SQL-Server索引漫谈
一. SQL-Server数据存储基本单位
[文章排版比较乱,所以还请读者体谅一下,后续如果有时间会重新整理一下]这篇文章讨论的主题是索引,但在正式进入索引的内容前,想简单介绍一下关于SQL-Server数据存储的一些简单认识,这将帮助我们更好地理解索引的结构。在SQL-Server中,数据存储的基本单位是页,一页的大小是8KB(共8192字节)。
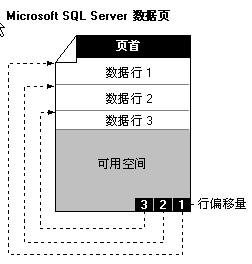
1. 页首
页首固定占用每个数据页的96字节,保存了页面系统信息。下表列出了部分具体信息:
pageID: 数据库中该页的文件编号和页编号
nextPage:如果该页位于一个页链中,则该字段表示下一页的文件编号和页编号
pervPage:如果该页位于一个页链中,则该字段表示上一页的文件编号和页编号
Metadata:ObjectId:该页所在对象的ID
indexId:该页的索引ID(0为数据页)
2. 行内数据的数据行
数据行是真实数据的存储区域。每一行的大小是不固定的,以Slot为单位,0开始编号,Slot0,Slot1依次类推。
3. 行偏移数组
用于记录该数据页中每个Slot的相对位置,便于快速定位Slot的位置。例如:行偏移数组槽0可以指向偏移0X60(96字节)的Slot0。行偏移数组的每个记录占两个字节。行偏移数组表示的是数据页上面的逻辑顺序。例如Slot0可以指向0X80,而Slot1可以指向0X60,实际存储的物理位置不一定按照(聚集索引)排序的。
二. 什么是索引
数据库索引是对表的一列或多列的值进行排序的一种结构,索引与表数据的关系类似于目录与书籍内容的关系。在SQL-Server中存在两种比较重要的索引,分别为聚集索引与非聚集索引,它们是以B+树组织保存的。
建立索引也要付出额外代价的: 索引需要占据额外的内存空间 (当创建一张新表table_name后,并插入数据,使用sp_spaceused(table_name)就可以查看当前索引使用了多少内存,但必须注意sp_spaceused是每个数据库都有的一个系统存储过程,在使用的时候必须指明要查询的数据库) ; 插入和修改数据需要涉及索引的改动,将花费更多的时间。
三. 为什么要使用索引
众所周知,数据查询是数据库一项使用非常频繁的操作,查询的快慢已成为了衡量系统好坏的一个重要标准,而合理地使用索引可以提高数据检索效率,改善数据库性能,加快数据访问速度。
四. 堆结构
1. 什么是堆结构
堆的本义是杂乱无章,无序的意思。对于未建立聚集索引的表,数据是没有遵循特定的某种规则排序的,表中的所有数据页就形成了堆结构。
2. 堆结构实例
--接下来的数据库语句操作都是一些简单的命令
--数据库为Test USE Test GO --创建一张table CREATE TABLE t1 ( t1_id INT NOT NULL ) GO --查看t1的使用情况 sp_spaceused t1

USE Test GO --sys.indexes是系统视图,当创建一张新表的时候,就会在sys.indexes中增加一条记录 --可以在http://msdn.microsoft.com/zhcn/library/ms173760(v=sql.100).aspx 中找到相关信息 SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID('t1') GO --sys.sysindexes同样是系统视图 --可以在http://technet.microsoft.com/zh-cn/library/ms190283(v=sql.100).aspx 中找到相关信息 SELECT * FROM sys.sysindexes WHERE id = OBJECT_ID('t1') GO

sys.indexes中的记录type_desc明确指出了索引的类型是堆(HEAP)。

sys.sysindexes中的记录与数据页组织有莫大的关系,后面会继续讨论。indid=0表示这是堆。堆只需考虑FirstIAM的变化情况,可以看到这里FirstIAM的指针地址为0。
USE Test --接下来,插入一条记录 INSERT INTO t1(t1_id) VALUES (1) GO --重新查看内存使用情况 sp_spaceused t1 GO

这里可以明显地知道,数据插入的基本单位是数据页,即使插入的是一行数据,也占据一张数据页。后续插入数据的时候,如果当前的数据页还可以继续容纳的话,就插入到当前数据页中,不然就插入到一张新数据页中。但这里还是有一个疑问,为什么会有index_size呢?这里不是只插入了一条记录而已吗?这就要从堆的内部结构说起了。
USE Test GO --我们来继续查看sys.sysindexes,看下这条记录发生了什么变化 SELECT * FROM sys.sysindexes WHERE id = OBJECT_ID('t1') GO

