python模块3
一、 timeit
timeit 是 Python 标准库中的一个函数,用于精确测量小段代码的执行时间。它特别适合用于性能测试,能够准确地计算出代码块的运行时间,并提供有关代码执行效率的有价值信息。
# #1 测量一行代码的执行时间
# import timeit
# execution_time = timeit.timeit('x = sum(range(100))', number=10000)
# print(f"Execution time: {execution_time} seconds")
# #2使用 timeit 测量代码块的执行时间:
# import timeit
# code_to_test = '''
# result = 0
# for i in range(1000):
# result += i
# '''
# execution_time = timeit.timeit(code_to_test, number=1000)
# print(f"Execution time: {execution_time} seconds")
# #3测量函数的执行时间:
# import timeit
# def test_function():
# return sum(range(100))
# execution_time = timeit.timeit(test_function, number=10000)
# print(f"Execution time: {execution_time} seconds")
二、jieba
jieba库主要用于中文文本内容的分词,通过pip intall jieba 来安装
它有3种分词方法:
1)精确模式, 试图将句子最精确地切开,适合文本分析:
2)全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
3)搜索引擎模式,在精确模式的基础上,对长词再词切分,提高召回率,适合用于搜索引擎分词。
1、精确模式
它可以将结果十分精确分开,不存在多余的词。常用函数:lcut(str) 、 cut(str)
cut()的结果是个生成器序列,lcut()和cut()使用方法一样,不过返回的是列表。
import jieba
ss='任性的90后boy'
for i in jieba.cut(ss):
print(i)
'''
任性
的
90
后
boy<br>'''
2、全模式
它可以将结果全部展现,也就是一段话可以拆分进行组合的可能它都给列举出来了。常用函数:lcut(str,cut_all=True) 、 cut(str,cut_all=True)
import jieba
seg_str = "好好学习,天天向上。"
print("/".join(jieba.lcut(seg_str))) # 精简模式,返回一个列表类型的结果
print("/".join(jieba.lcut(seg_str, cut_all=True))) # 全模式,使用 'cut_all=True' 指定
print("/".join(jieba.lcut_for_search(seg_str))) # 搜索引擎模式
'''
好好学习/,/天天向上/。
好好/好好学/好好学习/好学/学习/,/天天/天天向上/向上/。
好好/好学/学习/好好学/好好学习/,/天天/向上/天天向上/。
'''
可以看到,全模式把句子中所有的可以成词的词语都扫描出来, 会出现一词多用、一词多意。精确模式将句子最精确的切分开,每个词都只有一种含义。
3、搜索引擎模式
将结果精确分开,对比较长的词进行二次切分。它可以将全模式的所有可能再次进行一个重组。lcut_for_search(str) 、cut_for_search(str)
import jieba
seg_list = jieba.cut_for_search("中国上海是一座美丽的国际性大都市,拥有复旦大学、上海交通大学等知名高等学府")
print(", ".join(seg_list))
'''
中国, 上海, 是, 一座, 美丽, 的, 国际, 国际性, 大都, 都市, 大都市, ,, 拥有, 复旦, 大学, 复旦大学, 、, 上海, 交通, 大学, 上海交通大学, 等, 知名, 高等, 学府, 高等学府
'''
4、jieba的其它应用
1)、添加新词
它是将本身存在于文本中的词进行一个重组,它可以将我设置的两个词连贯起来,这对于名字分词是很有帮助的,有时候分词会将三个字甚至是多个字的人名划分开来,这个时候我们就需要用到添加新词了。当然,如果你添加了文本中没有的词,那是没有任何效果.
