第六课 决策树
决策树(Decision Tree)是为数不多存活下来的机器学习算法之一,因其良好的性能和可解释性,被广泛应用于生产和生活当中。
1、决策树初体验
图1是一个女方是否决定相亲的决策树示例,通过年龄、长相、收入、职业四个维度进行决策判断,媒人同时介绍了两个男方,男方一:25岁、中等相貌、中等收入、IT码农,男方二:年龄30、帅气、收入一般,根据图1的决策树条件,男方一会被女方拒绝,男方二会被接受。
因此,决策树的决策流程一目了然,而且非常简单,所以决策树是至今仍在使用的机器学习算法。

图1相亲决策树示例
2、决策树的结构
决策树是一个倒长的树型结构,如图2所示,图中的黑实心圆表示分支结点(包含决策树的根结点),黑实心矩形为叶子结点。
决策树的结点分为根结点、分支结点和叶子结点,根结点是决策树的起点,是算法执行流的起点,根据根结点的条件判断后续的执行流程,是往左走还是往右走; 根结点本质上也是分支结点,分支结点起到一个承上启下的作用,用于根据分支结点的条件设置,判断下一步是往左走还是往右走; 叶子结点是决策树的结果输出结点,算法执行流走到了叶子结点,就表示找到了对应的结果。
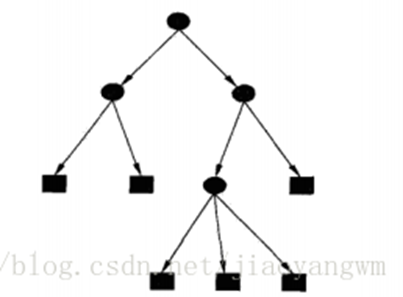
图2决策树结构抽象定义
3、构建决策树
决策树使用起来非常简单高效,其算法关键点是如何构建决策树,而构建决策树的关键是如何选择分支节点(分裂结点)以及分支结点的判断条件,目前常用的用于选择分支结点及分裂值的方法有ID3、C4.5、和CART。
3.1 ID3算法
ID3英文全称是Iterative Dichotomizer 3,是寻找使当前节点信息增益(熵)下降最快的特征(属性)及其分裂值,是一种贪心算法。信息增益的计算依据熵的计算,即算法经过当前节点后,系统熵下降最大。
熵的概念来自于物理学科的热力学,表示系统内部的混乱程度,热力学里面就是表示分子的运动剧烈和排列混乱程度,而在信息论里面,熵表示信息数据的有序程度,比如有一个抽屉A里装有:1本书、3支笔、1个平板, 另一个抽屉只装有:5张纸,抽屉A的熵会比抽屉B的熵大。
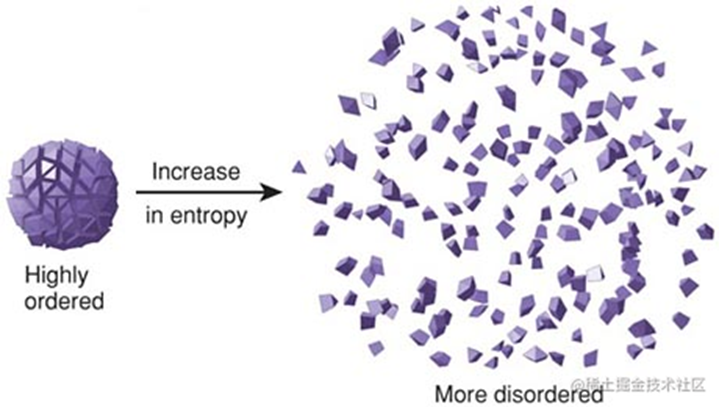
图3有序和无序状态下的熵对比
熵的计算依赖于信息量的计算,而信息量的计算公式为:
![]()
信息量是概率p的减函数,概率越大,信息量越小,反之越大,如图4所示。
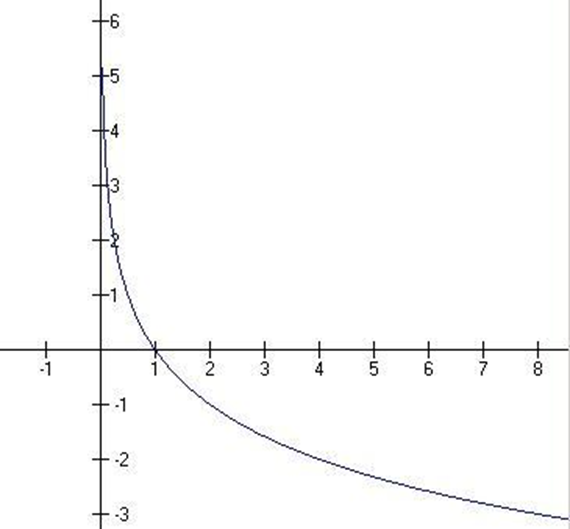
图4信息量函数曲线图
从数学角度解释信息量的含义和特点,不是太好理解,如果从另外一个角度解释,相对就容易理解信息量的内涵。
现在有2句话“明天太阳从东边升起”,“外星人来攻打地球了”,很明显第一句话“太阳从东边升起”是很确定的常识和现象,其发生的概率基本是100%,对地球上所有生物而言,基本没有什么奇怪和需要探讨的,所以第一句话的信息量很小,而第二句话“外星人来攻打地球了”,其发生概率很低,而一旦发生,那么其所代表的事件绝对是哄动全球的,因此其所蕴含的信息量是巨大的。
