撑起计算机视觉半边天的ResNet【论文精读随笔】
 ResNet(残差网络)通过引入残差学习框架,解决了深度神经网络中的退化问题,使得训练数百层的网络成为可能。通过残差块的结构化设计,ResNet在ImageNet和CIFAR-10数据集上取得了显著性能提升,并推动了计算机视觉领域的范式转变。
ResNet(残差网络)通过引入残差学习框架,解决了深度神经网络中的退化问题,使得训练数百层的网络成为可能。通过残差块的结构化设计,ResNet在ImageNet和CIFAR-10数据集上取得了显著性能提升,并推动了计算机视觉领域的范式转变。
一、技术背景
消失的梯度与退化问题
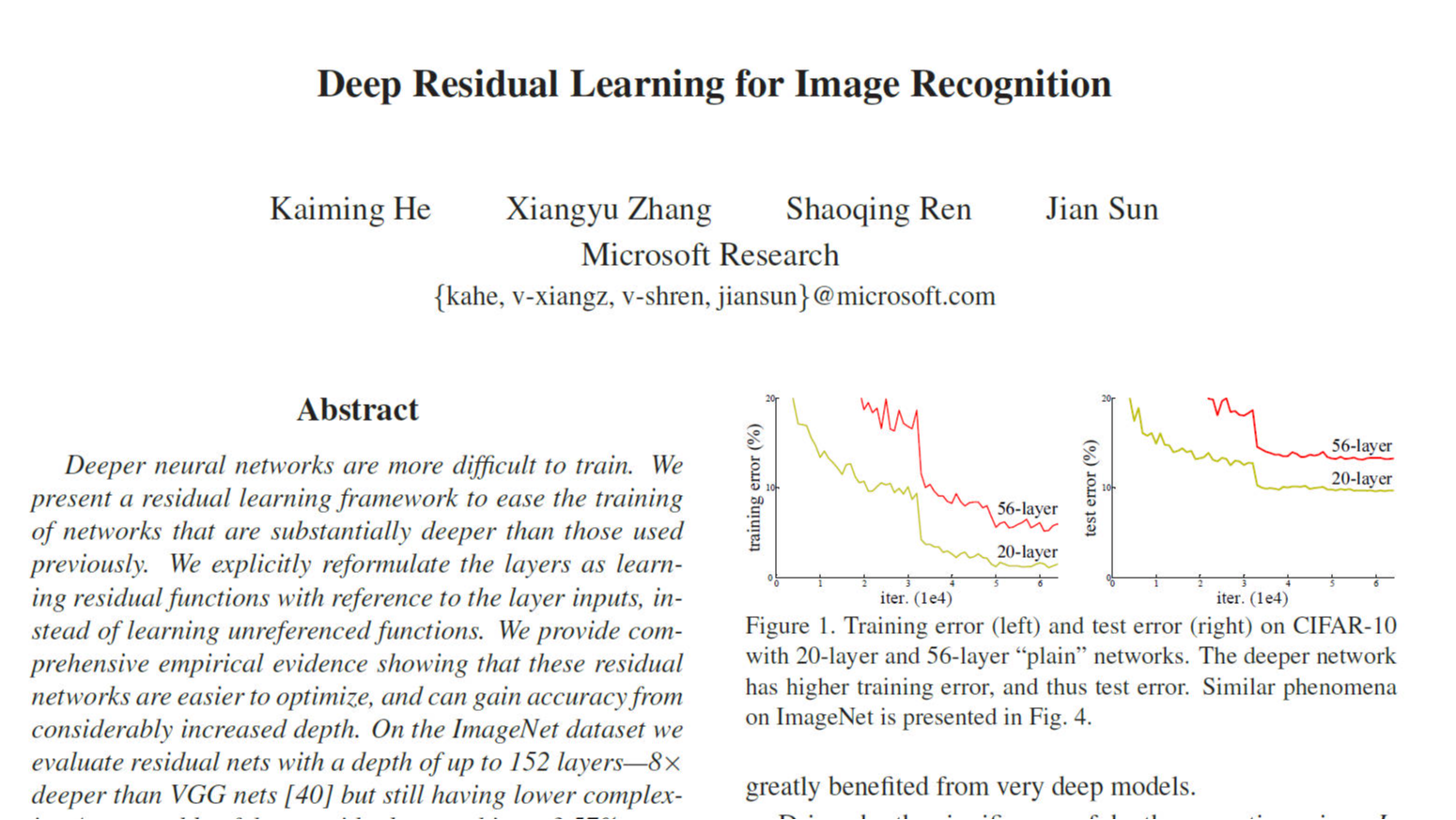
在ResNet提出之前,深度学习领域已通过VGGNet、GoogLeNet等模型验证了网络深度的重要性。然而,当网络深度超过20层时,研究者发现了一个反直觉现象:更深的网络反而导致更高的训练误差(图1)。这一现象被称为退化问题(Degradation Problem),其核心矛盾在于:理论上,深层网络至少可以通过浅层网络的解(例如将新增层设为恒等映射)达到与浅层网络相当的精度,但实际训练中优化器难以找到这样的解。

(示意图:深层网络的训练误差反而更高)
残差学习的灵感来源
作者受多网格法(Multigrid)和VLAD残差编码的启发,提出残差学习(Residual Learning):
假设目标映射为 $ \mathcal{H}(\mathbf{x}) $,让网络学习残差 $ \mathcal{F}(\mathbf{x}) = \mathcal{H}(\mathbf{x}) - \mathbf{x} $,最终输出为 $ \mathcal{F}(\mathbf{x}) + \mathbf{x} $。
