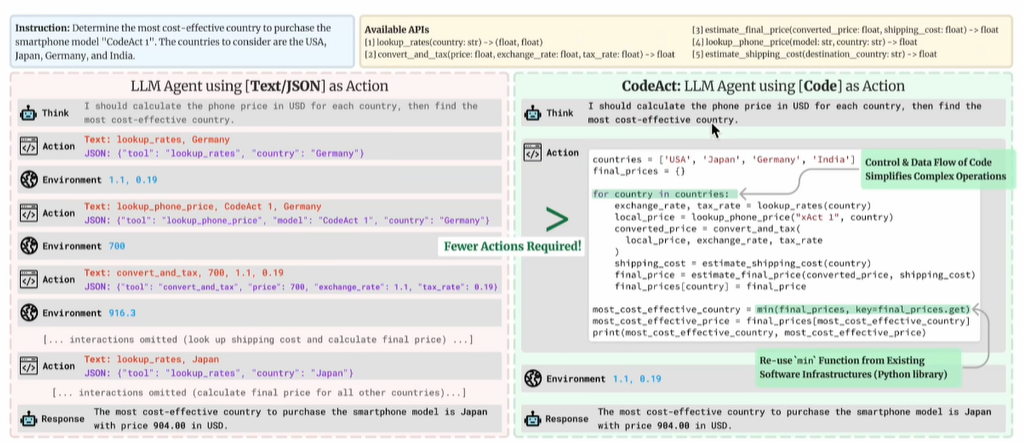
这么做的问题有:
- 分成多步骤:执行效率打折
- json生成的function必须正确,并且json格式也要正确
所以2024有篇paper针对这个问题,提出了code action的方案:agent输出code,通过执行code干其他所有的事!不需要分步骤,一次性完成!就连hugging face的agent都是code agent(详https://huggingface.co/docs/smolagents/main/en/tutorials/secure_code_execution ),他们给出的理由是:
- Object management: how do you store the output of an action like generate_image in JSON? json没发保存图片啊!
- Composability: could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?json可能还要嵌套,使用解析都麻烦
- Generality: code is built to express simply anything you can have a computer do. 电脑能执行code,code就是computer的语言
- Representation in LLM training corpus: why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus? 训练预料已经有code了,如果是json,还要单独准备语料
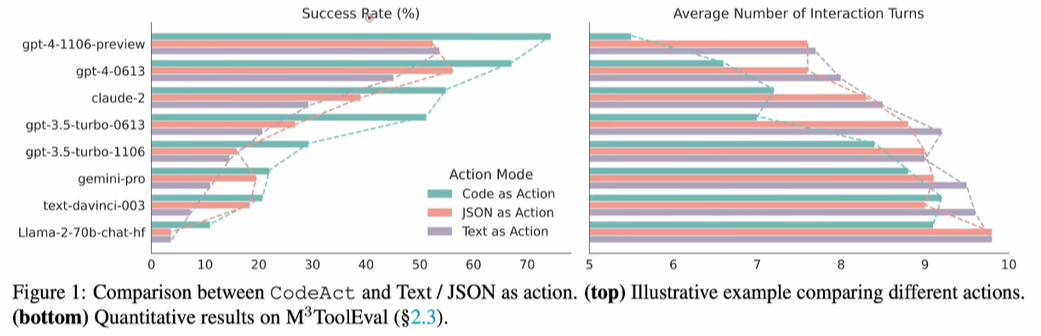
上图是codeAct和传统的Json/text相比:成功率高,交互次数还少,优点拉的慢慢的!所以结论就是:LLM生成正确的code已经能泛化到其他大部分领域了!
