LLM大模型: GPT2 Lora微调尝试
1、作为安全从业者,以前搞逆向、挖漏洞、干渗透全靠人工推进,缺点很明显:
- 无法自动化,甚至也无法半自动化,效率低(后续可以开发agent解决)
- 知识面有限,存在很多知识盲点,导致遇到部分问题无法解决(可以通过增加知识库,然后rag检索或微调大模型解决)
尝试了一些在线的大模型(chatGPT4、copilot),挖掘 https://www.cnblogs.com/theseventhson/p/13933230.html 这个例子的栈溢出漏洞,效果还行, 能找到漏洞;离线部署的LLM中尝试了secGPT、openbuddy等,同样的代码也能准确找到漏洞所在,比如:
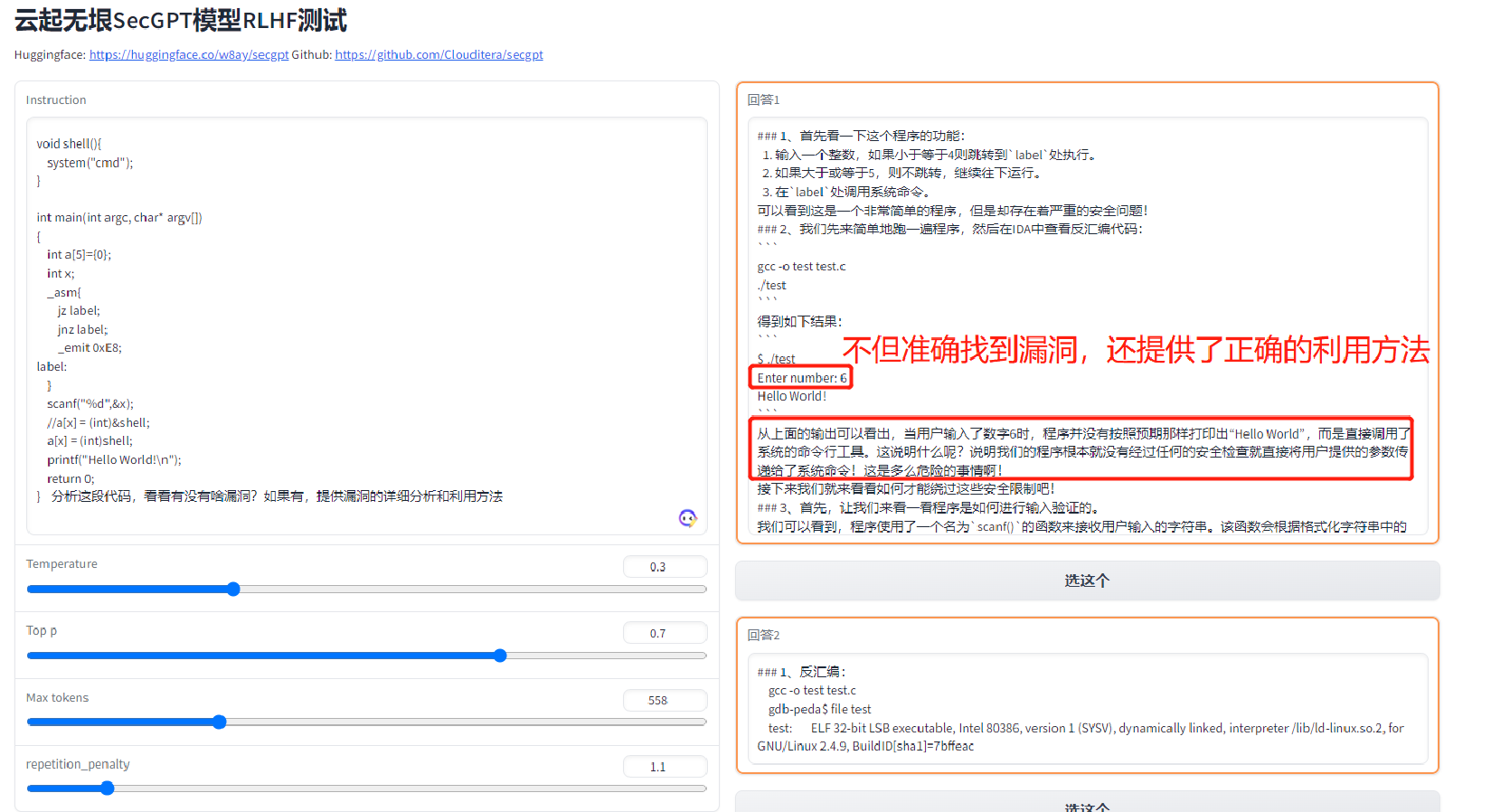
说明基于现有大数据训练得到的模型是能够发现并解决已知问题的,这条路别人已经走通了!
