python二十一课---python第3方模块下载极其重要!!,requests与openpyxl等使用
补充知识1
脚本语言又被称为扩建的语言,或者动态语言,是一种编程语言,用来控制软件应用程序,脚本通常以文本(如ASCII)保存,只在被调用时进行解释或编译。
脚本语言是为了缩短传统的编写-编译-链接-运行(edit-compile-link-run)过程而创建的计算机编程语言。
一个脚本通常是解释执行而非编译。脚本语言通常都有简单、易学、易用的特性,目的就是希望能让程序员快速完成程序的编写工作。
补充知识2
pip是Python的包管理器。这意味着它是一个工具,允许你安装和管理不属于标准库的其他库和依赖。
软件包管理极其重要,所以自 Python3 的 3.4 版本以及 Python2 的 2.7.9 版本开始,pip一直被直接包括在 Python 的安装包内,同样还被用于 Python 的其它项目中,这使得 pip 成为了每一个 Pythonista(Python用户)必备的工具。
Python被认为是一种"内置电池"式的语言。这表示 Python 标准库包含大量的软件包和模块,这些模块有助于开发人员开发脚本和应用。
与此同时,Python 拥有一个活跃的社区,它提供了一个更大的软件包集合,以供你开发所需。这些软件包发布在 Python Package Index,也被称为 PyPI(发音 Pie Pea Eye)。PyPI 托管了大量包,包括开发框架,工具和库。
昨日内容回顾
-
正则表达式前戏
正则表达式是一门独立的语言 主要的功能在于使用特殊符号的组合或者直接填写需要查找的具体内容去字符串中筛选出符合条件的数据 -
正则表达式之字符组
中括号括起来 里面填写一些内容 [0123456789] [0-9] [a-z] [A-Z] [0-9A-Za-z] """ 字符组默认情况下筛选数据是挨个挨个匹配 字符组内所有的内容默认都是或关系 """ -
正则表达式之特殊符号
. 匹配除换行符意外的任意字符 \w 匹配数字、字母、下划线 \W 匹配除数字、字母、下划线 \d 匹配数字 ^ 匹配字符串的开头 $ 匹配字符串的结尾 () 正则表达式分组 [^] 中括号内取反操作查找其他 a|b 匹配a或者b """特殊符号默认情况下筛选数据也是挨个挨个匹配""" -
正则表达式之量词
* 零次或多次 + 一次或多次 ? 零次或一次 {n} n次 {n,} n次或多次 {n,m} n到m次 """量词默认情况下都是贪婪匹配>>>:尽可能多的匹""" -
正则表达式之课堂练习
趁热打铁熟悉基本使用 -
正则表达式之贪婪与非贪婪
量词后面如果跟了问号则会变为非贪婪匹配 .* .*? """ 使用贪婪匹配或者非贪婪匹配 建议在前后加上明确的结束标志 """ -
正则表达式之转义符
在正则表达式中也存在斜杠与字母的组合会产生特殊含义 如果想避免该现象需要再加一个斜杠取消前面斜杠的含义 \\n \n \\\\n \\n 在python中转义符可以使用字母r -
正则表达式之实战建议
常见的正则直接百度搜索 不要自己写浪费时间 -
re模块常见用法
import re re.findall(正则表达式,待匹配的内容) re.finditer(正则表达式,待匹配的内容) re.search(正则表达式,待匹配的内容) re.match(正则表达式,待匹配的内容) obj = re.compile(正则表达式) re.split() # 切割 re.sub() # 替换 re.subn() # 替换 -
re模块补充说明
1.分组优先展示 findall() # 默认分组优先 findall((?:\d)) # 取消分组优先 2.分组起别名 (?P<user_id>\d) res = re.search() res.group(0) res.group('user_id')
今日内容概要
- 作业讲解
- 第三方模块的下载与使用
- 网络爬虫模块之requests模块
- 网络爬虫实战之爬取链家二手房数据
- 自动化办公领域之openpyxl模块
- 第三方模块的扩展(模块叠模块)
- hashlib加密模块
今日内容详细
作业讲解
"""
网络爬虫没有我们现在接触的那么简单
有时候页面数据无法直接拷贝获取
有时候页面还存在防爬机制 弄得不好ip会被短暂拉黑
"""
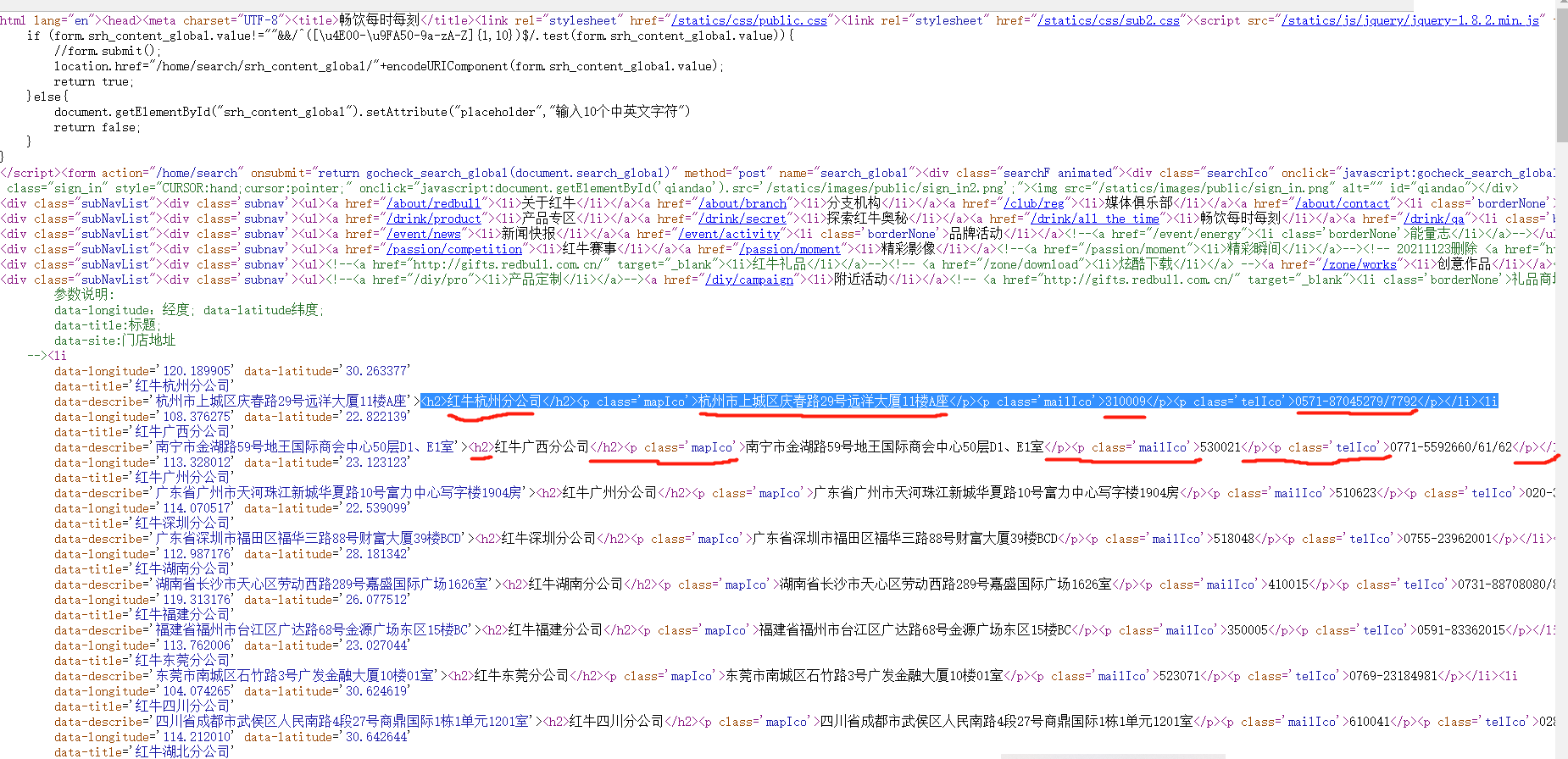
1.右键网页内容,查看网页源码
2.直接拷贝页面数据到本地文件
3.读取文件内容当做字符串处理
4.编写正则筛选内容
5.实际上就用到正则的非贪婪匹配拿到想匹配的数据,以及用到python re 模块 re.findall()方法里面有一个分组优先展示的规则,把打出来
re.findall("<h2>(.*?)</h2><p class='mapIco'>(.*?)</p><p class='mailIco'>(.*?)</p><p class='telIco'>(.*?)</p>",待匹配的数据date)
因为我们想要的数据都在这些固定字符的中间,那么正好就以这些固定字符为首尾限制,利用.*?非贪婪匹配,就能匹配到想要的数据了,再加上利用分组优先展示的原理,虽然匹配上了,但又正好被findall去掉了首尾的固定字符!!!
