20242106 2024-2025-2 《Python 程序设计》实验四报告
20242106 2024-2025-2 《Python 程序设计》实验四报告
课程:《Python 程序设计》
班级: 2421
姓名: 于凯
学号: 20242106
实验教师:王志强
实验日期:2025 年 5 月 14 日
必修/选修: 公选课
一、实验内容
这次实验我选择做一个B站视频标签分析系统,主要是之前搞的要么太难做,要么没什么意思,所以就这样了。这个系统主要是用来分析 B 站用户收藏夹里的视频标签,看看自己平时都喜欢收藏什么类型的视频(就是查成分)。
主要功能包括:
- 自动获取用户所有收藏夹中的视频
- 批量提取视频标签
- 生成分类词云和汇总词云
- 支持导出标签数据为 CSV 格式
- 提供友好的命令行交互界面
二、实验过程及结果
1. 实验思路
在网上查了很多资料,然后瞎搞。
- 数据获取:通过 B 站 API 获取用户收藏夹和视频信息
- 数据存储:使用 JSON 格式存储配置信息(本来想用数据库的,但是觉得这个项目数据量不大,用 JSON 就够了)
- 日志系统:使用 logging 模块记录运行日志,调试舒服一些
- 数据分析:统计标签频率,生成词云
- 可视化:使用 pyecharts 生成交互式词云,挺好用的
2. 项目结构
BilibiliFuck/
├── config/
│ └── config.json # 配置文件,主要存 Cookie
├── results/
│ └── combined.html # 词云报告,可以导出数据
├── test.py # 主程序
└── video_analysis.log # 日志文件
4. 分步实现
(1) 测试 API 访问
写了个简单的测试代码:
def test_api_access():
url = "https://api.bilibili.com/x/v3/fav/folder/created/list-all"
response = requests.get(url, headers=headers, cookies=cookies)
print(f"状态码: {response.status_code}")
print(f"响应内容: {response.json()}")
运行就报错,然后发现是 Cookie 的问题。
(2) 实现数据获取
写了一个 BiliVideoAnalyzer 类,写的时候要注意考虑异常情况,主要包括:
- 获取用户收藏夹列表
- 获取收藏夹中的视频
- 提取视频标签
(3) 数据处理和存储
这部分我本来想用数据库的,但是觉得太麻烦了,就用了 JSON:
-
数据清洗:
- 过滤空标签
- 统计标签频率
- 格式化数据
-
数据存储:
- 使用 JSON 格式存储配置
- 使用 HTML 文件存储词云
- 支持 CSV 格式导出
(4) 可视化实现
考虑方便好用的 pyecharts 库
- 生成分类词云
- 生成汇总词云
- 添加交互式功能
- 支持数据导出(这个功能是后来加的)
5. 代码展示
- 解释直接塞进注释了,单独拎出来写太乱了。
- test.py
"""
B 站视频标签分析系统
===================
这是一个用于分析 B 站用户收藏视频标签的工具。它可以帮助您:
1. 自动获取所有收藏夹中的视频
2. 提取每个视频的标签信息
3. 生成分类词云和汇总词云
4. 支持导出标签数据为 CSV 格式
使用方法:
----------
1. 查看帮助信息:
python BilibiliFuck/test.py -h
2. 分析收藏夹视频:
python BilibiliFuck/test.py -t favorites
注意事项:
----------
1. 使用前请确保已正确配置 config.json 文件,包含有效的 Cookie 信息
2. 程序会自动限制每个收藏夹的获取页数,防止请求过多
3. 分析结果将保存在 BilibiliFuck/results 目录下
4. 可以通过浏览器打开生成的 HTML 文件查看词云
"""
import re
import json
import time
import logging
import argparse
import requests
import pandas as pd
from datetime import datetime
from tqdm import tqdm
from pathlib import Path
from typing import List, Dict, Tuple
from collections import defaultdict, Counter
from pyecharts.charts import WordCloud, Tab
from pyecharts import options as opts
from pyecharts.globals import ThemeType
# 配置日志系统
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[logging.FileHandler('BilibiliFuck/video_analysis.log', encoding='utf-8'), logging.StreamHandler()])
class BiliVideoAnalyzer:
"""
B 站视频分析器
主要功能:
1. 获取用户收藏夹列表
2. 从收藏夹中提取视频信息
3. 批量获取视频标签
4. 生成词云可视化
属性:
headers (dict): 请求头信息
cookies (dict): 用户 Cookie 信息
api_endpoints (dict): B 站 API 接口地址
request_interval (float): 请求间隔时间(秒)
max_retries (int): 请求失败重试次数
dede_user_id (str): 用户 ID,用于 API 认证
"""
def __init__(self, config: dict):