import jieba
aa=jieba.cut('任性的90后boy来自于美丽的城市湖北武汉,他曾经在长江边游览过')
print('/'.join(aa))
'''
任性的/90/后/boy/来自于/美丽/的/城市/湖北/武汉/,/他/曾经/在/长江/边/游览/过
'''
import jieba
aa=jieba.cut('任性的90后boy来自于美丽的城市湖北武汉,他曾经在长江边游览过')
jieba.add_word('90后')
jieba.add_word('美丽的城市')
print('/'.join(aa))
'''
任性的/90后/boy/来自于/美丽的城市/湖北/武汉/,/他/曾经/在/长江/边/游览/过
'''
2)、添加字典
jieba可以添加属于自己的字典,用来切分查找关键词。这样就可以有效缩小查找范围,从而使得匹配完成度更高,时间更短。
我们可以使用load_userdict函数来读取自定义词典,它需要传入一个文件名,格式如下:
#文件一行只可写三项参数,分别为词语、词频(可省略)、词性(可省略)空格隔开,顺序不可颠倒
jieba.load_userdict(file)这样就可以读取到该文件中的所有文本,然后我们让它去匹配我们要进行分词的文本,然后利用三大模式中的一种就可以精确匹配到要查找的内容。
import jieba
jieba.load_userdict('C:\\Programs\\PythonTest3\\test.txt')
aa=jieba.cut('任性的90后boy来自于美丽的城市湖北武汉,他曾经在长江边游览过')
print('/'.join(aa))
'''
任性的/90后/boy/来自于/美丽的城市/湖北/武汉/,/他/曾经/在/长江/边/游览/过
'''
3)、删除新词
如果我们对自己所添加的新词不满意,可以直接删除。
import jieba
jieba.load_userdict('C:\\Programs\\PythonTest3\\test.txt')
jieba.del_word('90后')
aa=jieba.cut('任性的90后boy来自于美丽的城市湖北武汉,他曾经在长江边游览过')
print('/'.join(aa))
'''
任性的/90/后/boy/来自于/美丽的城市/湖北/武汉/,/他/曾经/在/长江/边/游览/过
'''
4)、处理停用词
在有时候我们处理大篇幅文章时,可能用不到每个词,需要将一些词过滤掉,这个时候我们需要处理掉这些词,比如‘的’ ‘了’、 ‘哈哈’,这些都是可有可无的词。
import jieba
stop=['的','了','哈哈']
aa=jieba.lcut('我再也回不到童年的美好时光了,哈哈,想想都觉得伤心了')
ss=''
for i in aa:
if i not in stop:
ss+=i
ll=jieba.cut(ss)
print('/'.join(ll))
'''
我/再也/回/不到/童年/美好时光/,/,/想想/都/觉得/伤心
'''
5)、权重分析
很多时候我们需要将关键词以出现的次数频率来排列,这个时候就需要进行权重分析函数了,它会将字符串中出现频率最高的几个词按顺序排列了出来,如果你想打印出这几个词的频率的话,只需添加一个withWeight参数,如果想输出指定数的词,只需添加一个topK参数。一定要这样导入,否则会报错 import jieba.analyse
import jieba.analyse
text='我再也回不到童年美好的时光了,哈哈,想想都觉得伤心了,童年是我梦寐以前的美好,它带给我太多美好'
tag=jieba.analyse.extract_tags(sentence=text,topK=5,withWeight=True)
print(tag)
'''
[('美好', 1.43198988550875), ('童年', 1.04541792312), ('我太多', 0.74717296893125), ('梦寐', 0.7189238987), ('带给', 0.50886099238125)]
'''
6)、调节单个词语的词频
在分词过程中,我们可以将某个词显式进行划分。如下,可以看到它将美和好分开了。
import jieba
aa=jieba.lcut('我再也回不到童年美好的时光了,哈哈,想想都觉得伤心了',HMM=False)
print('/'.join(aa))
jieba.suggest_freq(('美','好'),tune=True)#加上tune参数表示可以划分
aa=jieba.lcut('我再也回不到童年美好的时光了,哈哈,想想都觉得伤心了',HMM=False)
print('/'.join(aa)) #生成新词频
'''
我/再也/回/不到/童年/美好/的/时光/了/,/哈哈/,/想想/都/觉得/伤心/了
我/再也/回/不到/童年/美/好/的/时光/了/,/哈哈/,/想想/都/觉得/伤心/了
'''
7)、查看文本内词语的开始和结束位置
有时候我们为了得到某个词的准确位置以及分布情况我们可以使用函数tokenize()来定位。
import jieba
ab=jieba.tokenize('任性的90后boy,毕业于家里蹲大学,热爱学习,目前单身,无工作,望富婆垂怜')
for y in ab:
print(f'单词:{y[0]}\t\t开始:{y[1]}\t\t结束:{y[2]}')
'''
单词:任性的 开始:0 结束:3
单词:90 开始:3 结束:5
......
