
一、什么是回表查询?
这先要从InnoDB的索引实现说起,InnoDB有两大类索引:
- 聚集索引(clustered index)
- 普通索引(secondary index)
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:
t(id PK, name KEY, sex, flag);
id是聚集索引,name是普通索引。
表中有四条记录:
1, shenjian, m, A 3, zhangsan, m, A 5, lisi, m, A 9, wangwu, f, B
该聚集索引和普通索引如图:
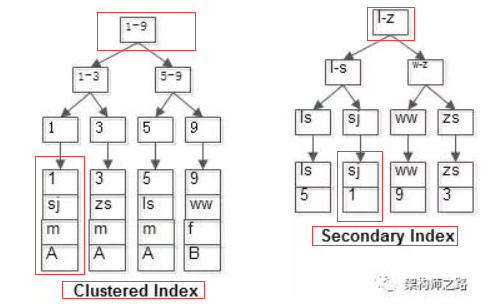
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
如图可知主键索引从根节点开始利用页目录通过二分法查找某个索引页,由于索引是有序的,所以在数据页中同样利用二分法查询指定记录。
普通索引和主键索引一样是棵B+树,不过普通索引的记录和页按照某个非主键列的值排序,叶子节点保存的不是完整数据,而是某个非主键列和主键,普通索引的非叶结点保存的是非主键列和页号。
(重点)一个 SQL 只能利用到复合索引中的其中一列进行范围查询,因为B+树的每个叶子节点有一个指针指向下一个节点,把某一索引列的所有的叶子节点串在了一起,只能根据单列的叶子节点进行范围查询,这就是复合索引中只能有其中一列使用索引进行范围查询的原理。
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
(重点)通常情况下,需要先遍历普通索引的B+树获得聚集索引主键id,然后遍历聚集索引的B+树获得行记录的对应的值。
B+树的每个叶子节点有一个指针指向下一个节点,把所有的叶子节点串在了一起,这就是范围查询使用索引的的原理。
select * from t where name='lisi';
如下图所示流程:
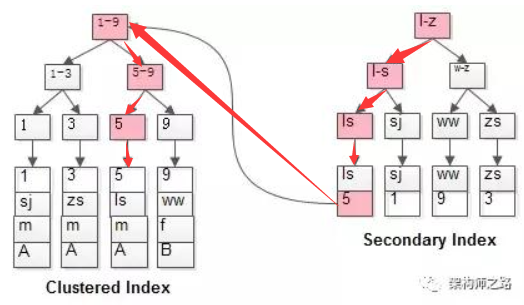
如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
(重点)这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
二、什么是索引覆盖(Covering index)?
explain查询计划优化章节,即explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
三、如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
仍是《迅猛定位低效SQL》中的例子:
create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engine=innodb;
第一个SQL语句:
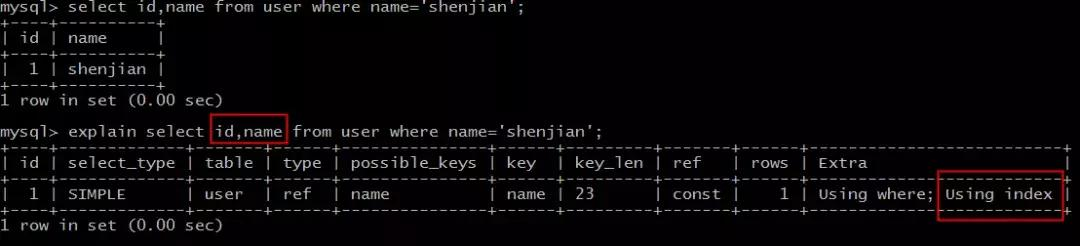
select id,name from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
Extra:Using index。
第二个SQL语句:

select id,name,sex from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫描聚集索引获取sex字段,效率会降低。
Extra:Using index condition。
如果把(name)单列索引升级为联合索引(name, sex)就不同了。
create table user ( id int primary key, name varchar(20), sex varchar(5), index(name, sex) )engine=innodb;

可以看到:
select id,name ... where name='shenjian';
select id,name,sex ... where name='shenjian';
都能够命中索引覆盖,无需回表。
画外音,Extra:Using index。
四、哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
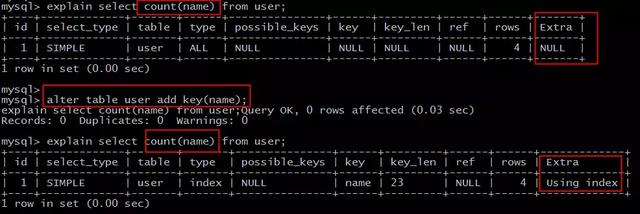
原表为:
user(PK id, name, sex);
直接:
select count(name) from user;
不能利用索引覆盖。
添加索引:
alter table user add key(name);
就能够利用索引覆盖提效。
场景2:列查询回表优化
select id,name,sex ... where name='shenjian';
这个例子不再赘述,将单列索引(name)升级为联合索引(name, sex),即可避免回表。
场景3:分页查询
select id,name,sex ... order by name limit 500,100;
将单列索引(name)升级为联合索引(name, sex),也可以避免回表。