"""
初始化分析器
Args:
config (dict): 配置信息,必须包含 cookies 字段
"""
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3', 'Referer': 'https://www.bilibili.com/'}
self.cookies = config.get('cookies', {})
self.api_endpoints = {
'favorite_folders_list': 'https://api.bilibili.com/x/v3/fav/folder/created/list-all', # 获取收藏夹列表
'videos_in_favorite_folder': 'https://api.bilibili.com/x/v3/fav/resource/list' # 获取收藏夹中的视频
}
self.request_interval = 0.5 # 请求间隔,防止被 B 站限制
self.max_retries = 3 # 请求失败时的重试次数
self.dede_user_id = self.cookies.get('DedeUserID', None)
if not self.dede_user_id: logging.warning("警告: 未在提供的 Cookie 中找到 DedeUserID。需要 DedeUserID 才能获取收藏夹视频。")
def _safe_request(self, url: str, params: dict = None) -> dict:
"""
发送安全的 HTTP 请求,包含重试机制
Args:
url (str): 请求的 URL
params (dict, optional): URL 参数
Returns:
dict: API 返回的 JSON 数据
如果请求失败会重试最多 3 次,每次间隔 2 秒
"""
for _ in range(self.max_retries):
try:
response = requests.get(url, headers=self.headers, cookies=self.cookies, params=params, timeout=10)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
logging.warning(f"请求失败: {str(e)},正在重试...")
time.sleep(2)
return {'code': -1, 'message': '请求失败'}
def _get_user_favorite_folders(self) -> List[Dict[str, any]]:
"""
获取用户所有非空收藏夹列表
Returns:
List[Dict]: 收藏夹信息列表,每个收藏夹包含:
- media_id: 收藏夹 ID
- title: 收藏夹名称
- media_count: 收藏夹中的视频数量
只返回非空的收藏夹,空收藏夹会被过滤掉
"""
if not self.dede_user_id:
logging.error("获取收藏夹列表失败: DedeUserID 未配置或无效。")
return []
folders = []
params = {'up_mid': self.dede_user_id, 'jsonp': 'jsonp'}
logging.info(f"正在请求收藏夹列表 API: {self.api_endpoints['favorite_folders_list']} with params up_mid={self.dede_user_id}")
result = self._safe_request(self.api_endpoints['favorite_folders_list'], params)
if result.get('code') != 0:
logging.error(f"获取收藏夹列表 API 失败: code={result.get('code')}, message=\"{result.get('message')}\"")
return []
data = result.get('data')
if not data or not isinstance(data.get('list'), list):
logging.info("用户没有创建任何收藏夹,或 API 返回格式不符合预期。")
return []
for folder_info in data['list']:
if isinstance(folder_info, dict) and folder_info.get('media_count', 0) > 0:
folders.append({
'media_id': folder_info.get('id'),
'title': folder_info.get('title', '未知收藏夹'),
'media_count': folder_info.get('media_count')
})
if not folders: logging.info("用户所有收藏夹均为空或未能成功解析。")
else: logging.info(f"成功获取到 {len(folders)} 个非空收藏夹。")
return folders
def _get_videos_from_specific_favorite_folder(self, media_id: int, folder_title: str, total_videos: int, max_pages_limit: int = 10) -> List[str]:
"""
从指定收藏夹获取视频链接列表
Args:
media_id (int): 收藏夹 ID
folder_title (str): 收藏夹名称
total_videos (int): 收藏夹中的视频总数
max_pages_limit (int, optional): 最大获取页数,默认 10 页
