性能:Receiver层面
创建多个接收器
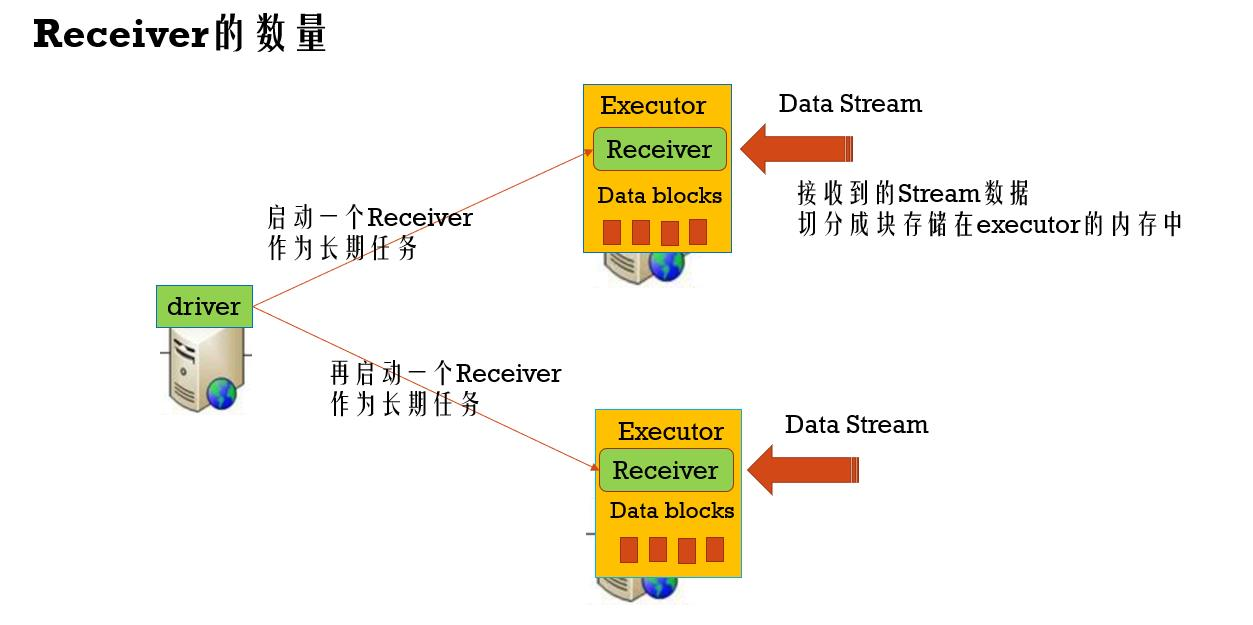
多个端口启动多个receiver在其他Executor,接收多个端口数据,在吞吐量上提高其性能。代码上:
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
* spark-submit --class com.twq.wordcount.JavaNetworkWordCount \
* --master spark://master:7077 \
* --deploy-mode client \
* --driver-memory 512m \
* --executor-memory 512m \
* --total-executor-cores 4 \
* --executor-cores 2 \
* /home/hadoop-twq/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
*
* spark-shell --master spark://master:7077 --total-executor-cores 4 --executor-cores 2
*/
object MultiReceiverNetworkWordCount {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(5))
//创建多个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines1 = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
val lines2 = ssc.socketTextStream("master", 9997, StorageLevel.MEMORY_AND_DISK_SER)
val lines = lines1.union(lines2)
/////val lines = lines1.union(lines2).union(lines3)
lines.repartition(100)
//处理的逻辑,就是简单的进行word count
val words = lines.repartition(100).flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10))
//将结果输出到控制台
wordCounts.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
ssc.stop(false)
}
}
Receiver数据块的数量
数据一条一条接收,以一个块一个块的方式存储在内存中,多少条记录组成一个block块:
batchInterval : 触发批处理的时间间隔
blockInterval : 将接收到的数据生成Block的时间间隔:spark.streaming.blockInterval(默认是200ms)
BlockRDD的分区数 = batchInterval / blockInterval 即一个Block就是RDD的一个分区,就是一个task
比如,batchInterval是2秒,而blockInterval是200ms,那么task数为10
如果task的数量太少,比一个executor的core数还少的话,那么可以减少blockInterval
blockInterval最好不要小于50ms,太小的话导致task数太多,那么launch task的时间久多了
Receiver接受数据的速率
QPS -> queries per second
permits per second 每秒允许接受的数据量
Spark Streaming默认的PPS是没有限制的
可以通过参数spark.streaming.receiver.maxRate来控制,默认是Long.Maxvalue

 浙公网安备 33010602011771号
浙公网安备 33010602011771号