LLM大模型: DeepSeek-Prover-V2浅析
1、5.1假期,deepseek又整活了,不过这次并不是万众期待的R2通用推理模型,而是Prover-V2,主打 formal theorem proving in Lean 4,简单理解就是数学定理的证明,在几大数据集的测试结果如下:
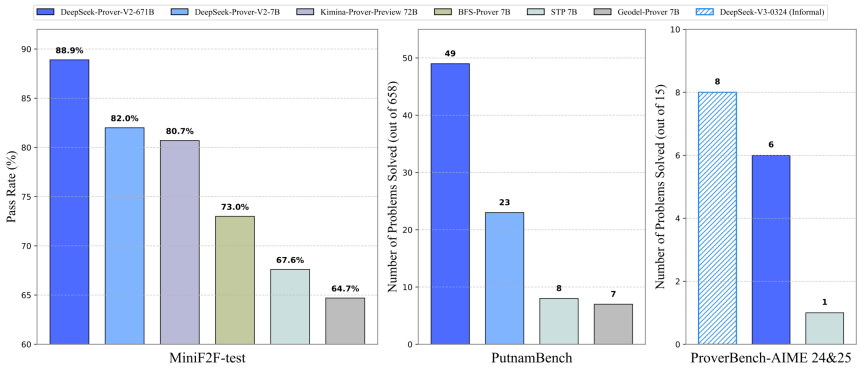
所以现在大家最关心的是:这么好的效果,都是怎么做到的?
这次开源模型主打数学定理的证明,那么首先想想人是怎么证明数学定理的了?学过数学的都知道,遇到大的、难的证明题目,必须分解成多个逻辑严密的步骤,然后挨个证明每个步骤的正确性(这不就是推理模型最早成熟的COT范式么?),这就是最常用的step-by-step的方式!既然是大模型做证明题,输出的答案肯定要人能看得懂才行嘛,否则有啥意义了,所以必然模仿人类的方式!官方的原文是这样描述的:The cold-start training procedure begins by prompting DeepSeek-V3 to decompose complex problems into a series of subgoals(用V3把复杂问题分解成一系列subgoal). The proofs of resolved subgoals are synthesized into a chain-of-thought process, combined with DeepSeek-V3's step-by-step reasoning(还是V3使用COT逐步证明每个subgoals), to create an initial cold start for reinforcement learning. This process enables us to integrate both informal and formal mathematical reasoning into a unified model(模型能输出正式或非正式的数学证明过程);该模型大的训练思路就是这样的,容易理解吧!
2、思路确定后,就要准备训练预料了!高质量的model需要高质量的数据,这些数据都是哪来的?
- 人工标注
- 其他model合成
数据证明题这类专业程度非常高的数据,要是完全靠人工标注,成本要上天,官方是这么干的:Synthesize Cold-Start Reasoning Data through Recursive Proof Search;这里的Recursive Proof Search该怎么理解?是怎么做的了?
-
To construct the cold-start dataset, we develop a simple yet effective pipeline for recursive theorem proving(递归证明), utilizing DeepSeek-V3 as a unified tool for both subgoal decomposition and formalization. We prompt DeepSeek-V3 to decompose theorems into high-level proof sketches while simultaneously formalizing these proof steps in Lean 4, resulting in a sequence of subgoals. 用V3把复杂的问题分解成自然语言形式的草稿,同时在Lean 4中将这些证明步骤形式化,从而产生一系列子目标。
-
We use a smaller 7B model to handle the proof search for each subgoal, thereby reducing the associated computational burden. Once the decomposed steps of a challenging problem are resolved, we pair the complete step-by-step formal proof with the corresponding chain-of-thought from DeepSeek-V3 to create cold-start reasoning data. 为了减少计算量,用7B的模型证明每个subgoal;一旦完成整个证明过程,这些数据会被整理成COT形式,形成冷启动数据集;
官方给的一个例子如下:证明对于任何n>=4的整数,n^2<=n!;为了证明这个,V3对原论点做分解,转成多个步骤;同时转成标准的lean 4 proof结构;然后用7B的模型证明每个步骤!

3、数据合成后,接下来就该训练了!原文分了两步:
-
High-efficiency non-Chain-of-Thought (non-CoT) mode: This mode is optimized for the rapid generation of formal Lean proof codes, focusing on producing concise proofs without explicit intermediate reasoning steps;非COT的模式,所以速度很快,聚焦于生成标准的lean代码;
-
High-precision Chain-of-Thought (CoT) mode: This mode systematically articulates intermediate reasoning steps, emphasizing transparency and logical progression, before constructing the final formal proofs.; 大家耳熟能详的COT模式了,生成精确的推理过程!
那么问题来了:传统的推理模型都是用COT,这里为啥要分两步?直接COT不好么?