Returns:
List[str]: 视频链接列表
每页最多获取 20 个视频,超过限制的页数会被忽略
"""
video_urls = []
page = 1
videos_per_page = 20 # B 站 API 每页固定返回 20 个视频
# 计算实际需要获取的页数
total_pages = min((total_videos + videos_per_page - 1) // videos_per_page, max_pages_limit)
max_videos = total_pages * videos_per_page
logging.info(f"收藏夹 {folder_title} 共有 {total_videos} 个视频,将获取前 {max_videos} 个视频(最多 {max_pages_limit} 页)")
with tqdm(total=max_videos, desc=f"获取收藏夹 {folder_title} 视频", unit='video', leave=False) as pbar:
while page <= total_pages:
time.sleep(self.request_interval)
params = {'media_id': media_id, 'pn': page, 'ps': videos_per_page, 'order': 'mtime', 'type': 0, 'jsonp': 'jsonp'}
try:
result = self._safe_request(self.api_endpoints['videos_in_favorite_folder'], params)
if result.get('code') != 0:
logging.error(f"获取收藏夹 {folder_title} (ID: {media_id})第{page}页视频失败: {result.get('message')}")
break
items = result.get('data', {}).get('medias', [])
if not items:
logging.info(f"收藏夹 {folder_title} (ID: {media_id})第{page}页没有更多视频了。")
break
for item in items:
bvid = item.get('bvid')
if bvid: video_urls.append(f"https://www.bilibili.com/video/{bvid}")
pbar.update(1)
if len(items) < videos_per_page: break
page += 1
except Exception as e:
logging.error(f"获取收藏夹 {folder_title} 第{page}页时发生错误: {str(e)}")
break
logging.info(f"从收藏夹 {folder_title} (ID:{media_id})获取到 {len(video_urls)} 个视频链接 (共 {total_videos} 个视频,获取了 {page-1} 页)。")
return video_urls
def get_user_videos(self, types: List[str]) -> Dict[str, List[str]]:
"""
批量获取用户收藏视频
Args:
types (List[str]): 要获取的视频类型列表,目前只支持 'favorites'
Returns:
Dict[str, List[str]]: 按收藏夹分类的视频链接字典
key: 收藏夹名称
value: 该收藏夹中的视频链接列表
1. 如果收藏夹数量超过 5 个,每个收藏夹只获取前 3 页视频
2. 否则每个收藏夹最多获取 5 页视频
"""
results = {}
max_pages_per_source = 5 # 默认每个收藏夹最多获取 5 页
favorite_folders = []
if 'favorites' in types:
if not self.dede_user_id: logging.error("无法获取收藏夹视频,因为DedeUserID未配置。请检查 config.json。")
else:
logging.info("开始获取用户收藏夹列表...")
favorite_folders = self._get_user_favorite_folders()
if favorite_folders:
if len(favorite_folders) > 5:
max_pages_per_source = 3
logging.info(f"检测到收藏夹数量较多({len(favorite_folders)}个),每个收藏夹将只获取前3页视频")
else:
logging.info("没有找到非空收藏夹或获取收藏夹列表失败。")
for video_type in types:
if video_type == 'favorites':
if not favorite_folders: continue
for folder in favorite_folders:
folder_id = folder.get('media_id')
folder_title = folder.get('title', '未知收藏夹')
folder_video_count = folder.get('media_count', 0)
if not folder_id:
logging.warning(f"收藏夹 {folder_title} 缺少ID,跳过。")
continue
result_key = f"收藏夹-{folder_title}"
logging.info(f"准备从收藏夹 {folder_title} (ID: {folder_id}, 共{folder_video_count}个视频)获取视频...")