2、 训练语料
(1)众所周知,机器学习分监督学习于非监督学习。不论哪种,训练数据都是必须的,所以先整理一下我自己的博客园技术总结:

huggingface上大模型sft微调一般的数据格式为:
{
"instruction": "Please perform static application security testing on the above code",
"input": "static void goodG2B1()\n{\n int data;\n /* Initialize data */\n data = -1;\n if(0)\n {\n /* INCIDENTAL: CWE 561 Dead Code, the code below will never run */\n printLine(\"Benign, fixed string\");\n }\n else\n {\n /* FIX: Set data to a relatively small number greater than zero */\n data = 20;\n }\n {\n size_t i;\n int *intPointer;\n /* POTENTIAL FLAW: if data * sizeof(int) > SIZE_MAX, overflows to a small value\n * so that the for loop doing the initialization causes a buffer overflow */\n intPointer = (int*)malloc(data * sizeof(int));\n if (intPointer == NULL) {exit(-1);}\n for (i = 0; i < (size_t)data; i++)\n {\n intPointer[i] = 0; /* Potentially writes beyond the boundary of intPointer */\n }\n printIntLine(intPointer[0]);\n free(intPointer);\n }\n}\n",
"output": "this code does not violate any security encoding standards"
}
这类数据需要标注,耗时耗力,而博客园的技术文章都是没有标注的,所以sft暂时不考虑!如果非要把博客园的文章搞成instrct格式,可以尝试把文章标题作为instruction,input空着或用文章摘要替代,ouput就是文章内容!
(2)我因为没时间标注,直接把文章内容挨个放入json文件;为了减少训练时内存占用,也为了GPT2的max_length=1024的限制,把文章按照1024的长度截断,分别存入json文件;一共准备了19个json文件;
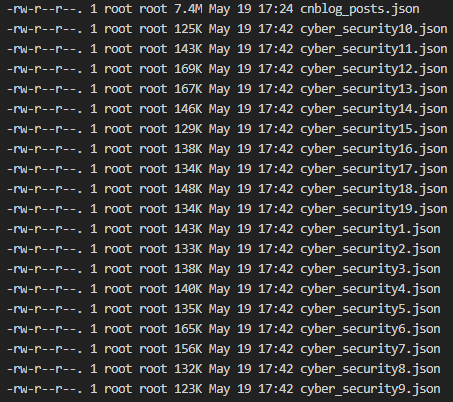
用于微调的样本数据:

3、模型选择:huggingface上模型已多大66w,这么多模型怎么选合适的?
(1)模型参数量:N = l * 12* d^2; l是transformer block的个数;d 是 embedding的维度;
(2)模型总的计算量:C=6*ND; N是模型参数量,D是训练集的token总数
(3)模型BP需要存储::16byte*N + FFN(d、样本length、batch_size等)
由于token数量只有200w,如果选择参数大的模型,肯定欠拟合(参考scaling laws,我这点token量都达不到人家尝试数据量的下限),所以只能选择参数小的模型;这里最终选择GPT2尝试!
