爬虫的练习--1
windows环境
安装 pip install virtualenv
安装指定版本的python(适用于多个版本的python)
C:\Users\Administrator>virtualenv -p C:\Users\Administrator\AppData\Local\Progra
ms\Python\Python35-32\python.exe Pachong
C:\Users\Administrator\Pachong\Scripts>pip install virtualenvwrapper-win (集中管理虚拟机,可以用 workon 管理) ##注意是 在 sctripts里面运行此命令 linux 不需要带win
deactivate 此命令用于退出虚拟环境
新建 Ten 文章目录 mkvirtualenv (--python=版本路径\python.exe) Ten
删除虚拟环境
rmvirtualenv venv
安装scrapy 需要依赖一个文件 网址在 https://www.lfd.uci.edu/~gohlke/pythonlibs/
3.5 的Python是 Twisted-17.9.0-cp35-cp35m-win_amd32.whl (注意 python版本32就下 32)
mkvirtualenv xxx虚拟名称
查看虚拟环境 workon
进入指定的虚拟环境 workon XXX
新建工程 scrapy startproject Ten ##(项目名称 Ten)
注意:
进入工程后创建项目 ##一定要 cd Ten
scrapy genspider jobbole(项目名称) blog.jobbole.com(网站名称)
scrapy crawl jobbole ( 会依赖包 pip install pypiwin32)
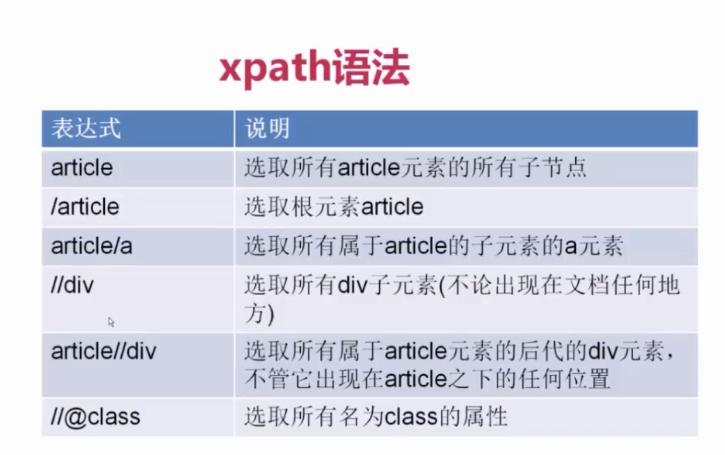
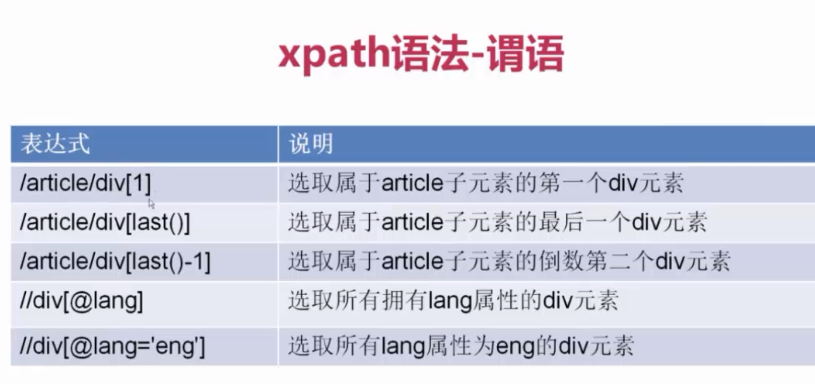