- 第一个non-COT阶段:The non-CoT generation mode is chosen to accelerate iterative training and data collection processes, as it offers significantly faster inference and validation cycles;这一步的目的是加速迭代训练和训练数据收集!模型能力提升还要考后续的SFT和RL;这里采用的是expert iteration的范式,原文的解释为:In each training iteration, the current best prover policy is used to generate proof attempts for those challenging problems that remain unsolved in prior iterations. Those successful attempts, verified by Lean proof assistant, are incorporated into the SFT dataset to train an improved model. This iterative loop ensures that the model not only learns from the initial demonstration datasets but also distills its own successful reasoning traces, progressively refining its ability to solve harder problems.概括一下就是:生成-验证-学习循环这种自我迭代式的改进!
- 当前最优policy model生成前序迭代尚未解决问题的证明;
- Lean 证明助手验证这些尝试的正确性;
- 成功案例被加入监督微调(SFT)数据集,训练下一代模型。
这个过程和人思考问题的方式是不是完全一样啊!学生证明数学题时先给出一个解,老师判断是否正确,如果正确就纳入标准题库,同时学生自己也强化了解题的思路,相当于自己distills蒸馏了正确的推理路径,达到自我强化的目的!所以现在训练预料有两部分:
- 原始通过第2步中的V3和7B合成的COT数据;这部分数据distillation了V3强大的数据问题reasoning能力,有详细的解题步骤和过程;
- the CoT examples explicitly model the cognitive process of transforming mathematical intuition into formal proof structures 核心是确保训练数据严格准确,最终达到formal proof structures(数据的组织结构正式严谨,不是随意的NLP语言,而是lean 4这种容易验证的)的目的
- non-COT阶段通过expert iteration生成的lean code,这部分数据没有reasoning步骤,只有最终的结果
- The non-CoT components emphasize formal verification skills in the Lean theorem prover ecosystem:直接生成精简的 Lean 代码,适用于常规问题的快速验证,减少token消耗;难度较高的问题用上面的COT数据集验证
4、(1)按照post-train的套路,SFT后就是RL;既然是deepseek,当然要用GRPO了!Training utilizes binary rewards, where each generated Lean proof receives a reward of 1 if verified as correct and 0 otherwise lean验证助手根据结果奖励1或0分. To ensure effective learning, we curate training prompts to include only problems that are sufficiently challenging yet solvable by the supervised fine-tuned model 为了加速训练,只挑选有一定难度但又在当前SFT模型的潜在能力范围内. During each iteration, we sample 256 distinct problems, generating 32 candidate proofs per theorem with a maximum sequence length of 32,768 tokens. 每次迭代,采样256个独立的问题,每个问题产生32个答案,每次最长32K个token!