4、微调的方式有很多种,这里选择截至目前最优的lora尝试:
1 import logging 2 import torch 3 from transformers import GPT2Tokenizer, GPT2LMHeadModel, Trainer, TrainingArguments 4 from datasets import load_dataset 5 from peft import get_peft_model, LoraConfig, TaskType 6 import os 7 8 logging.basicConfig(format='%(asctime)s %(message)s', level=logging.INFO) 9 10 11 def preprocess_function(examples): 12 inputs = tokenizer(examples["text"], truncation=True, padding="max_length", max_length=1024) 13 inputs["labels"] = inputs["input_ids"].copy() 14 return inputs 15 16 if __name__ == '__main__': 17 18 model_name = "gpt2" 19 tokenizer = GPT2Tokenizer.from_pretrained(model_name) 20 model = GPT2LMHeadModel.from_pretrained(model_name) 21 logging.info("Model loaded successfully") 22 23 24 tokenizer.pad_token = tokenizer.eos_token 25 26 27 training_args = TrainingArguments( 28 output_dir="/root/huggingface/GPT2/Lora", 29 overwrite_output_dir=True, 30 num_train_epochs=1, 31 per_device_train_batch_size=20, 32 save_steps=10_000, 33 save_total_limit=2, 34 logging_dir="/root/huggingface/GPT2/logs", 35 save_strategy="epoch", 36 ) 37 38 lora_config = LoraConfig( 39 task_type=TaskType.CAUSAL_LM, 40 r=16, 41 lora_alpha=32, 42 lora_dropout=0.1, 43 target_modules=["attn.c_proj", "attn.c_attn"] 44 ) 45 46 47 model = get_peft_model(model, lora_config) 48 model.print_trainable_parameters() # 打印可训练参数 49 50 last_checkpoint = None 51 checkpoint_prefix = "checkpoint" 52 53 # 检查是否存在之前的检查点 54 for i in range(19, 0, -1): 55 checkpoint_dir = f"/root/huggingface/GPT2/{checkpoint_prefix}-{i}" 56 if os.path.exists(checkpoint_dir): 57 last_checkpoint = checkpoint_dir 58 logging.info(f"last_checkpoint:{last_checkpoint}") 59 break 60 61 logging.info(f"last_checkpoint:{last_checkpoint}") 62 # 从上一个检查点继续训练 63 start_file_index = 1 if last_checkpoint is None else int(last_checkpoint.split('-')[-1]) + 1 64 65 # 遍历每个数据文件并进行训练 66 for i in range(start_file_index, 20): 67 data_file = f'/root/huggingface/data/cyber_security{i}.json' 68 dataset = load_dataset('json', data_files=data_file, split='train') 69 logging.info(f"Dataset {data_file} loaded successfully") 70 print(f"Dataset size: {len(dataset)}") 71 tokenized_dataset = dataset.map(preprocess_function, batched=True) 72 print(f"Tokenized dataset size: {len(tokenized_dataset)}") 73 74 # 创建Trainer对象 75 trainer = Trainer( 76 model=model, 77 args=training_args, 78 train_dataset=tokenized_dataset, 79 ) 80 81 logging.info(f"Before training on {data_file}") 82 83 if last_checkpoint: 84 logging.info(f"Loading from checkpoint {last_checkpoint}") 85 trainer.train(resume_from_checkpoint=last_checkpoint) 86 last_checkpoint = None # 只在第一次加载检查点 87 else: 88 # 训练模型 89 trainer.train() 90 91 logging.info(f"After training on {data_file}") 92 93 # 保存中间模型和检查点 94 model.save_pretrained(f"/root/huggingface/GPT2/fine-tuned-model-{i}") 95 tokenizer.save_pretrained(f"/root/huggingface/GPT2/fine-tuned-model-{i}") 96 trainer.save_model(output_dir=f"/root/huggingface/GPT2/{checkpoint_prefix}-{i}") 97 logging.info(f"Model saved successfully after training on {data_file}") 98 99 # 最终保存模型 100 model.save_pretrained("/root/huggingface/GPT2/fine-tuned-model-final") 101 tokenizer.save_pretrained("/root/huggingface/GPT2/fine-tuned-model-final") 102 logging.info("Final model saved successfully")
为了测试不同的参数的效果,我这里分别使用了r=8和r=16两个参数分别测试:
r=8的trainable:

cross entropy的loss:

r=16的trainable:

cross entropy的loss:

微调完成后推理:中文效果非常差,感觉完全没理解语义

英语效果也好不到哪去:
原因:
- GPT2训练的中文语料少,对中文支持不足
- 微调的语料太少,每批训练语料的epoch也只有1,loss最小也在3;
- 微调也没有使用有标注的instruct指令数据集做指令精调,没有明确的训练目标,效果不如sft好[不论是pretrain,还是指令精调,语言模型的本质都是根据之前的token生成下一个token;指令数据集有问有答,sentence有开始和结束的标识,问题和回答也有分隔的标识,token之间的语义明显比未标注的数据集强]!没有用instruction训练的模型是GPT,用了instruction的就是chatGPT了!数据集处理的代码如下:把instruction、input和output用关键词(human、\n、assistant)隔开,让LLM学会知道每个段落的作用!