urls = self._get_videos_from_specific_favorite_folder(media_id=folder_id, folder_title=folder_title, total_videos=folder_video_count, max_pages_limit=max_pages_per_source )
if urls: results[result_key] = urls
else: logging.info(f"收藏夹 {folder_title} 中没有获取到视频链接或获取失败。")
return results
def batch_get_tags(self, video_urls: List[str]) -> List[str]:
"""
批量获取视频标签
Args:
video_urls (List[str]): 视频链接列表
Returns:
List[str]: 所有视频的标签列表
每个视频请求之间有 0.5 秒的间隔,防止被 B 站限制
"""
all_tags = []
with tqdm(total=len(video_urls), desc="解析视频标签", unit="video") as pbar:
for url in video_urls:
try:
tags = self._get_video_tags(url)
all_tags.extend(tags)
except Exception as e:
logging.error(f"处理视频 {url} 失败: {str(e)}")
finally:
time.sleep(self.request_interval)
pbar.update(1)
return all_tags
def _get_video_tags(self, url: str) -> List[str]:
"""
获取单个视频的标签
Args:
url (str): 视频链接
Returns:
List[str]: 视频标签列表
通过解析视频页面的 HTML 来获取标签信息
"""
try:
response = requests.get(url, headers=self.headers, timeout=10)
response.raise_for_status()
html = response.text
match = re.search(r'window\.__INITIAL_STATE__=({.*?});', html, re.DOTALL)
if not match: return []
initial_state = json.loads(match.group(1))
return [tag['tag_name'] for tag in initial_state.get('tags', [])]
except Exception as e:
logging.error(f"解析标签失败: {str(e)}")
return []
def generate_clouds(self, tag_data: Dict[str, List[str]], output_dir: str = "results"):
"""
生成词云可视化
Args:
tag_data (Dict[str, List[str]]): 按来源分类的标签数据
output_dir (str, optional): 输出目录,默认为 "results"
1. 会生成每个来源的分类词云
2. 同时生成所有标签的汇总词云
3. 支持导出标签数据为 CSV 格式
"""
Path(output_dir).mkdir(exist_ok=True)
tab = Tab()
# 准备导出数据
export_data = []
for source, tags in tag_data.items():
tag_counter = Counter(tags)
for tag, count in tag_counter.items(): export_data.append({'来源': source, '标签': tag, '出现次数': count})
# 生成汇总词云
all_tags = [tag for tags in tag_data.values() for tag in tags]
self._create_wordcloud(all_tags, "所有视频标签汇总", tab)
# 生成分类词云
for name, tags in tag_data.items(): self._create_wordcloud(tags, f"{name}标签", tab)
# 添加导出按钮和数据的JavaScript代码
export_js = """
<script>
function exportToExcel() {
const data = %s;
let csvContent = "来源,标签,出现次数\\n";
data.forEach(item => {
csvContent += `${item.来源},${item.标签},${item.出现次数}\\n`;
});
const blob = new Blob([csvContent], { type: 'text/csv;charset=utf-8;' });
const link = document.createElement("a");
const url = URL.createObjectURL(blob);
link.setAttribute("href", url);
link.setAttribute("download", "标签统计_" + new Date().toISOString().slice(0,19).replace(/[:]/g, '') + ".csv");
link.style.visibility = 'hidden';
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
}
</script>
<div style="text-align: center; margin: 20px;">
<button onclick="exportToExcel()" style="padding: 10px 20px; font-size: 16px; cursor: pointer; background-color: #4CAF50; color: white; border: none; border-radius: 4px;">
导出标签数据到 CSV
</button>
</div>
""" % json.dumps(export_data, ensure_ascii=False)
# 保存结果
output_path = f"{output_dir}/combined.html"
tab.render(output_path)
# 在HTML文件末尾添加导出按钮
with open(output_path, 'r', encoding='utf-8') as f: content = f.read()