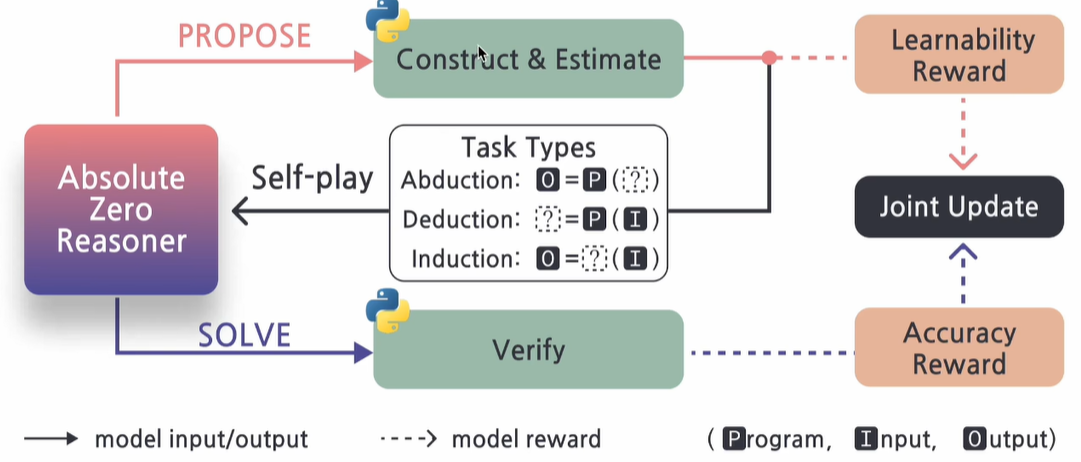
2、(1)既然是做post train的RL,data和reward肯定是要的,既然不是人工生成,那就只能让LLM生成了,具体该怎么做了?AZR是这么干的,如下图所示:
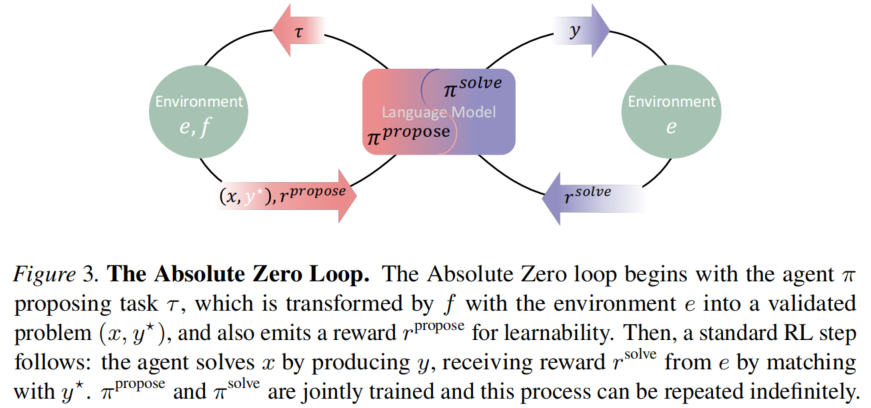
- proposer:类似teacher模型,产生train data,和env交互后得到reward用于更新自己的参数
- solver:类似student模型,使用train data,和env交互后得到reward用于更新自己的参数
solver是后续用于inference的LLM,proposer是用于生成train data的LLM,既然都是LLM,肯定都是要训练参数的,怎么确保这两个LLM都正确收敛了?此时就需要正确的reward信号了!
(2)既然proposer是teacher,用于产生train data,肯定要先收敛,得到正确的参数(才能产生正确的data)才能训练出正确的solver,这里proposer的reward设置如下:
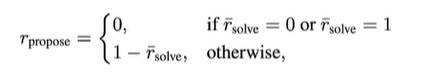
proposer产生的train data,如果solver全都做对了,说明data逻辑太简单,这时proposer不能有reward;反之亦然:如果solver全都做错了,说明data题目太难,proposer也不能得分;proposer的reward就是1-solver的reward!
对于solver,reward就简单了:做对了多少题目,就得这么多的分数!
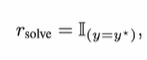
除了train data和回答对错外,还有一个重要的reward:formatting格式!作者这里借鉴了deepseek R1的思路,回答需要包含think和answer的标签。如果不包括,那就扣分!如下:


3、方案确定,最重要的步骤来了:data怎么生成?生成后怎么训练了?注意:这个paper做的post train,不是pre train,所以使用的LLM都是pre train好了的,具备一定基础能力的base model!
(1)前面提到了,这次是以code类数据作为训练样本的,这类数据每条大概分三部分:input、program和output,图示如下:
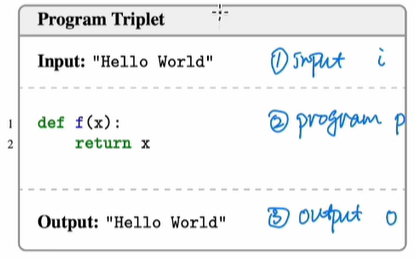
这次训练的核心思路:每条数据,proposer提供完整的三个信息,形成所谓的triplet(p,i,o)数据。然后减少其中1个信息,让solver预测缺少的这个!原论文总结如下:

上面的描述可能有点抽象,下面举一些具体的例子阐述proposer产生train data的方法和solver的训练方法;
(2)先看第一个deduction:从buffer中随机选择K个example放在prompt中作为in context learning,然后把prompt输入proposer,让proposer回答,包括两部分:文字描述cot,还有python代码(包括代码的input),这里就产生了pair(p,i)!

随即把code和其input作为prompt发给solver,让solver输出结果,如下:

solver回答对不对了?直接运行code一下不就知道了?如果正确,就得到reward;这时就得到了完整的triplet(p,i,o);这些正确的triplet(p,i,o)放回deduction buffer后续要继续用的!
(3)abduction:proposer和deduction一样,给一些reference example,这些example都是(p,i)对,把这些pair(p,i)输入proposer,让proposer模仿这些example生成新的program和input,然后再代码环境中执行(p,i)对得到output,得到triplet(p,i,o);但对于solver,此时只能看到(p,o),需要预测i的值;图示如下:

solver预测的input是不是对的了?把原来的p和solver预测的input配套在代码环境中执行一下,看看output是不是和之前的一致不就行了?只要output是对的,那就可以反推solver预测的input肯定是对的!
(4)最后一种情况:Induction,根据input和output,得到program;proposer从上面两步产生的triplet对中抽取example,产生对应的input,拼凑成(p,i)对,继续运行得到output形成triplet(p,i,o);除此,proposer还需要产生对应的任务描述message,解释任务的功能,利于solver理解任务背景、目的!对于solver,输入的是(input,output,message)对,需要输出对应的program!
具体的例子:从上面两步生成的buffer中随机选择program输入proposer,如下:

proposer模型的输出:大致分成3部分,
- 分析这段program在干什么
- 根据前面的分析提供多组input
- 提供message,介绍program的背景、功能等

最后需要把program和input放到python环境执行一下,得到output,才能形成完整的(p,i,o,m)对!
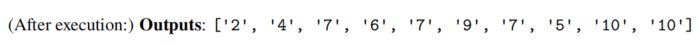
对于solver,只能看到(i,o,m),需要根据这些信息预测program!solver的输入如下:就是proposer产生的message、input、output;

solver产生的output:前面是思考过程cot,最后是最终的program;这个program是不是对的,放到环境执行一下就行了!
(5)整个训练过程总结如下:task type分三种,每次都人为去掉其中的1中,让solver去推测!proposer和solver分别都有自己的reward,用于更新参数!
(6)具体的训练算法和GRPO非常类似:advantage的计算都是找到比均值高的action!