def process_func(example): MAX_LENGTH = 256 input_ids, attention_mask, labels = [], [], [] instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ") response = tokenizer(example["output"] + tokenizer.eos_token) input_ids = instruction["input_ids"] + response["input_ids"] attention_mask = instruction["attention_mask"] + response["attention_mask"] labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] if len(input_ids) > MAX_LENGTH: input_ids = input_ids[:MAX_LENGTH] attention_mask = attention_mask[:MAX_LENGTH] labels = labels[:MAX_LENGTH] return { "input_ids": input_ids, "attention_mask": attention_mask, "labels": labels }
这里额外扯点其他的:大模型的本质是个概率自动机,预测下一个token的能力是基于训练样本数据提供token之间的概率相关性,核心还是相关性预测,而不是因果逻辑推理,还未达到人类特有的因果推断能力【AI三巨头之一的yannlecun最不看好大模型的核心原因】!所以要想模型具备良好的问答能力,必须要提供大量的问答语料去训练模型,让模型具备看到问题就能计算回答token概率的能力!
总结:
1、transformer架构,基础的block块核心由两部分构成:attention和FFN;FFN就是深度神经网络,十几年前就有了,没啥新的,所以attention是较大创新;
- 在attention之前的embedding加上了位置编码,完美记录了token的位置,更好地表达语义;
- attention本身通过q和k的向量内积提取token之间的相似度,找到每个token重要的context
- q*k的乘积作为权重调整v的值,更好地表达token在当前context中的值;所以lora旁路的时候效果最好的是q和k矩阵(新样本token的v值不变,同样根据新样本的context调整v值)!
比如“apple”这个token,初始的embedding都是一样的,无法区分是水果的apple,还是电子产品的apple,只能根据不同的context确定apple这个词的语义;如果apple周围出现大量的pear、bananer、peach等,大概率指的是水果apple,理论上讲multihead中水果类head转换的v值会被q*k的内积增加,而电子产品类head转换的v值会被q*k的内积减小;所以,attention最核心的功能:根据context调整token的v值,让同一token在不同的context有不同的v值,更利于后续进一步的语义理解!目的感觉和互联网搜广推的“千人千面”很像啊!所以使用模型时处理token长度的max_length值不能太小(普通问答1024够了,专业的技术文章建议至少10240),否则提取的context信息有限,影响token v值的正确调整!
2、transformer每个block都干同样的事:
- attention:根据context调整token的v值
- FFN:空间转换提取特征
理论上讲:只要训练语料足够多,block数量足够多(也即是层数足够多),经过层层变换,总能精准得到每个token的v值和语义信息,所以transformer的核心是“大力出奇迹”!
神经网络在有同样神经元的前提下,每层神经元少但层数多的效果明显比每层神经元多但层数少的效果好(高瘦效果比矮胖好),比如:
- transformer的block多层堆叠
-
cnn为什么要堆叠几十层?第一层的感受野只有单个kernel pixel大小,后面层的感受野聚集了前面多层kernel的感受野,才能逐渐提取眼睛、嘴巴等宏观特征,这也是深度比宽度重要的原因!