import re
# 1.文件操作读取文本内容
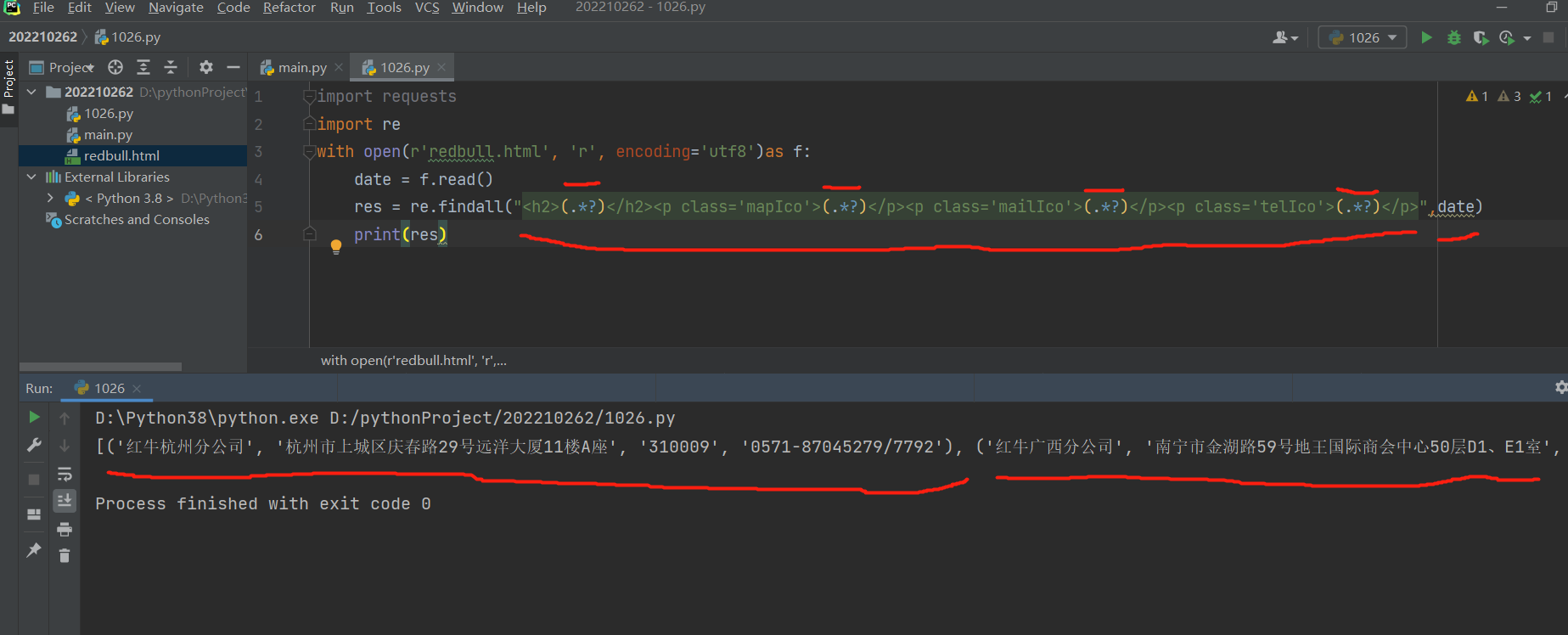
with open(r'redbull.html', 'r', encoding='utf8') as f:
# 2.直接读取全部内容 无需优化
data = f.read()
# 3.研究各部分数据的特征 编写相应的正则表达式
"""
思路1:
一次性获取每个公司全部的数据
分部分挨个获取最后统一整合
"""
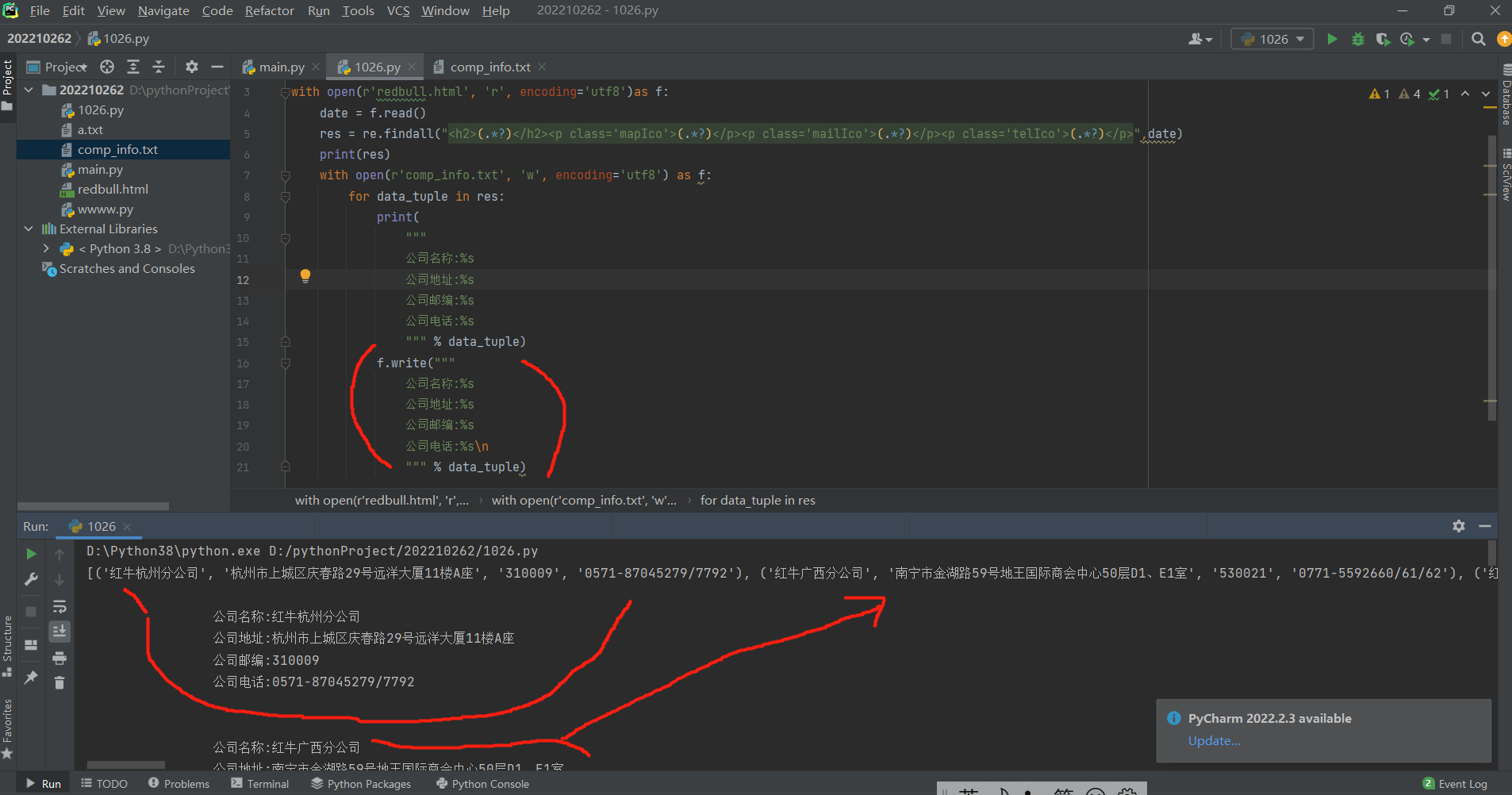
res = re.findall("<h2>(.*?)</h2><p class='mapIco'>(.*?)</p><p class='mailIco'>(.*?)</p><p class='telIco'>(.*?)</p>",data)
print(res) # [(),(),(),()]
也可以分开拿 公司名称、地址、邮编、电话,用正则分开来匹配获取
comp_title_list = re.findall('<h2>(.*?)</h2>', data)
print(comp_title_list)
comp_address_list = re.findall("<p class='mapIco'>(.*?)</p>", data)
print(comp_address_list)
comp_email_list = re.findall("<p class='mailIco'>(.*?)</p>", data)
