LLM大模型:post-training方法概述
现目前市面上主流大模型都是分步骤训练出来的:
- pre-train:让LLM具备初步的存储、记忆和理解知识的能力(目前互联网的优质token已经被耗尽,pre-train几乎走到了尽头,后续就看post-train了!)
- post-train:让LLM更精准、聪明,能适配某些垂直领域的特定任务!post-train中,reinforcement learning绝对是核心方法!GRPO简单有效,后续会成为主流方法!
所以post-train其实更重要,那么业界最流行的post-train都有哪些做法了?https://arxiv.org/abs/2502.21321 LLM Post-Training: A Deep Dive into Reasoning Large Language Models 系统性地总结了以下步骤:
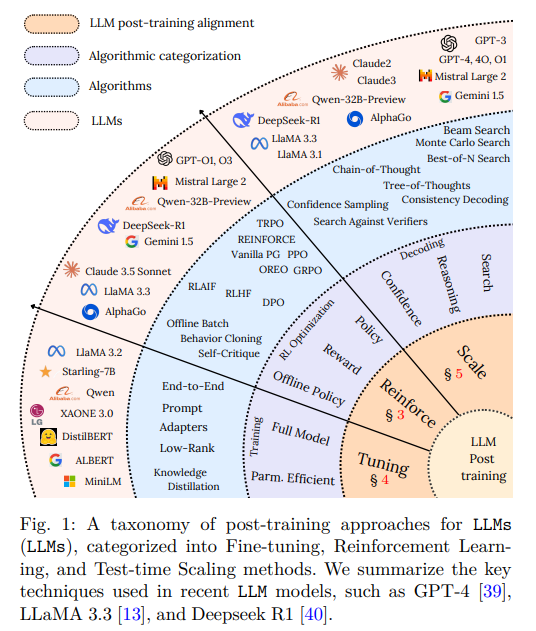
1、微调(Fine-Tuning):让LLM适配特定垂直领域的任务。但是如果fine-tune过火,可能出现over-fitting、Catastrophic Forgetting等让LLM退步的问题,常见的fine-tuning方法:
-
全参数微调(Full Fine-Tuning) :
-
调整模型的全部参数,能带来最佳效果,但计算开销巨大,并且可能导致灾难性遗忘(Catastrophic Forgetting)。可以用deepspeed做全参微调!
-
适用于医学、法律等需要高度定制化的专业领域模型
-
- 低秩适配(LoRA,Low-Rank Adaptation)
-
-
仅训练特定层的低秩矩阵,大幅降低计算量,同时保留模型的泛化能力。
-
广泛应用于开源大模型(如LLaMA系列),尤其适合数据有限、算力也有限场景。
-
- 适配器(Adapters)
- 在模型的特定层插入小型模块,使底层能力可共享,并支持多任务学习(Multi-Task Learning)
-
适用于需要同时处理多个领域任务的场景
2、 Reinforcement learning:通过reward优化模型决策,使其回答更符合人类偏好、更加逻辑清晰
- 人类反馈强化学习(RLHF,Reinforcement Learning from Human Feedback)
-
训练一个奖励模型(Reward Model),根据人类偏好对模型输出评分;当然也可以魔改:用正则、规则等方式计算reward,效率更高;reward也更准确!
-
通过策略优化(如PPO,Proximal Policy Optimization)调整模型,使其回答风格更符合人类需求
-
GPT-4、Claude3等顶级模型均采用RLHF,以减少幻觉(hallucination)并优化对话体验
-
-
直接偏好优化(DPO,Direct Preference Optimization)
-
直接基于偏好数据优化模型参数;比如正对同一个prompt,LLM产生3个response,然后让用户选择最喜欢的一个response,后续LLM的回答尽可能接近用户最喜欢的这个response,远离不喜欢的
-
训练过程比RLHF更稳定,且效果接近甚至优于RLHF
- DPO
-
-
群体相对策略优化(GRPO,Group Relative Policy Optimization)
-
改进PPO训练方式,不依赖独立的value function,而是通过对比多个responce优化策略;比如找到reward大于均值的输出,然后通过这个update 参数!