这一设计的核心思想是:学习残差比直接学习目标映射更容易。若最优解接近恒等映射,残差块只需将权重逼近零即可实现。
二、核心创新
残差块的数学与结构
ResNet的核心单元是残差块(Residual Block)(图2),其数学表达为:
\(
\mathbf{y} = \mathcal{F}(\mathbf{x}, \{W_i\}) + \mathbf{x}
\)
其中:
- $ \mathcal{F}(\mathbf{x}) $:由卷积层和非线性激活组成的残差函数;
- $ \mathbf{x} $:通过恒等捷径(Identity Shortcut) 直接传递的输入。
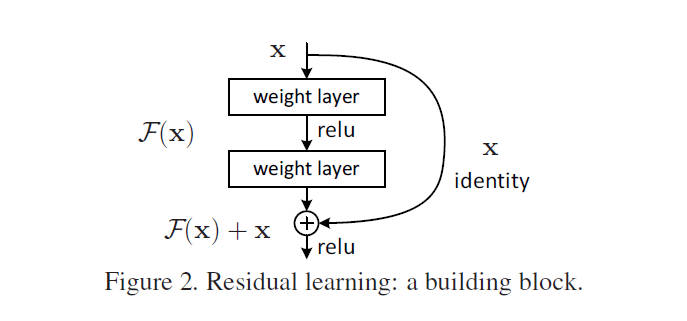
(残差块的两种形式:直接相加 vs 维度匹配时的投影)
关键设计选择
- 恒等捷径 vs 投影捷径
- 当输入输出维度一致时,直接使用恒等映射(无参数);
- 维度变化时,通过1x1卷积调整通道数(选项B),实验证明投影并非必需(表3)。
- 瓶颈结构(Bottleneck)
对于超深网络(如ResNet-152),采用1x1-3x3-1x1卷积堆叠,减少计算量(图5)。
三、实验设计分析
ImageNet实验结果
| 模型 | Top-1误差 (%) | Top-5误差 (%) | FLOPs (亿) |
|---|---|---|---|
| VGG-19 | 28.07 | 9.33 | 196 |
| ResNet-34 | 24.19 | 7.40 | 36 |
| ResNet-152 | 19.38 | 4.49 | 113 |
- 关键结论:
- ResNet-152以更低的计算量(VGG的58%)实现显著精度提升;