print(comp_email_list)
comp_phone_list = re.findall("<p class='telIco'>(.*?)</p>", data)
print(comp_phone_list)
res = zip(comp_title_list, comp_address_list, comp_email_list, comp_phone_list)
print(list(res)) # [(),(),(),(),()]
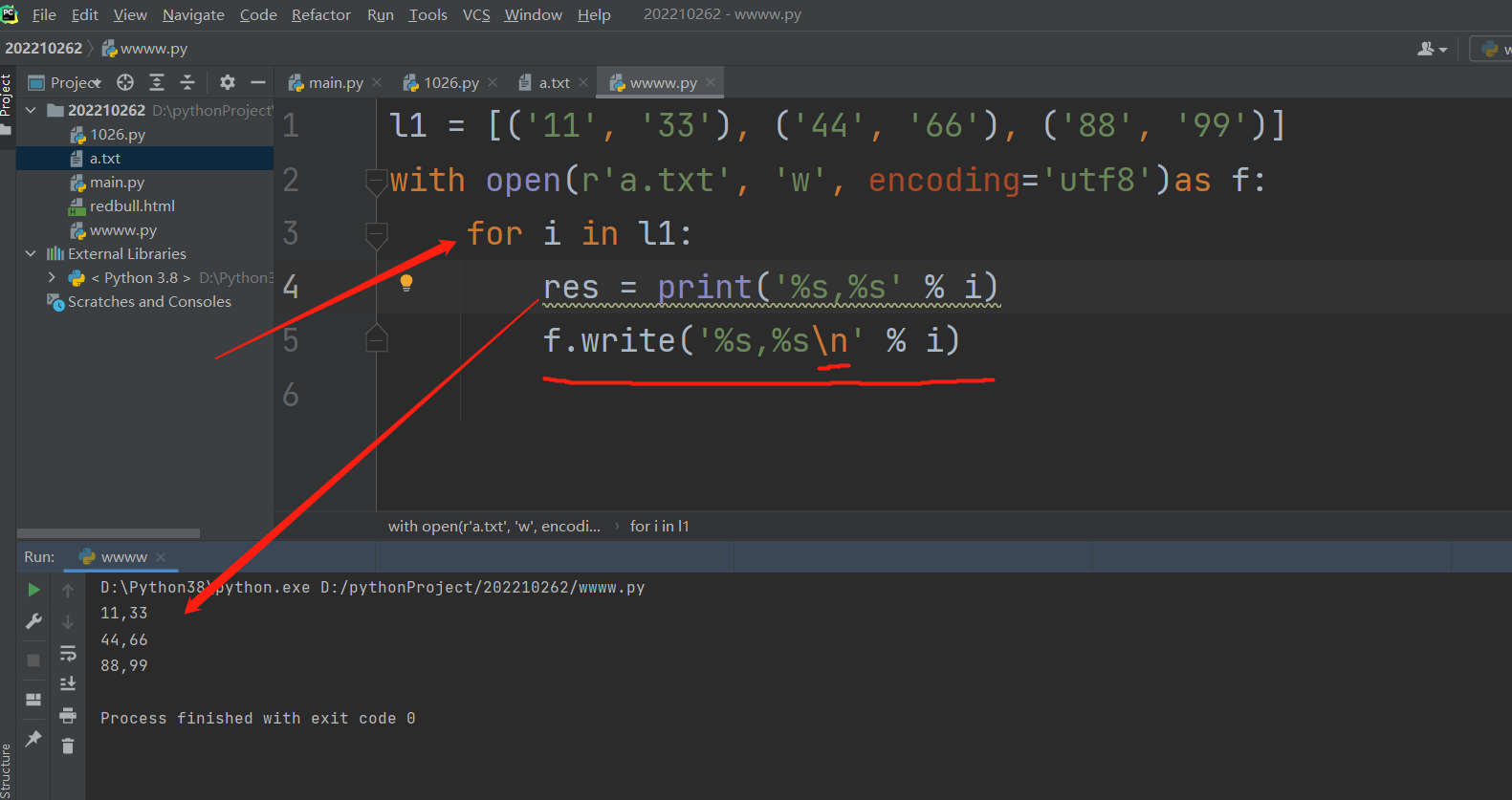
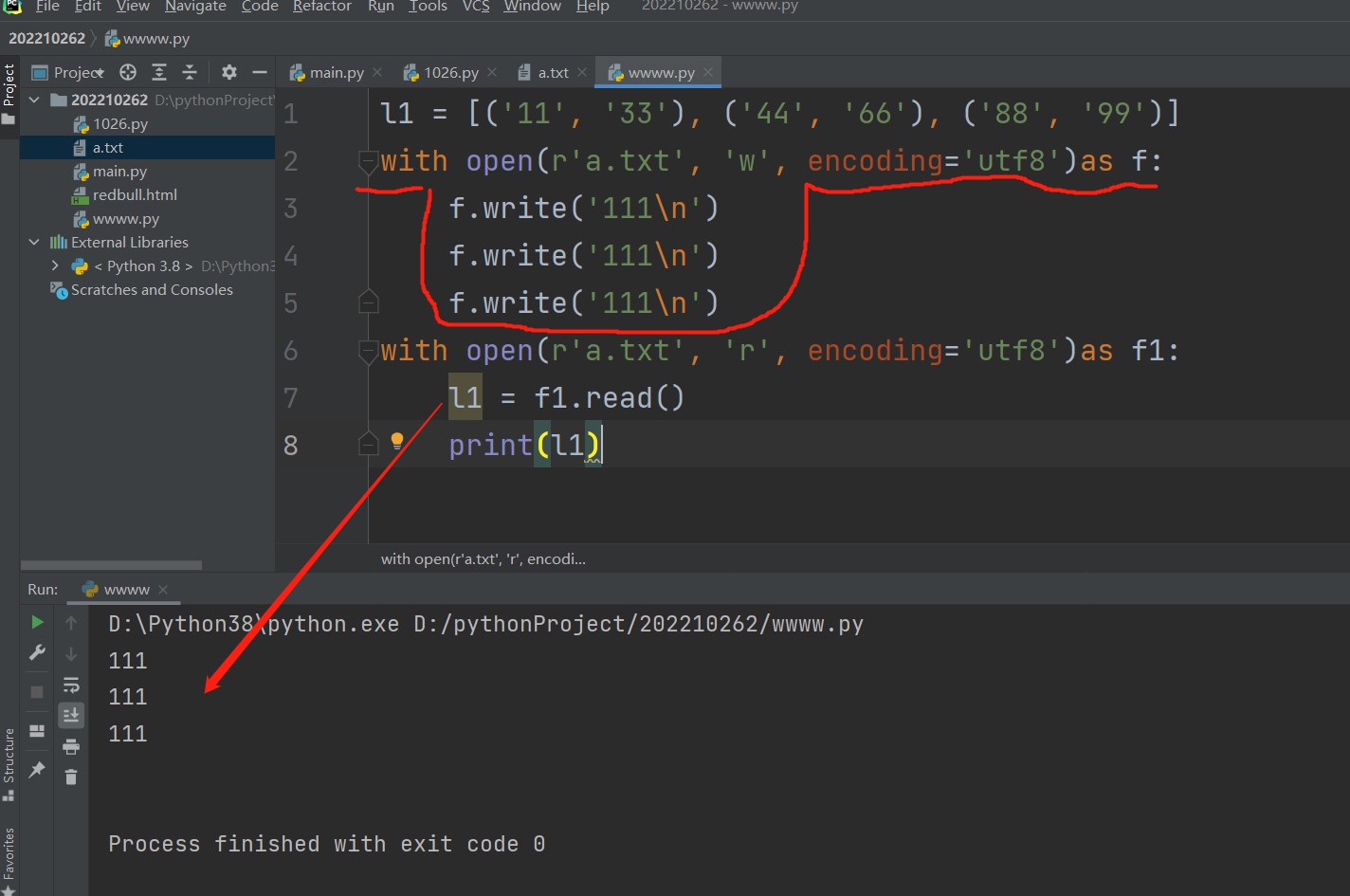
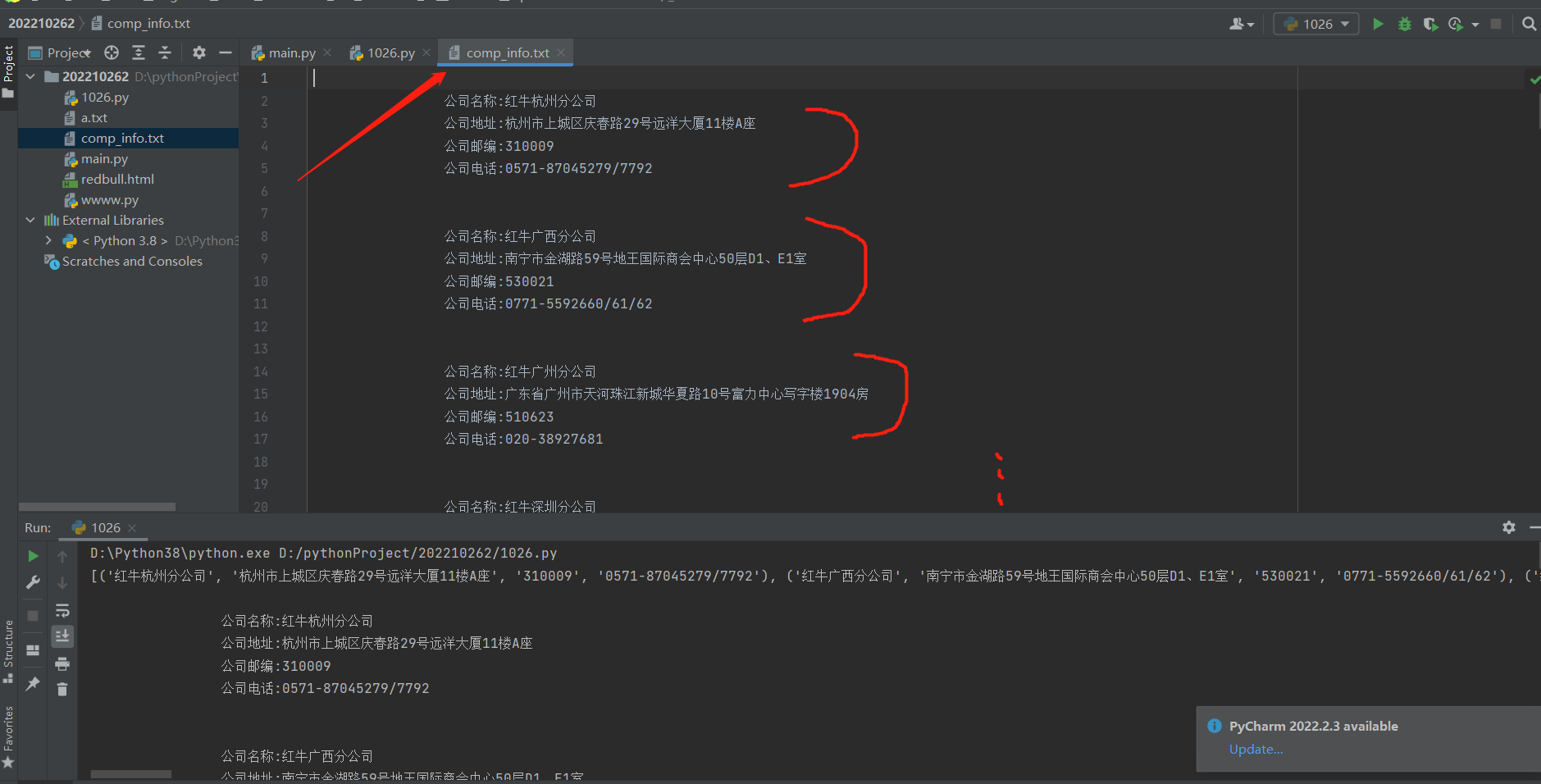
最后把变量名res代表的findall获取的[(),(),(),()],通过for循环及格式化输出的方式写进comp_info.txt 文件里面去!!
with open(r'comp_info.txt', 'w', encoding='utf8') as f:
for data_tuple in res:
print(
"""
公司名称:%s
公司地址:%s
公司邮编:%s
公司电话:%s
""" % data_tuple)
f.write( """
公司名称:%s
公司地址:%s
公司邮编:%s
公司电话:%s\n
""" % data_tuple)
.
