python—web自动化(4)—测试框架之unittest2的基本操作方法
- 学习目标:自动化测试框架搭建unittest2
- 需求分解:
- 测试用例
- BaseTestCase:
-
- 封装测试用例中相同的部分
-
- 数据驱动测试(ddt):
-
- 测试数据与操作分离
-
- 生成测试报告:
- BaseTestCase:
- 测试用例
- 技术实验:
- unittest2使用:单元测试框架
- 导包:unittest2
- 继承unittest2代码库中的TestCase类:表示当前类是测试用例类
- 定义一个test开头的方法:表示这是测试用例方法,可以直接运行
- 重写父类中的两个方法:
- setUp():在每条测试用例方法开始前,要做的预置操作
- tearDown():在每条测试用例方法结束后,要做的场景还原
- 通过main关键字,增加:
- if__main__ == '__main__' :当前文件直接运行时,该语句下面的代码才会运行
- unittest2.main():调用unittest2的主方法,会执行当前类中的所以方法
- 更加光标位置,执行对应位置的方法
- BaseTestCase:
-
- 创建一个父类,继承unittest2.TestCase,在这个类里实现setUpClass,tearDownClass方法,控制浏览器打开和关闭操作
- 后续测试用例继承这个BaseTestCase父类
-
- 数据驱动测试(ddt):批量注册用户
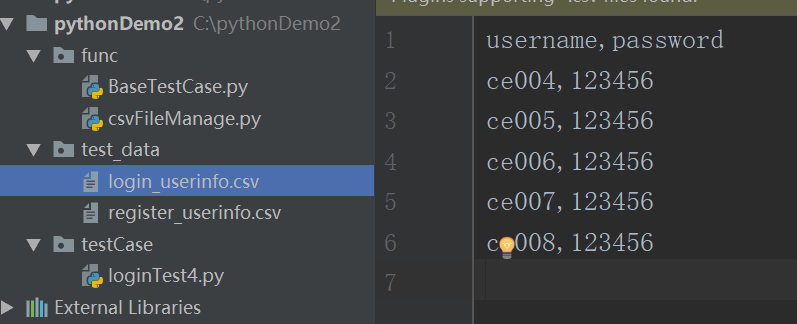
- 在csv文件中保存5个用户信息
- 编写读取csv文件的方法:
- 导入csv库
- 指定csv文件路径:path = r'c:/../...xx.csv'
- 打开csv文件:with open(path) as file
- 读取csv文件内容
- 打印读取内容
- 把读取到的内容分别传入测试用例中,循环执行:
- for循环的方式,一条用例失败,会使后面的测试数据不执行
- 改进方法:
- 导入ddt:全名是data driver test
- 调用读取csv的方法
- 在类上面加装饰器:@ddt.ddt 表示当前是数据驱动测试的类
- 在方法上面加装饰器:
- @ddt.data() 用例指定测试数据源,要求源是多个参数的数据格式
- 列表前加*号:解包
- 生成测试报告:
- 组织和执行用例
- 在项目根节点建立python文件,找出所有测试用例,suite = unitter2.defaultTestLoader.discover('测试用例文件夹名成',测试用例文件名的规则)
- 执行找出的用例集suiet,TextTestRunner(默认方式没有美丽的报告)
- 下载并复制HTMLTestRunner.py到项目的lib文件夹中,用HTMLTestRunner这个类代替TextTestRunner来执行用例
- 实例化HTMLTestRunner:
-
-
- file = open(测试报告的路径,’wb‘)
- HTMLTestRunner(二进制文件,日志详细程度,报告标题,报告正文,测试人员名字)
- 通过实例化的对象,调用run(suite)
-
-
- 实例化HTMLTestRunner:
- 补充断言,可以在报告中直观展示用例执行明细
- 自动判断测试用例结果
- 检查点:
- 页面级别检查:
-
- 网页标题
- 网址
-
- 页面元素级别:
-
- 元素文本
- 元素的某个属性
-
- 页面级别检查:
- 组织和执行用例
- unittest2使用:单元测试框架
- 案例代码演示:
- 登录测试用例V1版:
LoginTestV1.py
- 代码:
-
'''' 登录测试用例V1版本: 使用unitest2,执行测试用例 ''' # 导入包unittest2 import time import warnings import unittest2 from selenium import webdriver # 创建测试类,继承unittest2.TestCsae class LoginTestV1(unittest2.TestCase): # 1 前置方法 @classmethod def setUpClass(cls): warnings.simplefilter('ignore', ResourceWarning) # 打开浏览器 cls.driver = webdriver.Chrome() # 设置隐式等待 cls.driver.implicitly_wait(5) # 设置窗口最大化 cls.driver.maximize_window() # 2 后置方法 @classmethod def tearDownClass(cls): # 方便观察,设置等待时间 time.sleep(2) # 关闭浏览器 cls.driver.quit() # 3 定义登录的测试方法.test开头 def test_login(self): # 访问商城登录页面:http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login self.driver.get('http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login') # 输入账号密码 self.driver.find_element_by_id('username').send_keys('cs001') self.driver.find_element_by_id('password').send_keys('123456') # 点击登录按钮 self.driver.find_element_by_class_name('login_btn').click()