'''
5、jieba 分词简单应用
import jieba
txt = open("三国演义.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(3):
word, count = items[i]
print("{0:<5}{1:>5}".format(word, count))
三、pyttsx3
pyttsx3是Python中的文本到语音转换库。pyttsx3的安装pip install pyttsx
1、导入pyttsx3库后,调用speak函数即可进行语音播放。
import pyttsx3
#语音播放
pyttsx3.speak("How are you?")
pyttsx3.speak("I am fine, thank you")
2、如果我们想要修改语速、音量、语音合成器等,可以用如下方法。
import pyttsx3
engine = pyttsx3.init() #初始化语音引擎
rate = engine.getProperty('rate')
print(f'语速:{rate}')
volume = engine.getProperty('volume')
print (f'音量:{volume}')
#设置语速、音量等参数
engine.setProperty('rate', 100) #设置语速
engine.setProperty('volume',0.6) #设置音量
运行结果为:
语速:200
音量:1.0
3、查看语音合成器
voices = engine.getProperty('voices')
for voice in voices:
print(voice)
运行结果如下:
<Voice id=HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_ZH-CN_HUIHUI_11.0 name=Microsoft Huihui Desktop - Chinese (Simplified) languages=[] gender=None age=None> <Voice id=HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_EN-US_ZIRA_11.0 name=Microsoft Zira Desktop - English (United States) languages=[] gender=None age=None>
合成器的主要参数如下:
age发音人的年龄,默认为Nonegender以字符串为类型的发音人性别: male, female, or neutral.默认为Noneid关于Voice的字符串确认信息languages发音支持的语言列表,默认为一个空的列表name发音人名称,默认为None
默认的语音合成器有两个,两个语音合成器均可以合成英文音频,但只有第一个合成器能合成中文音频。如果需要其他的语音合成器需要自行下载和设置。
import pyttsx3
engine = pyttsx3.init() #初始化语音引擎
engine.setProperty('rate', 150) #设置语速
engine.setProperty('volume',0.6) #设置音量
voices = engine.getProperty('voices')
engine.setProperty('voice',voices[0].id) #设置第一个语音合成器
engine.say("春光灿烂猪八戒")
engine.runAndWait()
engine.stop()
四、pandas_alive
Pandas_Alive,它以 matplotlib 绘图为后端,不仅可以创建出令人惊叹的数据动画可视化,而且使用方法非常简单。
#动态条形图
import pandas as pd
import pandas_alive
#显示中文宋体字体导入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体,正常显示中文)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
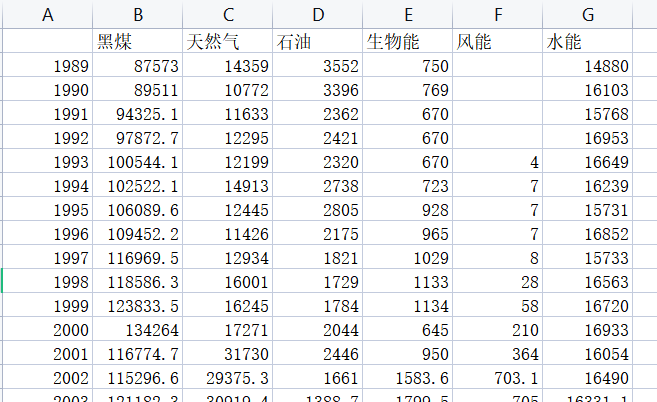
elec_df = pd.read_csv("C:/Programs/test/us_Elec_Gen_1980_2018.csv",index_col=0,parse_dates=[0],thousands=',',encoding='gb18030')
elec_df.fillna(0).plot_animated('example-electricity.gif',period_fmt="%Y",title='Australian1980-2018',n_visible = 15)

#动态柱形图
import pandas as pd
import pandas_alive
#显示中文宋体字体导入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体,正常显示中文)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