.
往文件里面写字符串是可以'w'模式打开后,先for循环,然后将for循环出的结果,一个一个的都写进去的,记得加换行符就行,因为这个时候实际上就'w'打开一次,所以每次往里面写的数据并不会被覆盖!!
.
.
.
第三方模块的下载与使用
第三方模块:别人写的模块 一般情况下功能都特别强大
我们如果想使用第三方模块 第一次必须先下载后面才可以反复使用(等同于内置模块)
下载第三方模块的方式
1.pip工具
注意:!!!!
每个解释器都有pip工具 如果我们的电脑上有多个版本的解释器那么我们在使用pip的时候一定要注意到底用的是哪一个 否则极其任意出现使用的是A版本解释器然后用B版本的
第一种 在cmd命令行执行pip下载模块
pip包下载工具---下载模块
为了避免pip冲突 我们在使用的时候可以添加对应的版本号
python27 pip2.7
python36 pip3.6
python38 pip3.8
注意在这个地方如果你要用python38的解释器,那么你在pip下载第三方模块的时候,就要在pip后面加数字比如 pip3.8 install 模块名
cmd命令下 pip下载第三方模块的句式!!!
pip install 模块名
下载第三方模块临时切换仓库!!!
pip install 模块名 -i 仓库地址
下载第三方模块指定版本(不指定默认是最新版)
pip install 模块名==版本号 -i 仓库地址
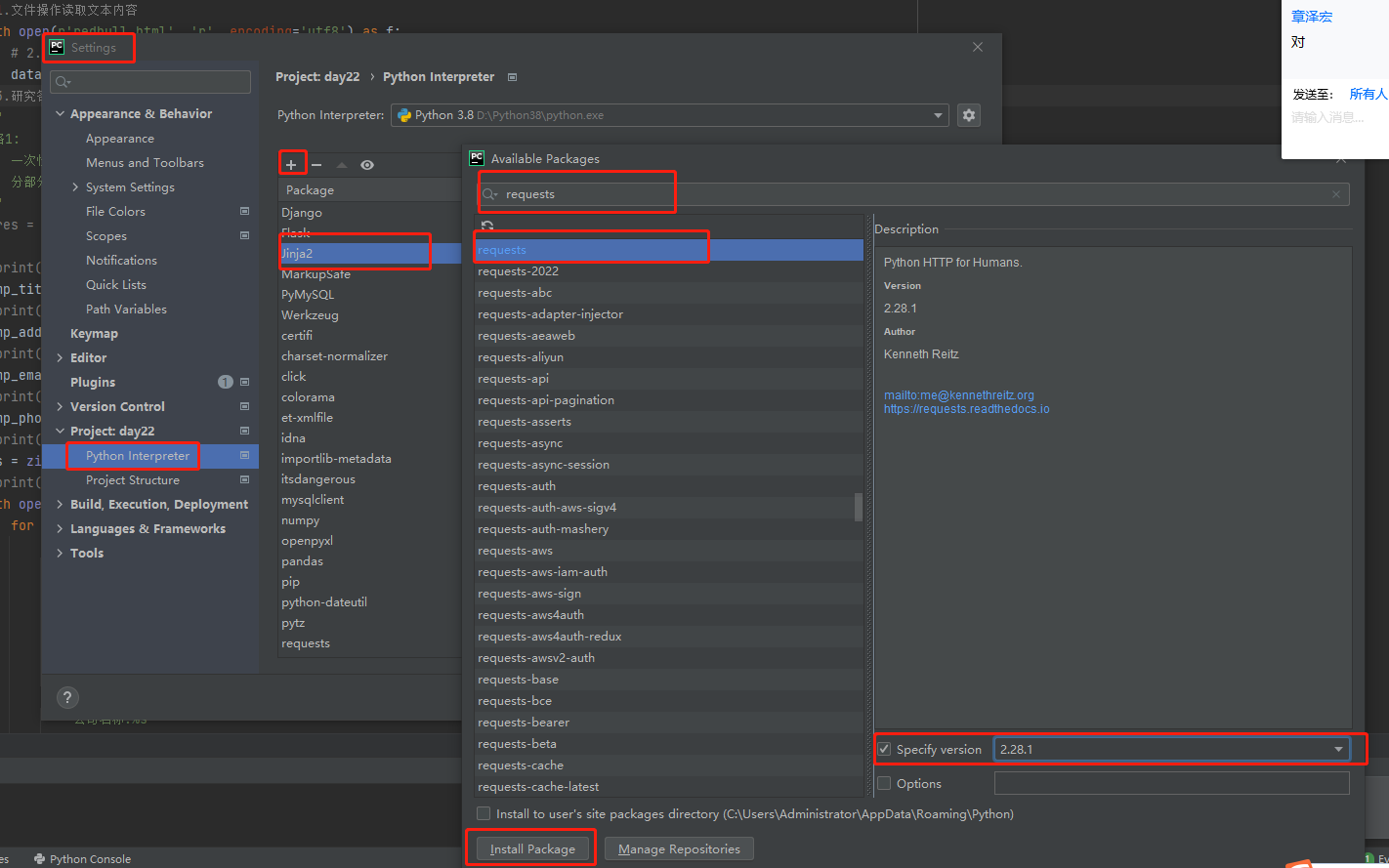
第二种 直接在pycharm里面下载模块,最简单!!!
2.pycharm提供快捷方式
群内截图
"""
下载第三方模块可能会出现的问题
1.报错并有警告信息
WARNING: You are using pip version 20.2.1;
原因在于pip版本过低 只需要拷贝后面的命令执行更新操作即可
d:\python38\python.exe -m pip install --upgrade pip
更新完成后再次执行下载第三方模块的命令即可
2.报错并含有Timeout关键字
说明当前计算机网络不稳定 只需要换网或者重新执行几次即可
3.报错并没有关键字
面向百度搜索
pip下载XXX报错:拷贝错误信息
通常都是需要用户提前准备好一些环境才可以顺利下载
4.下载速度很慢
pip默认下载的仓库地址是国外的 python.org
我们可以切换下载的地址
pip install 模块名 -i 仓库地址
pip的仓库地址有很多 百度查询即可
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
"""
网络爬虫模块之--------------requests模块 重要!!!
requests模块能够模拟浏览器发送网络请求
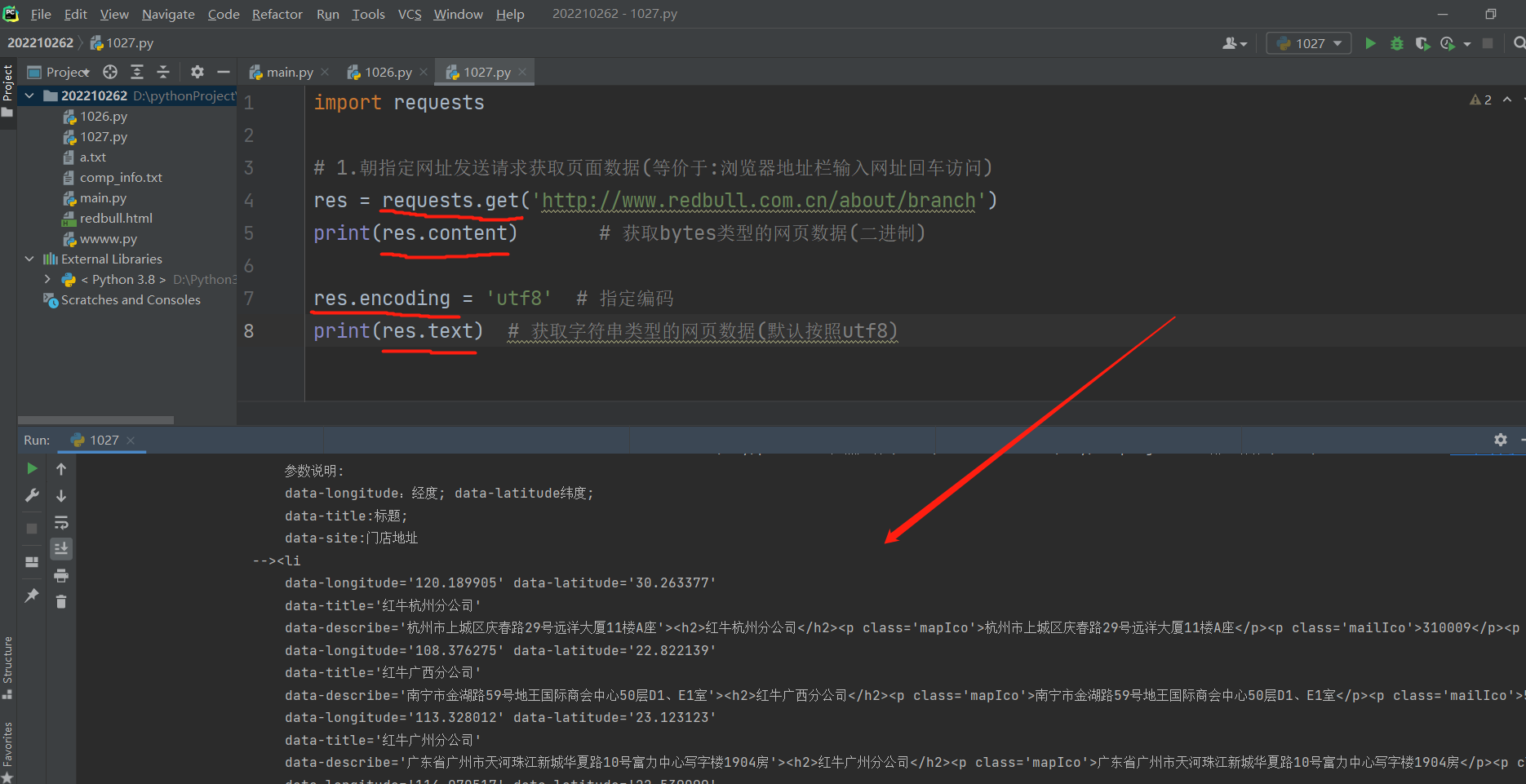
import requests
# 1.朝指定网址发送请求获取页面数据(等价于:浏览器地址栏输入网址回车访问)
res = requests.get('http://www.redbull.com.cn/about/branch')
print(res.content) # 获取bytes类型的网页数据(二进制)
res.encoding = 'utf8' # 指定编码
print(res.text) # 获取字符串类型的网页数据(默认按照utf8) 等价于鼠标右键查看网页源码
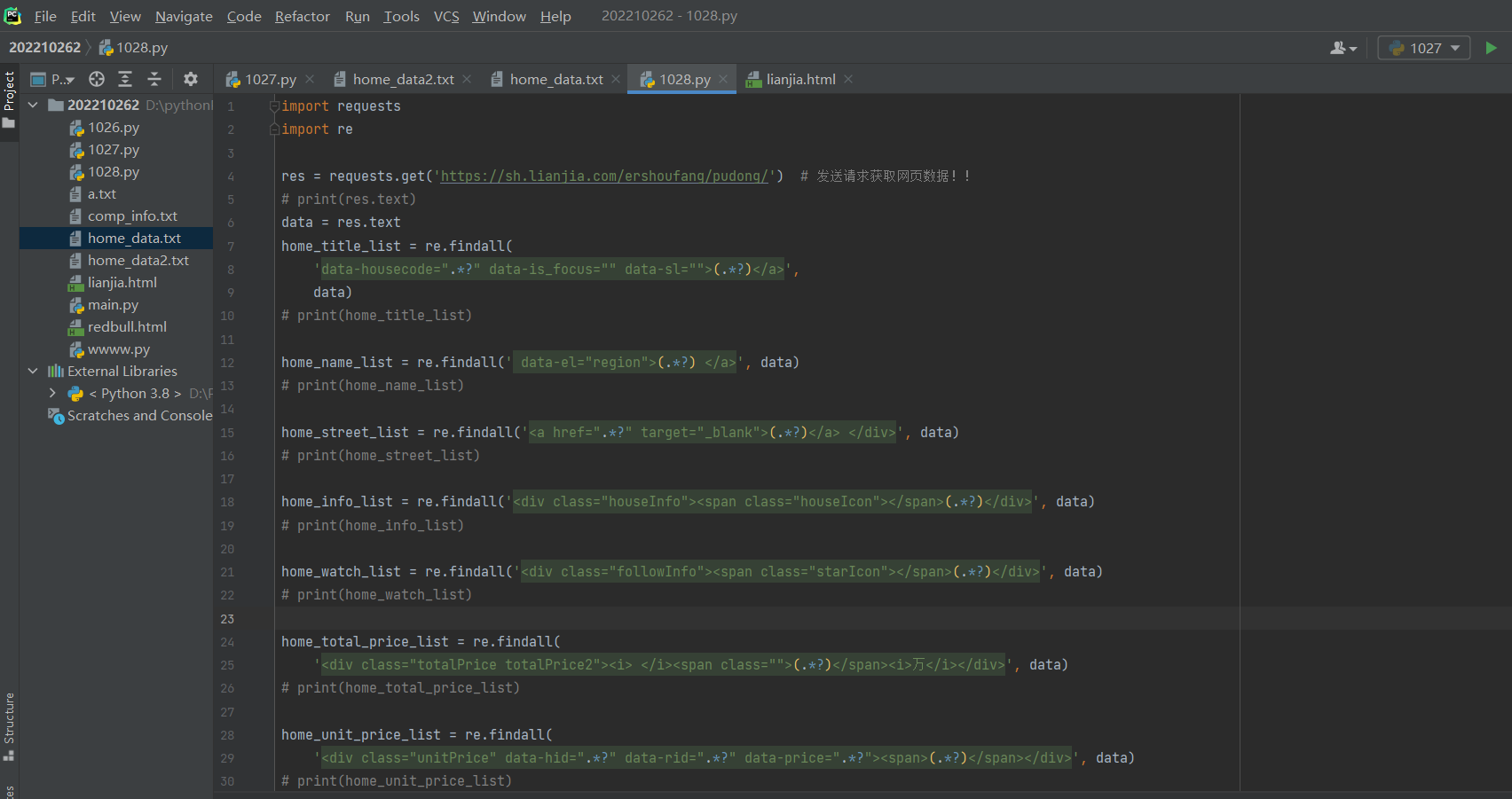
网络爬虫实战之爬取链家二手房数据
import requests
import re
# 第一步:
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/') # 发送请求获取网页数据!!
# print(res.text) # 打印看一下结果
data = res.text # 默认按照utf8解码字符串类型文本数据!!
