python第十九课--os与json模块
昨日内容回顾
- 包的实际应用
内部含有__init__.py文件的文件夹
如果直接导入包名其实导入的是内部的__init__.py文件,
所以包名点的方式其实是跟__init__.py文件要名字
- 编程思想的转变
1.面条版
2.函数版
3.模块版
- 软件开发目录规范
-项目名
--bin目录 项目启动文件
---start.py
--conf目录 项目配置文件
---settings.py
--core目录 项目核心文件
---src.py
--interface目录 项目接口文件
---goods.py
---user.py
---accounts.py
--lib目录 项目公共文件,包括库文件,装饰器文件等
---common.py
--db目录 数据库文件 主要是一些文本等文件 后续有软件替代
---userinfo.txt
--log目录 日志文件 后续有软件替代
---log.log
--readme文件 项目说明书文件
---项目说明书
--requirements.txt文件 项目要求环境,模块及版本要求
---项目必备模块及版本
- collections模块
具名元组(namedtuple)
双端队列deque、队列(先进先出)、堆栈(先进后出)
有序字典、计数器
- 时间模块
"""
时间的三种格式
时间戳
格式化时间
结构化时间
"""
time模块
import time
time.time()
time.strftime('%Y-%m-%d %H:%M:%S')
time.strftime('%Y-%m-%d %X')
time.localtime()
time.sleep()
datetime模块
import datetime
datetime.datetime.today() 年月日时分秒
datetime.date.today() 年月日
datetime.timedelta(days=3) 时间差值
- 随机数模块
import random
random.random() 随机0-1之间的小数
random.randint(a,b) 随机a-b之间的整数
random.randrange(a,b,c) 随机a-b之间的整数,以c为步长,可以控制数字奇偶
random.choice() 括号里面一般放一个列表, 随机从列表里面取1个
random.choices() 将随机取出的值放到空列表里面去了
random.sample() 随机抽指定的样本数
random.shuffle() 将数据原来的顺序打乱
随机生成验证码:简单实现
for i in range(4)
uper1=chr(65,90) lower1=chr(97,122)
ASCII码数字转字母65-90A-Z 97-122a-z
num1=random.randint(0,9)
temp = random.choice(uper1,lower1,num1)
print(temp,end='')
.
.
.
今日内容概要
- os与sys模块
sys模块主要与python解释器打交道
sys是system的缩写,sys模块是与python解释器交互的一个接口。
sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分。
os模块主要与操作系统打交道
os是operation system(操作系统)的缩写,
os模块提供了多数操作系统的功能接口函数。
(OS模块提供了与操作系统进行交互的函数)
-
json模块
-
hashlib模块
今日内容详细
os模块 十分重要!!!!!!
# os模块主要与代码运行所在的操作系统打交道
dir 就是 directory(计算机的)目录,文件夹
------------------------------------
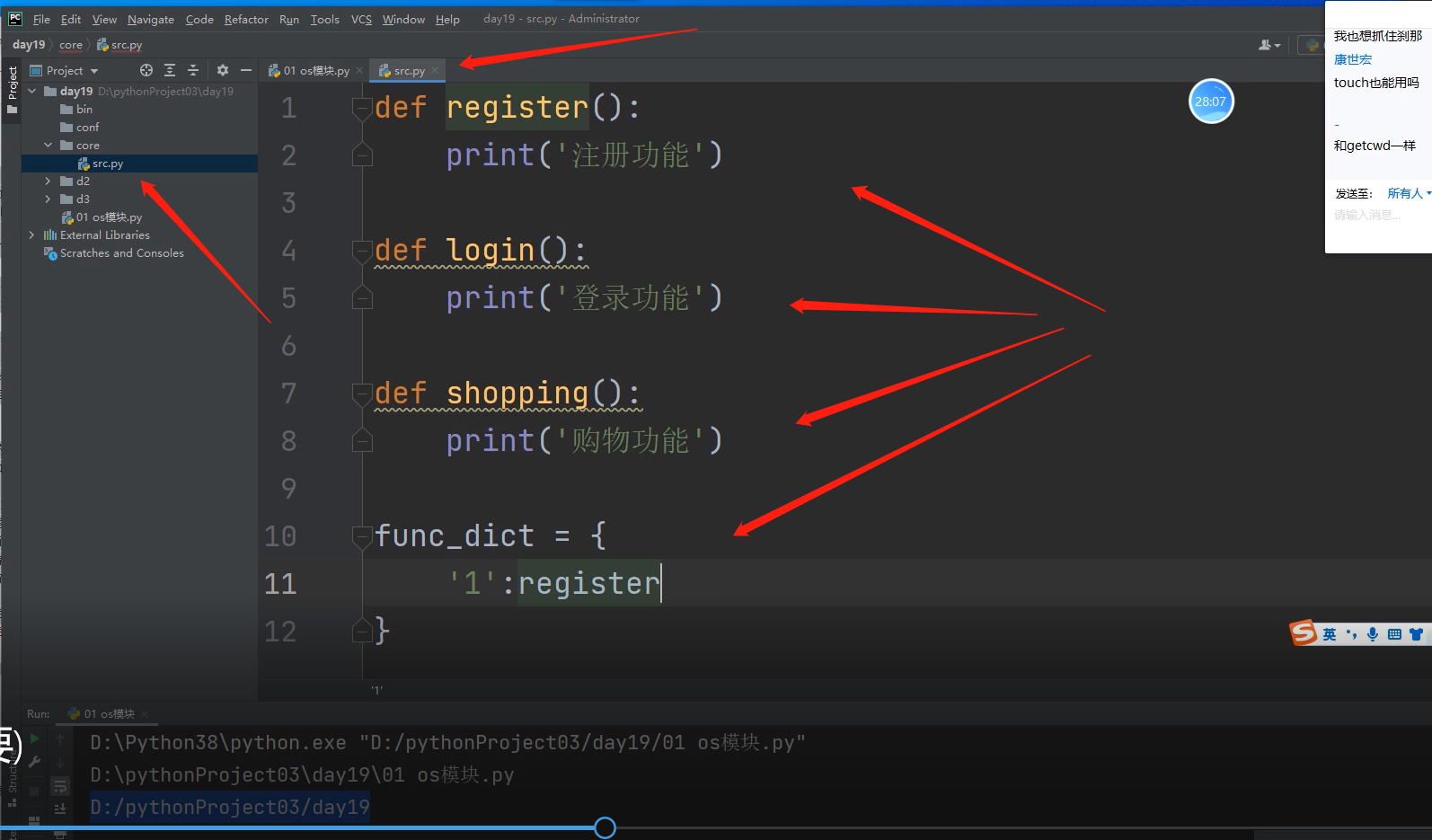
# 1.创建文件夹(目录)
------------------------------------
os.mkdir(r'd1')
在执行文件所在的路径下,创建一个名字叫d1的文件夹
os.mkdir(r'd2\d22\d222')
# 不可以一次性,创建多级目录,
# 但是如果d2\d22这两个文件夹存在,d222文件夹也能创建,
# 也就是说这个方法每次只能创一个文件夹,且该文件夹的上级文件夹必须存在!!!
------------------------------------
os.makedirs(r'd2\d22\d222') # 可以创建多级目录
os.makedirs(r'd3') # 也可以创建单级目录
------------------------------------
# 2.删除目录(文件夹)!!!!!!!!!!
------------------------------------
os.rmdir(r'd1')
# 可以删除单级目录,每次只能删一个,当是绝对路径时删最后一个文件夹!!!
# 用法与mkdir创建目录用法一样
os.rmdir(r'd2\d22\d222') # 不可以一次性删除多级目录,d2\d22存在可以删d222文件夹
------------------------------------
os.removedirs(r'd2\d22') # 可以删除多级目录
os.removedirs(r'd2\d22\d222\d2222') # 只能删除空的多级目录!!!
os.rmdir(r'd3') # 只能删空的单级目录!!!
------------------------------------
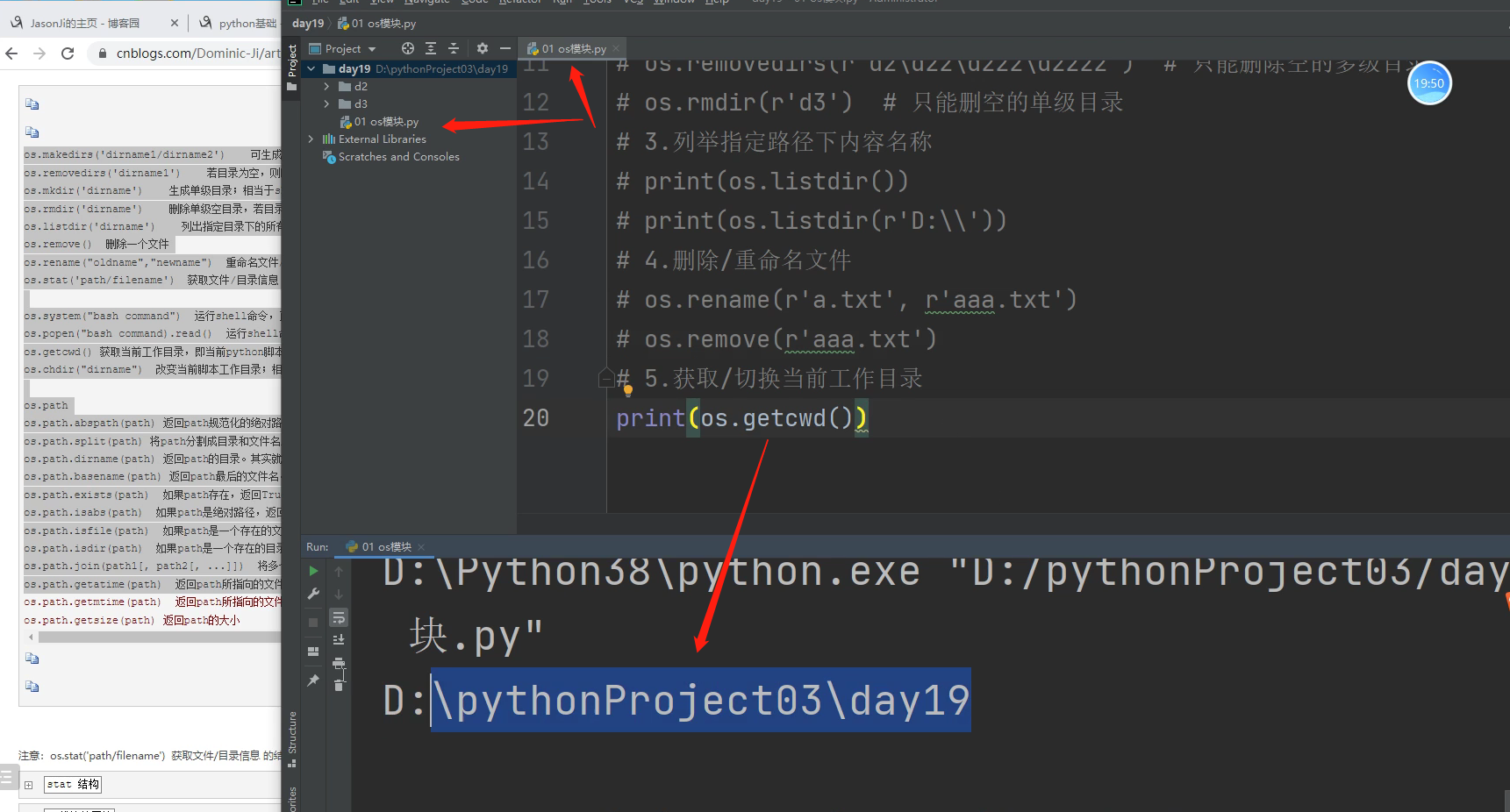
# 3.获取指定路径下内容名称 os.listdir()
print(os.listdir())
# listdir()括号里面什么都不写,默认获取当前路径下所有文件名称!!!
print(os.listdir(r'D:\\'))
# 也可以获取指定路径下的文件名称!!!
# 注意此处文件包括文件夹名称与单个的功能文件名称
------------------------------------
# 4.删除/重命名文件 注意文件是文件,文件夹是目录!!!
os.rename(r'a.txt', r'b.txt')
# 重命名文件,将a.txt重命名为b.txt,如果是相对路径,也是只能在当前执行文件的目录下可以操作
os.rename(r'd1\e1\p111.py', r'd1/e1/p222.py') 绝对路径也可以重命名
os.remove(r'aaa.txt') 相对路径 只能在当前目录下操作!!!
os.remove(r'd1\e1\p121.py') 绝对路径也能删文件,只删路径的最后的那一个!!!