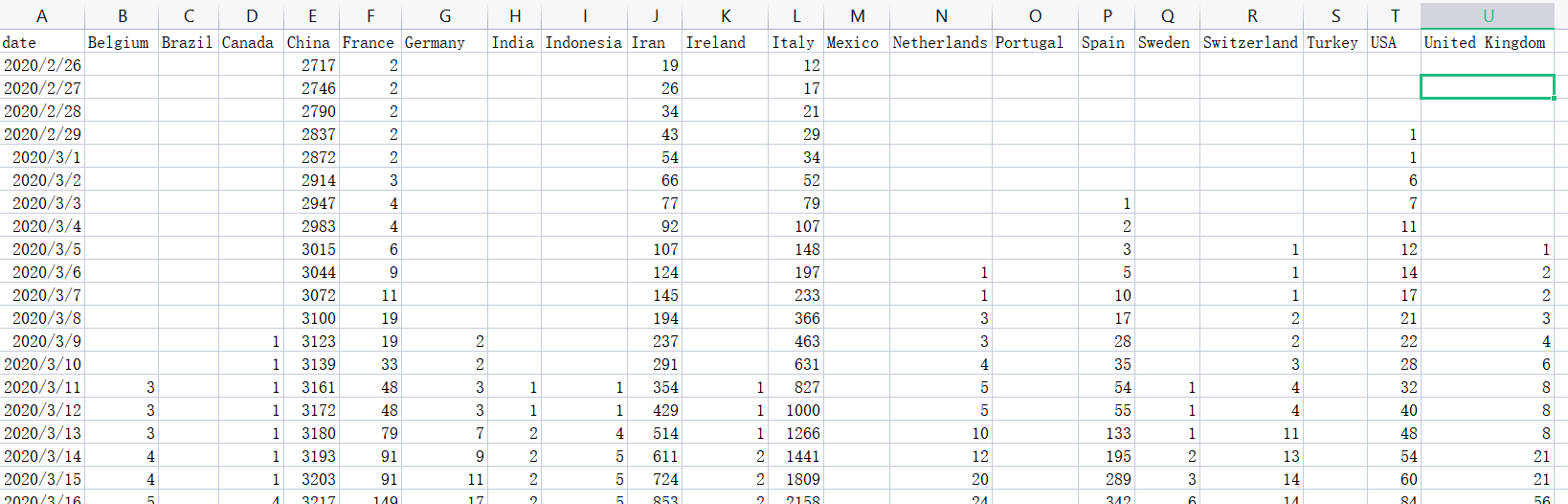
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.plot_animated(filename = 'example-barv-chart.gif',orientation='v',n_visible = 15)

#动态曲线图
import pandas as pd
import pandas_alive
#显示中文宋体字体导入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体,正常显示中文)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.diff().fillna(0).plot_animated(filename = 'example-line-chart.gif',kind = 'line',period_label = { 'x': 0.25, 'y':0.9 },n_visible = 15)
#动态面积图
import pandas as pd
import pandas_alive
#显示中文宋体字体导入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体,正常显示中文)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.sum(axis=1).fillna(0).plot_animated(filename='example-bar-chart.gif',kind='bar',
period_label={'x':0.1,'y':0.9},enable_progress_bar=True, steps_per_period=2, interpolate_period=True, period_length=200)

#动态饼图
import pandas as pd
import pandas_alive
#显示中文宋体字体导入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体,正常显示中文)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
covid_df.plot_animated(filename='example-pie-chart.gif',kind="pie",rotatelabels=True,period_label={'x':0,'y':0})

#多个图表
import pandas_alive
import pandas as pd
#显示中文宋体字体导入
import matplotlib as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体,正常显示中文)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
covid_df = pd.read_csv("C:/Programs/test/covid19.csv",index_col = 0,parse_dates = [ 0 ])
animated_line_chart = covid_df.diff().fillna(0).plot_animated(kind='line',period_label=False,add_legend=False)
animated_bar_chart = covid_df.plot_animated(n_visible=10)
pandas_alive.animate_multiple_plots('example-bar-and-line-chart.gif',[animated_bar_chart,animated_line_chart],enable_progress_bar=True)

五、PyWebIO
PyWebIO使Python 也可以写前端,PyWebIO 开发页面我们不用过分关心CSS、JS等文件,全程我们只需要操作一个py脚本。也不用关心数据库配置、前后端交互,就像上面的数据分析一样,创建一个空白页面,然后一行代码添加一部分内容,内容可以实时编译输出。PyWebIO 提供了一系列命令式的交互函数来在浏览器上获取用户输入和进行输出,将浏览器变成了一个“富文本终端”,可以用于构建简单的 Web 应用或基于浏览器的 GUI 应用。使用 PyWebIO,开发者能像编写终端脚本一样(基于 input 和 print 进行交互)来编写应用,无需具备 HTML 和 JS 的相关知识;PyWebIO 还可以方便地整合进现有的 Web 服务。非常适合快速构建对 UI 要求不高的应用。安装:pip install PyWebIO
PyWebIO一行代码对应一个操作,例如可以调用 put_text() 、 put_image() 、 put_table() 等函数输出文本、图片、表格等内容到浏览器!