这里的FirstIAM的指针地址发生了变化。
--查看页的基本信息
--前提条件:表中必须插入了数据
--所需参数:(数据库名,表名,-1表示显示全部IAM页,数据页, 索引页) DBCC IND (Test2,t1,-1)
![]()
PageType=1表示这是数据页,PageType=10表示这是IAM页。
什么是IAM页? IAM=Index Allocation Map,索引分配映射。IAM页的结构与数据页的结构基本相同。堆结构中,IAM是SQL-Server查找属于该表单所有范围的唯一方法。
那么FirstIAM的地址指针0X4F0000000100又是如何跟IAM页关联的呢? 首先必须拆分这个地址指针,从右往左读,两数字为一组,得到0X 00 01 00 00 00 4F。前两组表示文件编号(PageFID),即0X0001(1),后四组表示页编号(PagePID),即0X0000004F(79)。这样FirstIAM就与IAM页关联起来了。
USE Test GO DECLARE @i INT; SET @i = 10000; --插入10000条记录 WHILE @i>0 BEGIN INSERT INTO t1 (t1_id) VALUES (@i) SET @i = @i - 1 END GO --再次查看页的基本信息 DBCC IND(Test,t1,-1) GO
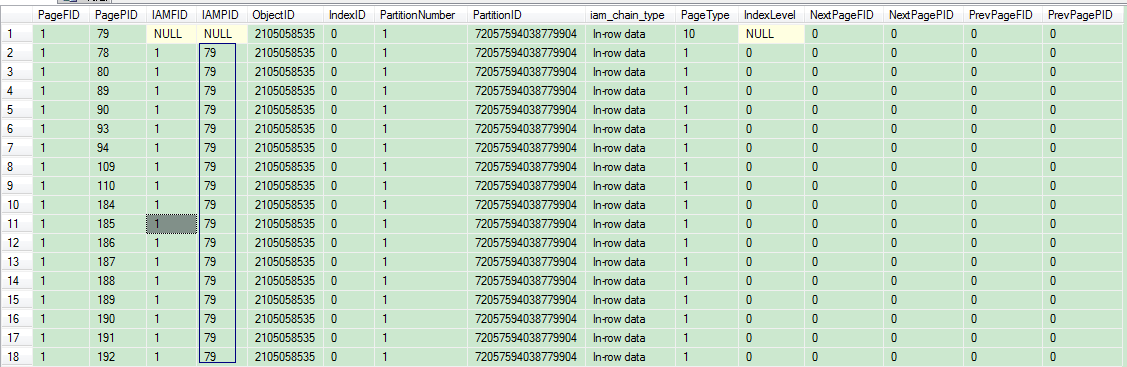
插入了10000条记录后,可以看到数据页增加了17页,而IAM页还是只有1页,这是因为IAM页最多可定位4GB的数据量。在堆结构中,PrevPagePID和NextPagePID都是0,数据页之间不存在链表关系,数据页的关系仅靠IAMPID维持着。
堆结构的查询示意图如下:
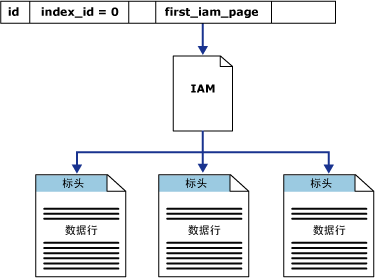
3. 堆结构全表扫描
SQL-Server在接到查询请求后,便会首先分析sys.sysindexes的索引标识符indid,堆结构的indid为0,这时就会查找另一个字段FirstIAM,找到IAM页链,便开始所有数据页的依次遍历查找过程。堆结构的表就像一个存放着乱七八糟的书而且没有排序好的书库,当要查询某一类型的书或某个范围内的书的时候,就只能从第一个书架开始找起,每一本书都要看,如果匹配就拿出来,直到最后一个书架都找完了。当书库的书成千上万的时候,这样的查找方式确实效率低下。
五. 索引的分类
1.聚集索引(CLUSTERED INDEX)
1) 什么是聚集索引
聚集索引定义了数据在表中存储的物理顺序。如果不止在一个列上定义了聚集索引,数据将按照在这些列上所指定的顺序而存储,先按第一列指定的顺序,再按第二列指定的顺序,以此类推。由于数据只能有一种实际存储方式,所以对于一张表来说聚集索引只能有一个。以经典的新华字典例子说起,新华字典中的字是按照拼音字母的先后顺序排序存储的,当我们要查‘安’字的时候,我们首先会在字典的拼音索引中找到‘an’读音所在的页码,并开始按序查找,如果找不到就表示新华字典中没有‘安’字。这就是聚集索引的工作原理。
2) 聚集索引结构
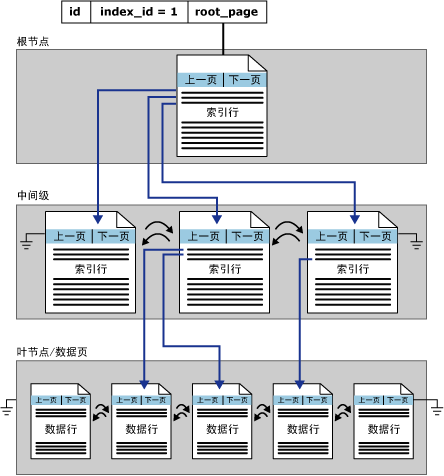
接下来将对这张结构图进行全面的分析。
SQL-Server在接到查询请求后,便会首先分析sys.sysindexes的索引标识符indid,可以看到聚集索引结构的indid=1,这时就会查找root的字段,而root指向的是聚集索引根级索引页。这里跟堆结构是有区别的,堆结构使用的字段是FirstIAM。
那什么是索引页呢?
索引页与文章开头讨论的数据页的结构几乎完全相同,也是8KB固定大小,使用96字节的页首,结尾处使用偏移数组。只是索引页存储的是索引记录,而数据页存储的是数据记录。


