编程模型:数据处理层
Basic相关API
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
spark-submit --class com.dev.streaming.NetworkWordCount \
--master spark://master:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 4 \
--executor-cores 2 \
/home/hadoop-dev/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
spark-shell --master spark://master:7077 --total-executor-cores 4 --executor-cores 2
*/
object BasicAPITest {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// StreamingContext 编程入口
val ssc = new StreamingContext(sc, Seconds(1))
//数据接收器(Receiver)
//创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
//数据处理(Process)
//处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" ")).filter(_.contains("exception"))
val wordPairs = words.map(x => (x, 1))
// reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10) 指定suffer后分区数量和分区算法(默认是HashPartitioner)
val wordCounts = wordPairs.repartition(100).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10))
//结果输出(Output)
//将结果输出到控制台
wordCounts.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
}
}
Join相关API
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by tangweiqun on 2018/1/6.
*/
object JoinAPITest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 5 second batch size
val ssc = new StreamingContext(sc, Seconds(5))
val lines1 = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
val kvs1 = lines1.map { line =>
val arr = line.split(" ")
(arr(0), arr(1))
}
val lines2 = ssc.socketTextStream("master", 9997, StorageLevel.MEMORY_AND_DISK_SER)
val kvs2 = lines2.map { line =>
val arr = line.split(" ")
(arr(0), arr(1))
}
kvs1.join(kvs2).print()
kvs1.fullOuterJoin(kvs2).print()
kvs1.leftOuterJoin(kvs2).print()
kvs1.rightOuterJoin(kvs2).print()
//启动Streaming处理流
ssc.start()
ssc.stop(false)
//等待Streaming程序终止
ssc.awaitTermination()
}
}
TransformAPI
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by tangweiqun on 2018/1/6.
*/
object TransformAPITest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(5))
val lines1 = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
val kvs1 = lines1.map { line =>
val arr = line.split(" ")
(arr(0), arr(1))
}
/// 实时数据
val path = "hdfs://master:9999/user/hadoop-twq/spark-course/streaming/keyvalue.txt"
val keyvalueRDD =
sc.textFile(path).map { line =>
val arr = line.split(" ")
(arr(0), arr(1))
}
/// 静态数据
kvs1.transform { rdd =>
rdd.join(keyvalueRDD)
} print()
//启动Streaming处理流
ssc.start()
ssc.stop(false)
val lines2 = ssc.socketTextStream("master", 9997, StorageLevel.MEMORY_AND_DISK_SER)
val kvs2 = lines2.map { line =>
val arr = line.split(" ")
(arr(0), arr(1))
}
//(将实时数据与静态数据相关联)
kvs1.transformWith(kvs2, (rdd1: RDD[(String, String)], rdd2: RDD[(String, String)]) => rdd1.join(rdd2))
//等待Streaming程序终止
ssc.awaitTermination()
}
}
WindowAPI
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by tangweiqun on 2018/1/6.
*/
object WindowAPITest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(1)) //// 用来控制RDD的分区
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
//每过2秒钟,然后显示前20秒的数据
val windowDStream = lines.window(Seconds(20), Seconds(2))
windowDStream.print()
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
ssc.stop(false)
}
}

batch interval - DStream产生的间隔,由StreamingContext指定 (这里设置为1s),控制RDD分区
window length - 窗口的长度,即一个窗口包含的RDD的个数 (这里设置为20s,必须是batch interval的倍数)
sliding interval - 窗口滑动间隔,执行窗口操作的时间段(这里设置为2s,必须是batch interval的倍数)
ReduceByKeyAndWindowAPI
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by tangweiqun on 2018/1/6.