with open(output_path, 'w', encoding='utf-8') as f: f.write(content.replace('</body>', export_js + '</body>'))
logging.info(f"结果已保存到 {output_path}")
return output_path
def _create_wordcloud(self, tags: List[str], title: str, tab) -> None:
"""
生成单个词云并添加到标签页
Args:
tags (List[str]): 标签列表
title (str): 词云标题
tab: pyecharts 的 Tab 对象
Note:
词云最多显示前 100 个高频标签
"""
if not tags: return
counter = Counter(tags)
data = sorted(counter.items(), key=lambda x: x[1], reverse=True)[:100]
cloud = (
WordCloud(init_opts=opts.InitOpts(theme=ThemeType.ROMA))
.add(series_name="", data_pair=data, word_size_range=[20, 100], shape="diamond", textstyle_opts=opts.TextStyleOpts(font_family="Microsoft YaHei"),)
.set_global_opts(
title_opts=opts.TitleOpts(title=title),
tooltip_opts=opts.TooltipOpts(formatter="{b}: {c}次"),
visualmap_opts=opts.VisualMapOpts(min_=1, max_=max([count for _, count in data]), orient="horizontal", pos_left="center")
)
)
tab.add(cloud, title)
class ConfigManager:
"""
配置管理类
用于加载和验证配置文件
"""
@staticmethod
def load_config(file_path: str = "BilibiliFuck/config.json") -> dict:
"""
加载配置文件
Args:
file_path (str, optional): 配置文件路径,默认为 "BilibiliFuck/config.json"
Returns:
dict: 配置信息
Raises:
FileNotFoundError: 配置文件不存在
ValueError: 配置文件格式错误或缺少必要字段
"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
config = json.load(f)
if 'cookies' not in config: raise ValueError("配置文件中缺少 cookies 字段")
return config
except FileNotFoundError:
logging.error("找不到配置文件 BilibiliFuck/config.json")
raise
except json.JSONDecodeError:
logging.error("配置文件格式错误")
raise
def parse_arguments():
"""
解析命令行参数
Returns:
argparse.Namespace: 解析后的参数对象
只支持 favorites 选项
"""
parser = argparse.ArgumentParser(description="B 站视频标签分析系统")
parser.add_argument('-t', '--types', nargs='+', choices=['favorites'], help='要分析的类型(favorites)')
parser.add_argument('-o', '--output', default="BilibiliFuck/results", help='输出目录')
return parser.parse_args()
def main():
"""
主函数
处理命令行参数,初始化分析器,执行分析流程
1. 必须指定要分析的类型
2. 分析结果会保存在指定目录下
3. 会自动打开浏览器显示结果
"""
args = parse_arguments()
if args.types is None:
logging.error("请使用 -t 或 --types 参数指定要分析的类型,例如:-t favorites")
return
try:
# 确保输出目录存在
output_dir = Path(args.output)
output_dir.mkdir(parents=True, exist_ok=True)
# 初始化配置
logging.info("开始加载配置文件...")
config = ConfigManager.load_config()
analyzer = BiliVideoAnalyzer(config)
tag_data = {} # 用来存储各个来源的标签数据
# 处理用户收藏视频
user_interaction_types = args.types
if user_interaction_types:
logging.info(f"准备开始处理您选择的用户收藏视频类型: {', '.join(user_interaction_types)}")
video_data = analyzer.get_user_videos(user_interaction_types)
for vtype, urls in video_data.items():
if urls: # 加个判断,确保真的有 URL 列表
logging.info(f"正在为 {vtype} 类型的视频收集标签...")
tag_data[vtype] = analyzer.batch_get_tags(urls)
logging.info(f"{vtype} 类型视频的标签已收集完毕。")
else: logging.warning(f"看起来 {vtype} 类型下没有找到任何视频链接,已跳过。")
else: logging.info("没有指定需要分析的用户收藏视频类型。")
# 生成可视化结果
if tag_data:
logging.info("所有标签数据已准备就绪,开始生成词云报告...")
output_path = analyzer.generate_clouds(tag_data, str(output_dir))
logging.info(f"词云报告已生成完毕!路径是: {output_path}")
try:
import webbrowser
logging.info("正在尝试用默认浏览器打开报告...")