USE Test GO --创建一张表 CREATE TABLE t2 ( t2_id INT IDENTITY(1,1) NOT NULL, t2_c1 VARCHAR(10) NOT NULL ) --创建一个在列t2_id上的聚集索引 CREATE CLUSTERED INDEX ix_t2_id ON t2 (t2_id ASC) --插入4000行数据 DECLARE @i INT SET @i = 4000 WHILE @i>0 BEGIN INSERT INTO t2 (t2_c1) VALUES ('a') SET @i = @i - 1 END --查看sys.sysyindexes的使用情况 SELECT * FROM sys.sysindexes WHERE id = OBJECT_ID('t2') --使用DBCC IND查看页的使用情况 DBCC IND(Test,t2,-1)

indid=1表示这是一个聚集索引,与堆结构的FirstIAM转换规则一样,0X730000000100可以转化为(1:115),则指向的索引页的文件编号是1,页编号是115。
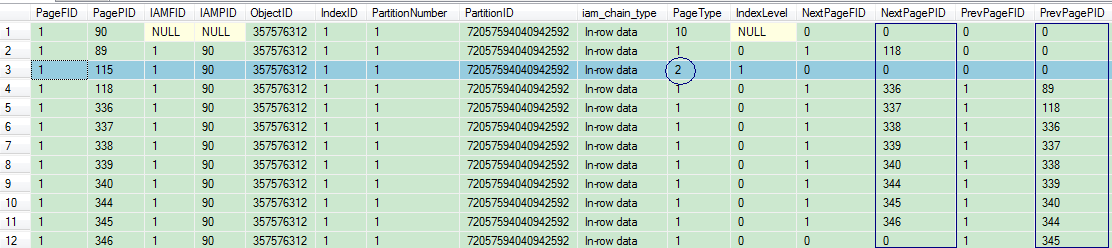
PagePID=115的行的PageType=2,表示这是一个索引页。IndexLevel表示索引的等级,数值越大表示离根节点越近。这里因为只插入了4000条数据,数据量较少,所以只需一个索引页。同时观察一下PageType=1的数据页,NextPagePID和PrePagePID将数据页串联成一个数据链表,和堆结构的数据页是有明显的区别的。这是B+树的一个特点所在,在此对B+树的结构就不多加讨论了。
可以看到建立了聚集索引的表也有一个IAM页,个人推测这个IAM页的作用是当删除聚集索引后,表变成了堆结构,这时就按堆结构的工作方式查询数据。
USE Test GO --这里可以使用PAGE命令查看页的具体情况 --参数(数据库名,FileID,PageID,3表示查看索引页信息) DBCC PAGE(Test,1,115,3)