*/
object ReduceByKeyAndWindowAPITest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(1))
ssc.checkpoint("hdfs://master:9999/user/hadoop-twq/spark-course/streaming/checkpoint")
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
//每5秒中,统计前20秒内每个单词出现的次数
val wordPair = words.map(x => (x, 1))
val wordCounts =
wordPair.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(20), Seconds(5))
wordCounts.print()
//启动Streaming处理流
ssc.start()
ssc.stop(false)
//接受一个ReduceFunc和一个invReduceFunc
//滑动时间比较短,窗口长度很长的场景
// 需要用checkpoint机制
val wordCountsOther =
wordPair.reduceByKeyAndWindow((a: Int, b: Int) => a + b,
(a: Int, b: Int) => a - b, Seconds(60), Seconds(2))
wordCountsOther.checkpoint(Seconds(12)) //窗口滑动间隔的5到10倍
wordCountsOther.print()
ssc.start()
//过滤掉value = 0的值
words.map(x => (x, 1)).reduceByKeyAndWindow((a: Int, b: Int) => a + b,
(a: Int, b: Int) => a - b,
Seconds(30), Seconds(10), 4,
(record: (String, Int)) => record._2 != 0)
//等待Streaming程序终止
ssc.awaitTermination()
}
}

1、分别对rdd2和rdd3进行reduceByKey
2、取在window内的rdd进行union,生成unionRDD
3、对unionRDD再次进行reduceByKey
(不需要 checkpoint机制,不需要依赖)
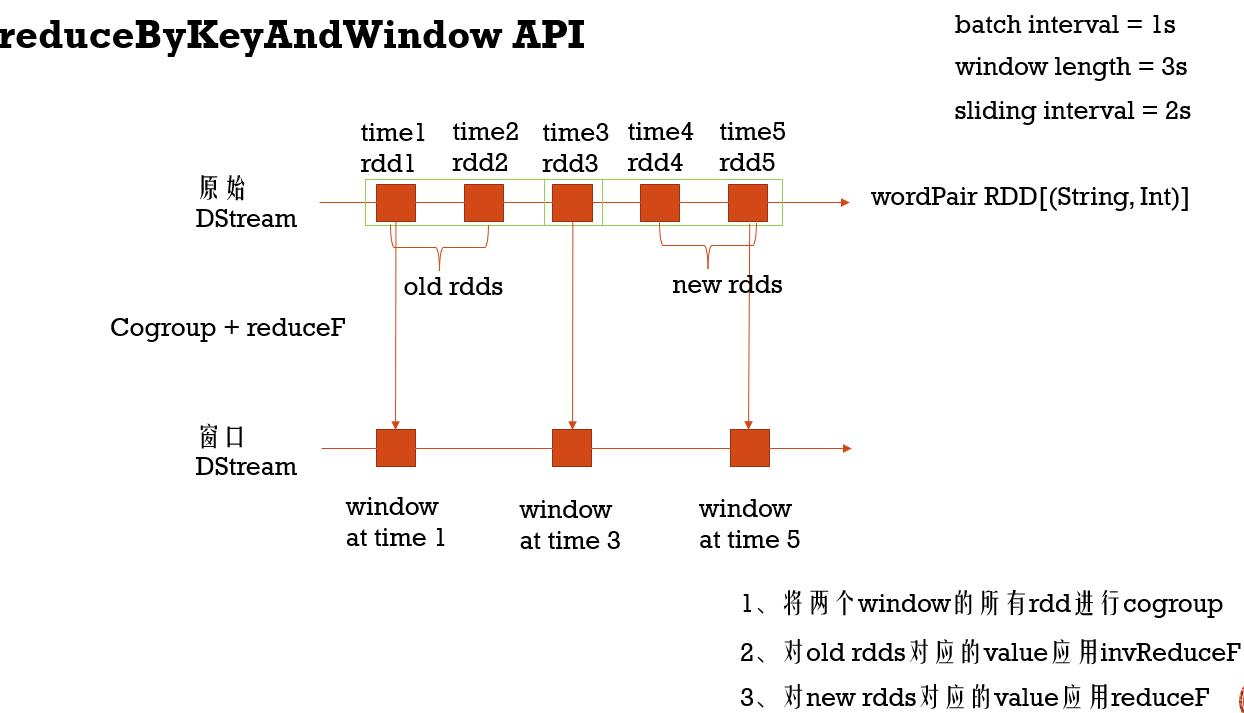
1、将两个window的所有rdd进行cogroup
(需要依赖前面的RDD,因此需要checkpoint机制)
2、对old rdds对应的value应用invReduceF
3、对new rdds对应的value应用reduceF
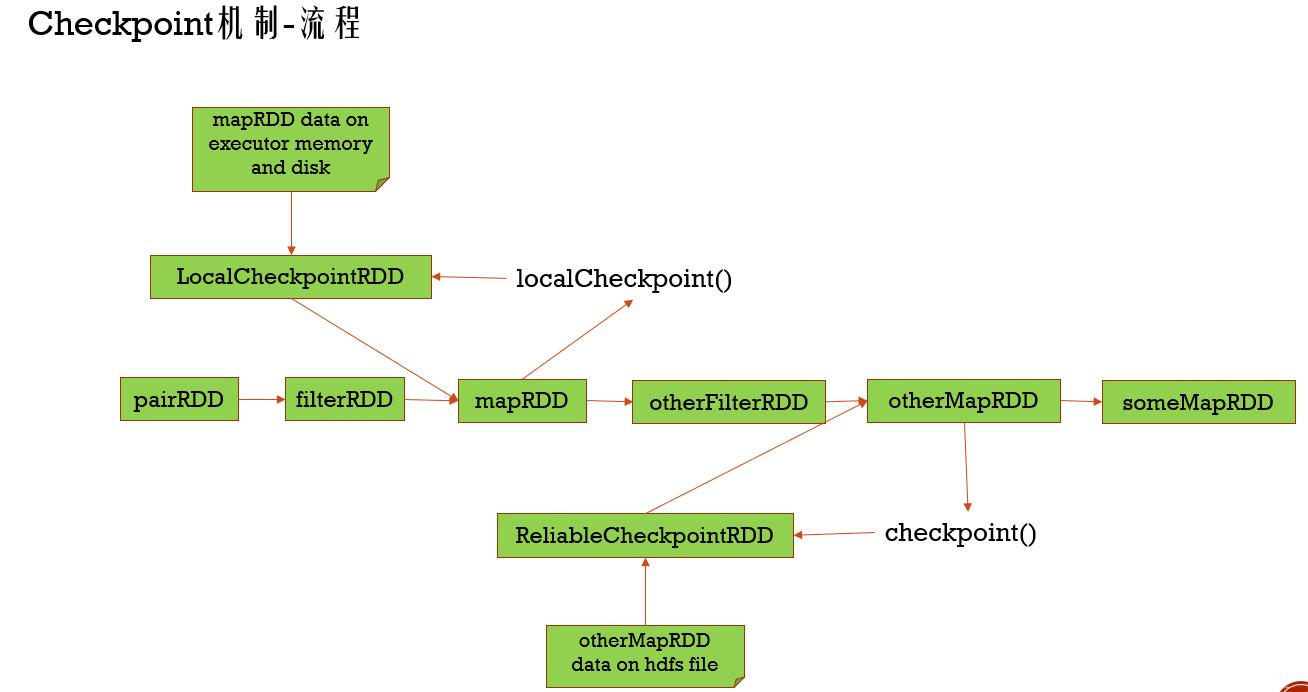
localCheckpoint() 存储在内存和磁盘中,但数据不可靠
checkpoint() 存储在HDFS中去,数据可靠,提高容错性能,需要设置文件目录
UpdateStateByKeyAPI
1、updateStateByKey,这个API根据一个key的之前的状态和新的接收到的数据来计算并且更新新状态。使用这个API需要做两步:第一就是为每一个key定义一个初始状态,这个状态的类型可以实任意类型;第二就是定义一个更新状态的函数,这个函数根据每一个key之前的状态和新接收到的数据计算新的状态。
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object UpdateStateByKeyAPITest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(1))
ssc.checkpoint("hdfs://master:9999/user/hadoop-twq/spark-course/streaming/checkpoint")
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordsDStream = words.map(x => (x, 1))
///values: Seq[Int] 在一定的时间段内收到的 当前key在这个时间段内收集到的value,
/// currentState: Option[Int] 当前key的状态
wordsDStream.updateStateByKey(
(values: Seq[Int], currentState: Option[Int]) => Some(currentState.getOrElse(0) + values.sum)).print()
//启动Streaming处理流