------------------------------------
.
.
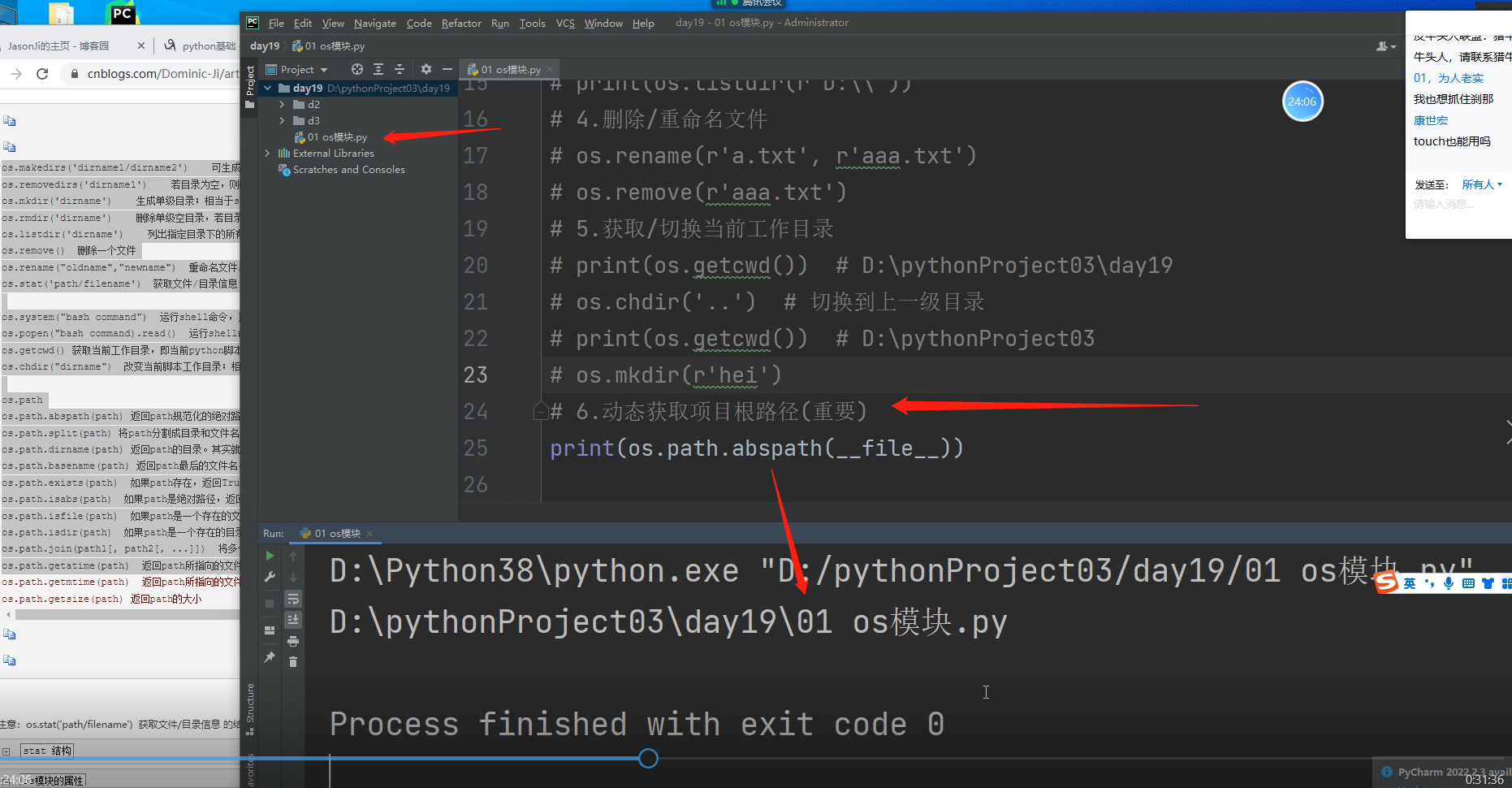
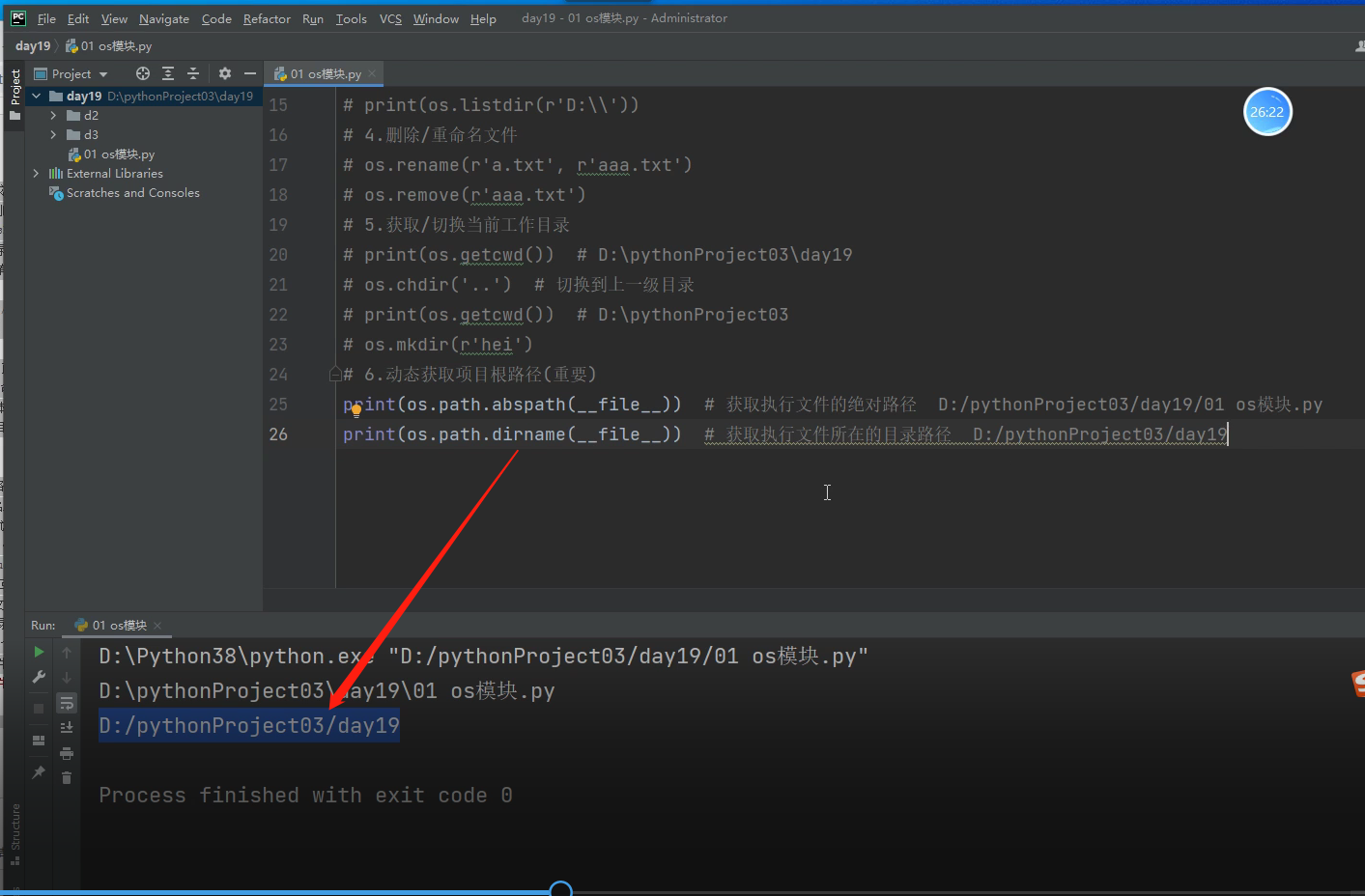
6.动态获取路径(重要!!!!!!!!!!!!!!!)
### 注意绝对路径是包括执行文件本身的!!! os.path.abspath(_ _ file _ _)
### 目录路径是不包含执行文件本身的!!!! os.path.dirname(_ _file _ _)
os.path.abspath(__file__)的路径
print(os.path.abspath(__file__)) # 获取代码所在的执行文件的绝对路径!!!! D:\pythonProject03\day19\01 os模块.py
os.path.dirname(__file__) 的路径
print(os.path.dirname(__file__)) # 获取执行文件所在的目录路径,就是获取该文件的sys.path D:/pythonProject03/day19
---------------------------------------------------------
os.path.abspath(__file__) 与下面的方法唯一的差距就是该路径多带了执行文件自身!!
os.path.dirname(__file__) 这个语法用的很多!!!
.
.
.
.
.
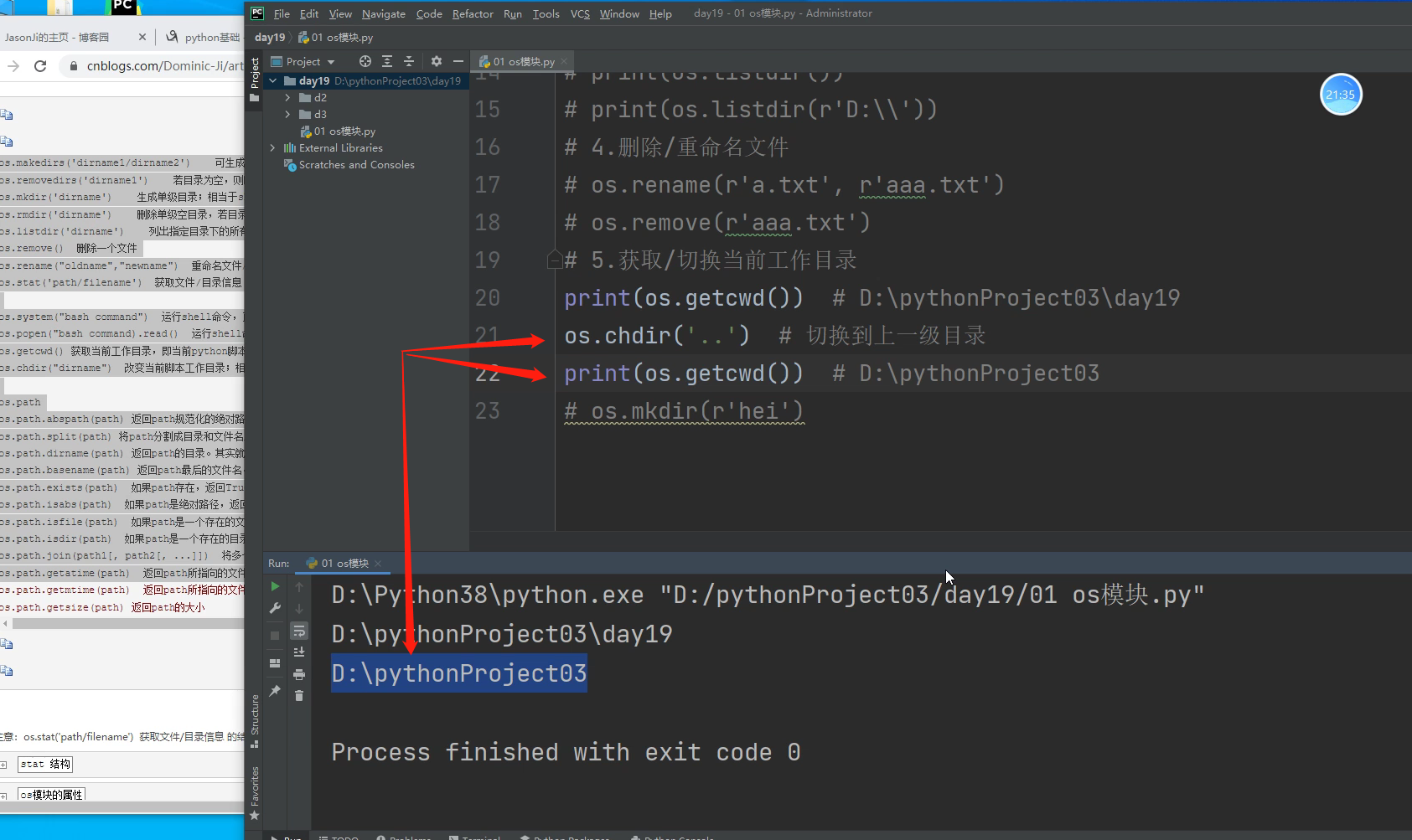
7.判断路径是否存在(文件、目录) 自动化创建目录要用!!! 重要!!!!!!
