JSnaughty: Recovering Clear, Natural Identifiers from Obfuscated JS Names
- 发表:FSE,2017,卡内基梅隆大学, Bogdan Vasilescu团队(https://bvasiles.github.io/);加利福尼亚大学戴维斯分校,Casey Casalnuovo团队(https://caseycas.github.io/)和 Premkumar Devanbu团队(https://web.cs.ucdavis.edu/~devanbu/)(https://cmustrudel.github.io/projects/jsnaughty/),
- 开源:https://cmustrudel.github.io/projects/jsnaughty/ (工具现已停用,代码开源,提供docker镜像)
- 内容概括
本文描述了一种基于统计机器翻译(SMT)的方法AUTONYM,加入JSNice互补,恢复被UglifyJS混淆的JS程序中的标识符名称。
整个架构图如下:
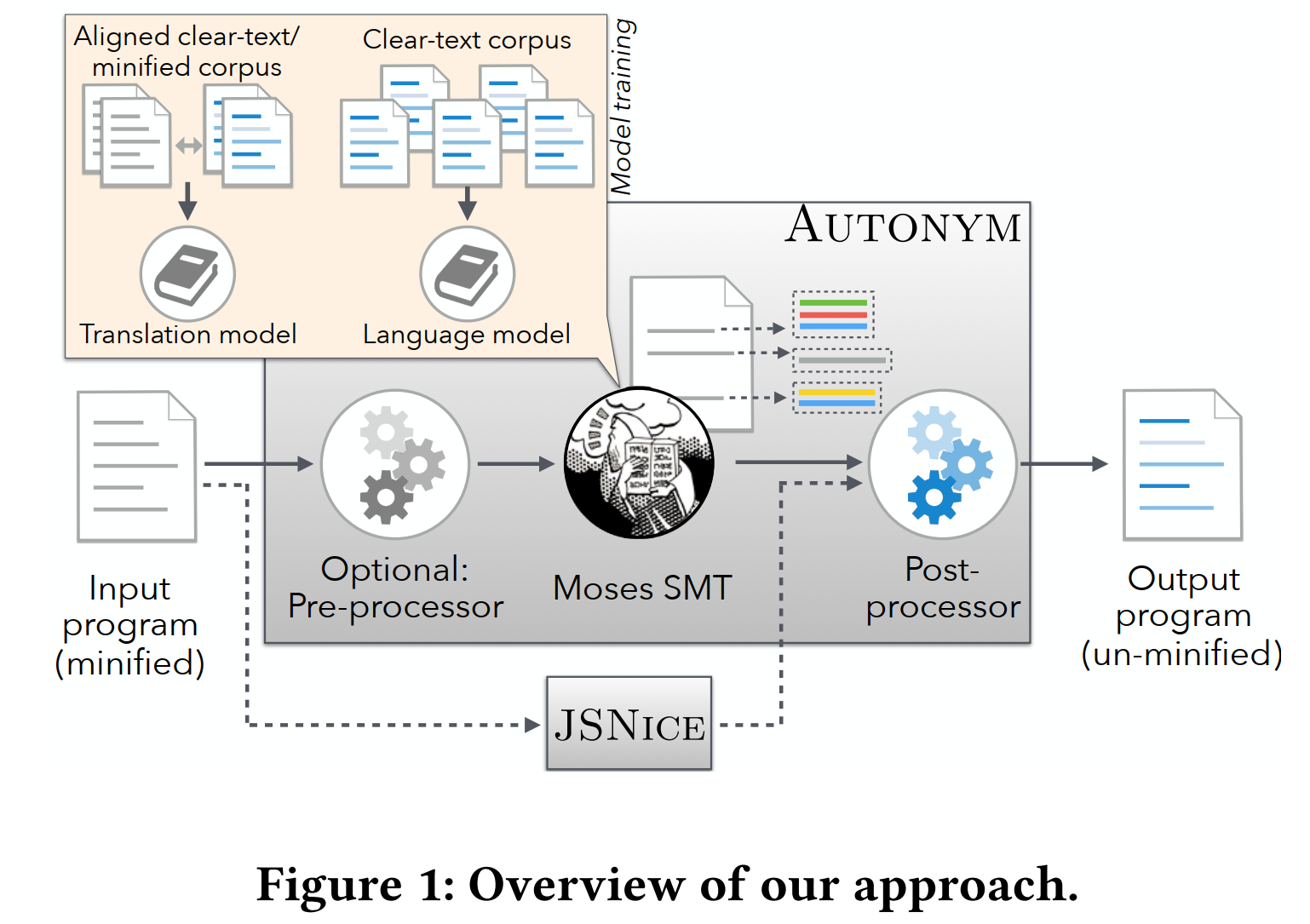
insight:要猜测被混淆的标识符w的明确、自然的名字v,我们所要做的就是根据w出现的上下文k(变量作用域信息)来猜测最有可能的名字。