-
- 代码:
- 登录测试用例优化:
- 代码里的前置,后置方法,可以单独封装到一个父类,其他用例就不用写,直接继承
- BaseTestCase封装:
BaseTestCase.py
- 代码:
-
''' BaseTestCase: 把setUpClass,tearDownClass 进行封装,方便后续测试用例直接使用 ''' import time import warnings import unittest2 from selenium import webdriver # 创建BaseTestCase类,继承unitest2 class BaseTestCase(unittest2.TestCase): # 1 前置方法 @classmethod def setUpClass(cls): warnings.simplefilter('ignore', ResourceWarning) # 打开浏览器 cls.driver = webdriver.Chrome() # 设置隐式等待 cls.driver.implicitly_wait(5) # 设置窗口最大化 cls.driver.maximize_window() # 2 后置方法 @classmethod def tearDownClass(cls): # 方便观察,设置等待时间 time.sleep(2) # 关闭浏览器 cls.driver.quit()
-
- 代码:
- 登录测试用例V2:
LoginTestV2.py
- 代码:
-
'''' 登录测试用例V2版本: 继承BaseTestCase ''' from func.BaseTestCase import BaseTestCase # 创建测试类,继承unittest2.TestCsae class LoginTestV2(BaseTestCase): # 定义登录的测试方法.test开头 def test_login(self): # 访问商城登录页面:http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login self.driver.get('http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login') # 输入账号密码 self.driver.find_element_by_id('username').send_keys('cs001') self.driver.find_element_by_id('password').send_keys('123456') # 点击登录按钮 self.driver.find_element_by_class_name('login_btn').click()
-
- 代码:
- 登录测试用例V1版:
-
- 登录测试用例V3版:
- 在上一个版本运行成功后,我们需要需设置断言,查看执行情况
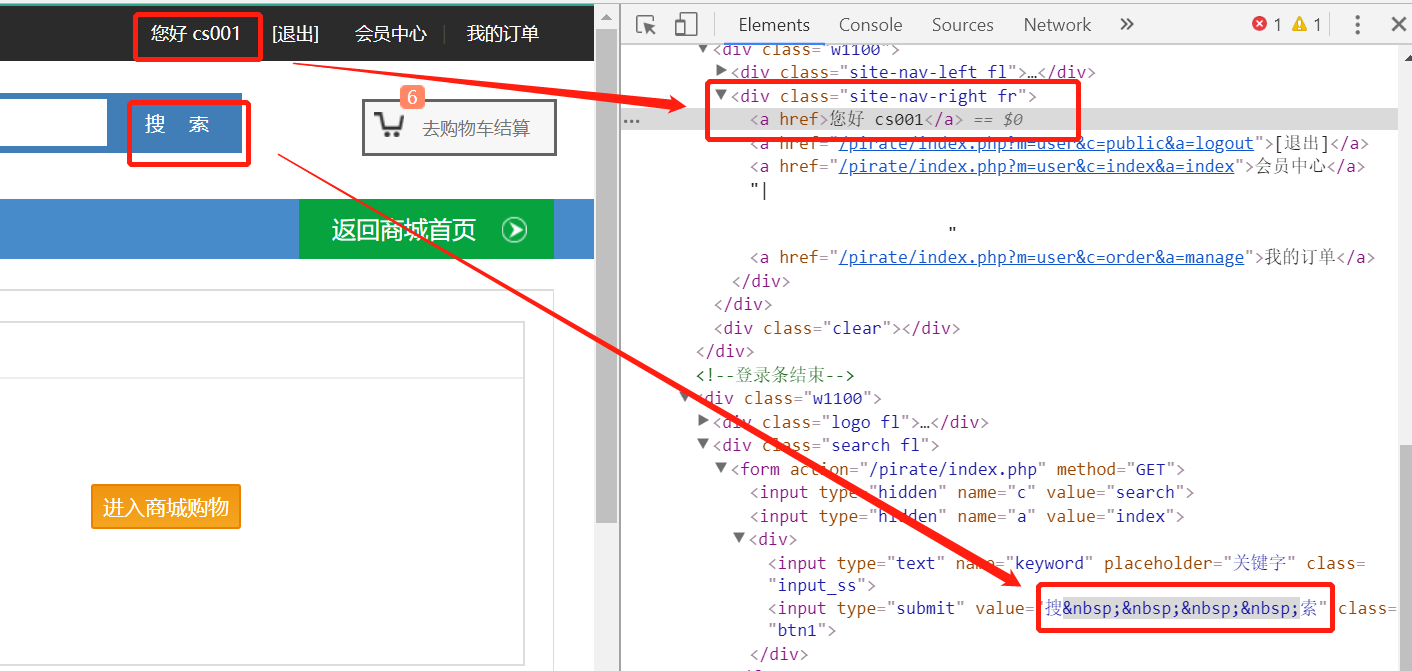
- 获取网页元素的文本信息
- 截图:
- 代码:
-
'''' 登录测试用例V3版本: 添加断言: 页面级别检查 网页元素级别检查 ''' from func.BaseTestCase import BaseTestCase # 创建测试类,继承unittest2.TestCsae class LoginTestV3(BaseTestCase): # 定义登录的测试方法.test开头 def test_login(self): # 访问商城登录页面:http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login self.driver.get('http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login') # 输入账号密码 self.driver.find_element_by_id('username').send_keys('cs001') self.driver.find_element_by_id('password').send_keys('123456') # 点击登录按钮 self.driver.find_element_by_class_name('login_btn').click() # 页面级别检查 # 获取网页标题 title = self.driver.title # 获取网址 current_url = self.driver.current_url # 网页元素检查, # 获取当前用户名 '''当前用户名是a标签,它的文本随账号变化无法link,所以使用css selector组合定位 # 先找a标签的父类,两个class用点号连接.site-nav-right.fr,再用 > 号表明找它的子节点a标签下的:nth-child(1)个元素 ''' user_info = self.driver.find_element_by_css_selector('.site-nav-right.fr > a:nth-child(1)').text # 获取搜索按钮的文本信息 ''' 搜索文本是value属性的值,我们先定位这个元素,在使用get_attribute('value') ''' search = self.driver.find_element_by_css_selector('.btn1').get_attribute('value') # 使用断言判断 ''' assertEqual判断两个值是否相等(预期,实际) 这里写死,先跑通脚本,后续可以优化 ''' self.assertEqual('我的会员中心',title) self.assertEqual('http://127.0.0.1:8080/pirate/index.php?m=user&c=index&a=index', current_url) self.assertEqual('搜索', search)