# 第二步,利用正则,与re模块找到想要的数据,可以先ctrl+A 全选内容,复制粘贴到html文件里面去,这样就可以用ctrl+F 搜索功能先找关键字,一眼定位到地方,方便写正则:
房屋标题信息
home_title_list = re.findall(
'<a class="" href=".*?" target="_blank" data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',
data)
# 注意这个地方的正则表达式,可以先就写你要的数据的前后的字符然后中间用(.*?),然后打印看一下,能不能拿到你要的数据,如果拿到的结果多余你要的结果,说明限制的还不够,可以再两头再加一点字符限定一下,其次两头的限定符里面,可能也有一些是随着每一组的数据变的,所以不能写死,所以还是用非贪婪匹配.*?,这样就写活了!!!!!!正则留这一串就行了 data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>'
# print(home_title_list)
# 打印看下结果对不对,如果还不对就继续修改分组两头的限定符
下面都是同样的方法依次类推
小区名
home_name_list = re.findall('<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>', data)
# print(home_name_list) 也是一样,打印看一下 正则这个就行了 data-el="region">(.*?) </a>'
街道
home_street_list = re.findall(
'<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" data-log_index=".*?" data-el="region">.*? </a> - <a href=".*?" target="_blank">(.*?)</a> </div>',data)
# print(home_street_list)
房屋详细信息
home_info_list = re.findall('<div class="houseInfo"><span class="houseIcon"></span>(.*?)</div>', data)
# print(home_info_list)
房屋关注人数等信息
home_watch_list = re.findall('<div class="followInfo"><span class="starIcon"></span>(.*?)</div>', data)
# print(home_watch_list)
总价格
home_total_price_list = re.findall(
'<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span><i>万</i></div>', data)
# print(home_total_price_list)
房屋单价
home_unit_price_list = re.findall(
'<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div>', data)
# print(home_unit_price_list)
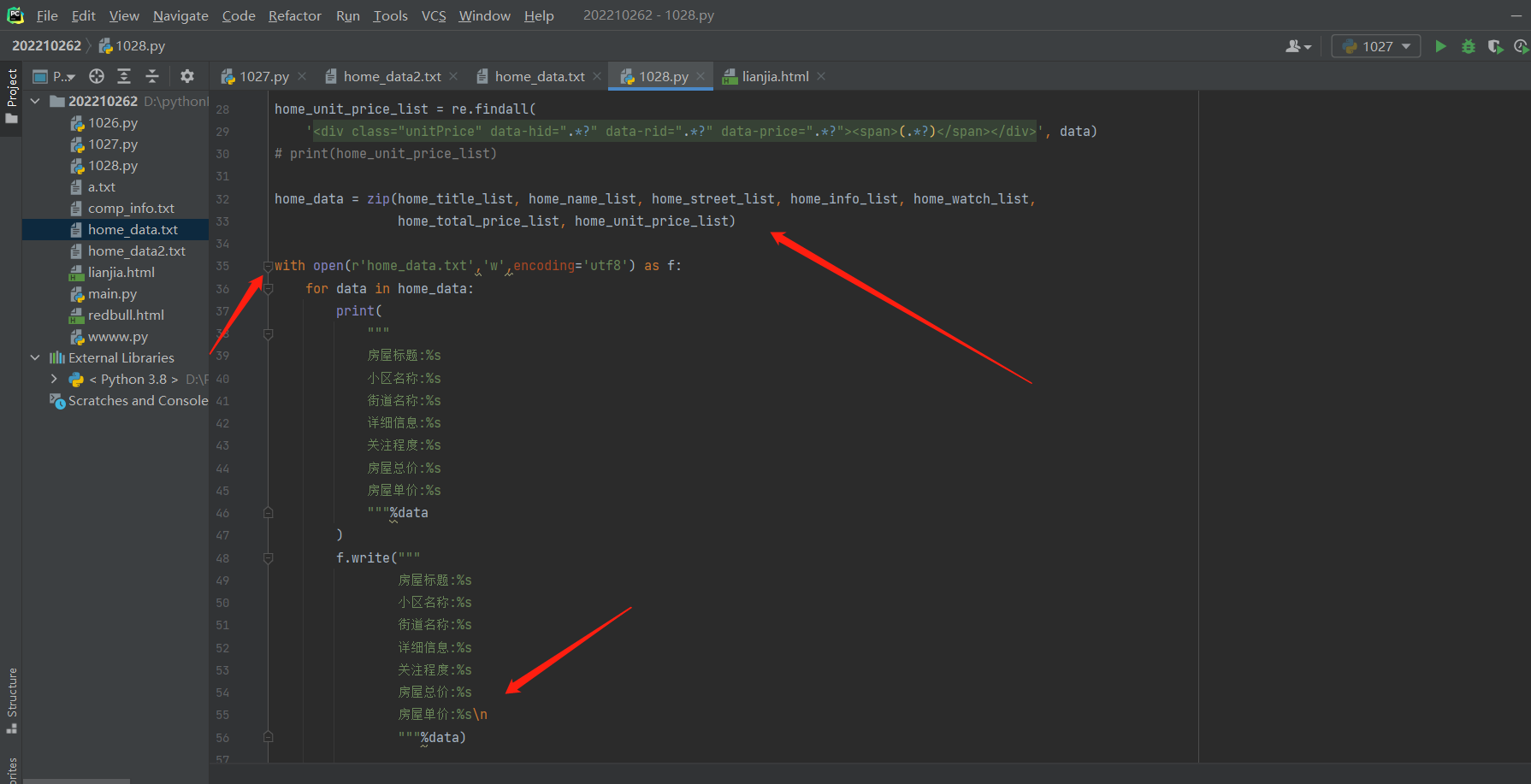
每个房子的总信息用zip函数对刚刚的每一个结果拉链一下
home_data = zip(home_title_list, home_name_list, home_street_list, home_info_list, home_watch_list,
home_total_price_list, home_unit_price_list)
最后把拉链出的列表数据,for循环出每一个元组,再将每一个元组里面的单个数据利用格式化输出,写进文件里去。第一页所有数据就爬到了!!