1、入门例子
我们用这个例子,来实现对数据的提交和检验。
from pywebio.input import *
from pywebio.output import *
from pywebio.pin import *
from pywebio import start_server
def input_input():
# input的合法性校验
# 自定义校验函数
def check_age(n):
if n<1:
return "Too Small!@"
if n>100:
return "Too Big!@"
else:
pass
myAge = input('please input your age:',type=NUMBER,validate=check_age,help_text='must in 1,100')
print('myAge is:',myAge)
if __name__ == '__main__':
start_server(
applications=[input_input,],
debug=True,
auto_open_webbrowser=True,
remote_access=True,
)
 效果图
效果图
2、input
# 输入框
input_res = input("please input your name:")
print('browser input is:', input_res)
# 密码框
pwd_res = input("please input your password:",type=PASSWORD)
print('password:', pwd_res)
# 下拉框
select_res = select("please select your city:",['北京','西安','成都'])
print('your city is:',select_res)
# checkbox
checkbox_res = checkbox("please confirm the checkbox:",options=['agree','disagree'])
print('checkbox:', checkbox_res)
# 文本框
text_res = textarea("please input what you want to say:",rows=3,placeholder='...')
print('what you said is:',text_res)
# 文件上传
upload_res = file_upload("please upload what you want to upload:",accept="image/*")
with open(upload_res.get('filename'),mode='wb') as f: # 因为读取的图片内容是二进制,所以要以wb模式打开
f.write(upload_res.get('content'))
print('what you uploaded is:',upload_res.get('filename'))
# 滑动条
sld = slider('这是滑动条',help_text='请滑动选择') # 缺点是不能显示当前滑动的值
toast('提交成功')
print(sld)
# 单选选项
radio_res = radio(
'这是单选',
options=['西安','北京','成都']
)
print(radio_res)
# 更新输入项
Country2City={
'China':['西安','北京','成都'],
'USA': ['纽约', '芝加哥', '佛罗里达'],
}
countries = list(Country2City.keys())
update_res = input_group(
"国家和城市联动",
[
# 当国家发生变化的时候,onchange触发input_update方法去更新name=city的选项,更新内容为Country2City[c],c代表国家的选项值
select('国家',options=countries,name='country',onchange=lambda c: input_update('city',options=Country2City[c])),
select('城市',options=Country2City[countries[0]],name='city')
]
)
print(update_res)
 输入框
输入框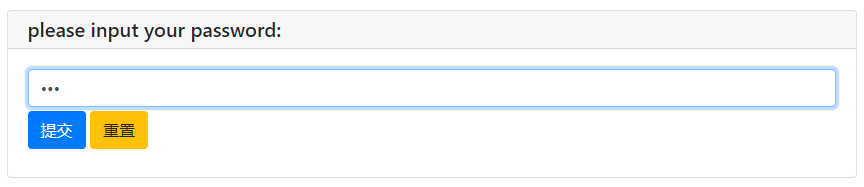 密码框
密码框 选择框
选择框 勾选框
勾选框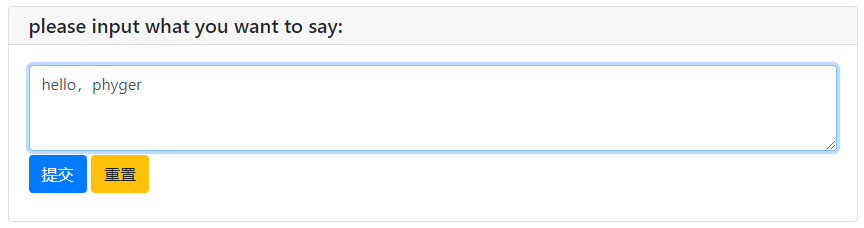 文本框
文本框 文件上传
文件上传 滑动条
滑动条 单选框
单选框 输入框联动-1
输入框联动-1 输入框联动-2
输入框联动-2
3、output
# 文本输出
put_text('这是输出的内容')
# 表格输出
put_table(
tdata=[
['序号','名称'],
[1,'中国'],
[2,'美国']
]
)
# MarkDown输出
put_markdown('~~删除线~~')
# 文件输出
put_file('秘籍.txt','降龙十八掌')
# 按钮输出
put_buttons(
buttons=['A','B'],
onclick=toast
)

4、部分高级用法
# ========================== 1-输入框的参数 ==============================
# input的更多参数
ipt = input(
