抖音推荐算法部分模型概述
抖音,一个世界级知名的app,全球拥有十亿级别的存量用户,其官方于近日发布了最核心的技术之一:推荐算法的部分模型,详见:https://95152.douyin.com/article/15358?enter_from=channel_page&channel=home 就其官方披露的信息看,抖音最核心的算法模型使用了:
- wide&deep模型
- 双塔模型
1、 wide&deep模型
推荐算法在20多年前互联网刚起步的时候已经萌芽,最早使用的就是user CF和item CF了。这两种CF通过计算相似性推荐item,在20多年前确实有效,但随着互联网规模扩大,user和item发生了量级的爆炸,CF的缺点越来越明显:没有提取feather,所以算法没法深入理解和挖掘user、item的特征,毫无泛化能力!推荐的结果头部效应比较明显,也就是容易造成信息单一问题(马太效应明显)。在2016年后,深度学习开始在推荐算法领域落地,deep&wide模型也成了抖音的核心推荐算法之一;整个模型的架构展示如下:
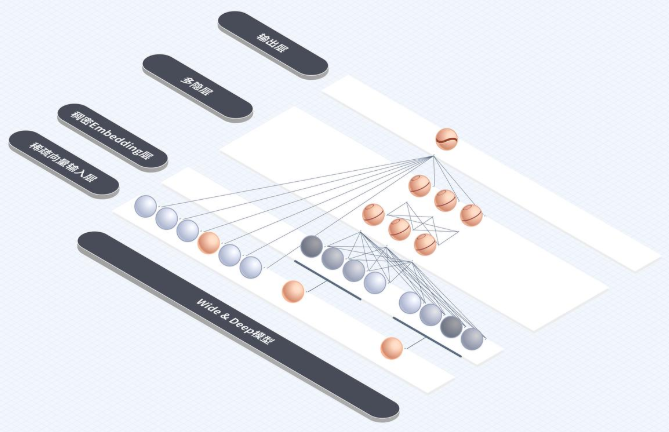
正如wide&deep算法的名称,模型的网络架构明显分成了两部分:左边的input只有一层,直接连接output,input的维度明显较多,这里就是wide了;但是右边的input维度明显少很多,而且有很多layer了,原始的input经过多层layer后再连接到output,那么问题来了:为什么要分成两部分?为什么wide只有一层,而deep有很多层?wide和deep的作用分别是什么?
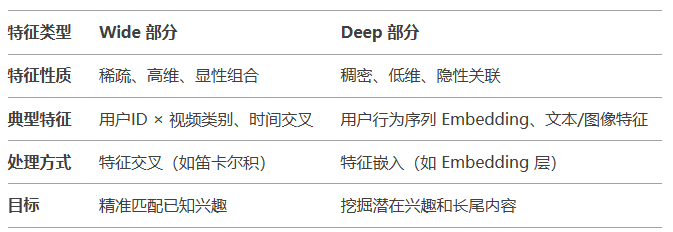
推荐的终极目标:找到user已经感兴趣的item(比如买了niek的鞋,可能对阿迪的鞋也感兴趣),和未来可能感兴趣的长尾item(比如买了运动鞋,可能对运动衣/库、足球/篮球/排球等感兴趣;这些信息都包含在embedding向量里面了)!目前最流行的方式是借助机器学习、深度学习、LLM来实现!不论是哪种方式,推荐效果好的核心要点都一样:需要好的feather,所以传统机器学习耗时最多的就是feather engineering!推荐系统用的也是各种机器学习、深度学习、LLM的算法,为了让最终的效果好,也需要构造好的feather!在推荐系统中,feather大致分成这么两类:一类是稀疏、高维、显性组合,另一类是稠密、低维、隐性关联,接下来详细说明这两类特征的特点;
(1) 稀疏、高维、显性组合的feather:
- user profile:用户age、gender、职业、兴趣爱好、地区......
- item profile: item的属性,比如item类别、尺寸、功能、性能、颜色、重量......