所以信息量和事件发生的概率是负相关的关系。
理解了信息量的含义和计算方式,那下面继续介绍熵(Entropy)的计算,熵的本质是系统内所有事件发生概率的数学期望(概率平均值),计算公式如下:
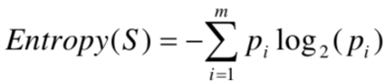
计算熵的关键,是要理清系统中有多少个事件,以及每个事件发生的概率是多少。
计算信息增益的公式如下,需要注意的是,在经过分裂节点后,会产生多个数据子集,每个数据子集会有新的熵,而最终的系统熵是这些数据子集的熵加权求和,每个数据子集的权值为数据子集的个数占总样本数的比例。
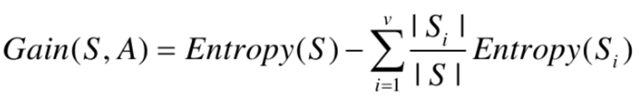
表1是一个根据天气、温度、湿度、风力等因素做出游决策的数据集,下面以这个数据集为例,说明ID3算法如何选择分裂节点,以及分裂值。表1中共14个样本,其最后一列Decision表示样本的标签,表示决策是否出游,只有yes和no两种取值。
初始状态,系统状态为(No, No, Yes, Yes, Yes, No, Yes, No, Yes, Yes, Yes, Yes, Yes, No),以下计算Log函数取10为底。
Yes的概率Pyes = 9/14 = 0.6429, No的概率Pno = 1 – Pyes = 0.3571
Entropy0(D) = -Pyes*LogPyes -Pno * LogPno
= - 0.6429 * Log0.6429 – 0.3571 * Log0.3571
= - 0.6429 * (-0.1919) – 0.3571 * (-0.4472)
= 0.1234 + 0.1597 = 0.2831
系统初始熵为0.2831,接下来要从Outlook、Temp、Humidity、Wind选取一个特征和特征的取值(分裂值),下面以Outlook取值Sunny为例,计算新的系统熵。
以Outlook=Sunny作为分裂结点,系统状态被分割为两个部分:
(No, No, No, Yes, Yes), (Yes, Yes, Yes, No, Yes, Yes, Yes, Yes, No)
第一个部分(No, No, No, Yes, Yes)的熵为
Entropy1(D | Outlook=Sunny) = -Pyes*LogPyes -Pno * LogPno
= -0.4 * Log0.4 – 0.6 * Log0.6
= 0.4 * 0.3979 + 0.6 * 0.2218
= 0.1592 + 0.1331 = 0.2923
第二个部分(Yes, Yes, Yes, No, Yes, Yes, Yes, Yes, No)的熵为
Entropy1(D | Outlook!=Sunny) = -Pyes*LogPyes -Pno * LogPno
= -0.7778 * Log0.7778 – 0.2222 * Log0.2222