'This is label',
type=TEXT,
placeholder='This is placeholder', # 占位
help_text='This is help text', # 提示
required=True, # 必填
datalist=['a1', 'b2', 'c3']) # 常驻输入联想
print('what you input is:',ipt)
# =========================== 2-输入框自定义校验 =============================
# input的合法性校验
# 自定义校验函数
def check_age(n):
if n<1:
return "Too Small!@"
if n>100:
return "Too Big!@"
else:
pass
myAge = input('please input your age:',type=NUMBER,validate=check_age,help_text='must in 1,100')
print('myAge is:',myAge)
# ============================ 3-代码编辑 ============================
# textare的代码模式
code = textarea(
label='这是代码模式',
code={
'mode':'python',
'theme':'darcula',
},
value='import time\n\ntime.sleep(2)'
)
print('code is:',code)
# ============================== 4-输入组 ==========================
def check_age(n):
if n<1:
return "Too Small!@"
if n>100:
return "Too Big!@"
else:
pass
def check_form(datas):
print(datas)
if datas.get("age")==1:
#return 'you are only one years old!'
return ('age','you are only one years old!')
if len(datas.get("name"))<=3:
return ('name','Name Too short!!!')
# 输入组
datas = input_group(
"It's input groups...",
inputs=[
input('please input name',name='name'),
input('please input age',name='age',type=NUMBER,validate=check_age)
],
validate=check_form
)
# ====================================== 5-输入框的action =========================================
import time
def set_today(set_value):
set_value(time.time())
print(time.time())
tt = input('选择时间',action=('Today',set_today),readonly=True)
print(tt)
# ====================================== 5-输入框的弹窗 =========================================
def set_some(set_value): # 此方法可以将选择的英文转换为中文
with popup('It is popup'): # popup 是 output 模块中的方法
put_buttons(['Today','Tomorrow'],onclick=[lambda: set_value('今天','Today1'),lambda:set_value('明天','Tomorrow2')]) # set_value('今天','Today') 按Today的按钮输入Today1,实际对应:今天
put_buttons(['Exit'],onclick=lambda _: close_popup())
pp = input('go popup',type=TEXT,action=('按钮弹窗',set_some))
print(pp)
联想词常驻+help_text

代码编辑模式
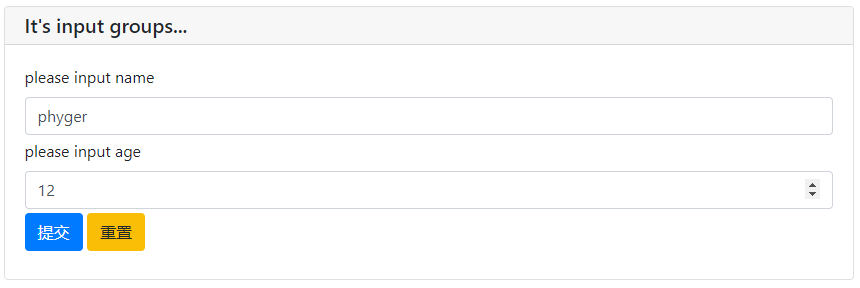
输入组
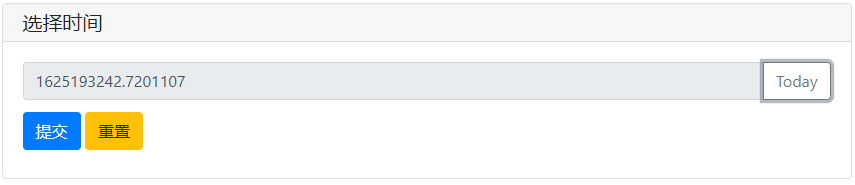
输入框的action

输入框的弹窗
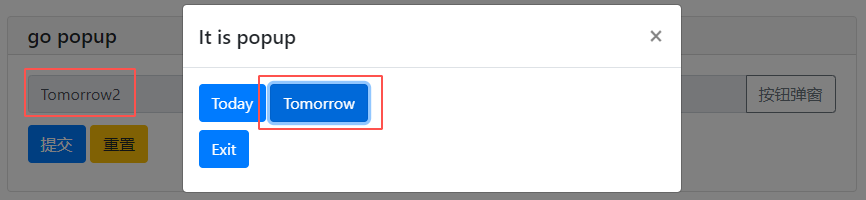
按钮的onclick
代码中的
六、pywebview
pywebview 是一个轻量级的 python 库,旨在简化桌面应用程序的开发。它利用系统的 WebView 组件,使得开发人员可以使用现代 Web 技术(HTML、CSS、JavaScript)来创建用户界面,同时使用 python 处理业务逻辑。pywebview 使得创建跨平台桌面应用程序变得更加简单和高效。主要功能和特点:
- 跨平台支持, pywebview 支持 Windows、macOS 和 Linux,确保应用程序可以在多个平台上运行。