-
- 截图:
- 获取网页元素的文本信息
- 在上一个版本运行成功后,我们需要需设置断言,查看执行情况
- 登录测试用例,读取csv文件:
- 封装一个读取csv的方法:
csvFileManage.py
- 代码:
-
# 导入csv import csv import os # 定义方法 def read_csv(filename): # 指明文件路径 path = os.path.dirname(__file__) base_path = path.replace('func','test_data/') + filename # 打开文件 with open(base_path) as file: case_data_list = [] # csv读取所以内容 table = csv.reader(file) i = 0 # 循环读取每一行 for row in table: # 去除第一行标题 if i == 0: pass else: case_data_list.append(row) i+=1 return case_data_list
-
- 测试数据:
- 代码:
- 登录测试用例V4版:
- 代码(展示了修改部分):
-
''' 登录测试用例V4版本: 读取csv文件数据,使用for循环执行用例 ''' from func.BaseTestCase import BaseTestCase from func.csvFileManage import read_csv # 创建测试类,继承unittest2.TestCsae class LoginTestV4(BaseTestCase): # 定义登录的测试方法.test开头 def test_login(self): # 导入文件读取方法后,调用它 table = read_csv('login_userinfo.csv') # 循环执行 for row in table: # 访问商城登录页面:http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login self.driver.get('http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login') # 输入账号密码 self.driver.find_element_by_id('username').send_keys(row[0]) self.driver.find_element_by_id('password').send_keys(row[1])
-
- 代码(展示了修改部分):
- 封装一个读取csv的方法:
- 登录测试用例V3版:
-
- 登录测试用例使用数据驱动:
- 在v4版中,防止循环会中断,使用ddt优化代码
- 登录测试用例V5版-代码:
-
''' 登录测试用例V5版本: 使用ddt,进行数据驱动测试 ''' import ddt from func.BaseTestCase import BaseTestCase from func.csvFileManage import read_csv # 创建测试类,继承unittest2.TestCsae @ddt.ddt class LoginTestV5(BaseTestCase): # 导入文件读取方法 table = read_csv('login_userinfo.csv') # 定义登录的测试方法.test开头 @ddt.data(*table) # 传入table,并解包成一条条单独的用例数据 def test_login(self,row): # 访问商城登录页面:http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login self.driver.get('http://127.0.0.1:8080/pirate/index.php?m=user&c=public&a=login') # 输入账号密码 self.driver.find_element_by_id('username').send_keys(row[0]) self.driver.find_element_by_id('password').send_keys(row[1])
-
- 登录测试用例V5版-代码:
- 在v4版中,防止循环会中断,使用ddt优化代码
- 生成测试报告:
- 代码-项目根目录下新建一个run_all_case文件:
-
import unittest2 from lib.HTMLTestRunner import HTMLTestRunner if __name__ == '__main__': # 找到所有测试用例 suite = unittest2.defaultTestLoader.discover('./testCase','*Test*.py') # 生成测试报告 # 指定报告位置 path = 'report/TestRepotr.html' file = open(path,'wb') HTMLTestRunner(stream=file, verbosity=1, title='登录功能测试报告', description='测试环境:Chrome', tester='testKK').run(suite)
-
- 报告截图:
- 代码-项目根目录下新建一个run_all_case文件:
- 登录测试用例使用数据驱动:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号