Spark框架与运行流程
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
Spark 是专为大规模数据处理而设计的快速通用的计算引擎。拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
旧的MapReduce过程是通过JobTracker和TaskTracker来完成的。JobTracker负责资源管理,跟踪资源消耗和可用性,作业生命周期管理;TaskTracker: 加载或关闭任务,定时报告任务状态。JobTracker是核心所在,存在单点问题和资源利用率问题。Yarn将JobTracker的职责进行拆分,将资源管理和任务调度监控拆分成独立的进程:一个全局的资源管理和一个单点的作业管理。ResourceManager和NodeManager提供了计算资源的分配和管理,而ApplicationMaster则完成应用程序的运行。Yarn作为资源调度器起到一个中央管理的作用,让多种框架工具都可以在同一个集群上运转,大家互相配合协调有序工作。
Hadoop的计算框架MapReduce存在着局限性和不足,比如抽象层次低,代码不好写;表达力欠缺、中间结果存储在HDFS中,速度不够快;延时高,只适合批处理不适合交互处理和实时处理。Spark的诞生就是为了解决这些问题,它的中间输出结果可以保存在内存中(内存放不下会写入磁盘),避免了对HDFS的大量的读写,减少了I/O的开销。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark大数据计算平台包含许多子模块,构成了整个Spark的生态系统,其中Spark为核心。
伯克利将整个Spark的生态系统称为伯克利数据分析栈(BDAS)
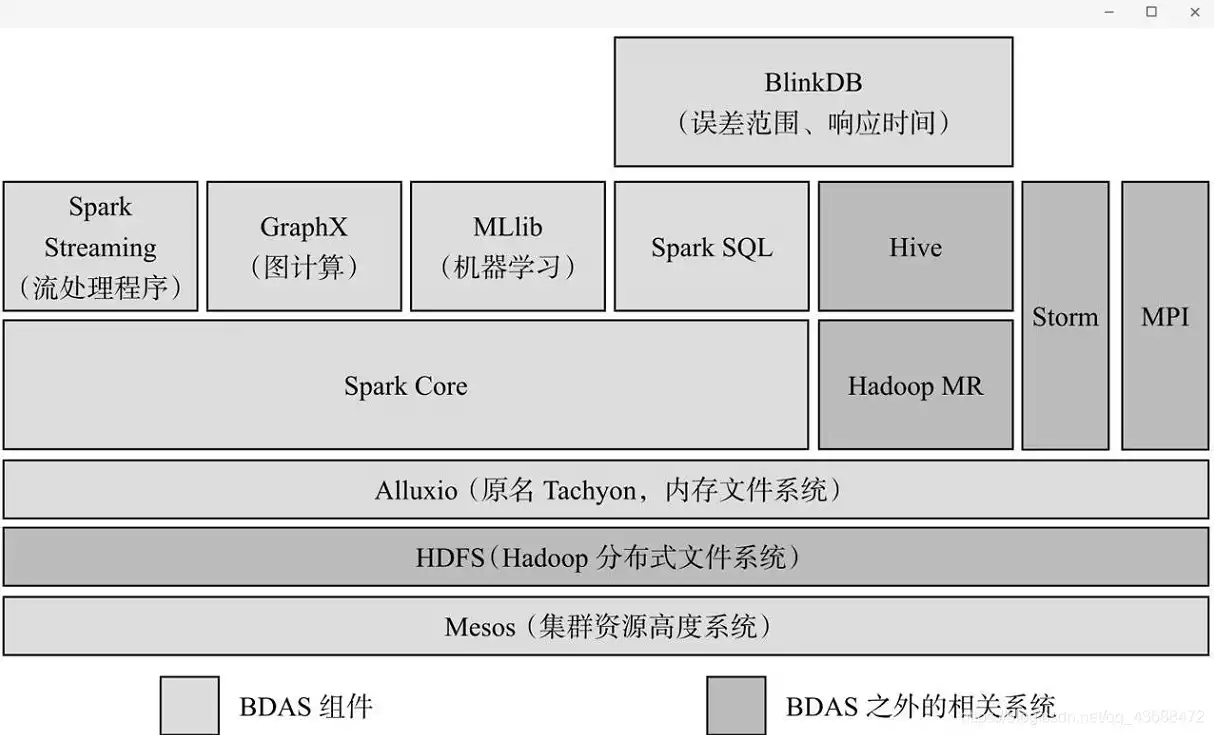
1. Spark Core
Spark Core是整个BDAS的核心组件,是一种大数据分布式处理框架,不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供如filter、join、groupByKey等更丰富的算子。
Spark将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala函数式语言书写而成,并且深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口。
2. Mesos
Mesos是Apache下的开源分布式资源管理框架,被称为分布式系统的内核,提供了类似YARN的功能,实现了高效的资源任务调度。
3. Spark Streaming
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。其吞吐量能够超越现有主流流处理框架Storm,并提供丰富的API用于流数据计算。