os.path.exists()
判断路径在不在,不管是文件路径还是目录路径
print(os.path.exists(r'01 os模块.py')) # 判断文件路径是否存在 True
print(os.path.exists(r'D:\pythonProject03\day19')) # 判断目录是否存在 True
这个更精确,判断路径是不是文件
print(os.path.isfile(r'01 os模块.py')) # 判断路径是不是文件的路径 True
print(os.path.isfile(r'D:\pythonProject03\day19')) # 判断路径是否是文件 False
这个更精确,判断路径是不是目录
print(os.path.isdir(r'01 os模块.py')) # False
print(os.path.isdir(r'D:\pythonProject03\day19')) # True

.
.
.
.
.
.
8.路径拼接 os.path.join() 重要!!!!!!!!!!
s1 = r'D:\pythonProject03\day19'
s2 = r'01 os模块.py'
print(f'{s1}\{s2}') # 不能手动拼接路径,会出问题的
注意!!!!!!!!
涉及到路径拼接一定不要自己做 因为不同的操作系统路径分隔符不一样
print(os.path.join(s1, s2)) # 一定要用path.join方法拼接路径!!!
-------------------------------------
### 9.获取文件大小(字节)
print(os.path.getsize(r'a.txt'))
.
.
.
.
.
.
.
.
sys模块
sys模块主要与python解释器打交道
import sys
print(sys.path) # 获取执行文件的sys.path
print(sys.getrecursionlimit()) # 获取python解释器默认最大递归深度
sys.setrecursionlimit(2000) # 修改python解释器默认最大递归深度
print(sys.version) # 解释器版本信息
3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]
print(sys.platform) # 平台信息 win32(了解即可)
.
.
.
.
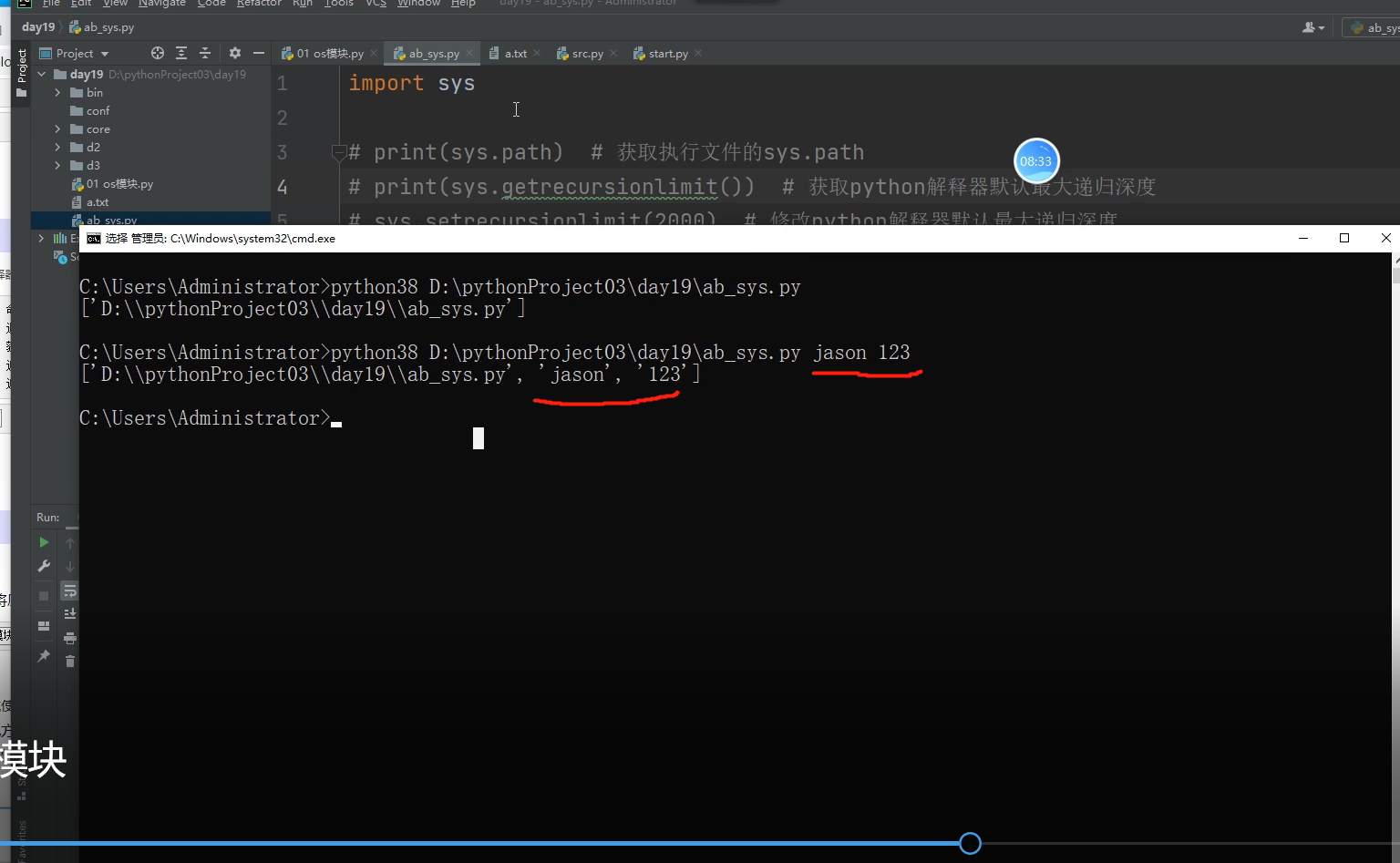
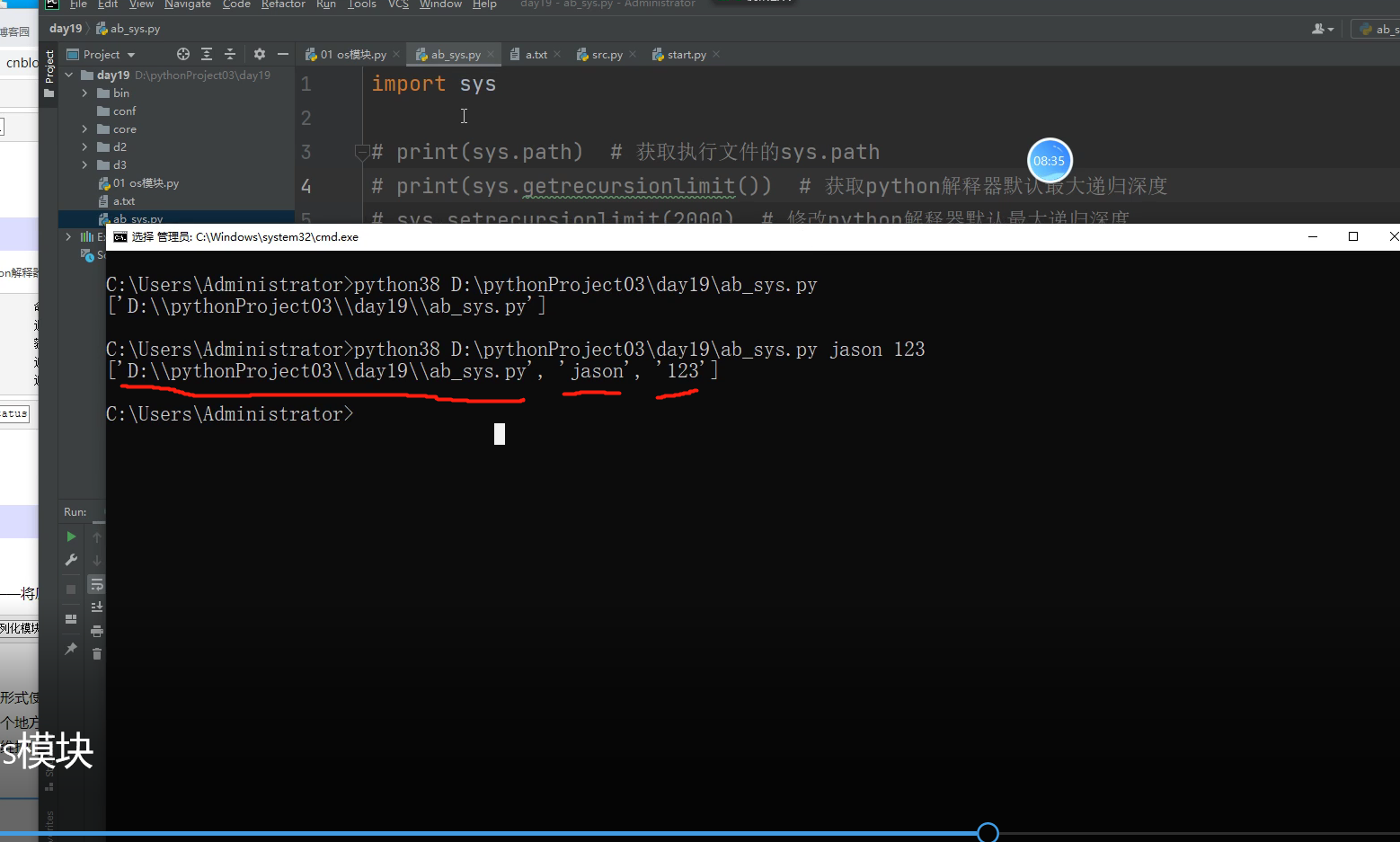
sys.argv是一个从【程序外部】获取参数的桥梁,
从外部取得的参数可以是多个,所以获得的是一个列表(list),
也就是说sys.argv其实可以看作是一个列表,可以用[0]、[1]、[2]、[3]…等提取其中的元素。
第一个元素(sys.argv[0])是程序本身路径,随后才依次是外部给予的参数。
res = sys.argv
#sys.argv 这个方法主要是用于py文件将来,命令行执行时,在路径后面必须添加额外的信息,比如账号密码信息
if len(res) != 3: # 如果字符数不是3 因为路径 用户名 密码 总共3个字符串!
print('执行命令缺少了用户名或密码')
else:
username = res[1]
password = res[2]
if username == 'jason' and password == '123':
print('jason您好 文件正常执行')
else:
print('您不是jason无权执行该文件')
这样就可以用代码控制,在文件在用命令行执行的时候,到底能不能执行!!!!!!