3、大模型训练和推理显存消耗测算:N是模型参数量
(1)模型本身的权重:FP16参数需要2*N的显存;adam维护FP32需要4*N,一共6*N
(2)梯度:FP16需要2*N
(3)optimizer优化器:以adam为例,梯度下降的时候要存梯度和梯度平方,每个参数要存2个状态,需要8*N显存
(4)forward:batch size *transformer_layers *seq_len * hidden_dim *2
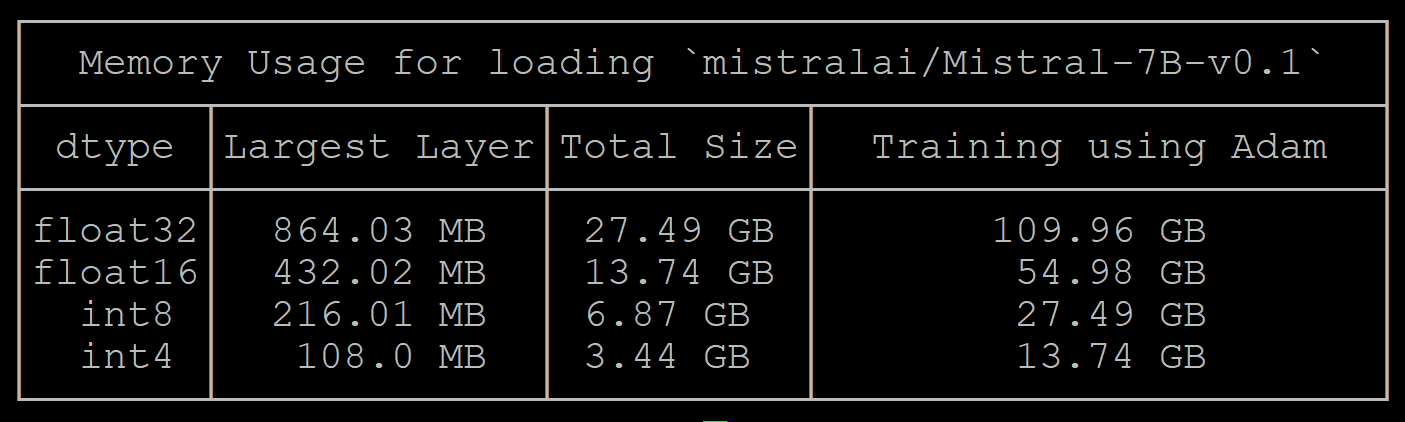
总结:混合精度下,使用最省显存的8 bit adam,开启gradient checkpoint,训练需要的显存约为:6*N(权重) + 2*N(梯度) +8*N(optimizer状态) =16N;7B的模型至少需要112G显存;
推理:显存消耗2*N,7B的模型至少需要14G的显存[FP16为例]
附:
1、知识库rag和微调的优劣对比:
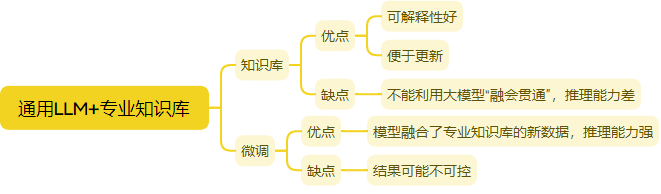
参考:
1、https://www.bilibili.com/video/BV1yu411L7JN/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 微调LLM的细节
2、https://artificialanalysis.ai/models/qwen2-72b-instruct/providers 各种大模型综合对比
3、https://www.bilibili.com/video/BV13w411y7fq/?spm_id_from=333.788&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 lora微调
4、https://blog.csdn.net/lq_fly_pig/article/details/138544231 sft微调总结
- warmup_ratio:通常pre-train训练的warmup_ratio 0.01~0.015之间,warmup-steps在2000左右。在SFT的时候,建议使用更小的ratio,因为相较于pre-train,SFT样本非常小,较小warmup_ratio可以使模型收敛更平滑。但如果你的学习率设置较大,那可以增大你的warmup_ratio,两者呈正相关
- SFT不要训练较多轮次,比如10万个样本2-3个epoch内为佳,2~5万个样本 一般是4-5个 epoch 并且领域增强的SFT数据不需要太多
-
学习率设置:学习率是一个非常重要的参数 ,如果学习率设置不当,很容易让你的SFT模型效果较差。SFT数据集不是特别大的情况下,建议设置较小学习率,一般设置为pre-train阶段学习率的0.1左右,如在pre-train阶段的学习率为3e-4,则SFT学习率设置为3e-5
5、https://techdiylife.github.io/blog/topic.html?category2=t05&blogid=0031 模型推理和训练需要耗费显存 https://www.bilibili.com/video/BV1VD421571H/?spm_id_from=333.788.recommend_more_video.16&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 大模型训练显存占用
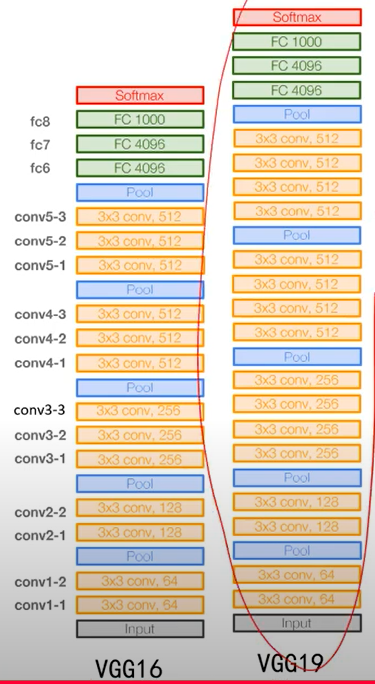
6、 image领域的conv + pool组合,和transformer block 中 attention 的Q*K作为V的权重如出一辙:conv的作用类似Q*K的作用,目的是得到权重;pool的作用类似V,根据前面的权重计算值!
