

Tesseract4.X已经有了初步成效(见下面的对比), 但目前结果对于训练之外的数据, 仍会有很大的偏差。想要更好的 OCR 结果, README 中重点强调的一点是: 在交给 Tesseract 之前, 改进图像的质量.
图像质量
Tesseract 处理 300 dpi 以上的图片会更加出色, 所以要对图片的大小有起码的要求. 分辨率和 point size 必须要考虑, 低于 10pt * 300dpi 的会被筛掉, 低于 8pt * 300dpi 的筛除地更快. 快速对图片进行检查, 是为了计算字符 x 的高度(像素). 在 10pt * 300dpi 的情况下, x的高度通常为 20 像素(字体差异上下浮动). 低于 10 像素的 x 字符高度的识别, 很难做到准确了, 如果低于 8 像素, 那么这些文本将在 ‘去噪’ 环节被过滤掉。
DPI(Dots Per Inch,每英寸点数):表示分辨率,是一个量度单位,用于点阵数码影像,指每一英寸长度中,取样、可显示或输出点的数目。
预处理流程:
二值化
二值化的过程, 实际上 Tesseract 内置了, 但处理的应该比较粗暴, 我的经验是, 这个二值化的过程, 尽量由自己进行, 选取一个尽量去除光照影响的算法,
去噪
噪点, 往往是二值化过程中, 处理亮度与颜色时遗留下来的. Tesseract 对这些噪点不会去除, 从而影响了结果的准确率.
旋转/去偏移
如果目标文字出现倾斜, Tesseract 的 line segmentation 效果会大打折扣. 如果可能的话,应该提前将文字扶正, 保证水平.
去边缘
无论是扫描件, 还是照片, 往往在二值化之后, 残留大量的黑线/黑框. 这些会被 Tesseract 错误地拾取, 造成干扰. 最好能够截取目标文字区域, 然后交给 Tesseract.
图像来源百度
V4.X 脚本:
-
text = pytesseract.image_to_string(img.open('src1\A0.jpg'), lang='chi_sim', config='--psm 3 --oem 1')
print(text)
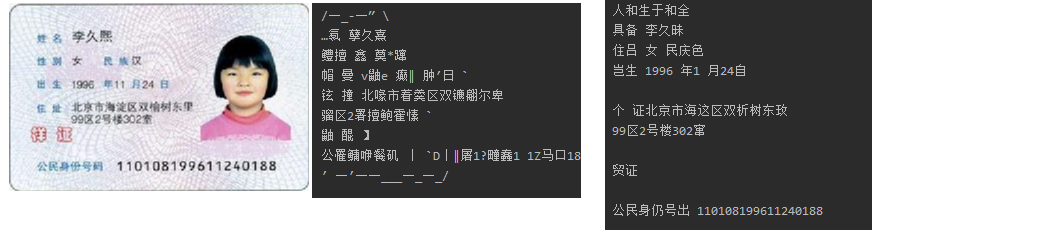
A0.jpg

A1.jpg

A2.jpg

A3.jpg
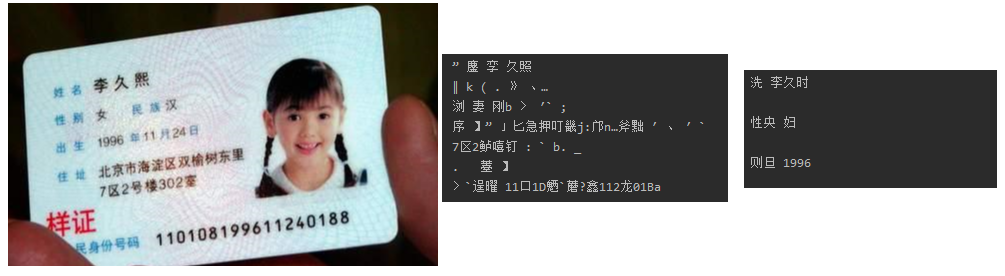
A4.jpg
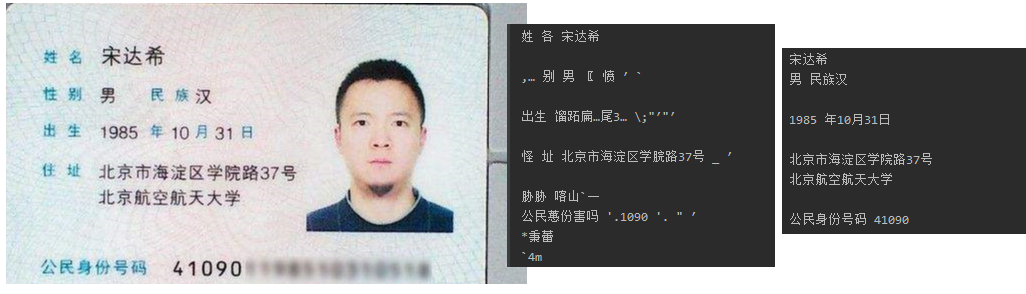
A5.jpg
参考资料:
- https://pushmind.org/2017/07/26/tesseract-notes/
- https://www.jianshu.com/p/41127bf90ca9
- https://my.oschina.net/gaoyoubo/blog/2231438/print
- https://blog.csdn.net/viewcode/article/details/7849448

 浙公网安备 33010602011771号
浙公网安备 33010602011771号