上述的方式旨在平衡挑战性与可行性,本质是让RL阶段的训练问题满足两个看似矛盾的条件:
- 足够挑战性(sufficiently challenging):问题需超出当前监督微调模型(SFT模型)的“舒适区”,存在一定失败概率,迫使模型必须通过探索新策略才能解决。
- 可被解决(solvable):问题必须在当前SFT模型的潜在能力范围内,即通过调整生成策略(如优化推理路径或子目标分解),模型有可能生成正确证明。
类比:类似于人类学习中“跳一跳够得着”的题目——既需要努力思考,又不至于完全无法理解。
(2)具体实现的意义:- 难度阈值动态调整
-
-
挑战性来源:问题可能涉及更复杂的子目标分解、需要更长的证明步骤或罕见的定理组合(如高阶数论中的非平凡构造)
-
可解性保障:通过预筛选机制(如基于SFT模型的初步尝试成功率)过滤掉完全无法解决的问题。例如,若SFT模型对某问题的零样本成功率为0%,则排除该问题;若成功率在5%-30%之间,则视为“边缘可解”而保留
-
-
课程学习(Curriculum Learning)的体现
-
随着RL迭代推进,模型能力逐步提升,筛选标准会动态调整:早期选择相对简单的问题(如MiniF2F中通过率30%的题目),后期逐步纳入更高难度问题(如Putnam竞赛级题目)。
-
-
数据效率与训练稳定性
-
避免无效探索:若问题过于简单(如SFT模型已能100%解决),RL无法获得新知识;若问题过难(SFT模型始终失败),模型因缺乏正反馈而陷入随机猜测
-
奖励稀疏性缓解:二元奖励(0/1)下,适度难度的问题可确保部分候选证明成功(奖励1),提供有效的梯度信号
-
-
上下文扩展与数据融合
-
将 DeepSeek-Prover-V1.5-Base-7B 的上下文窗口从 4K 扩展至 32K tokens,增强处理long sequence的能力
-
融合两类数据:
-
强化学习阶段数据:从 671B 模型的数据中收集的验证通过案例
-
非 CoT 数据:通过Expert Iteration 生成的精简 Lean 代码,不含中间推理步骤,提升形式化输出的效率
-
-
-
双阶段强化学习优化
-
7B 模型不仅继承大模型的蒸馏知识,还通过与大模型相同的RL阶段(采用 GRPO 算法)进一步优化策略,利用二元奖励(0/1)提升证明正确率
-
意外发现:7B 模型在特定场景(如有限基数问题)中表现出独立于大模型的新技能(例如使用
Cardinal.toNat方法),显示小模型的独特泛化潜力
-
-
互补推理模式
-
快速模式(non-CoT):直接生成精简的 Lean 代码,适用于常规问题的快速验证
-
逻辑模式(CoT):结合自然语言推理与形式化步骤,适用于复杂定理的详细推导。两种模式通过蒸馏实现互补,覆盖不同应用场景
-
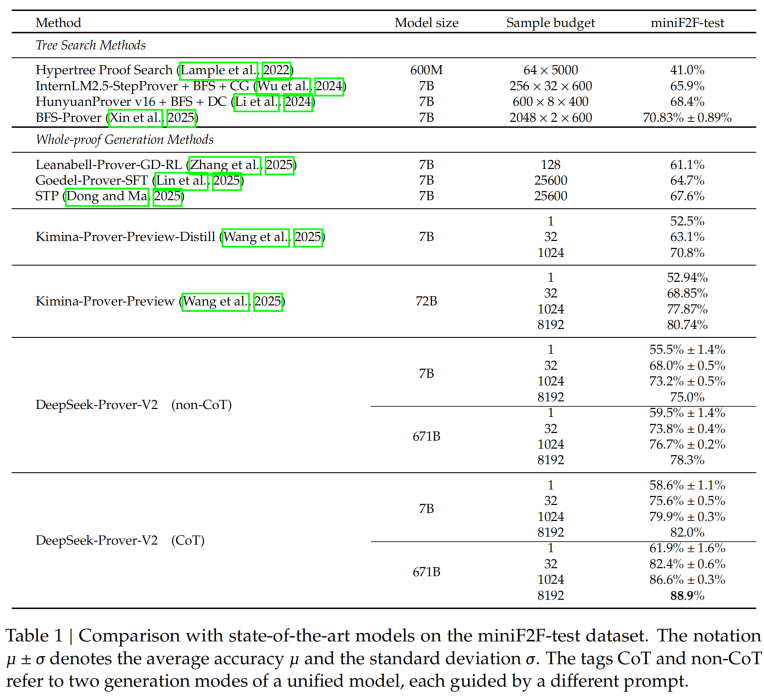
另一个数据集putnamBench的性能对比展示:
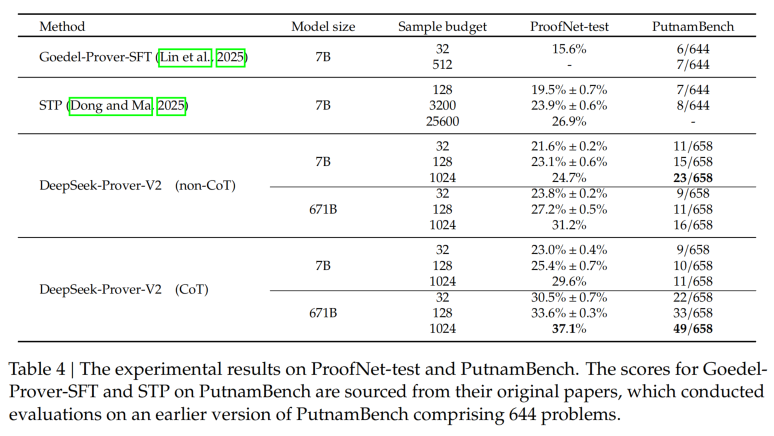
从上述的性能展示上也能看出,COT的性能明显比non-COT好,可能的原因是数学证明题,肯定需要大量的思考过程才严谨和清晰嘛!
总结:
- DeepSeek-Prover-V2在架构上没啥创新,我个人觉得在数据合成、训练方式上做了很多工作,这些思路在其他场景也是可以借鉴的!
- 以往我们关注大模型能够生成什么样的内容,而Prover-V2则更关注其能够进行怎样的证明。虽然数学是其切入点,但推理才是DeepSeek真正聚焦的核心领域。从生成普通内容向生成结构化逻辑的转变,可能是最早触及通用人工智能底层结构的途径。因为对于AI来说,尽管它可以不理解人情世故,但必须掌握推理能力。毕竟,任何知识体系的边界最终都取决于逻辑是否能够闭环以及推理是否能够成立。
- 多个model协作、各取所长会是未来的趋势!

- 如何让机器理解物理世界? How do you get machinestounderstand the physical world?
- 如何让它们拥有持续记忆?How do you get them to have persistent memory, which not too many people talk about?
- 如何实现推理能力和规划能力? And then the last two are, how do you get them to reason and plan? 貌似这个是prover-V2正在探索的事
参考:
1、https://github.com/deepseek-ai/DeepSeek-Prover-V2
2、https://www.thepaper.cn/newsDetail_forward_30757746?commTag=true
3、https://www.huxiu.com/article/4299198.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号