webbrowser.open(output_path)
except Exception as browser_e: logging.warning(f"自动打开浏览器失败: {browser_e}。请您手动打开上面的文件路径查看结果。")
else: logging.warning("非常抱歉,本次运行没有收集到任何有效的标签数据,所以无法生成词云报告。")
except FileNotFoundError: logging.error("关键错误:找不到配置文件 BilibiliFuck/config.json。请确保该文件与脚本在同一目录下,并且已正确配置 cookies。")
except json.JSONDecodeError: logging.error("关键错误:配置文件 BilibiliFuck/config.json 格式不正确,导致无法解析。请检查其内容是否为合法的 JSON 格式。")
except requests.exceptions.ConnectionError: logging.error("网络错误:似乎无法连接到B站的服务器。请检查您的网络连接是否正常。")
except requests.exceptions.Timeout: logging.error("网络超时:连接 B 站服务器或获取数据超时。可能是当前网络不太稳定,或者 B 站服务器比较繁忙。")
except requests.exceptions.RequestException as req_err: logging.error(f"网络请求过程中发生了意料之外的问题: {str(req_err)}")
except KeyError as ke: logging.error(f"处理数据时遇到了键错误(这可能意味着 B 站的 API 响应格式发生了变化,或者代码中有 bug):字段 {str(ke)} 未找到。")
except Exception as e:
logging.error(f"程序运行期间发生了一个未预料的错误: {str(e)}")
logging.info("如果问题依然存在,您可以尝试查看 BilibiliFuck/video_analysis.log 文件获取更详细的错误日志。")