4、效果展示:虽然train的data是code相关的,但在math上的表现也很好!AZR final model已经超过了现有的SOTA!
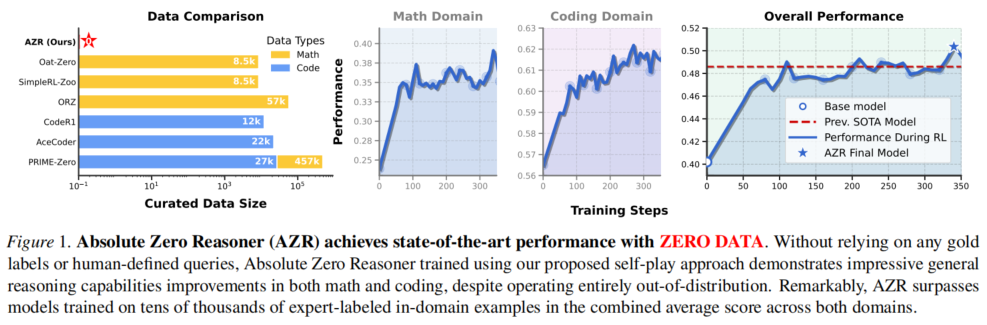
把qwen和llama作为base model后使用AZR做RL,AZR没有用现有的data,通过self-play、self-envole的方法,效果远超同类其他模型;训练data是coding类的,但是在match的表现也很好,说明model的泛化性是很好的!结论:尽量少依赖human prior的数据,让LLM自己探索,效果更好!
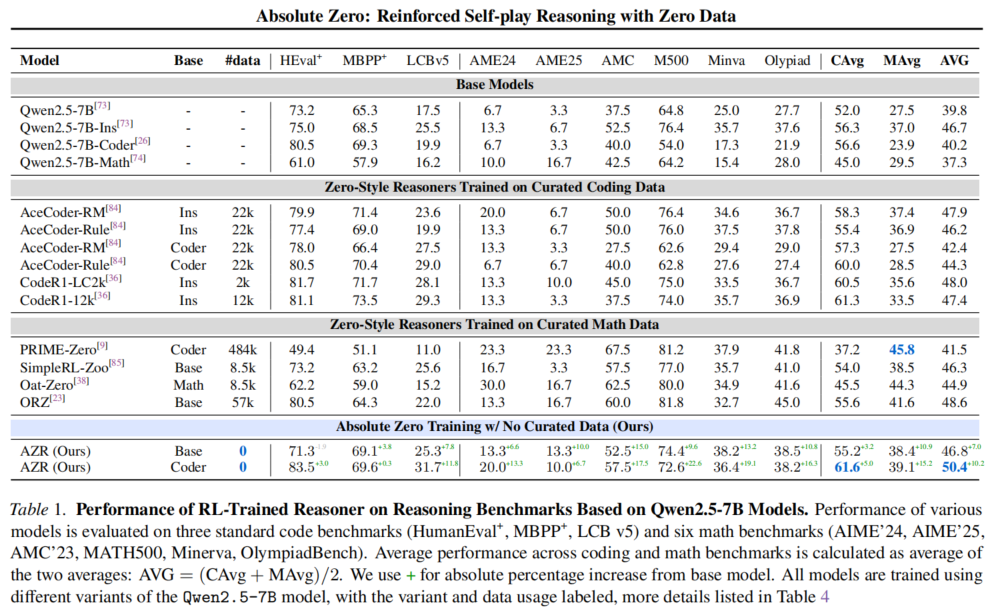
注:这里的zero-style就是deepseek R1这类的训练时没有标注cot的模型!
LLM领域,there is no free lunch!准确率等大幅提升,trade off是什么了?其他哪些功能会下降了?可能是instruction的遵从下降!模型越多的自我思考,它就会减少对于输入指令的跟随效果。
彩蛋:脱离了人类的prior data的约束,出现了一些unsafe reasoning,如下:

参考:
1、https://www.bilibili.com/video/BV1QbjNzdEVE/?spm_id_from=333.1387.homepage.video_card.click

 浙公网安备 33010602011771号
浙公网安备 33010602011771号