.
.
.
.
.
.
.
.
.
json模块 使用频率很高!!! 重要!!!!!!
dump 倾倒;倾卸 ;,转存(计算机数据)
load载入
json 模块就4个方法
dumps loads
-----------------------
dump load
-----------------------
dump相当于是dumps()和write()方法的结合!!!!
load相当于是loads()和read()方法的结合!!!!
----------------------
json模块的主要功能是将序列化数据从文件里读取出来或者存入文件。
其中dump()是将数据存入文件中,load()是用于读取文件。
----------------------
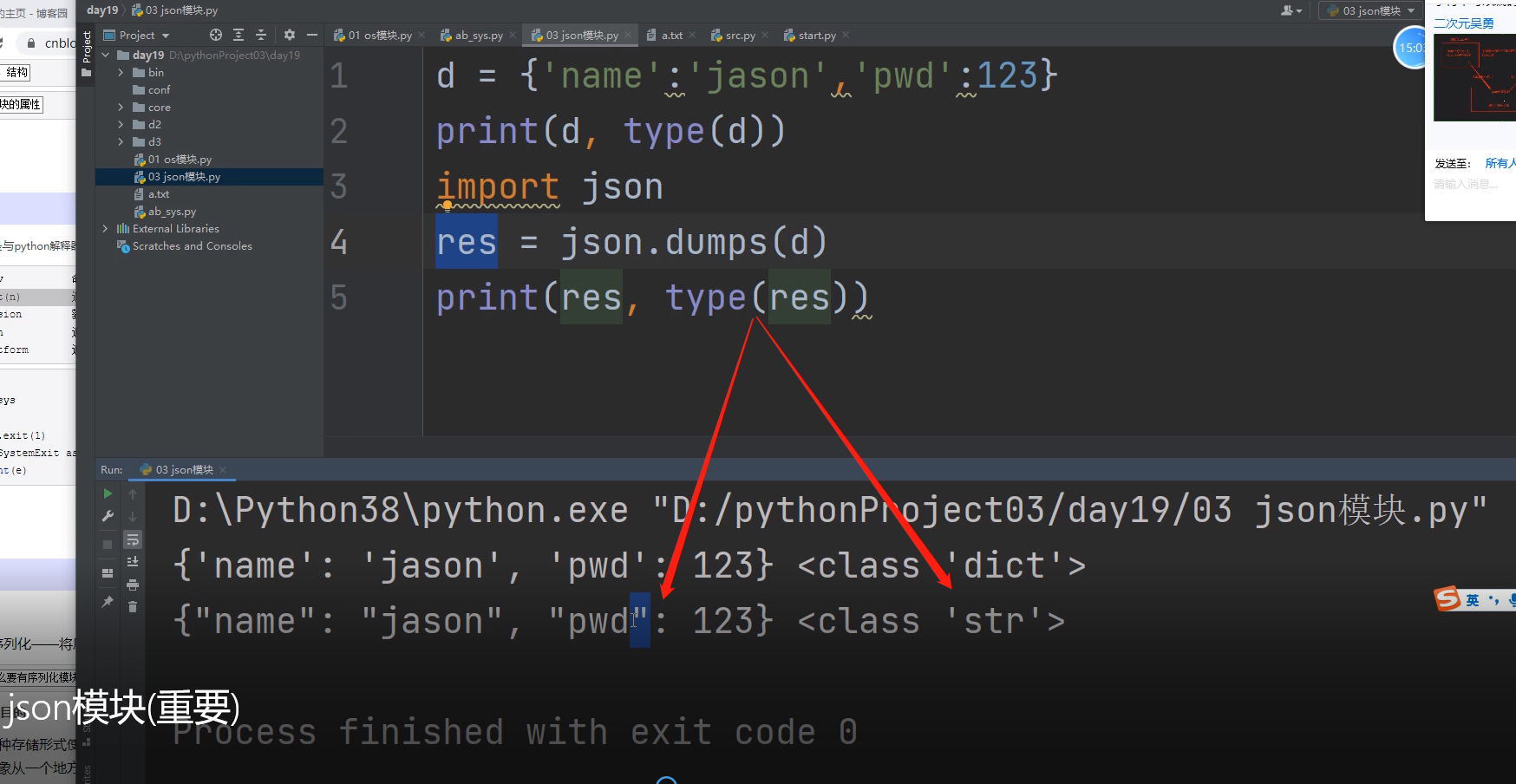
而dumps()和loads()是对python对象进行操作。
dumps()是将python对象编码成json字符串。
loads()是将json字符串解码成python对象。
---------------------
json.dumps()和json.dump()的区别
json.dumps() 是把python对象转换成json对象的一个过程,生成的是字符串。
json.dump() 是把python对象转换成json对象生成一个fp的文件流,和文件相关。
---------------------
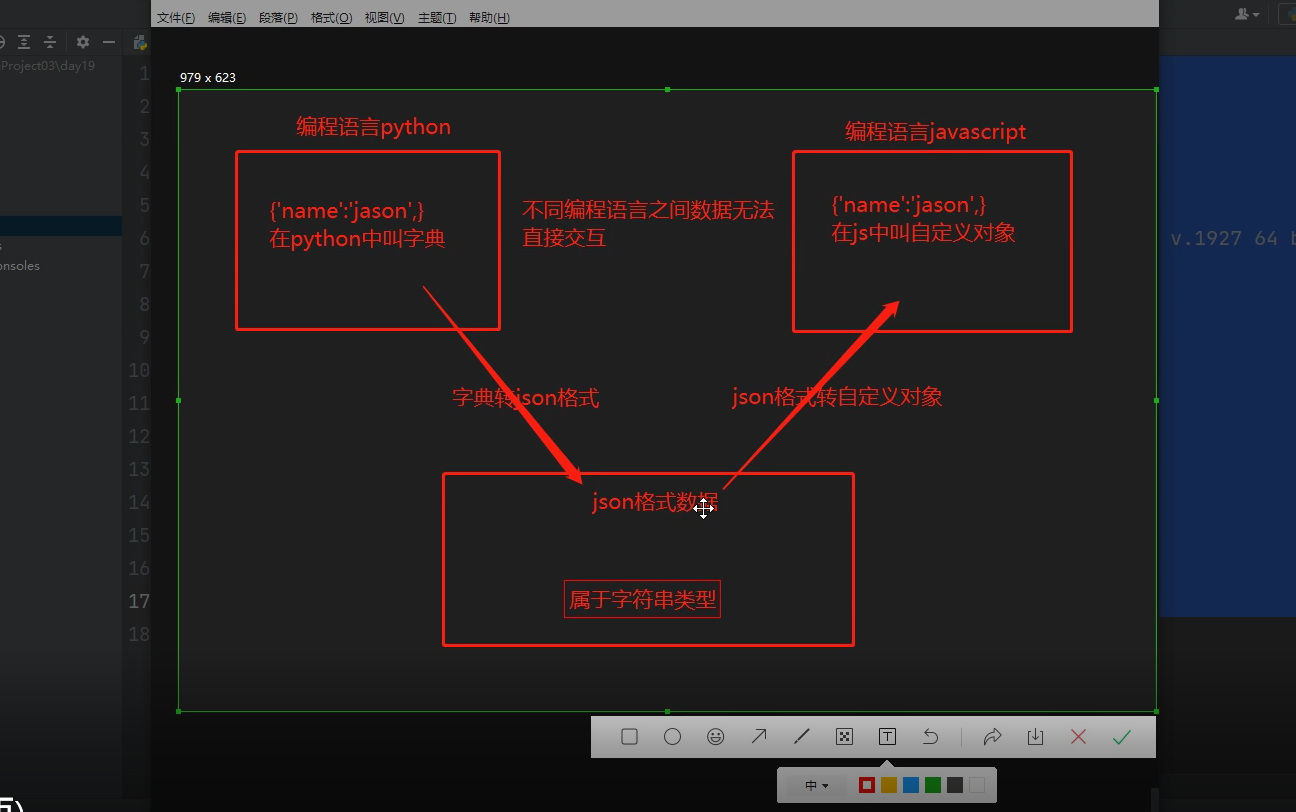
json模块也称为序列化模块
序列化可以打破语言限制实现不同编程语言之间数据交互
什么叫序列化?
将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化!!!!!!
序列化的目的
1、以某种存储形式使自定义对象持久化;
2、将对象从一个地方传递到另一个地方。
3、使程序更具维护性。
-----------------------------------------
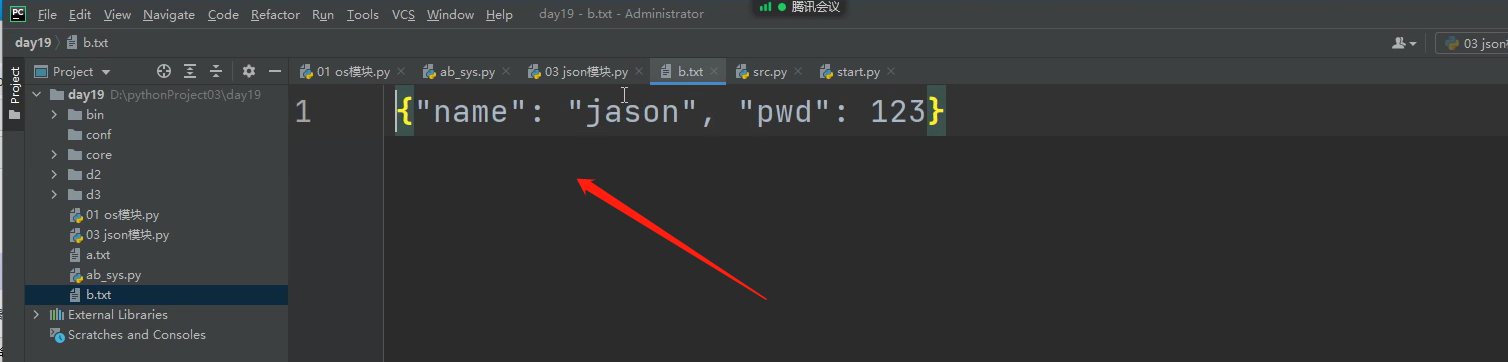
json格式数据的形式: 字符串类型,并且引号都是双引号!!!
---
json相关操作 dump 与 dumps 使用方法不一样,容易混,注意!!!
