JS混淆代码数据集构建方法
- 数据获取
(1)公开JS数据集,比如CodeSearchNet;
(2)自行构建JS数据集,爬取Github开源前端项目;
- 数据描述
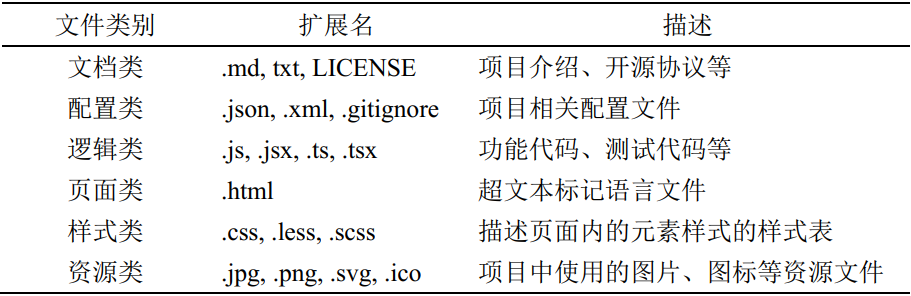
Github中采集前端项目文件分类如下,从中提取JS文件
- 数据预处理
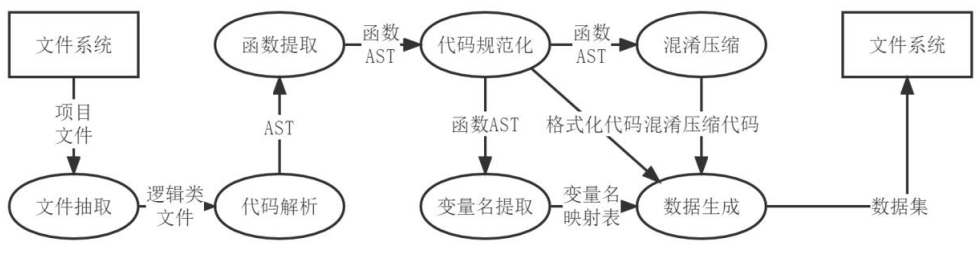
其中比较重要的步骤:
(1)代码混淆:使用现有工具,如UglifyJS、Terser、babel-minify、JS-Obfuscator;
以UglifyJS为例,结果如下(混淆前-->混淆后);


(2)变量名提取:包括静态解析和动态分析两种方法;通过静态解析的方式可递归遍历抽象语法树节点以提取代码中定义的变量名。静态解析的一种常用方法如下:
采用DTW算法,通过声明变量的节点到抽象语法树根节点的路径来表征该变量,然后计算原始代码的抽象语法树变量路径和混淆代码抽象语法树 中变量表征路径的相似度来进行变量名匹配, 以此创建变量名映射表(即原始变量 名和混淆变量名构成的键值对), 同时在此过程中丢弃不包含变量名的函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号