if __name__ == "__main__": main()
- config.json
{
"cookies": {
// 对着 B 站登录后,在浏览器的 Cookie 中复制,我不想被盗号(
"SESSDATA": "",
"bili_jct": "",
"DedeUserID": ""
}
}
6. 实验结果展示
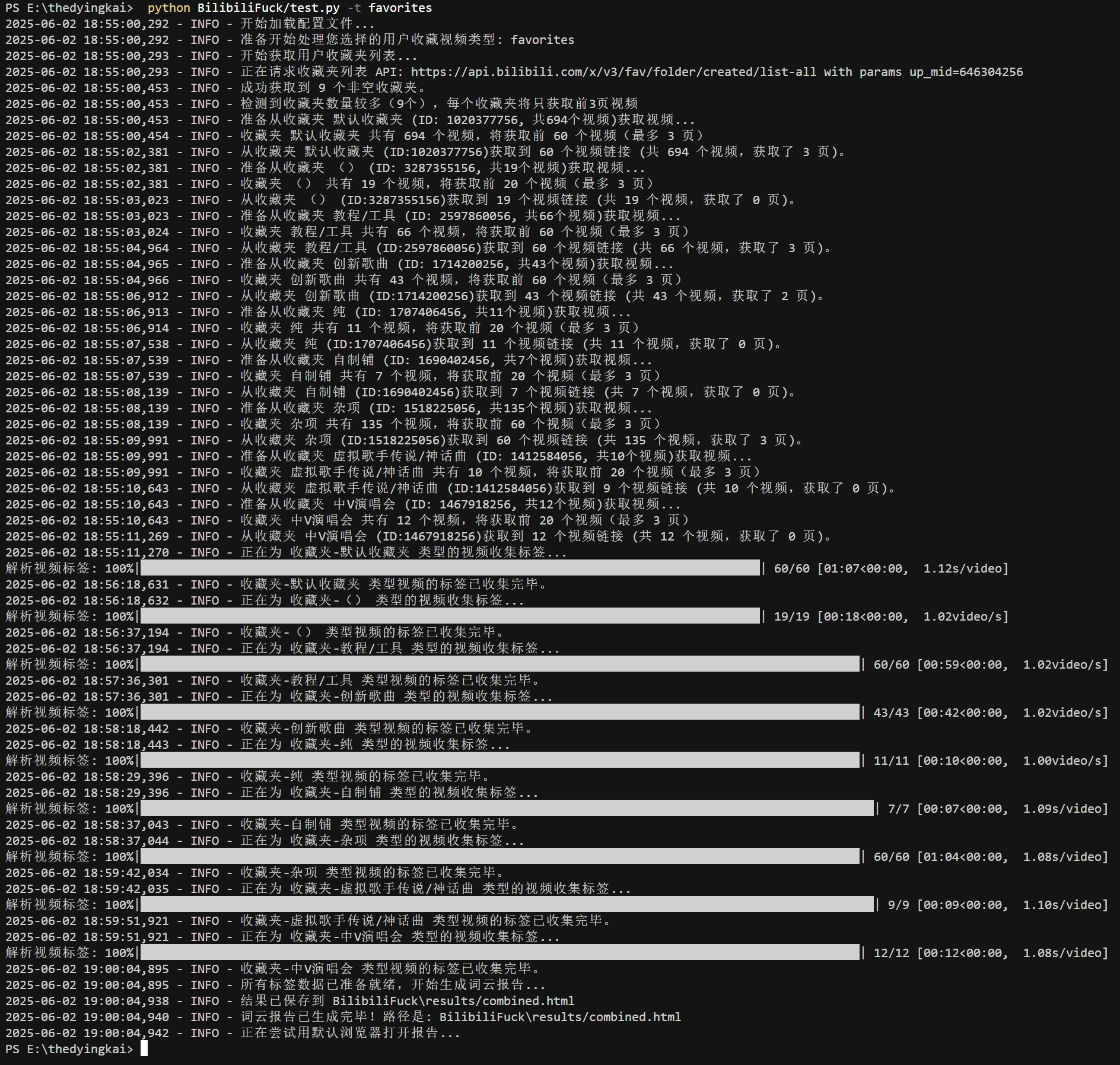



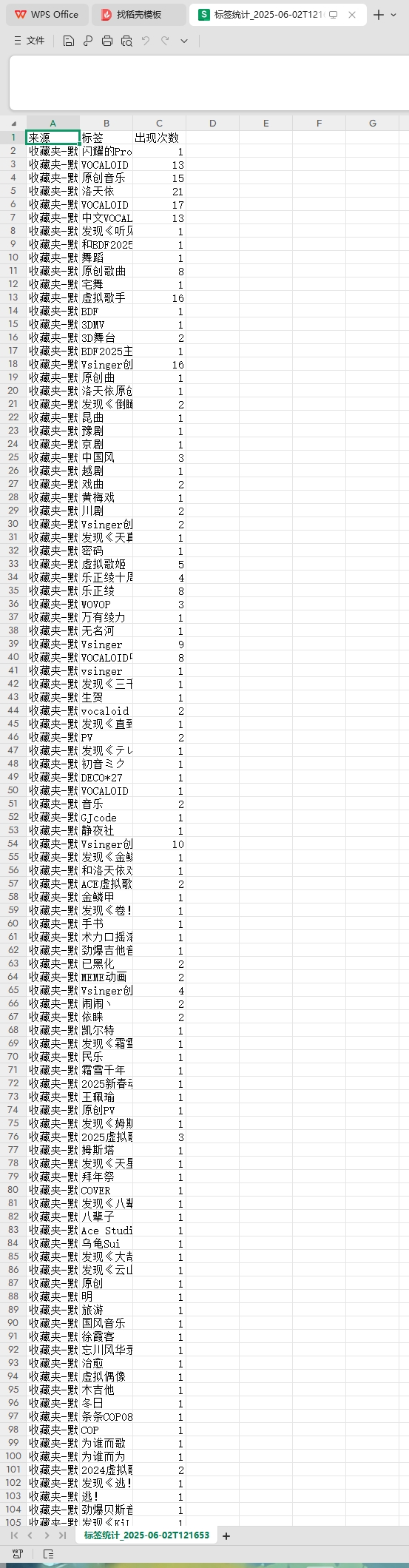
三、实验过程中遇到的问题和解决过程
- 问题 1:B 站 API 访问限制
- 问题 1 解决方案:使用 Cookie 进行身份验证(很麻烦,因为要经常更新)
- 问题 2:词云生成效果不理想
- 问题 2 解决方案: 调整词云参数,添加交互式功能
四、其他(感悟、思考等)
- 中间一步一步的修改过程我没写,因为实在是太乱了,每一次修改都是在做尝试,因为真没搞过这么大的单文件项目,再加上 pyhthon 写的太少,没什么清晰的分步。
- 本来是要把最近观看、收藏和点赞一起爬下来的,但是很糟糕,没找到最近点赞和观看的接口,遂放弃。
- 本来要做的 excel 导入视频链接生成报告其实做了,想了一下直接删了,很鸡肋的功能,谁会闲着没事把几百上千的视频链接贴进 excel 里,没有实际价值。
五、参考资料
- python 日志 logging 模块(详细解析)
- pandas 详细教程(涵盖全部,看这一篇就够了)
- Python 词云 wordcloud 十五分钟入门与进阶
- Pyecharts 功能详解与实战示例
六、课程总结
- 学习 Python 课程后,比如面向对象与网络编程,我的开发思维和项目实践能力显著提升。其简洁语法与强大库(如requests、socket)使复杂功能高效实现,对我在 JavaWeb 开发学习也有一定的帮助,两份知识互补让我理解更深。此外,Python 在 AI、网络安全等领域也能用得到。感谢王志强老师的悉心指导,您的专业与热忱让我深感敬佩,是我技术成长道路上的明灯。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号