针对数据
json.dumps() 将某个数据类型转为json类型的字符串
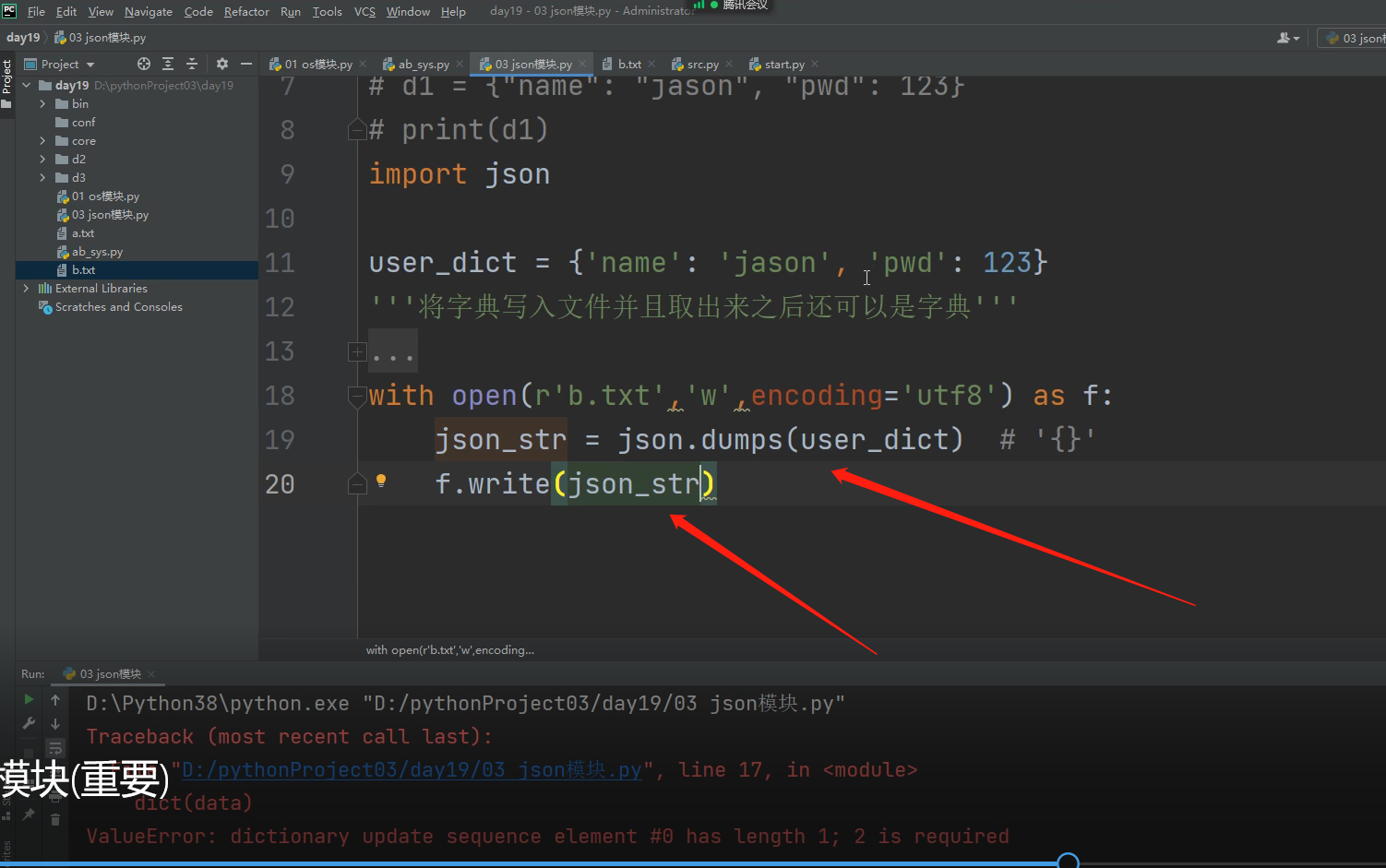
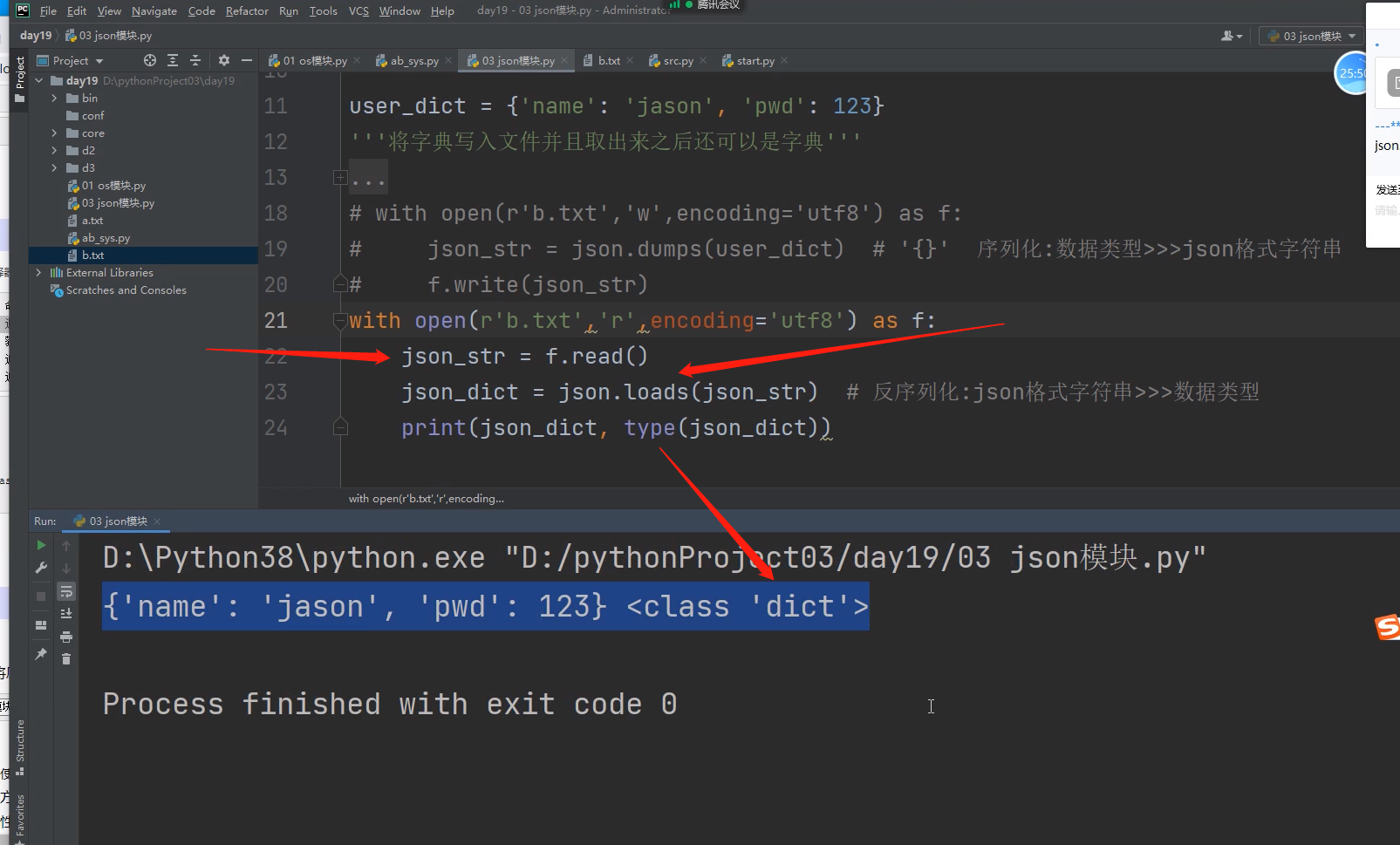
with open(r'a.txt','w',encoding = 'utf8') as f: # 打开文件
json_str = json.dumps(dict1) # dict1转为json格式字符串
f.write(json_str) # 将json格式字符串写入文件
上两步也可以简写为 json.dump(dict1,f) # 注意这个地方已经变成dump了,没有s了
# 等同于上面两部操作,dict转为json类型的字符串后,并写入文件
with open(r'a.txt','r',encoding = 'utf8') as f: # 打开文件
json_str = f.read() #上面存进去的是json格式的字符串,所以读出的也是json格式的字符串
dict1 = json.loads(json_str) # 将json格式字符串反序列化,变成再转为字典格式!!!
上两步也可以简写为 json.load(f) # 注意这个地方已经变成load了,没有s了
# 文件读出来后,反序列化,变成字典!!!
针对文件
json.dump()
json.load()
该方法在文件里面的数据是一个整体的json数据类型的时候比较好用,如果是多个json数据类型的时候不太好用!!!
推荐将其他的json数据类型放到其他的文件里面去!!!!

.
.
双引号是json格式字符串的标志!!!!!!
.
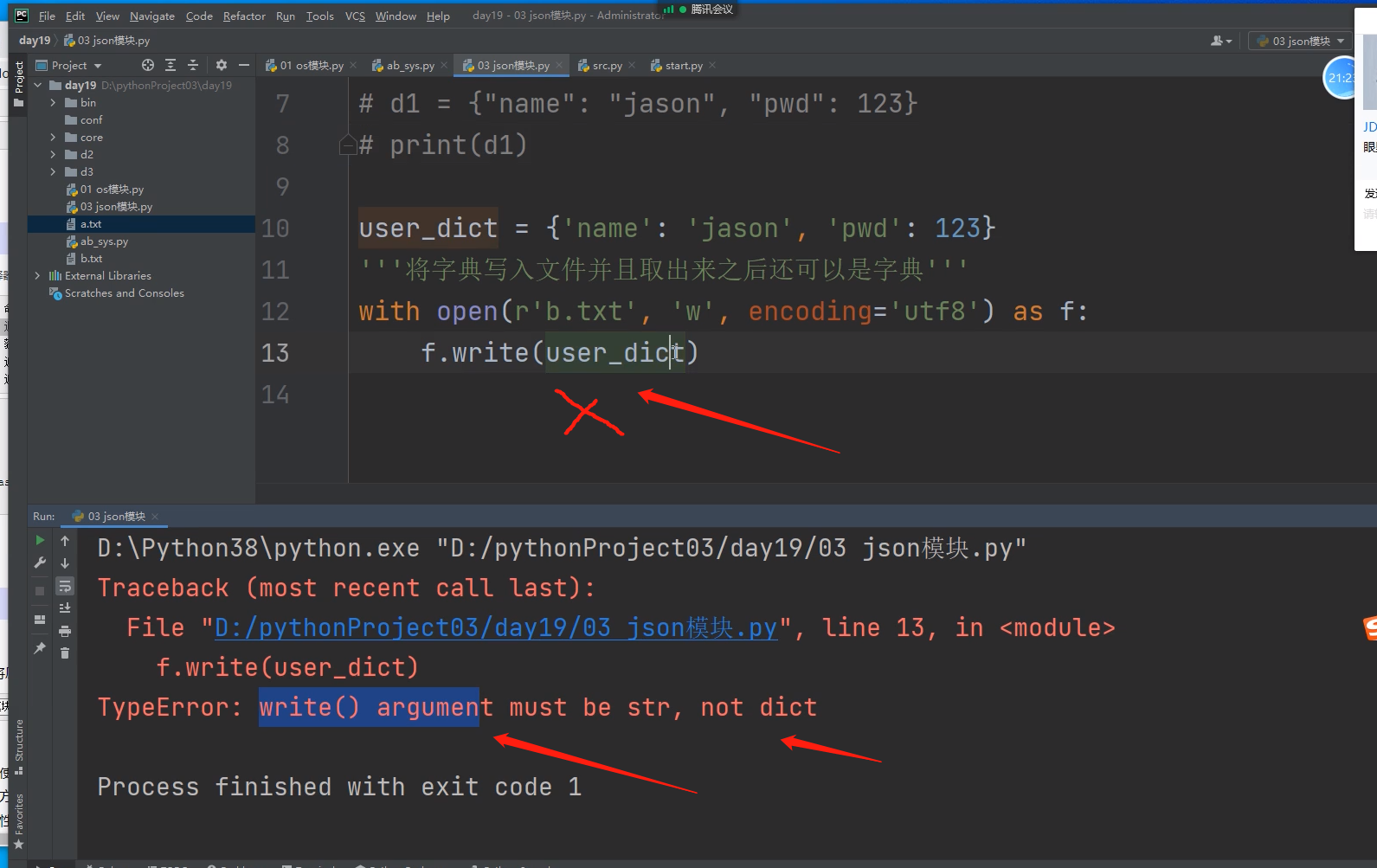
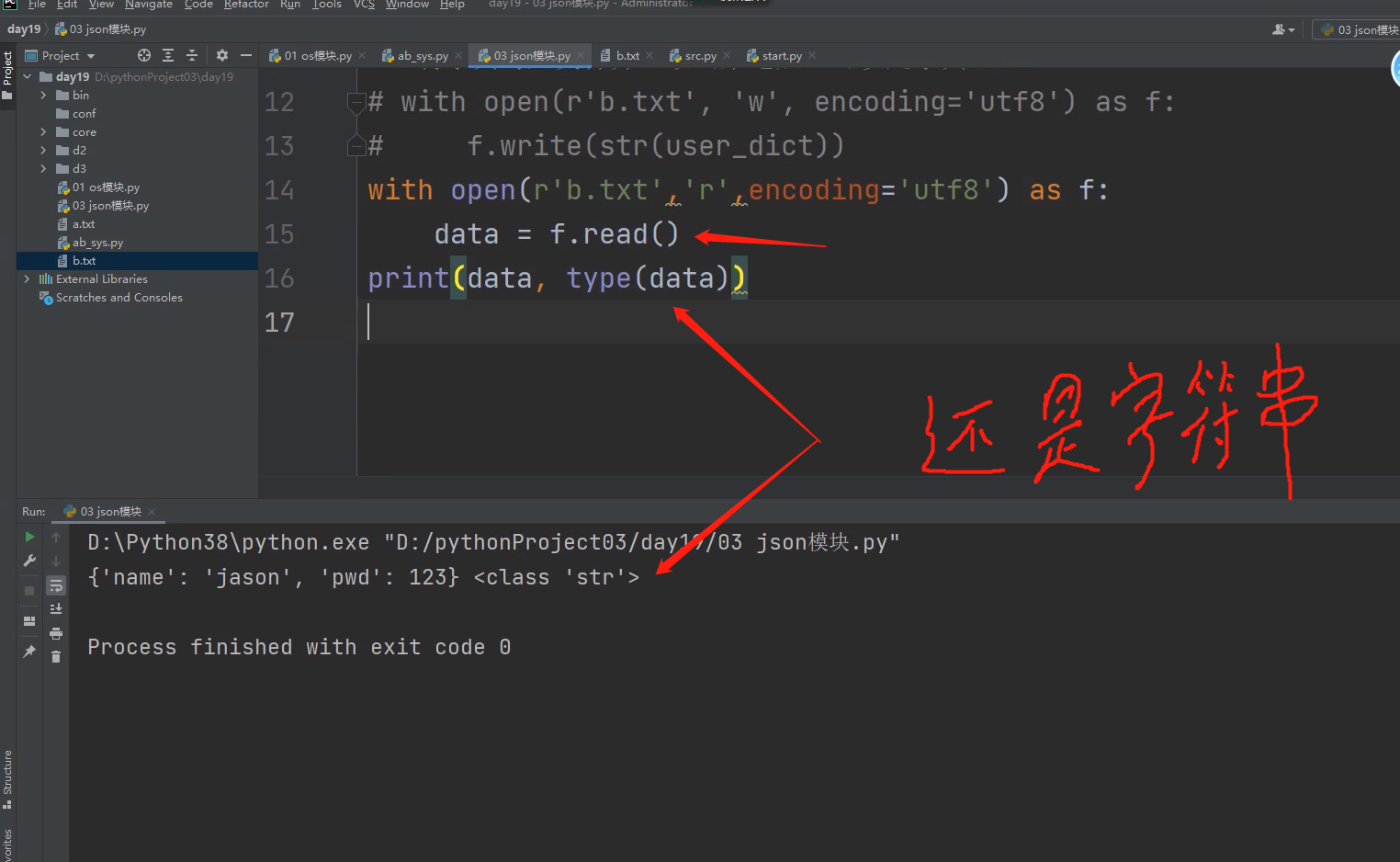
文本文件打开后,写入也是要以字符串的形式写入,不能以字典的形式将数据写入文本文件里面去
.