xpath 语法

\Ten>scrapy shell http://web.jobbole.com/94286/ ##在虚拟Python运行 命令 后面加你所需要测试的网页
在 cmd 虚拟机命令里
>>> title = response.xpath('//div[@class="entry-header"]/h1/text()')
>>> title
[<Selector xpath='//div[@class="entry-header"]/h1/text()' data='用 JavaScript
编
写 MPEG1 解码器'>]
>>>
>>> title.extract()
['用 JavaScript 编写 MPEG1 解码器']
>>> ###提取宿主
当class内容中有多个 值的时候 contains
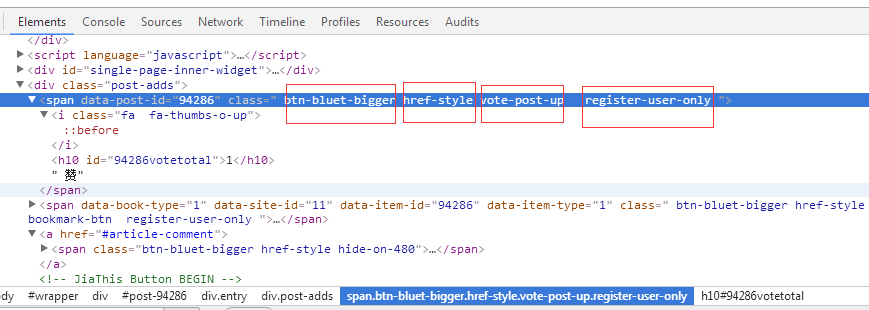
运用 xpath 的内置方法 例 >>> response.xpath('//span[contains(@class,"vote-post-up")]') ###class后面是 ,
>>> response.xpath('//span[contains(@class,"vote-post-up")]/h10/text()').extract()[0] ##点赞数思路
extract_first() ## extract()用此方法可能不存在,, 如用前者 不存在会返回NONE 也可以自定义不存在返回的值
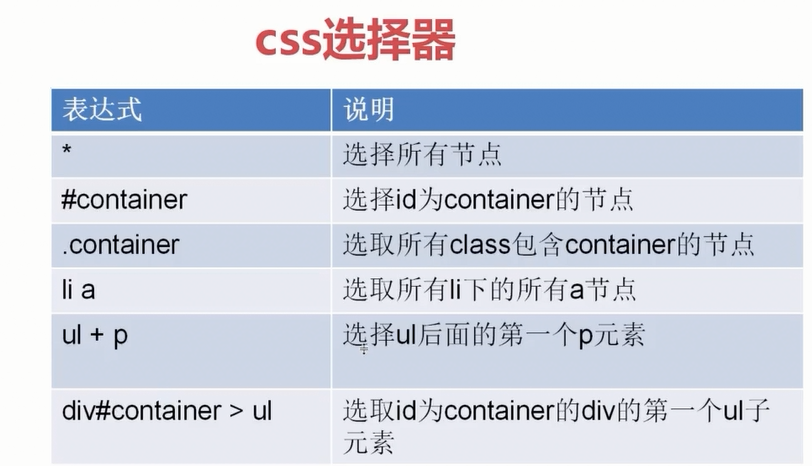
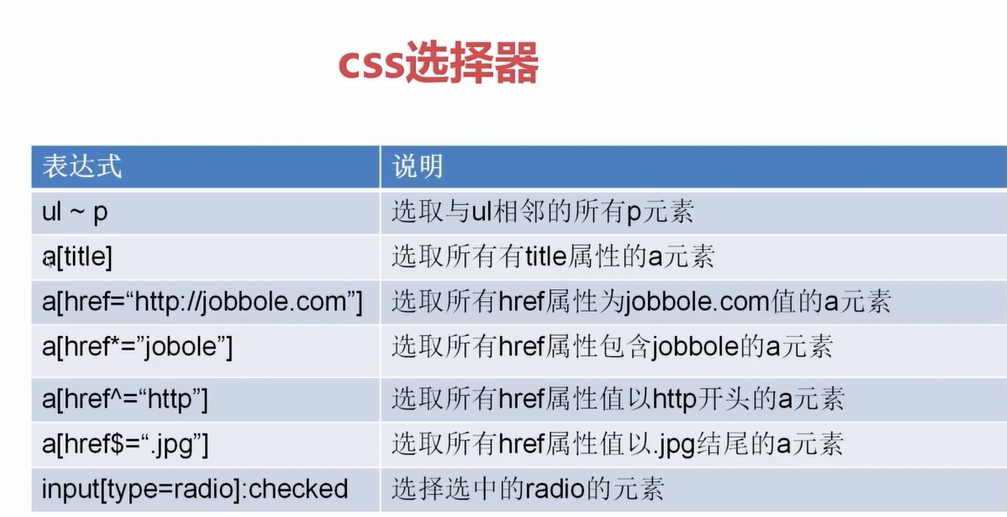
重复 学习 CSS
>>> aa = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extra
ct()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号