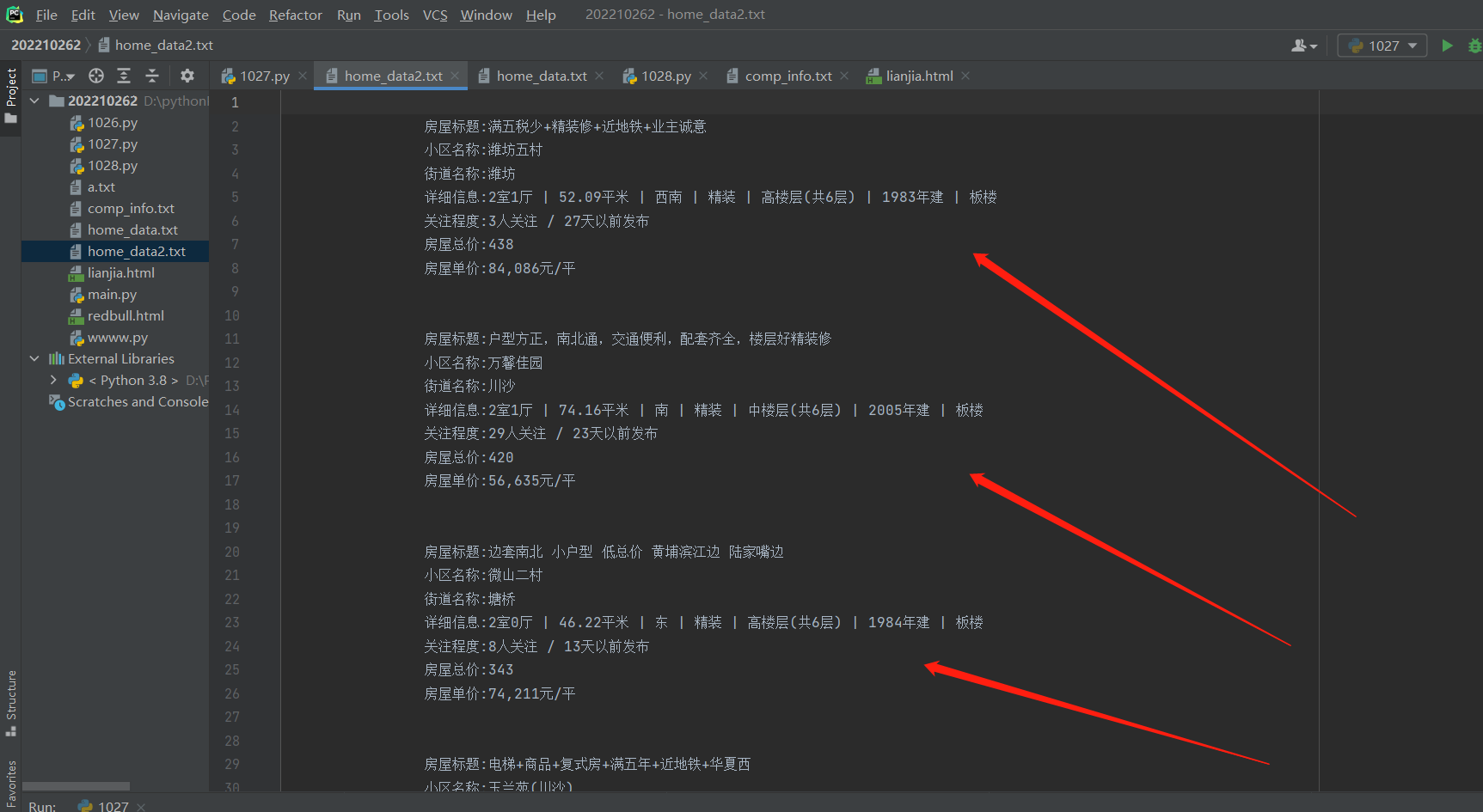
with open(r'home_data.txt','w',encoding='utf8') as f:
for data in home_data:
print(
"""
房屋标题:%s
小区名称:%s
街道名称:%s
详细信息:%s
关注程度:%s
房屋总价:%s
房屋单价:%s
"""%data
) # print这行可以不写,只是为了理解的写的!!!
f.write("""
房屋标题:%s
小区名称:%s
街道名称:%s
详细信息:%s
关注程度:%s
房屋总价:%s
房屋单价:%s\n
"""%data)
.
.
自动化办公领域之-----------------openpyxl模块
1.excel文件的后缀名问题
03版本之前
.xls
03版本之后
.xlsx
2.操作excel表格的第三方模块
xlwt往表格中写入数据、wlrd从表格中读取数据
兼容所有版本的excel文件
openpyxl最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
ps:还有很多操作excel表格的模块 甚至涵盖了上述的模块>>>:pandas
3.openpyxl操作
'''学会看官方文档!!!'''
先创建excel文件,再保存文件,然后往中间写操作excel的代码!!!
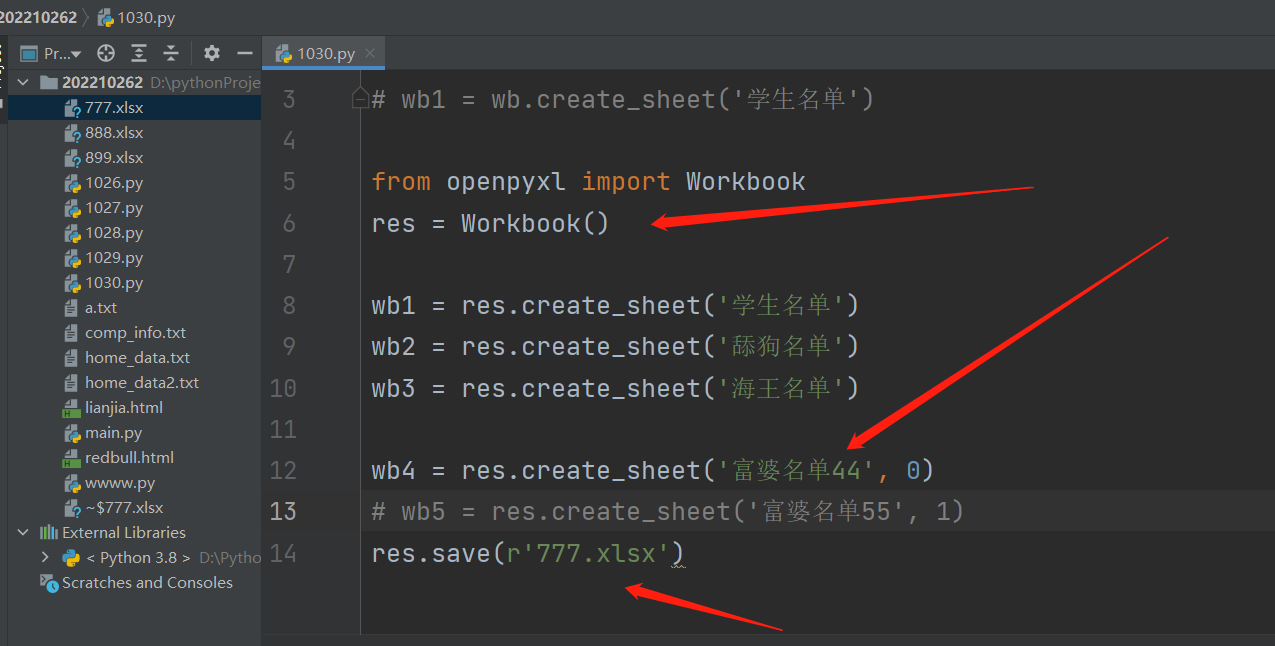
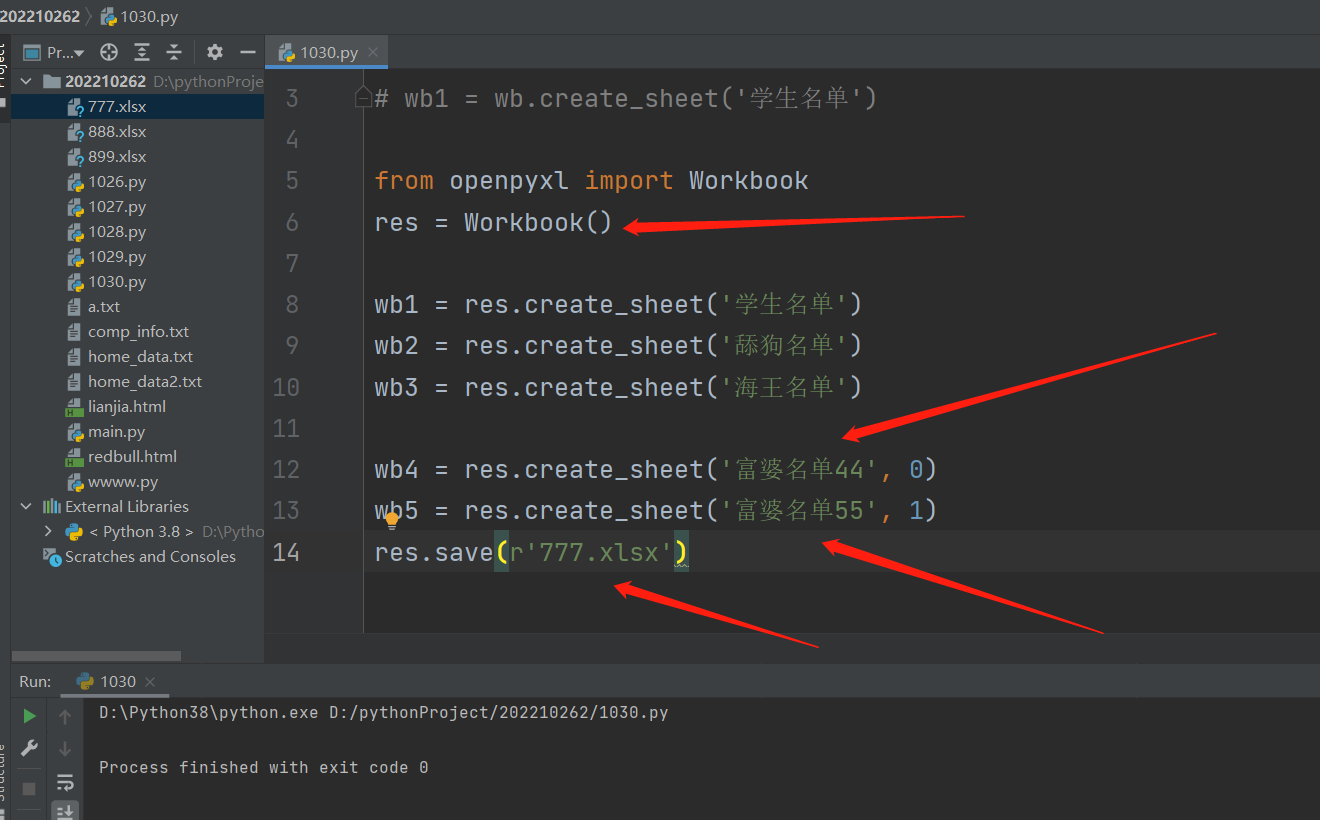
from openpyxl import Workbook
res = Workbook() # 1. 代码创建一个excel文件 res就是个变量名没特殊含义
# 3. 在一个excel文件内创建多个工作簿
wb1 = res.create_sheet('学生名单')
wb2 = res.create_sheet('舔狗名单')
wb3 = res.create_sheet('海王名单')
# 4. 还可以修改默认的工作簿位置
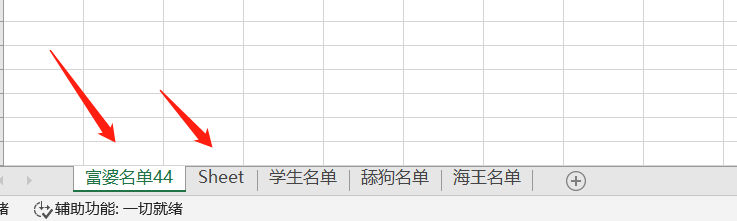