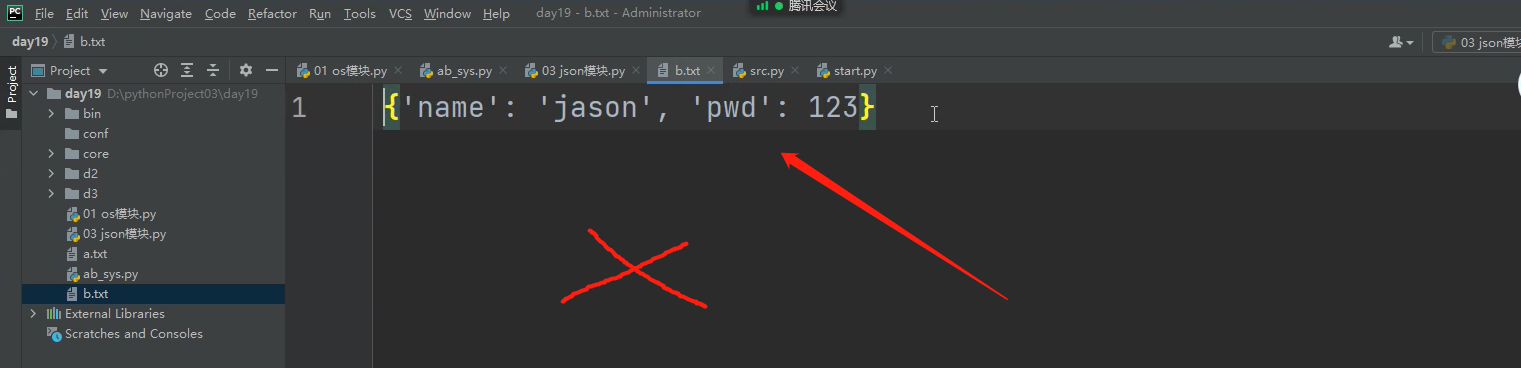
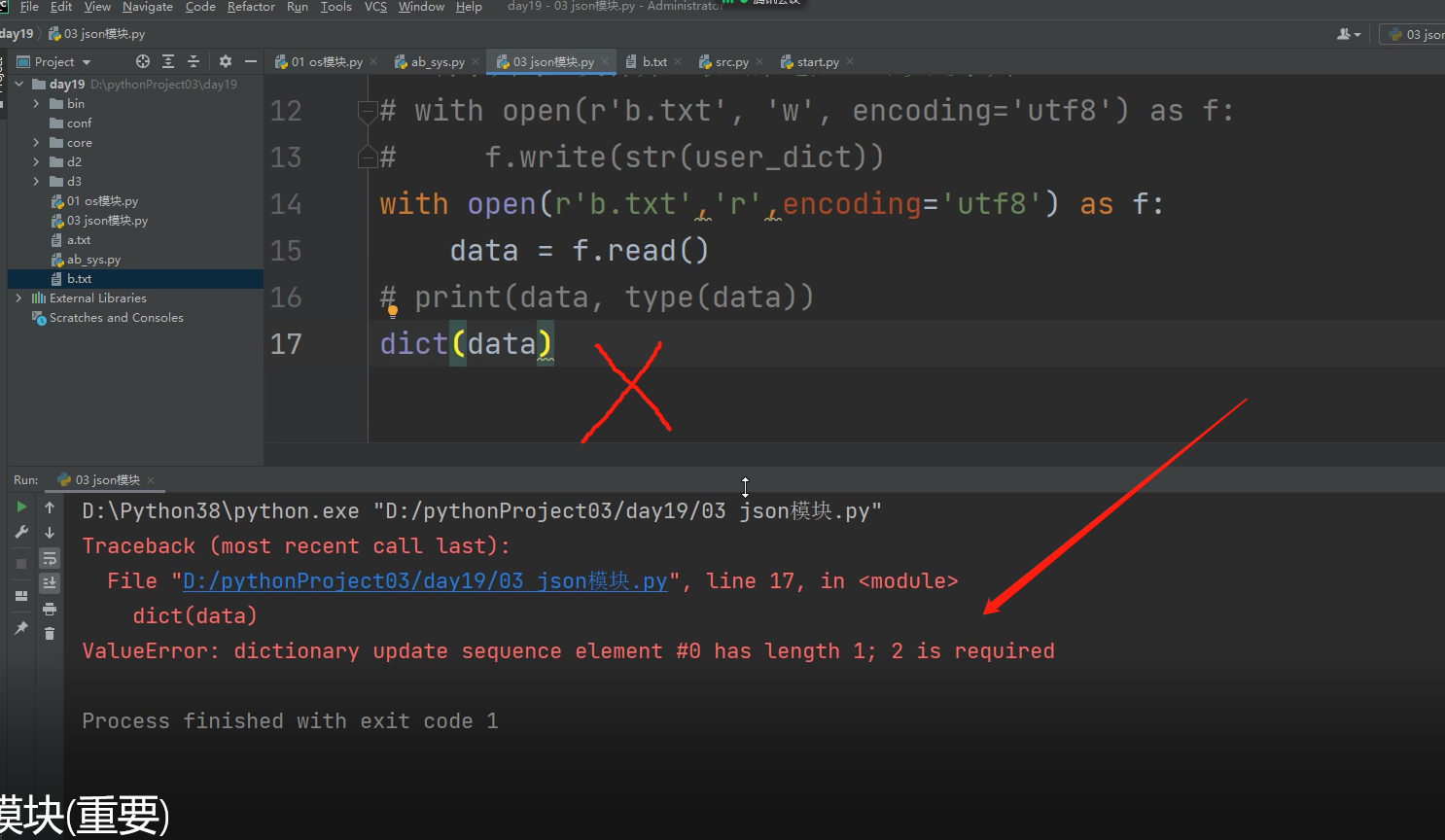
就算把字典转为字符串往文本里面写,还是有问题!!!

写进去后,去不好取,用dict的方法将字符串转字典很不好操作!!!!!
.
.
字符串转字典很难转!!!
.
先转json格式,再写入文本文件,
.
先将json格式字符串反序列化,再转为字典格式!!!
.
.
.
.
.
.
.
json模块实战 重要!!!!!!