- 残差结构彻底解决了退化问题(图4右)。
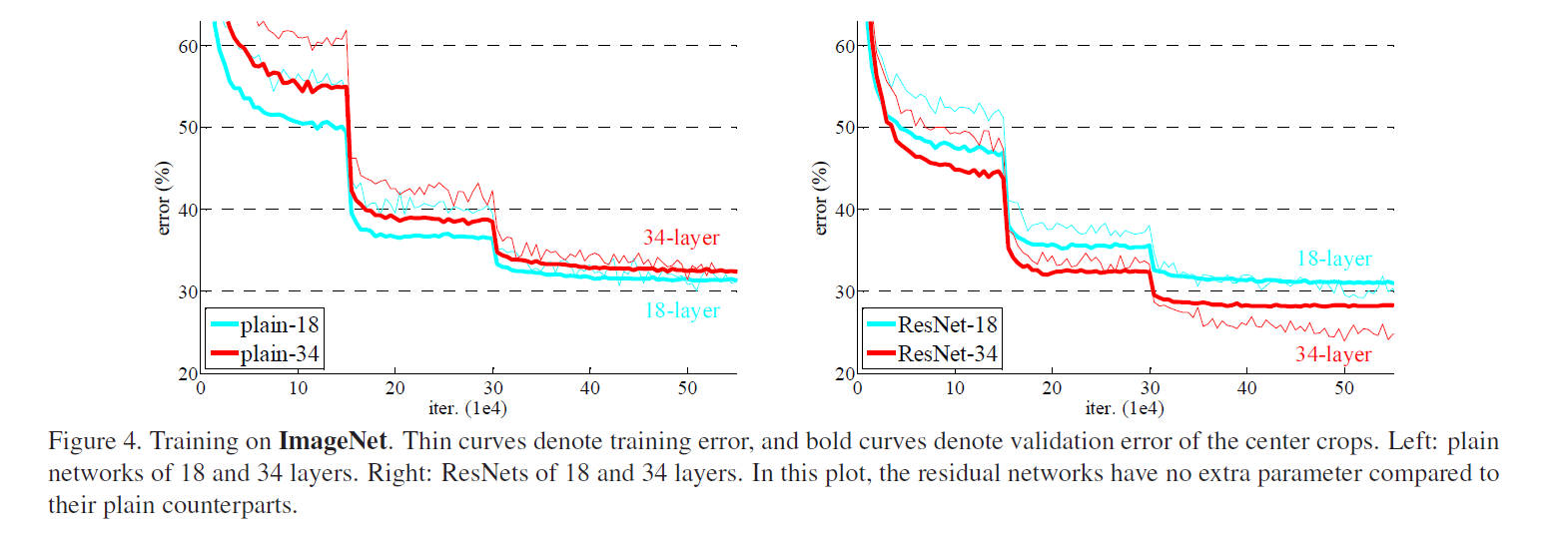
CIFAR-10的极限测试
- ResNet-110(1.7M参数)达到6.43%错误率,优于同期Highway Networks;
- 1202层网络(19.4M参数)训练误差<0.1%,但测试误差上升至7.93%,暴露过拟合问题(图6)。
四、领域影响
竞赛成绩与产业应用
- ILSVRC 2015:ResNet以3.57% Top-5误差夺冠;
- COCO检测:相对VGG-16提升28%(mAP@[.5, .95]从21.2%→27.2%);
- 后续影响:DenseNet、Transformer的残差连接、医疗图像分析等均受其启发。
研究范式转变
- 深层网络设计准则:残差连接成为标配;
- 优化理论:为后续研究(如PreAct-ResNet)提供基础。
结尾
延伸思考
- Transformer中的残差连接与多头注意力结合,是否能为CNN提供新思路?
- 能否通过可学习参数(如条件卷积)动态调整残差权重?
- 1202层ResNet的过拟合问题提示:如何在参数量与泛化性间取得平衡?
作者注:本文图表均来自原论文,代码实现可参考PyTorch官方ResNet。对残差学习的深入探讨,推荐阅读后续改进工作《Identity Mappings in Deep Residual Networks》。
本文来自博客园,作者:TfiyuenLau,转载请注明原文链接:https://www.cnblogs.com/tfiyuenlau/p/18717402

 浙公网安备 33010602011771号
浙公网安备 33010602011771号