ssc.start()
ssc.stop(false)
//updateStateByKey的另一个API
/// 接收的函数是Iterator 三元组 String Key Seq[Int] 接收到的数据 Option[Int]) Key当前的状态
wordsDStream.updateStateByKey[Int]((iter: Iterator[(String, Seq[Int], Option[Int])]) => {
val list = ListBuffer[(String, Int)]()
while (iter.hasNext) {
val (key, newCounts, currentState) = iter.next
val state = Some(currentState.getOrElse(0) + newCounts.sum)
val value = state.getOrElse(0)
if (key.contains("error")) {
list += ((key, value)) // Add only keys with contains error
}
}
list.toIterator
}, new HashPartitioner(4), true).print()
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
}
}
MapWithStateAPI
mapWithState,这个API的功能和updateStateByKey是一样的,只不过在性能方面做了很大的优化,这个函数对于没有接收到新数据的key是不会计算新状态的,而updateStateByKey是会重新计算任何的key的新状态的,由于这个原因所以导致mapWithState可以处理的key的数量比updateStateByKey多10倍多,性能也比updateStateByKey快很多。 支持促使状态mapWithState还支持timeout API
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.{SparkConf, SparkContext}
object MapWithStateAPITest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf)
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint("hdfs://master:9999/user/hadoop-twq/spark-course/streaming/checkpoint")
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordsDStream = words.map(x => (x, 1))
val initialRDD = sc.parallelize(List(("dummy", 100L), ("source", 32L)))
// currentBatchTime : 表示当前的Batch的时间
// key: 表示需要更新状态的key
// value: 表示当前batch的对应的key的对应的值
// currentState: 对应key的当前的状态
val stateSpec = StateSpec.function((currentBatchTime: Time, key: String, value: Option[Int], currentState: State[Long]) => {
val sum = value.getOrElse(0).toLong + currentState.getOption.getOrElse(0L)
val output = (key, sum)
if (!currentState.isTimingOut()) {
currentState.update(sum)
}
Some(output)
}).initialState(initialRDD).numPartitions(2).timeout(Seconds(30)) //timeout: 当一个key超过这个时间没有接收到数据的时候,这个key以及对应的状态会被移除掉
val result = wordsDStream.mapWithState(stateSpec)
result.print()
// 从一开始显示所有数据,包含初始值
result.stateSnapshots().print()
//启动Streaming处理流
ssc.start()
ssc.stop(false)
//等待Streaming程序终止
ssc.awaitTermination()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号