-
提高模型的稳定性,减少Reward Hacking,让LLM真正学到response的逻辑
-
三者的直观对比:
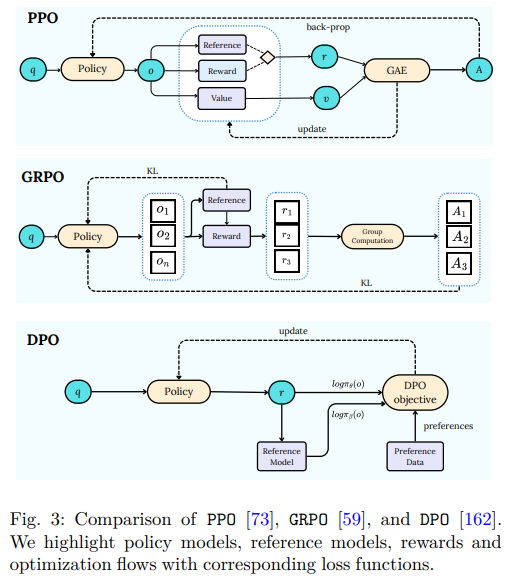
个人观点:
- DPO和GRPO没有本质区别,核心思路都是一样的:LLM针对同一个promt产生多个response,然后尽可能向好的response靠近(通过update网络参数,让reward高的response能以更高的概率生成!)至于怎么鉴别response好不好,DPO使用的是人工选择标注,GRPO使用的是规则判断!
- SFT是特殊的reinforcement learning!
- 网上很多RL的教程都是以bottom up的方式教学,一上来就是各种概念和算法实现细节,初学RL时会造成很大的困惑:这些概念和各种各样让人眼花缭乱的细节为什么这么设计了?都是干什么用的了?普通人很容易陷入局部细节无法自拔!所以在学RL之前,一定要想清楚RL的原理,看清楚RL的大方向。只有搞清楚这些,再遇到概念和细节问题时,才能以top down的视角理解概念和细节,完成“降维打击” !整个reinforcement learning的原理都一样:都是做大量尝试self-exploration&exploit,选择最好的top k个response作为目标来update parameters!self-training就是手动实现RL,DPO、PPO、GRPO是写代码自动实现RL的过程!
- RL最难的就是reward的设置;如果每个step都能设置合理的reward,那RL就是由大量监督学习组成的了!RL也就转换成监督学习了!
- RL各种算法,最核心的目的就是给每个step设置合理的reward
- PPO的目标是整个chain中累加的reward最大,所以需要一个value function来统计整体的value值,这个value值是每一步的reward累加得到的!而GRPO、DPO简单粗暴,直接从多个response中奔着最好的response去的,中间过程并不关心!
LLM3、推理增强(Test-Time Scaling):无需改动参数,专注于优化推理策略,也能提升推理能力
- chain of thoughts
-
让模型分步骤推理,而非直接给出答案
-
数学题中先列出解题步骤,再得出最终答案,可显著提升复杂推理任务的准确率
-
GPT-4、Claude3、Gemini等大模型均已广泛采用CoT
-
- Tree of thoughts/graph of thoughts
-
在CoT基础上扩展,使模型能探索多个可能解法,再选择最优解
-
AI版的头脑风暴,适用于数学、编程、科学推理等复杂任务
-
- Self-Consistency 自一致性
-
多次尝试:让LLM在推理时生成多个答案,并选择出现频率最高的答案作为最终结果
-
该方法能提高模型在复杂问答和数学计算上的准确率,毕竟尝试多次,肯定有蒙对的时候
-
