1 package com.jsoup;
2
3 import java.io.IOException;
4
5 import org.jsoup.Jsoup;
6 import org.jsoup.nodes.Document;
7 import org.jsoup.nodes.Element;
8 import org.jsoup.select.Elements;
9
10 public class FirstJsoup {
11
12 private static Document doc;
13
14 public static void main(String[] args) {
15 try {
16 //获取网站链接
17 doc = Jsoup.connect("https://www.cnblogs.com/").get();
18 } catch (IOException e) {
19 e.printStackTrace();
20 }
21 // 调用Blogs类
22 Blogs();
23 }
24
25 public static void Blogs() {
26 //选择网页中的元素
27 Elements tests = doc.select("div#post_list>div.post_item");
28 //使用for循环遍历网页中的数据
29 for (Element test : tests) {
30 //爬取页面中的文章标题
31 String txt = test.select("div.post_item_body>h3>a.titlelnk").text();
32 System.out.println("标题:" + txt);
33 //爬取页面中的文章链接
34 String href = test.select("div.post_item_body>h3>a.titlelnk").attr("href");
35 System.out.println("链接:" + href);
36 //爬取页面中的作者
37 String author = test.select("div.post_item_foot > a.lightblue").text();
38 System.out.println("作者:" + author);
39 //对爬取的数据进行分割
40 System.out.println("---------------------------");
41 }
42 }
43 }
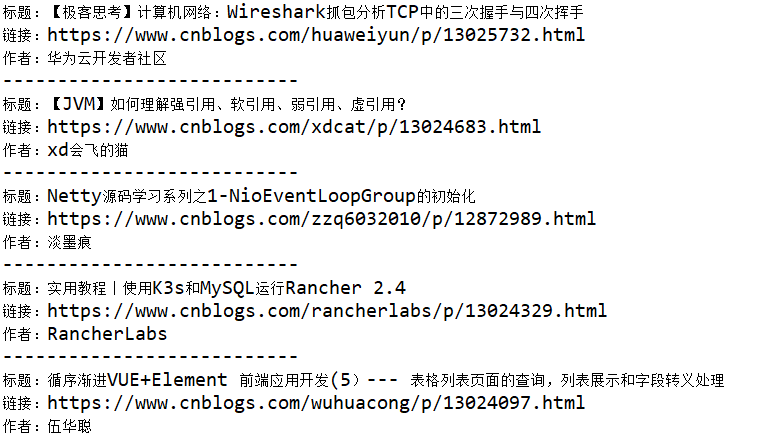
运行结果
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号