- 简易集成,可以轻松地将 Web 应用嵌入到桌面应用中,无需复杂的设置
- 安全性:支持禁用本地文件访问和执行外部脚本,提供额外的安全层。
1、安装
# 会默认安装基本的依赖
pip install pywebview2、pywebview默认使用系统自带的 WebView 组件作为浏览器引擎
- windows 使用默认使用 Internet Explorer 11 作为 WebView 引擎。
- macOS 默认使用 WebKit 引擎,这是 macOS 自带的 WebView 组件,基于 Safari 浏览器的引擎。
- Linux 默认使用 WebKitGTK,这是 Linux 上常用的 WebView 组件,基于 WebKit 引擎
如果需要其他引擎,需要单独安装:
3、windows中使用 CEF(Chromium Embedded Framework)作为引擎
pip install cefpython3
❝ 指定backend❞
import webview
webview.create_window('My App', 'https://www.baidu.com/', backend='cef')
webview.start()
4、基础使用
# demo1.py
import webview
window = webview.create_window('Woah dude!', 'https://pywebview.flowrl.com')
webview.start()
❝create_window函数用于创建一个新窗口,并返回一个 window 对象实例。在调用webview.start()之前创建的窗口将在 GUI 循环启动后立即显示。GUI 循环启动后创建的窗口也会立即显示。您可以创建任意数量的窗口,所有已打开的窗口都会按创建顺序存储在webview.windows列表中。❞
5、同时打开两个窗口
import webview
first_window = webview.create_window('Woah dude!', 'https://pywebview.flowrl.com')
second_window = webview.create_window('Second window', 'https://woot.fi')
webview.start()
6、调用后台执行
❝webview.start会启动一个 GUI 循环,并阻止进一步的代码执行,直到最后一个窗口被销毁。由于 GUI 循环是阻塞的,您必须在单独的线程或进程中执行后台逻辑。您可以通过将函数传递给webview.start(func, (params,))来执行后台代码。这将启动一个单独的线程,与手动启动线程是相同的。❞
# 界面打开后就会自动弹窗
import webview
def custom_logic(window):
window.toggle_fullscreen()
window.evaluate_js('alert("Nice one brother")')
window = webview.create_window('Woah dude!', html='<h1>Woah dude!<h1>')
webview.start(custom_logic, window)
❝ window.evaluate_js可以使用python执行js代码❞
7、js调用python
import webview
# 这里是核心,是和js中交互的关键
class Api():
def log(self, value):
print(value)
webview.create_window("Test", html="<button onclick='pywebview.api.log(\"Woah dude!\")'>Click me</button>", js_api=Api())
webview.start()
❝ 在打开的界面中点击按钮,后台就可以看到log函数被调用,会把传入的值 Woah dude! 打印到控制台❞
8、HTTP Server
❝ pywebview 默认使用 bottlepy 作为http 服务,默认端口是8080,前后服务也可以使用http 通信❞
- demo.py
import webview
from bottle import Bottle, run, static_file
import threading
app = Bottle()
@app.route("/api/data")
def get_data():
return {"message": "Hello from the server!"}
@app.route("/")
def index():
return static_file("index.html", root=".")
# 启动 HTTp 服务器
def start_server():
run(app, host="localhost", port=8080)
if __name__ == "__main__":
# 在单独的线程中启动 HTTp 服务器
server_thread = threading.Thread(target=start_server)
server_thread.daemon = True
server_thread.start()
# 创建并启动 pywebview 窗口
webview.create_window("pywebview Example", "http://localhost:8080")
webview.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号