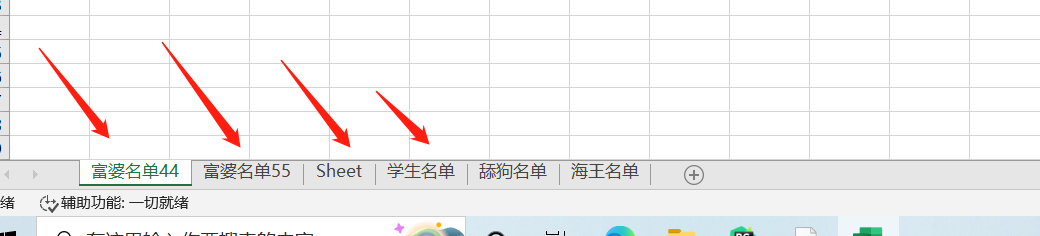
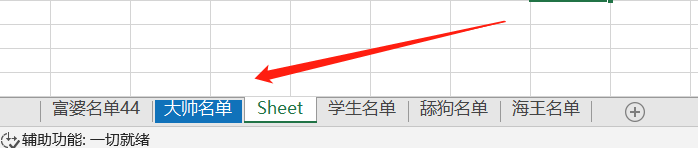
wb4 = res.create_sheet('富婆名单', 0) # 初始的sheet工作簿默认是索引0与它绑定,手动产生一个新的工作簿,让索引0与它绑定,那么其他工作簿的索引位置默认往后移一位。假设下一行代码再次产生一个新的工作簿,绑定索引1的位置,那么原有的工作簿还是一样全部往后移一位
,如果创建的工作簿没有绑定索引0,那么默认被初始的sheet工作簿绑定!!!
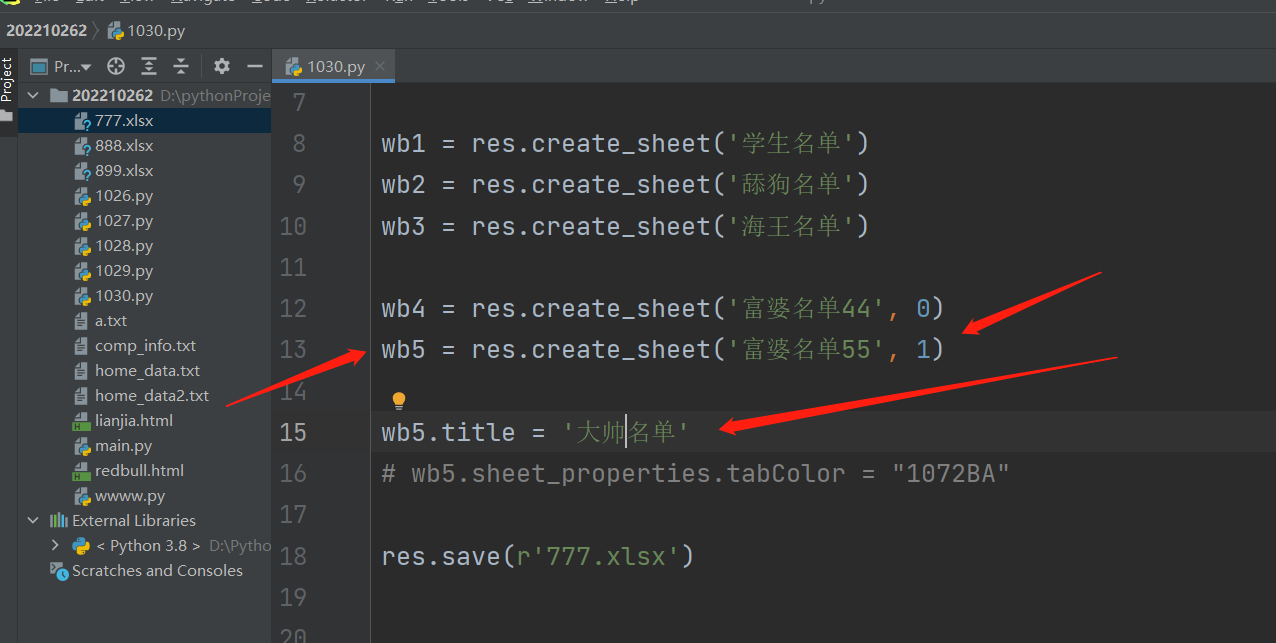
# 5. 还可以二次修改对应变量名的工作簿名称
wb4.title = '大帅名单' # 就把wb4变量名对应的工作簿名称给改成'大帅名单'了
wb4.sheet_properties.tabColor = "1072BA" # 改工作簿名称的颜色
.
.
.
.
.

.
.
.
.
# 6. 填写数据的方式1 按excel的横纵坐标填写字母是横左边,数字是纵坐标!!!
wb4['F4'] = 666
# 6. 填写数据的方式2 这个按行数row 列数column 确定要写的位置
wb4.cell(row=3, column=1, value='jason')
# 6. 填写数据的方式3 按行添加!!!!!列表里面有多少数据,就写多少数据!!
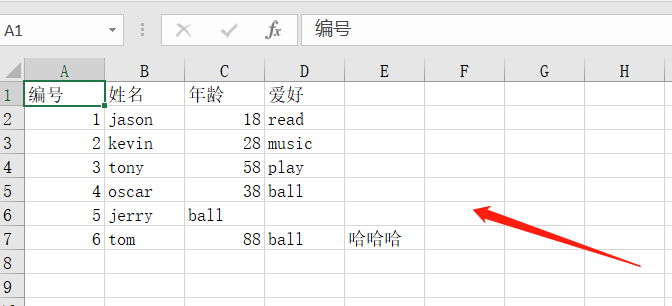
wb4.append(['编号', '姓名', '年龄', '爱好']) # 表头字段
wb4.append([1, 'jason', 18, 'read'])
wb4.append([2, 'kevin', 28, 'music'])
wb4.append([3, 'tony', 58, 'play'])
wb4.append([4, 'oscar', 38, 'ball'])
wb4.append([5, 'jerry', 'ball'])
wb4.append([6, 'tom', 88,'ball','哈哈哈'])
.
