转--sql中where和having的使用场景与区别
分享关于mysql中的where和having子句的区别,本文主要分享对象为刚刚接触sql的新人,下面将结合实际案例分析:
下面以一个例子来具体的讲解:
1. where和having都可以使用的场景
1)select addtime,name from dw_users where addtime> 1500000000
2)select addtime,name from dw_users having addtime> 1500000000
解释:上面的having可以用的前提是我已经筛选出了addtime字段,在这种情况下和where的效果是等效的,但是如果我没有select addtime就会报错!!因为having是从前面筛选的字段再筛选,而where是从数据表中的字段直接进行的筛选的。
2. 只可以用where,不可以用having的情况
1) select addtime,name from dw_users where addtime> 1500000000
2) select phone,name from dw_users having addtime> 1500000000 //报错!!!因为前面并没有筛选出addtime字段
3. 只可以用having,不可以用where情况
查询每种category_id商品的价格平均值,获取平均价格大于100元的商品信息
1)select category_id , avg(price) as ag from dw_goods group by goods_category having ag > 100
2)select category_id , avg(price) as ag from dw_goods where ag>100 group by goods_category //报错!!因为from dw_goods 这张数据表里面没有ag这个字段
注意:
where 后面要跟的是数据表里的存在的字段,如果我把ag换成avg(price)也是错误的!因为表里没有该字段。
而having只是根据前面查询出来的是什么就可以后面接什么(比如一些聚合函数这样的“伪字段”)。
转载自:http://baijiahao.baidu.com/s?id=1600513158500665764&wfr=spider&for=pc
第二篇:
前一段时间的面试,问道这个问题,不太清楚了,感觉有必要来总结一下。话不多说,直接开始吧!
一、order by的用法
使用order by,一般是用来,依照查询结果的某一列(或多列)属性,进行排序(升序:ASC;降序:DESC;默认为升序)。
当排序列含空值时:
ASC:排序列为空值的元组最后显示。
DESC:排序列为空值的元组最先显示。
为了好记忆,我的理解是,可以把null值看做无穷大,因为不知道具体为多少。然后去考虑排序,asc升序null肯定在最后,而desc降序,null肯定在最前面。(我的想法,轻喷。。。 )
)
1》单一列属性排序
举例1:默认排序:
select * from s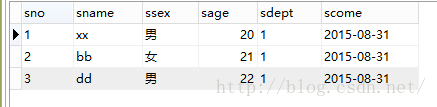
select * from s order by sno desc
按照sno降序:
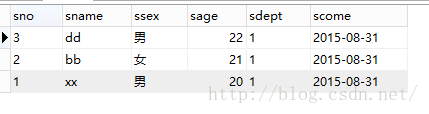
2》多个列属性排序
选择多个列属性进行排序,然后排序的顺序是,从左到右,依次排序。
如果前面列属性有些是一样的话,再按后面的列属性排序。(前提一定要满足前面的属性排序,因为在前面的优先级高)。
举例2:
-
select * from s
-
order by sname desc, sage desc

首先按照sname降序排序,然后出现了xx一样的,在按照sage降序排序。(默认sage是升序)。
如果最开始使用sno排序,
-
select * from s
-
order by sno desc, sage asc

必须先满足前面列属性的排序(sno在前优先级高)。才会去考虑后续列属性的排序。
二、group by的用法
group by按照查询结果集中的某一列(或多列),进行分组,值相等的为一组。
1》细化集函数(count,sum,avg,max,min)的作用对象:
未对查询结果分组,集函数将作用于整个查询结果。
对查询结果分组后,集函数将分别作用于每个组。
例子3:
求各个课程号及相应的选课人数:
SELECT cno,count(sno) from sc

对整个表进行count。
SELECT cno,count(sno) from sc group by cno
对分组的表进行count
sc表内容如下:
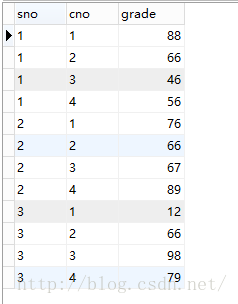
2》GROUP BY子句的作用对象是查询的中间结果表
分组方法:按指定的一列或多列值分组,值相等的为一组。
使用GROUP BY子句后,SELECT子句的列名列表中只能出现分组属性(比如:sno)和集函数(比如:count())。
select sno,count(cno) from sc group by sno
3》多个列属性进行分组举例:
select cno,grade,count(cno) from sc group by cno,grade
cno为1且成绩为66的,有3个
4》使用HAVING短语筛选最终输出结果
只有满足HAVING短语指定条件的组才输出。
HAVING短语与WHERE子句的区别:作用对象不同。
1》WHERE子句作用于基表或视图,从中选择满足条件的元组。
2》HAVING短语作用于组,从中选择满足条件的组。
举例:
查询选修了3门以上课程的学生学号:
select sno from sc group by sno having count(cno)>3
举例:
查询选修了3门以上课程,且所有课程成绩都高于60分的学生学号及课程数
-
select sno , count(cno)
-
from sc
-
where grade > 60
-
group by sno having count(cno) > 3

好的,先就总结到此吧,后续还会继续。由于水平有限,难免有不对的地方,还请指教。加油!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号