用户登录注册功能
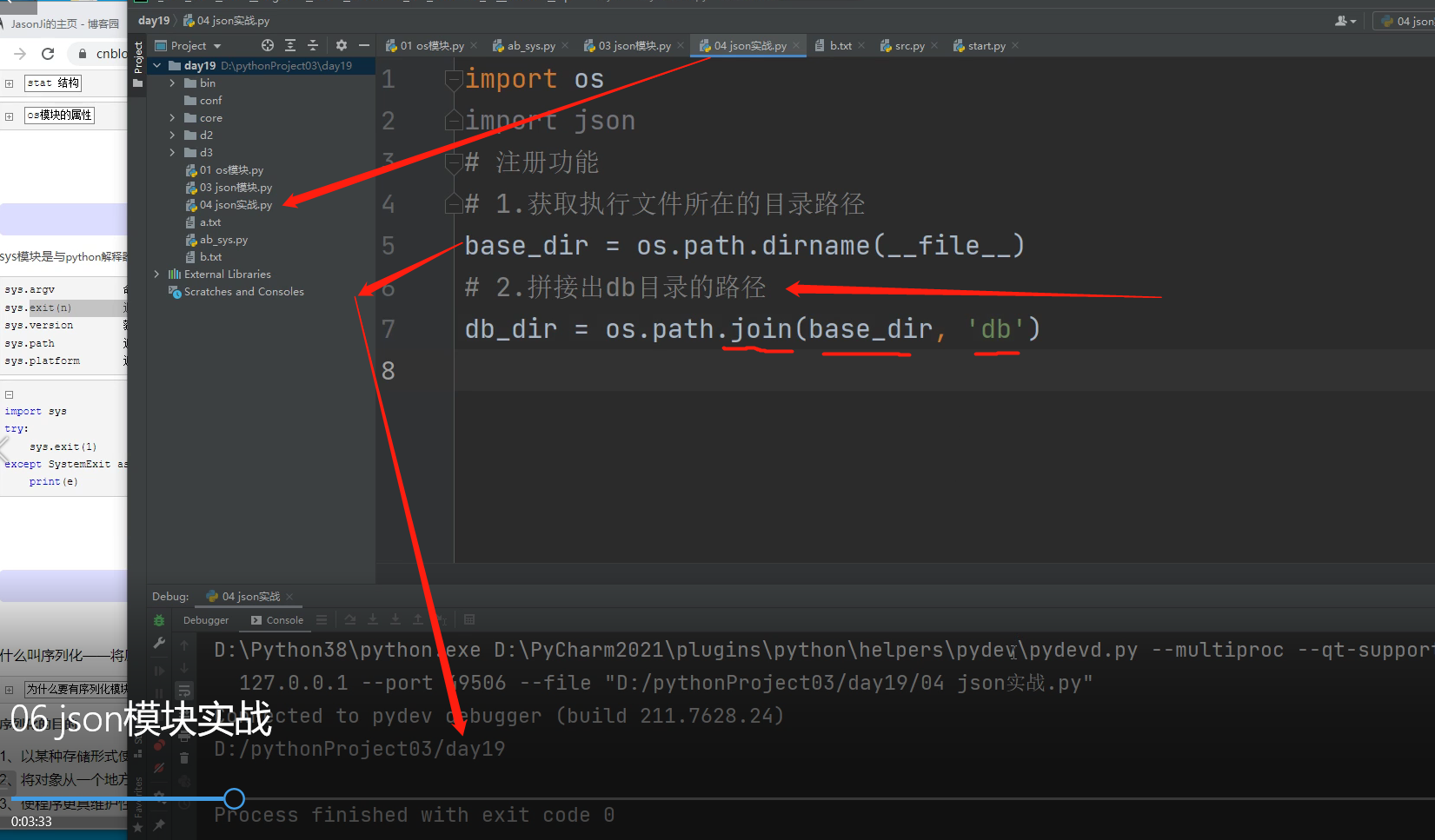
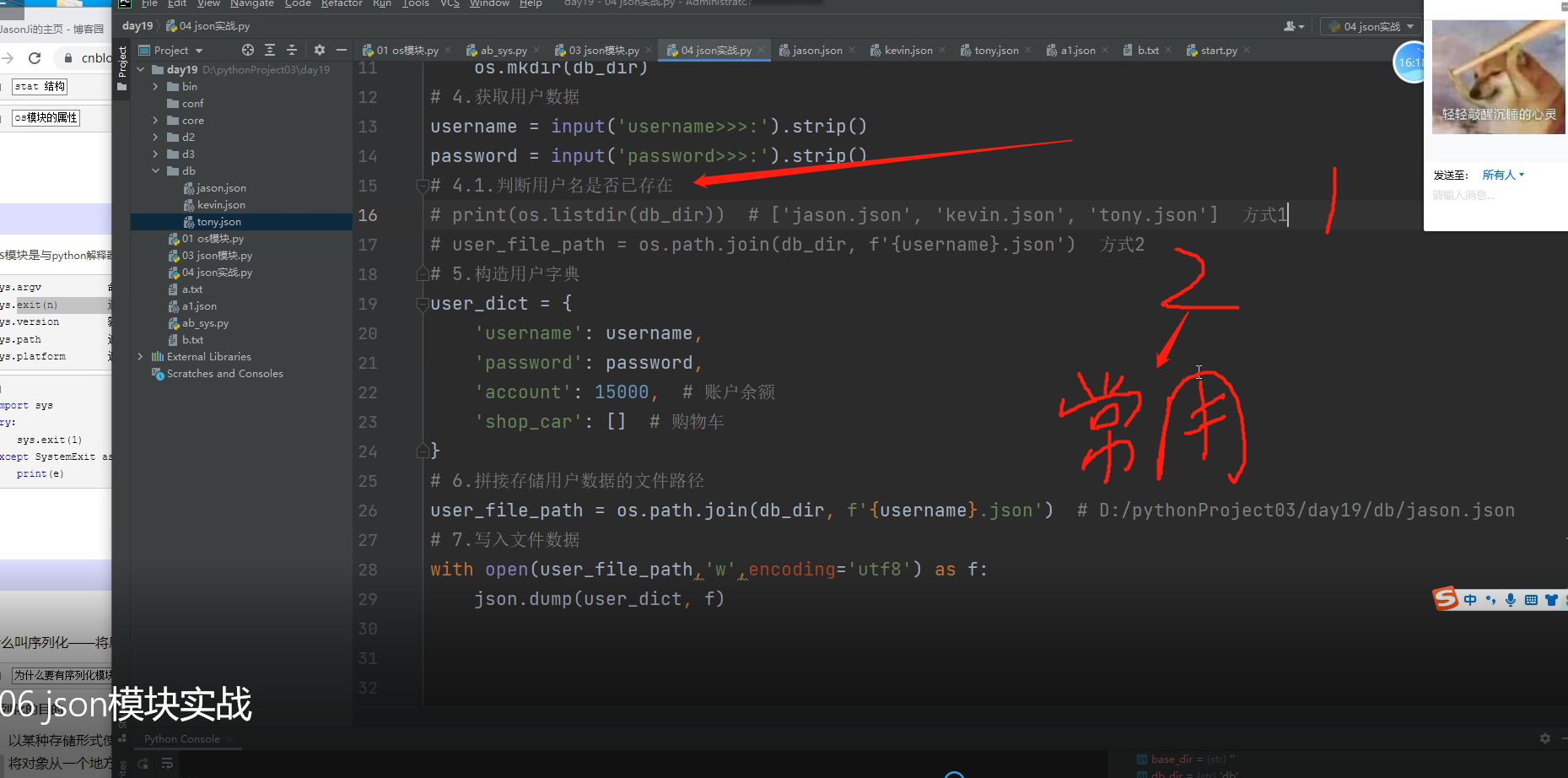
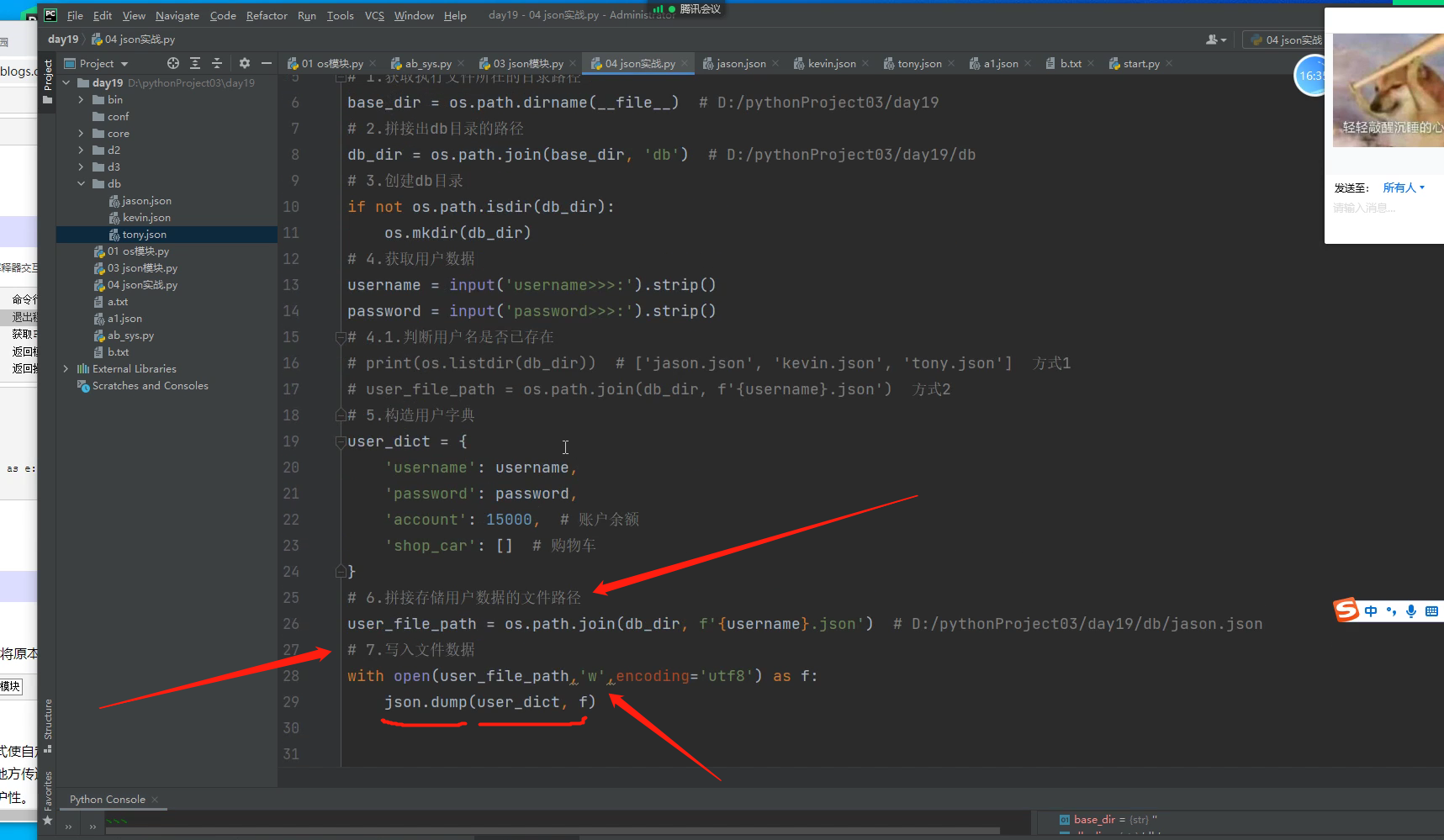
import os
import json # 先导入两个模块
# 注册功能
# 1.获取执行文件所在的目录路径, 此时执行文件在项目day19目录下
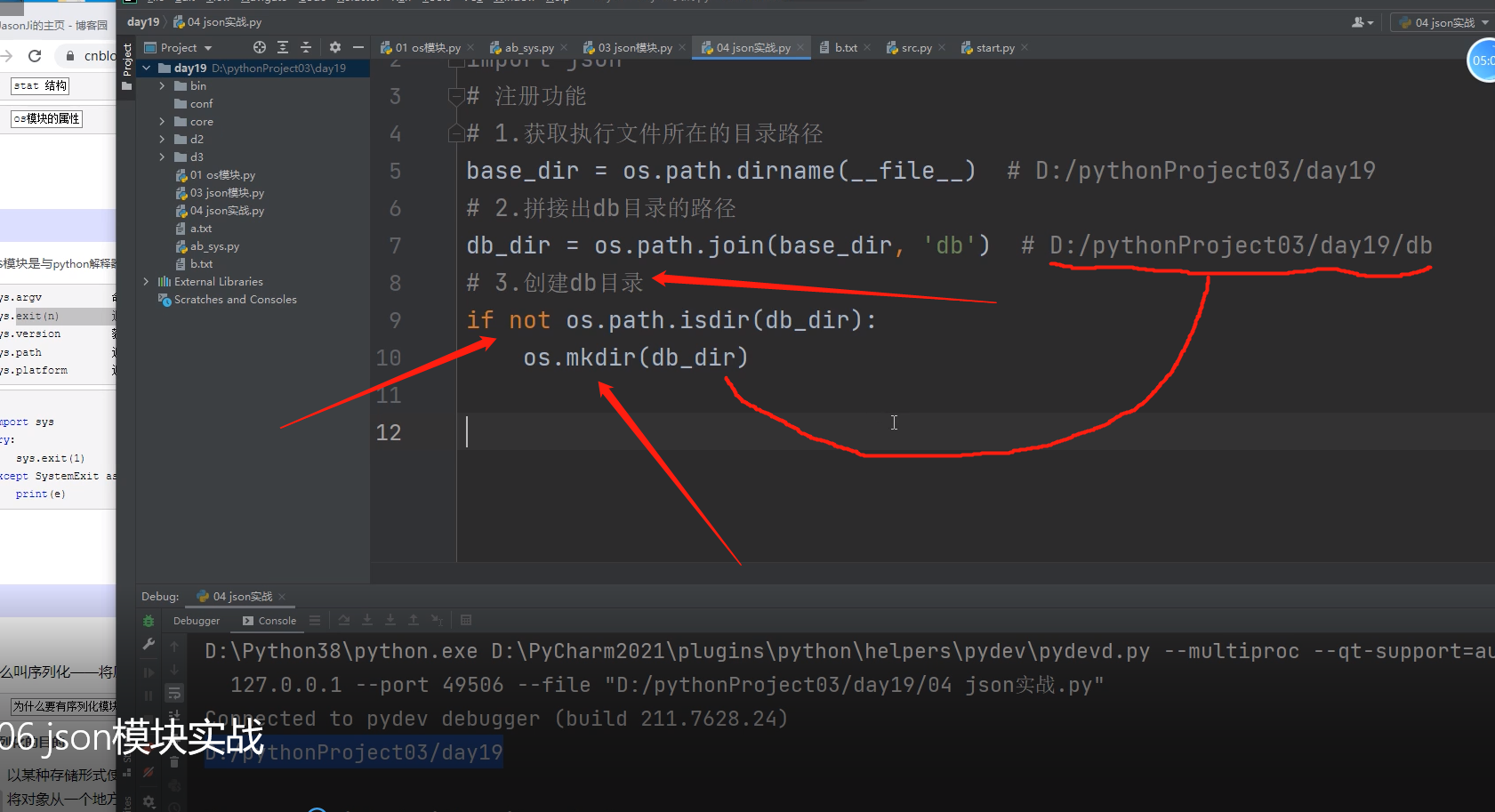
base_dir = os.path.dirname(__file__) # D:/pythonProject03/day19
# 2.拼接出db目录的路径
db_dir = os.path.join(base_dir, 'db') # D:/pythonProject03/day19/db
# 3.创建db目录
if not os.path.isdir(db_dir):
os.mkdir(db_dir)
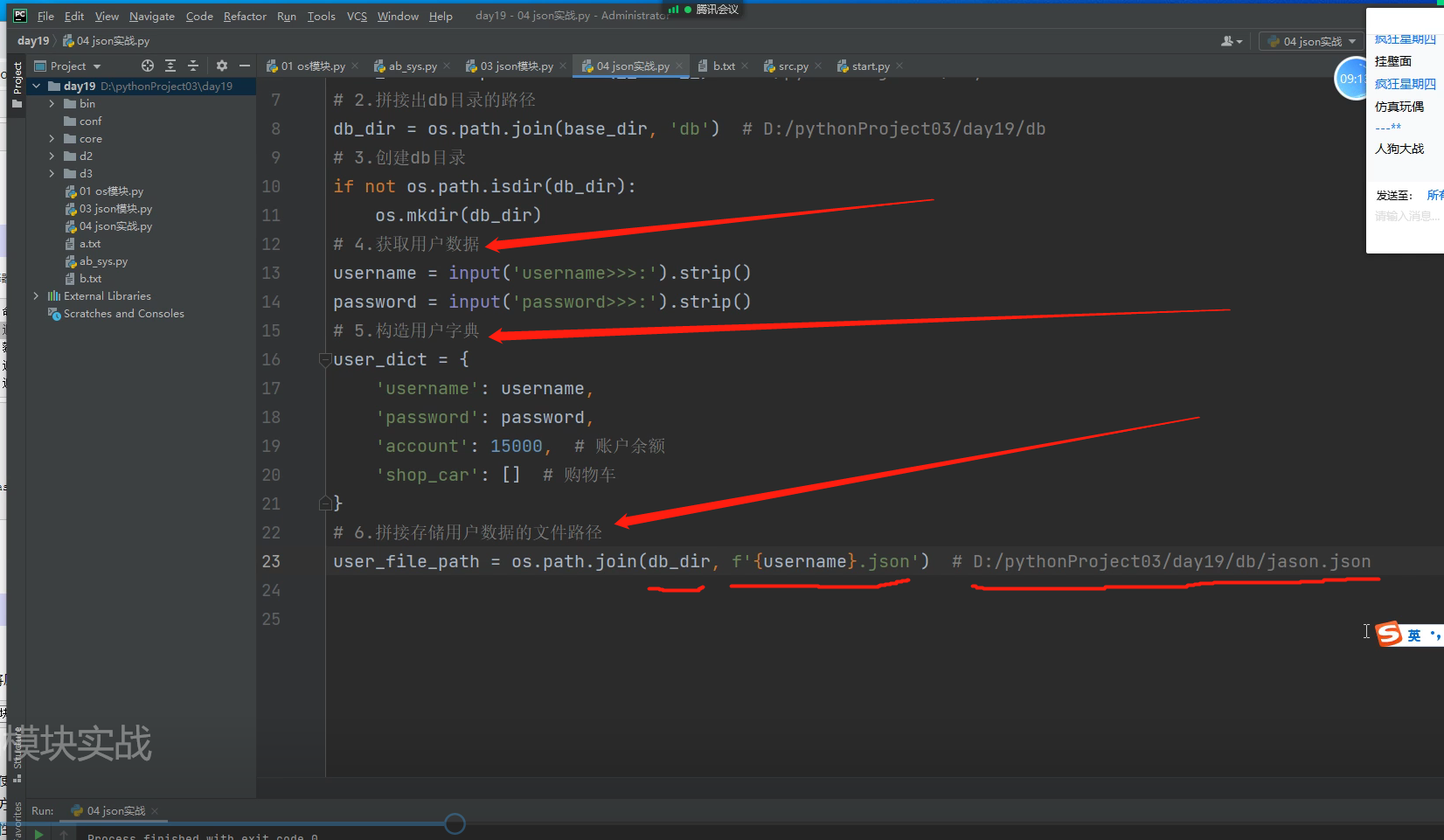
# 4.获取用户数据
# username = input('username>>>:').strip()
# password = input('password>>>:').strip()
# 4.1.判断用户名是否已存在
# print(os.listdir(db_dir)) # ['jason.json', 'kevin.json', 'tony.json'] 方式1
# user_file_path = os.path.join(db_dir, f'{username}.json') 方式2
# 5.构造用户字典
# user_dict = {
# 'username': username,
# 'password': password,
# 'account': 15000, # 账户余额
# 'shop_car': [] # 购物车
# }
# 6.