.
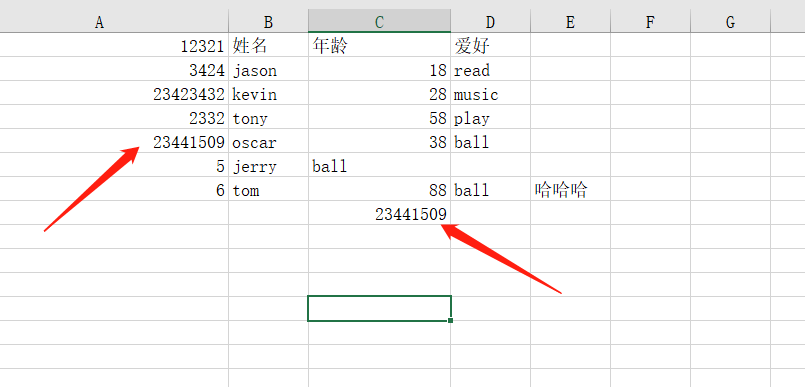
# 填写数学公式
wb4.cell(row=1, column=1, value=12321)
wb4.cell(row=2, column=1, value=3424)
wb4.cell(row=3, column=1, value=23423432)
wb4.cell(row=4, column=1, value=2332)
wb4['A5'] = '=sum(A1:A4)' # 写公式两种方法都行
wb4.cell(row=8, column=3, value='=sum(A1:A4)') # 写公式两种方法都行
res.save(r'111.xlsx') # 2. 保存该excel文件
.
.
.
openpyxl主要用于数据的写入 至于后续的表单操作它并不是很擅长 如果想做需要更高级的模块pandas
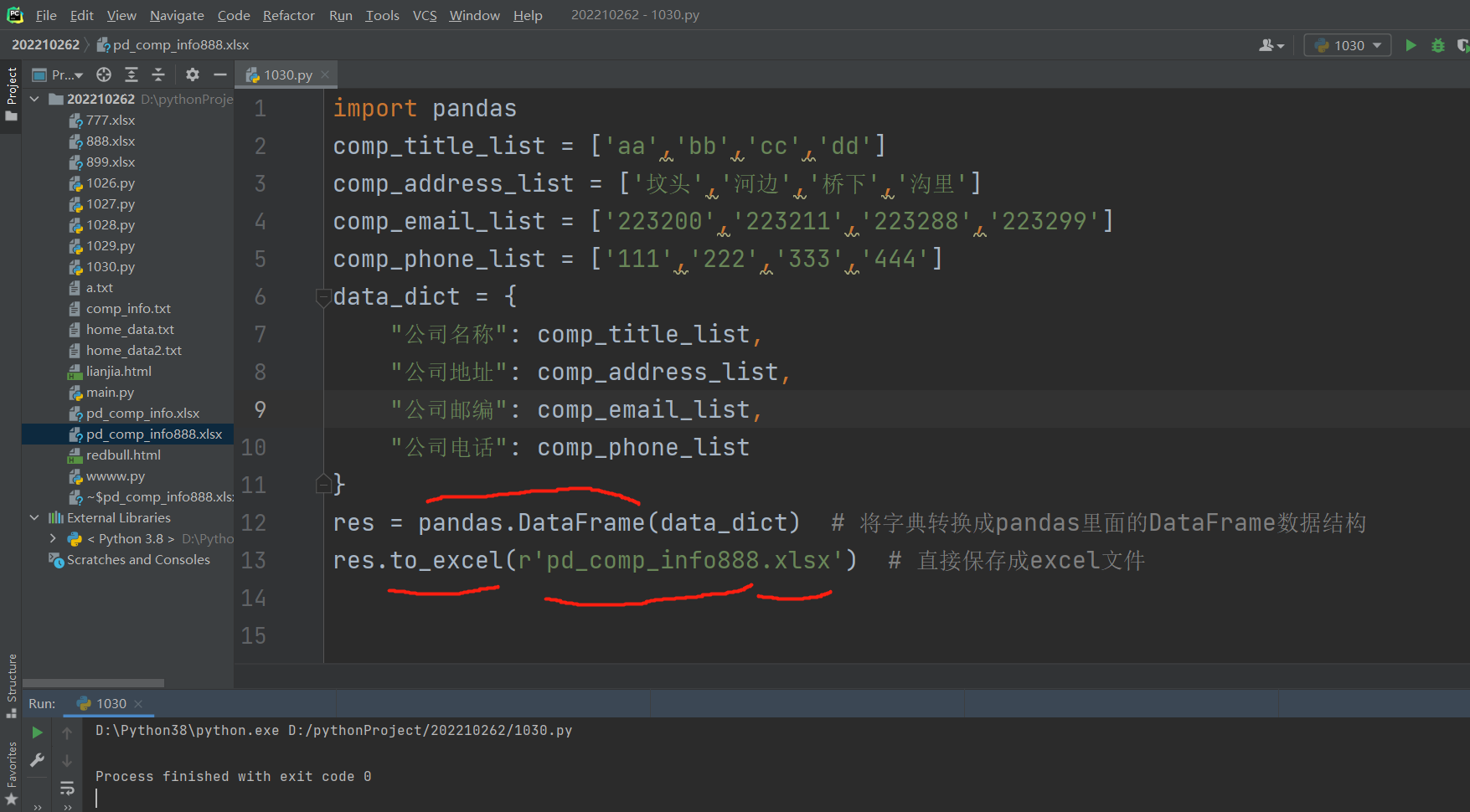
import pandas
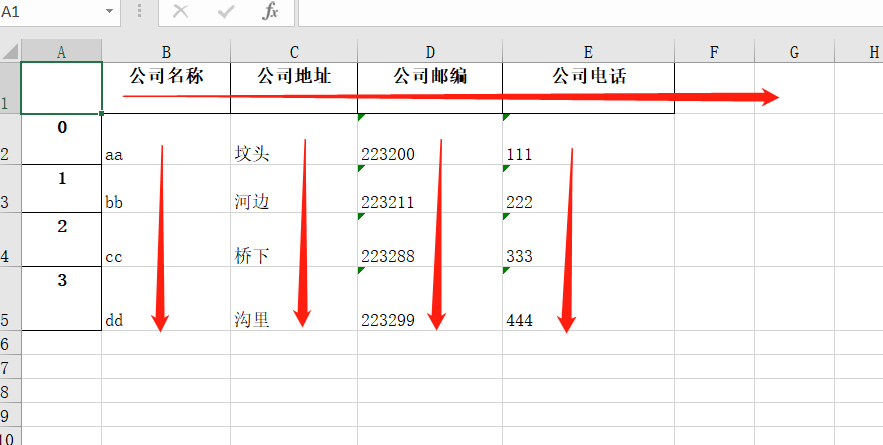
comp_title_list = ['aa','bb','cc','dd']
comp_address_list = ['坟头','河边','桥下','沟里']
comp_email_list = ['223200','223211','223288','223299']
comp_phone_list = ['111','222','333','444']
data_dict = {
"公司名称": comp_title_list,
"公司地址": comp_address_list,
"公司邮编": comp_email_list,
"公司电话": comp_phone_list
}
df = pandas.DataFrame(data_dict) # 将字典转换成pandas里面的DataFrame数据结构
df.to_excel(r'pd_comp_info.xlsx') # 保存excel
这个方法就理解为把字典里面所有的键横着写进excel里面第一行,每一个键对应的列表里面的数据全部对着键的位置往下写,这个方法要求,每个列表里面的数据的个数是一样多。
"""
excel软件正常可以打开操作的数据集在10万左右 一旦数据集过大 软件操作几乎无效
需要使用代码操作>>>:pandas模块
"""
。
作业
1.思考如何爬取二手房指定页数的数据
2.学有余力可以简单研究一下pandas模块
3.购物车还没有掌握的 抓紧时间 最多一天了! 马上就是ATM项目
代码实现:
import requests
import re
# https://sh.lianjia.com/ershoufang/pudong/pg1/
# https://sh.lianjia.com/ershoufang/pudong/pg2/
# https://sh.lianjia.com/ershoufang/pudong/pg3/
# 总共100页
base_url ='https://sh.lianjia.com/ershoufang/pudong/pg%s/'
for i in range(1,101):
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/pg%s/' % i) # 发送请求获取网页数据!!
# print(res.text)
data = res.text
home_title_list = re.findall(
'data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',
data)
# print(home_title_list)
home_name_list = re.findall(' data-el="region">(.*?) </a>', data)
# print(home_name_list)
home_street_list = re.findall('<a href=".*?" target="_blank">(.*?)</a> </div>', data)
# print(home_street_list)
home_info_list = re.findall('<div class="houseInfo"><span class="houseIcon"></span>(.*?)</div>', data)
# print(home_info_list)
home_watch_list = re.findall('<div class="followInfo"><span class="starIcon"></span>(.*?)</div>', data)
# print(home_watch_list)
home_total_price_list = re.findall(
'<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span><i>万</i></div>', data)
# print(home_total_price_list)
home_unit_price_list = re.findall(
'<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div>', data)
# print(home_unit_price_list)
home_data = zip(home_title_list, home_name_list, home_street_list, home_info_list, home_watch_list,
home_total_price_list, home_unit_price_list)
with open(r'home_data.txt','a',encoding='utf8') as f:
for data in home_data:
# print(
# """
# 房屋标题:%s
# 小区名称:%s
# 街道名称:%s
# 详细信息:%s
# 关注程度:%s
# 房屋总价:%s
# 房屋单价:%s
# """%data
# )
f.write("""
房屋标题:%s
小区名称:%s
街道名称:%s
详细信息:%s
关注程度:%s
房屋总价:%s
房屋单价:%s\n
"""%data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号