- Episodic Memory 记忆增强
-
让LLM在推理过程中“记住”先前的推理步骤,避免重复错误
- 能让LLM在对话时保持一致性
-
总结一下:LLM做post train的方法和步骤
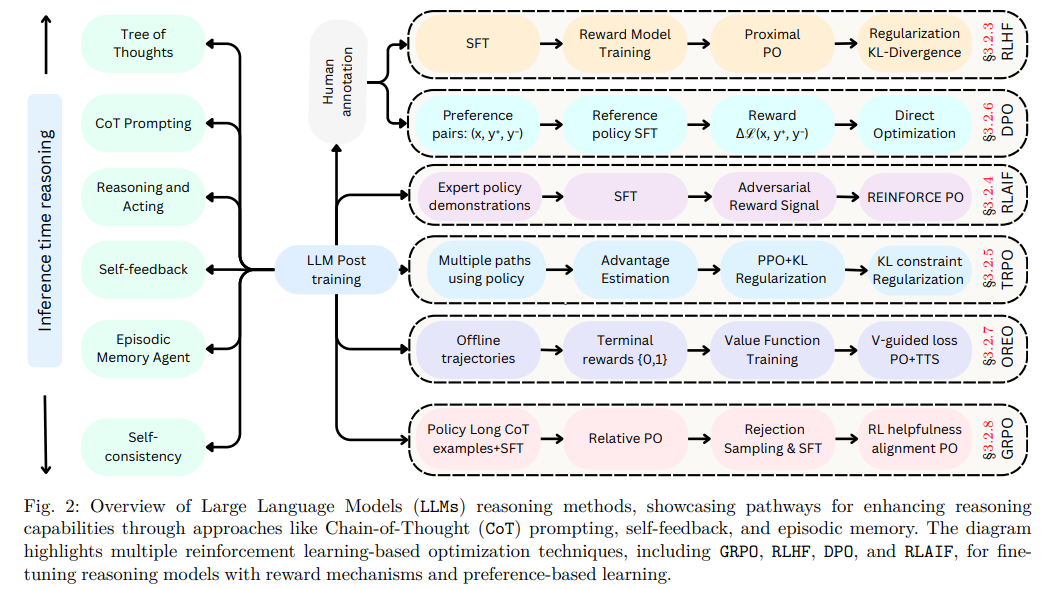
- Inference time reasoning 模型推理时可以采用的不同策略来增强其推理能力。
-
树状思考(Tree of Thoughts):通过生成逻辑上连贯的推理步骤来解决问题。
-
CoT 提示(CoT Prompting):提示模型生成逐步的推理过程。
-
推理与行动(Reasoning and Acting):模型根据给定的输入进行推理并采取行动。
-
自我反馈(Self-feedback):模型根据其生成的输出进行自我评估和调整。
-
情景记忆代理(Episodic Memory Agent):模型利用过去的经历来辅助当前的推理过程。
-
自我一致性(Self-consistency):确保模型输出的一致性和逻辑性。
-
- Human annotation 人工标注:人工标注好数据后,可以通过这种链条一步一步训练模型
- LLM Post training 后训练:
-
监督式微调(SFT):使用高质量的人类标注数据对模型进行微调。
-
奖励模型训练(Reward Model Training):训练一个模型来预测给定输入的奖励分数。
-
近端点策略优化(Proximal Policy Optimization,PPO):优化策略以最大化预期回报。
-
优势函数(Advantage Function):用于估计在特定状态下采取特定行动的价值。
-
直接优化(Direct Optimization):直接根据reward优化模型参数。
-
- 多种路径使用策略(Multiple paths using policy):通过探索多种可能的行动路径来增强模型的决策能力
- Offline trajectories:利用预先收集的数据轨迹来训练模型
- 基于reward的优化技术
-
REINFORCE PO:结合了奖励信号和策略优化。
-
PPO+KL 正则化:结合了PPO和KL正则化来稳定训练过程。
-
V-guided loss PO+TTS:使用价值函数引导的损失进行策略优化。
-
RL有用性对齐 PO:通过强化学习来优化模型的有用性。
-
参考:
1、https://arxiv.org/abs/2502.21321 LLM Post-Training: A Deep Dive into Reasoning Large Language Models
3、https://mp.weixin.qq.com/s/Ap-CBnqL_BxXH-bpH0CiTA HuggingFace 手把手教你构建DeepSeek-R1推理模型!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号