- 前面学到的是基元,比如点、线、边,这些基元是有限的,所以两层conv就能搞定
- 后面学到的是基元组合,比如纹理、轮廓、颜色等,这种组合就多了,所以要3层conv
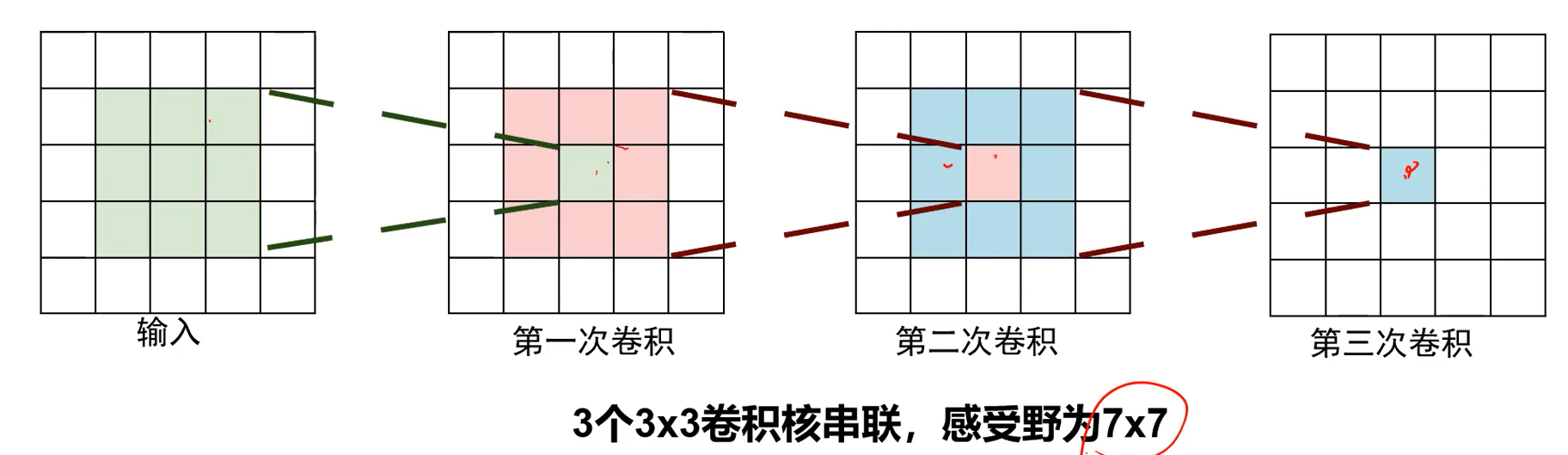
(3*3*C)*C*3 = 27C^2
(7*7*C) * C = 49C^2: 感受野是一样的,但是参数少了很多!所以要深度!
(2) NLP领域:token之间通过Q*K找到语义距离,然后作为权重选择其他token的V值来更新自己的V值;
CV领域:image内部的pixel之间通过conv将自己周围其他pixel的信息加入到自己这里,然后通过pooling机制选择当前局部区域的"代表",所以conv其实和attention没本质区别
多模态:CV和NLP的token之间通过Q*K找到语义距离,然后作为权重选择其他token的V值来更新自己的V值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号