可以看到,索引页共有10行,分别指向了10个页面,t2_id是索引键,ChlidPageId是指向数据页的页编号。
t2表的B+树结构如图:
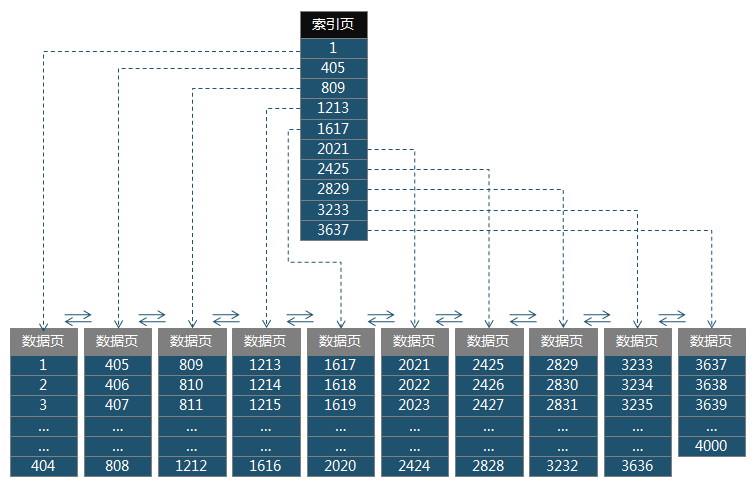
这里因为插入的每一行数据都占据相同的大小,所以数据页呈规律递增,但实际应用情况下,插入的数据基本是不同的,就不会像这里一样出现规律性的递增了。当要查询t2_id=800的记录的时候,就在索引页中查找,由于405<800<809,所以就在索引键405指向的数据页中顺序查找,如果找得到就返回t2_id=800的记录,这样就避免了堆结构的全表扫描,提高了查询的效率。
2.非聚集索引(NONCLUSTERED INDEX)
1) 什么是非聚集索引
非聚集索引与表中的逻辑组织顺序无关,是以分离的结构存在的,所以在一个表中可以同时存在多个非聚集索引。同样以新华字典为例,当我们要查询一个不知道读音的字,比如查询‘张’字,这时可以通过查询偏旁部首找到它,并查到‘张’字所在的页面。具有相同偏旁部首的字是按照笔画的多少排序的,运用了键值对的方法,每个字的右边就跟上具体的页码。非聚集索引也是使用索引键和指向表数据的指针。
2) 非聚集索引结构
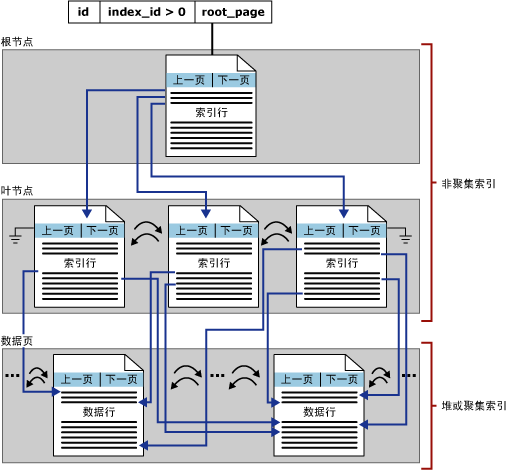
与聚集索引结构对比,非聚集索引结构同样是以B+树存储的。不同的是,indid字段>1,表示这是一个非聚集索引,非聚集索引中只有索引页,叶节点也是索引页,而聚集索引的叶节点是数据页;非聚集索引的每个索引行都指向具体的数据行。
3) 堆上的非聚集索引
USE Test GO --创建堆表 CREATE TABLE t3 ( t3_id INT IDENTITY(1,1) NOT NULL, t3_c1 VARCHAR(10) NOT NULL, ) --建立非聚集索引 CREATE NONCLUSTERED INDEX ix_t3_c1_nonclus ON t3 (t3_c1) --插入1000行数据 DECLARE @i INT DECLARE @num INT DECLARE @str VARCHAR(10) SET @i = 1000 WHILE @i > 0 BEGIN --设置插入字符个数 SET @num = CAST(RAND()*1000 AS INT)% 10 + 1 --字符串置空 SET @str = '' --插入随机字符 WHILE @num > 0 BEGIN SET @str += CHAR(CAST(RAND()*1000 AS INT)% 26 + 97) SET @num -= 1 END --插入t3表中 INSERT INTO t3 (t3_c1) VALUES (@str) SET @i -= 1 END --查看页的使用情况 DBCC IND(Test,t3,-1)