方法:使用一个JS混淆器(UglifyJS)生成大量pair(源JS-混淆JS)训练数据,在一个现成的SMT系统(MoSeS)训练。
挑战:(1)inconsistency. 默认情况下Moses独立地翻译每一行,没有内在机制确保不同行的相同标识符名称的一致恢复;(2)ambiguity. 存在多个不同作用域中重复使用同一简化名称来命名不同变量,即“重载”问题;(例如:function Vec(x,y)被混淆为function t(t,n))
解决方法:(1)后处理部分,包括两部分;第一,COMPUTECANDIDATENAMES ,接受一个标记化输入文件,并使用 MosE 将每个输入行反混淆,收集所有由 MosE 建议用于给定简化的任何名称的所有可能重命名,并且将JSNice预测出的名称加入候选列表;第二,RANKCANDIDATES,对每个标识符名称的一组候选名称进行排序,计算它们在将要使用的上下文中的“naturaless score”(通过语言模型),并且设计遍历名称的顺序,优先出现频率高,候选名称少的标识符。

(2)前处理部分,结合作用域信息,对简化名称进行哈希重命名;

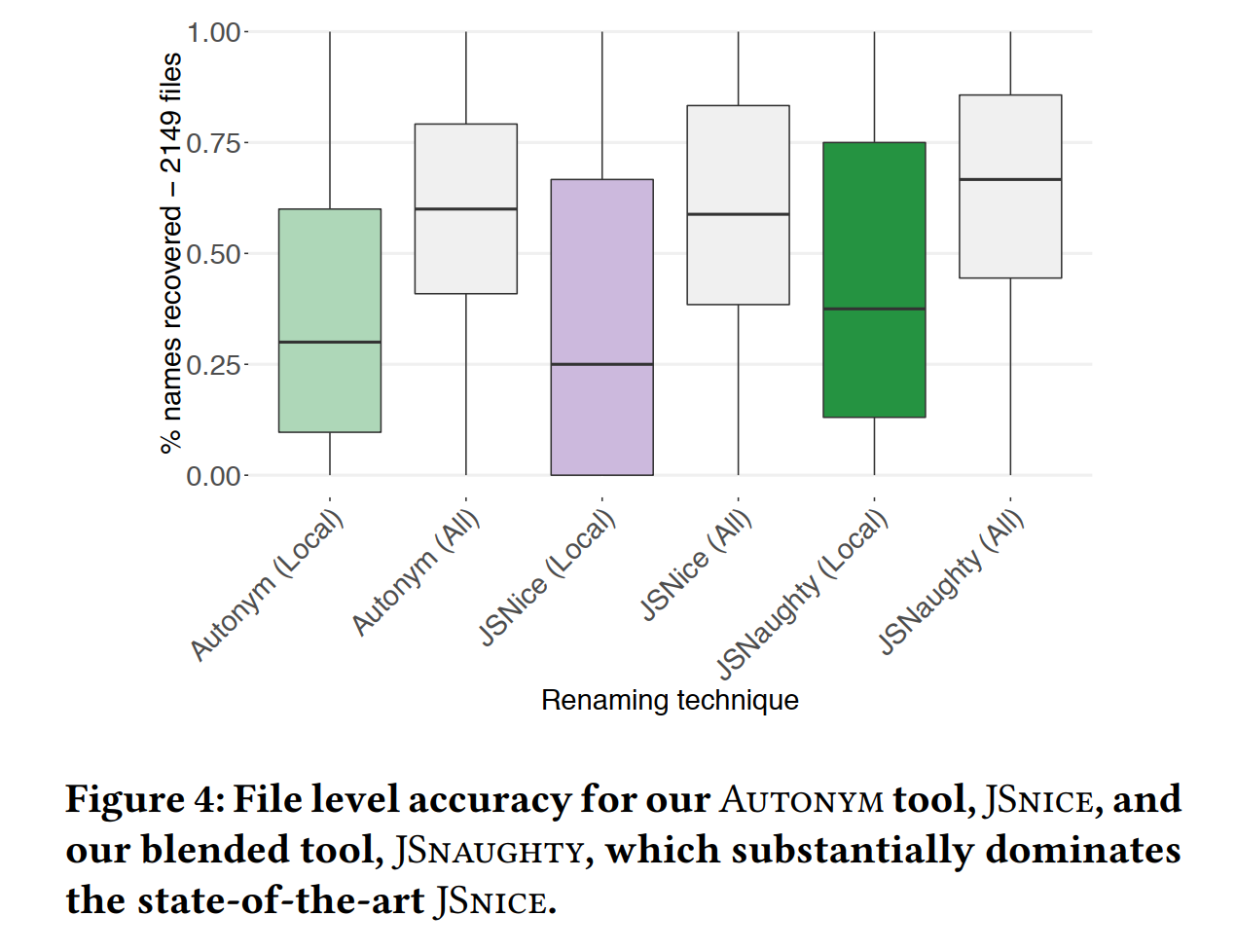
评估:性能指标是每种技术恢复原始标识符名称的百分比;(UGlifyJS主要混淆局部变量,单独分析)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号