= 0.7778 * 0.1091 + 0.2222 * 0.6533
= 0.0849 + 0.1452 = 0.2301
所以,以Outlook=Sunny作为分裂结点,系统状态熵为
Entropy1(D) = 5 /14 * Entropy1(D | Outlook=Sunny) + 9 / 14 * Entropy1(D | Outlook!=Sunny) = 5 / 14 * 0.2923 + 9 / 14 * 0.2301 = 0.1044 + 0.1479 = 0.2523
产生的信息增益下降值为
Gain(D|Outlook=Sunny) = Entropy0 – Entropy1 = 0.2831 – 0.2523 = 0.0308
后续再遍历Outlook的取值Overcast、Rain对应的信息增益,以及Temp、Humidity、Wind的所有取值及其对应的信息增益,并从所有这些增益中选出最大的,而这个信息增益最大的所对应的特征及特征值,就作为新的分裂节点。而再后续的分裂节点,再重复以上的计算过程,直到最终将所有样本正确地进行分类。
表1出游决策数据集
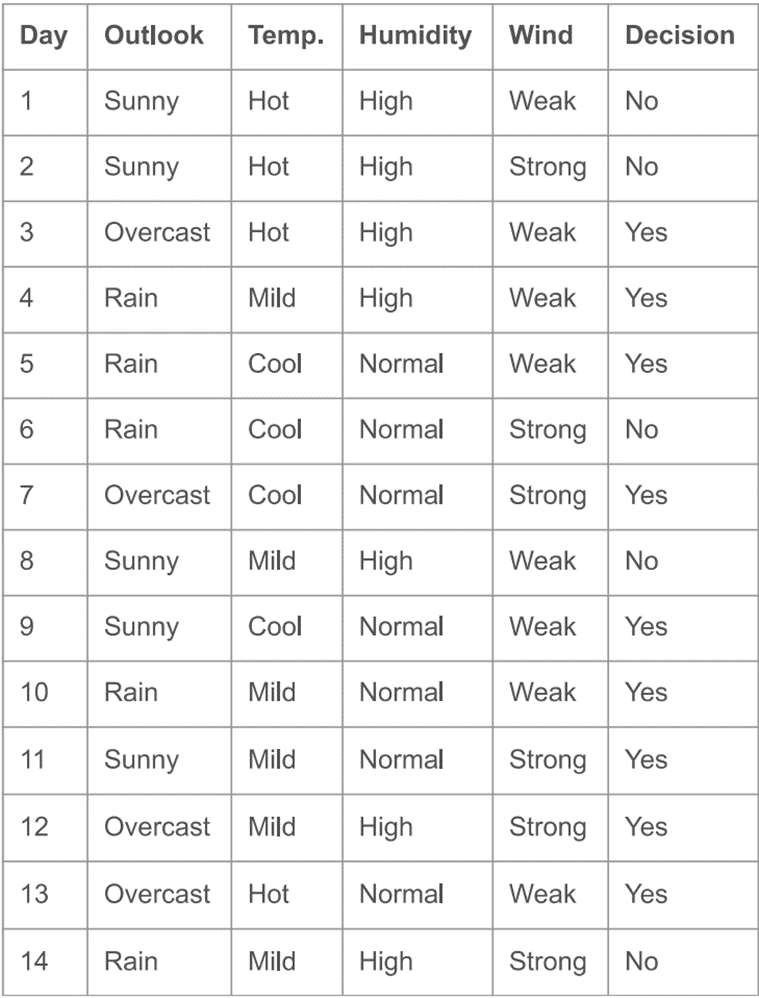
3.2 C4.5算法
C4.5是对ID3算法的一种改进,因为ID3算法倾向于选择属性值较多的特征,为修正这一点,C4.5提出了如下修正方法:
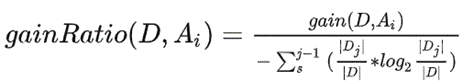
即使用信息增益率代替信息增益。
3.3 CART算法
CART算法基本与ID3算法类似,只需在计算熵的地方,替换为基尼系数即可。
CART和ID3的主要不同点在于使用CART基尼系数代替信息熵的计算,基尼系数的计算不涉及log运算,运算效率提高了多个数量级。

3.4剪枝
决策树算法的特点,会将每个样本分出它的类别,而训练集中有些数据是噪声,所以决策树比较容易出现过拟合,即训练集的预测效果比较好,但在测试集上就不太理想,所以决策树算法都会配有剪枝的策略,以提高决策树算法的泛化能力。
一种比较简单的剪枝策略是限制决策树的高度,其他的剪枝策略可参考网上的资料。
4、使用决策树
SkLearn中实现了决策树相关的算法类:DecisionTreeClassifier和DecisionTreeRegressor,DecisionTreeClassifier是分类器,DecisionTreeRegressor是回归器。
下面的代码使用DecisionTreeClassifier对鸢尾花数据集进行分类预测。

上面代码对应的输出如下:
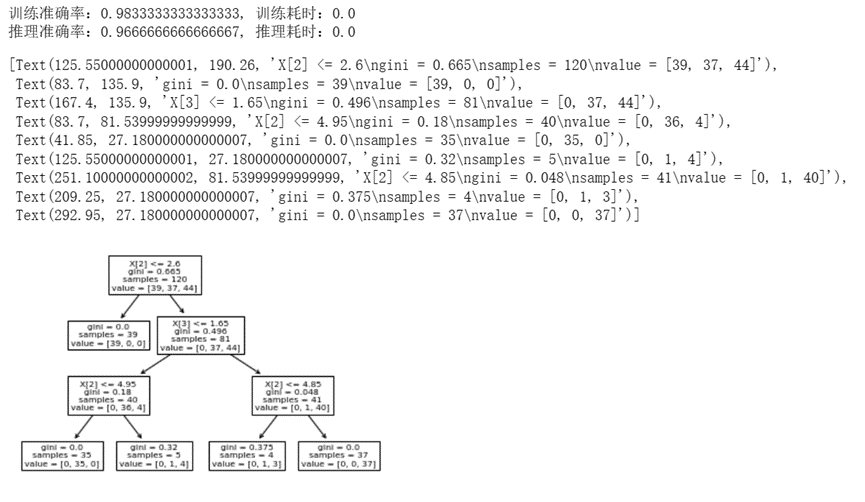
可见决策树的训练和推理速度是很快的,预测精度也还不错,测试集上的准确率稍低于训练集的准确率。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号