- user对item的行为:浏览、点击、点赞、评论、购买、投诉......
这类feather有明显的特点:
- 稀疏:比如user profile,不是每个user都有这么多维度;item同理;user对item的行为也是差异很大!所以如果用one-hot向量摊开,向量是非常sparse的
- 高维:每个领域都用one-hot表示,维度高达几十万维
- 显性组合:为了构造更好的特征,一般需要把上述多个领域的特征做N阶交叉,比如”男性+体育“、”女性+美妆“、”地域+美食探店“等,然后训练LR等模型
这部分特征的核心功能:精准匹配已知兴趣;比如男性用户看了dota视频,wide部分会继续推荐星际争霸的视频;
(2)稠密、低维、隐性关联的feather:上述feather都是直接能得到的,并且有明显业务意义的!除了这些明显的业务特征,是不是还需要继续挖掘一些隐藏特征了?这就是DNN最核心的用途了!DNN通过MLP,把低维的特征转成稠密的embedding,这个embedding就隐藏了很多关联的feather。这些feather可能没有明显的业务意义(比如人可能看不懂这些feather的含义),但这些feather用于down stream task的效果奇好!比如:
- 用户行为序列:这是个时序数据,可以通过DNN甚至LLM把时序数据转成embedding,这个embedding就代表了用户的行为特征!
- item的内容:内容可以是text,也可以是音视频,也可以通过DNN或LLM,把item的内容转成embedding,这个embedding就代表了item的特征!
既然通过embedding挖掘除了隐藏feather,这部分隐藏feather用来干啥了?核心目的是:挖掘潜在兴趣和长尾内容;比如女性用户浏览了口红,说明对美妆感兴趣,那么deep会继续推进啊粉底、眉笔、连衣裙等打扮类的item;男性用户看了运动鞋,deep模型会继续推荐手套、遮阳帽、登山杖之类的运动用品;
总结:wide&deep分别用户精准匹配已知兴趣、挖掘潜在兴趣和长尾item,两者的对比如下:
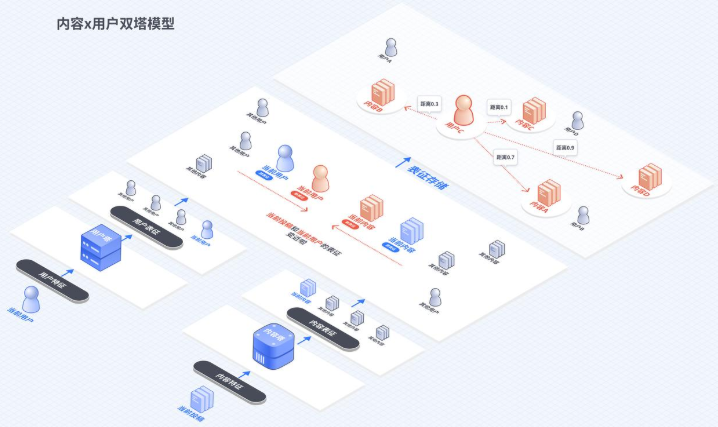
2、推荐的一般流程:召回->粗排->精排->重排,上述的wide&deep使用了DNN,计算量很大,所以一般用于精排;那前面的召回又是怎么做的了? 召回的目的是从百万、千万级别的item中找到几万、甚至几千个备选item,数量巨大,所以召回算法不能复杂,否则延迟会异常大!召回的思路之一:把user、item接近的、能配对的放在一起!怎么判断user和item配对了?
还记得CLIP么?使用text检索image的模型:把text和clip都转成embedding,然后计算embedding的距离,越近的说明越匹配!这里的user和item配对不也是一个原理么:把user embedding和item embedding分别求出来,计算两者之间的距离不久行了么?user-item双塔模型图示:
参考:
1、https://95152.douyin.com/article/15358?enter_from=channel_page&channel=home 从零开始了解推荐系统

 浙公网安备 33010602011771号
浙公网安备 33010602011771号