PageType=2表示这是非聚集索引。IndexLevel=1表示这是根节点页。
--查看根节点页的信息 DBCC PAGE(Test,1,356,3)

这里可以看到ChildPageId指向的是叶节点索引页,t3_c1是非聚集索引键,HEAP RID表示的是指针,指向真实的堆数据行。
--查看叶节点页的信息 DBCC PAGE(Test,1,343,3)
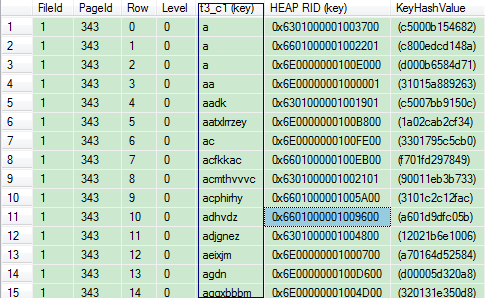
这里可以看到非聚集索引页是按照t3_c1的先后顺序排序的。HEAP RID的指针是有规律可循的,例如0X6301000001003700,前12位表示的是数据页编号和文件编号,后4位表示的是行编号,按照从右往左的顺序,以两位为一组,可以得到(1:355:55),表示文件编号为1,数据页编号为355,数据行编号为55。
堆上的聚集索引示意图:
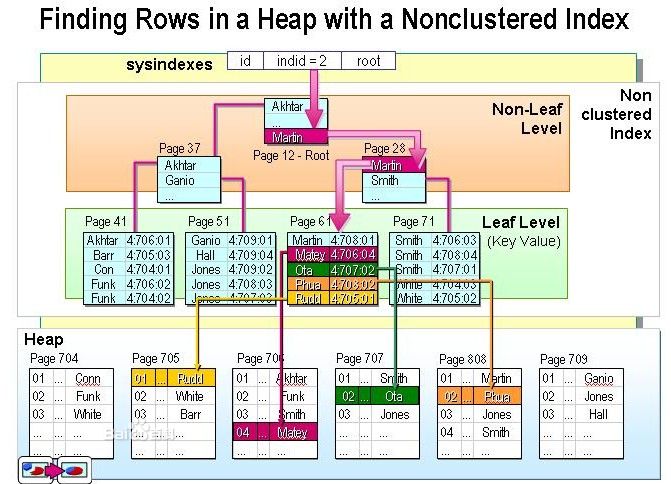
4)聚集表中的非聚集索引
USE Test GO --创建表t4 表结构与t3类似 CREATE TABLE t4 ( t4_id INT IDENTITY(1,1) NOT NULL, t4_c1 VARCHAR(10) NOT NULL ) --建立聚集索引 CREATE CLUSTERED INDEX ix_t4_clus ON t4 (t4_id) GO --建立非聚集索引 CREATE NONCLUSTERED INDEX ix_t4_c1_nonclus ON t4 (t4_c1) GO USE Test GO --插入1000行数据 DECLARE @i INT DECLARE @num INT DECLARE @str VARCHAR(10) SET @i = 1000 WHILE @i > 0 BEGIN --设置插入字符个数 SET @num = CAST(RAND()*1000 AS INT)% 10 + 1 --字符串置空 SET @str = '' --插入随机字符 WHILE @num > 0 BEGIN SET @str += CHAR(CAST(RAND()*1000 AS INT)% 26 + 97) SET @num -= 1 END --插入t3表中 INSERT INTO t4 (t4_c1) VALUES (@str) SET @i -= 1 END --查看页的使用情况 DBCC IND(Test,t4,-1)

我们可以看到IndexID=1,PageType=2,IndexLevel=1的索引页就是根聚集索引页,而IndexID=2,PageType=2,IndexLevel的索引页就是根非聚集索引页。
--查看非聚集索引根节点页的信息 DBCC PAGE(Test,1,367,3)

非聚集索引有聚集索引的键值,这就将非聚集索引与聚集索引联系起来了。这里的UNIQUIFIER(key),是做为一个唯一标识,因为聚集索引可以设定为不唯一,这个标识就能区分出相同的聚集索引键。
--查看非聚集索引叶节点页的信息 DBCC PAGE(Test,1,363,3)

当需要定位到指定的t4_id的时候,数据库就是用聚集索引查找的方法搜索聚集索引B+树,找到最终的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号