4. MLlib
MLlib是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。MLlib目前支持4种常见的机器学习问题:二元分类、回归、聚类以及协同过滤,还包括一个底层的梯度下降优化基础算法。
5. GraphX
GraphX是Spark中用于图和图并行计算的API,可以认为是GraphLab和Pregel在Spark (Scala)上的重写及优化,与其他分布式图计算框架相比,GraphX最大的贡献是,在Spark上提供一栈式数据解决方案,可以方便、高效地完成图计算的一整套流水作业。
6. Spark SQL
Shark是构建在Spark和Hive基础之上的数据仓库。它提供了能够查询Hive中所存储数据的一套SQL接口,兼容现有的Hive QL语法。熟悉Hive QL或者SQL的用户可以基于Shark进行快速的Ad-Hoc、Reporting等类型的SQL查询。由于其底层计算采用了Spark,性能比Mapreduce的Hive普遍快2倍以上,当数据全部存储在内存时,要快10倍以上。2014年7月1日,Spark社区推出了Spark SQL,重新实现了SQL解析等原来Hive完成的工作,Spark SQL在功能上全覆盖了原有的Shark,且具备更优秀的性能。
7. Alluxio
Alluxio(原名Tachyon)是一个分布式内存文件系统,可以理解为内存中的HDFS。为了提供更高的性能,将数据存储剥离Java Heap。用户可以基于Alluxio实现RDD或者文件的跨应用共享,并提供高容错机制,保证数据的
可靠性。
8. BlinkDB
BlinkDB是一个用于在海量数据上进行交互式SQL的近似查询引擎。它允许用户在查询准确性和查询响应时间之间做出权衡,执行相似查询。
3. 用图文描述你所理解的Spark运行架构,运行流程。
运行架构
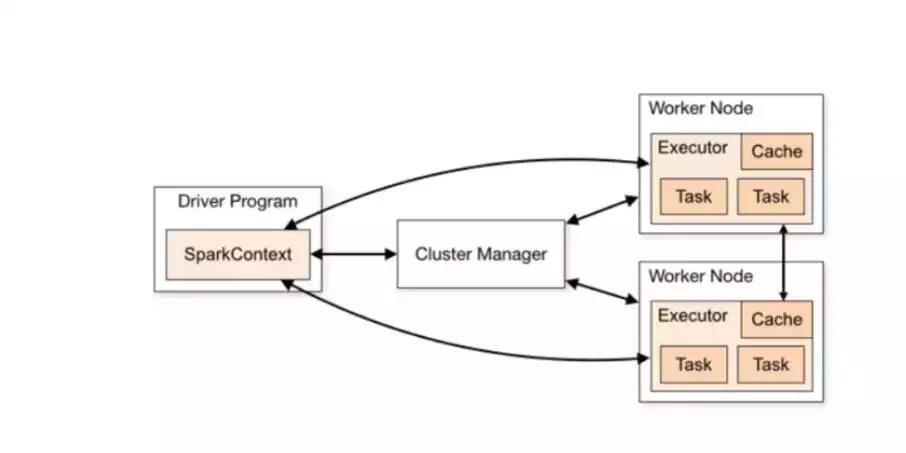
Spark应用程序有多种运行模式。SparkContext和Executor这两部分的核心代码实现在各种运行模式中都是公用的,在这两部分之上,根据运行部署模式(例如:Local[N]、Yarn cluster等)的不同,有不同的调度模块以及对应的适配代码。
运行流程
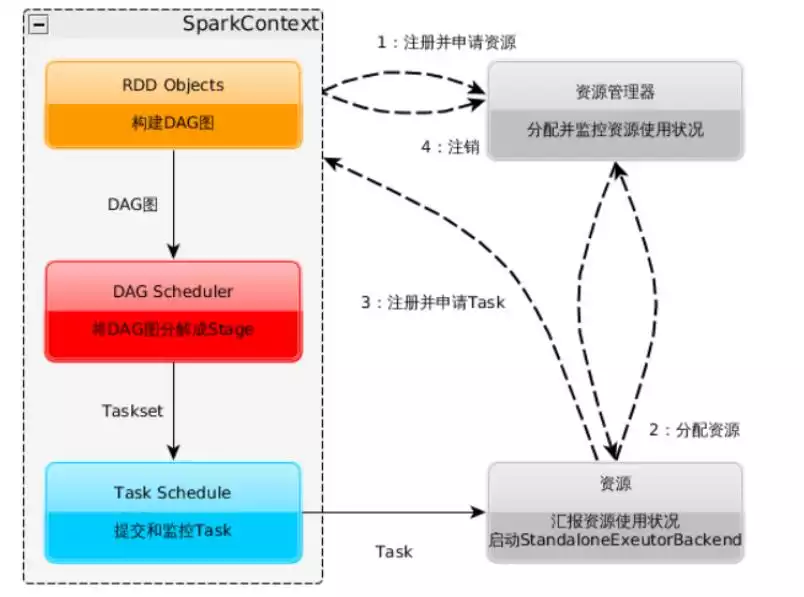
1. 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
2. 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
3. SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4. Task在Executor上运行,运行完毕释放所有资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号