拼接存储用户数据的文件路径
# user_file_path = os.path.join(db_dir, f'{username}.json') # D:/pythonProject03/day19/db/jason.json
# 7.写入文件数据
# with open(user_file_path,'w',encoding='utf8') as f:
# json.dump(user_dict, f)
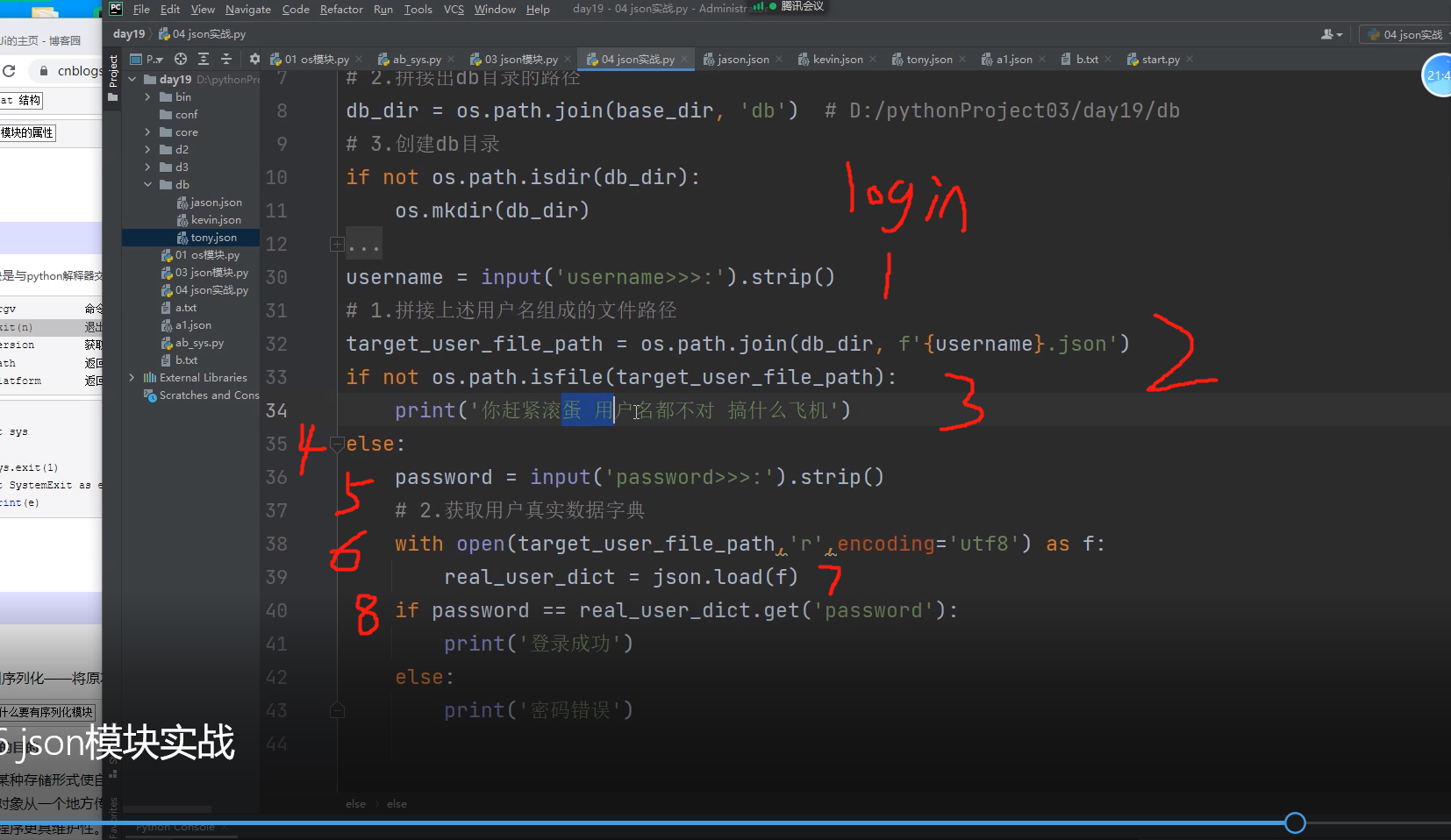
username = input('username>>>:').strip()
# 1.拼接上述用户名组成的文件路径
target_user_file_path = os.path.join(db_dir, f'{username}.json')
if not os.path.isfile(target_user_file_path):
print('你赶紧滚蛋 用户名都不对 搞什么飞机')
else:
password = input('password>>>:').strip()
# 2.获取用户真实数据字典
with open(target_user_file_path,'r',encoding='utf8') as f:
real_user_dict = json.load(f)
if password == real_user_dict.get('password'):
print('登录成功')
else:
print('密码错误')
.
if先判断db文件夹存不存在,如果不存在,则创建db文件夹!!!
.
.
怎么判断用户名存不存在?
有两种方法
第一种是先用os.listdir()方法,获取db文件下的文件名称,
所有文件名称在一个列表里面,可以for循环出来,再.strip('.json'),
这个时候可以拿获取的用户输入的用户名与循环出的文件名比较判断,
当然也可以将获取的用户名加上.json后,再与db文件夹下的文件名比较,都可以
第二种是用os.join()方法将用户名与db文件的目录路径拼接一下,拼成一个完整的路径出来,
然后再判断这个拼接出来的路径是不是已经存在了,如果已经存在了,说明该用户名已经注册过了!!!
一般常用第二种方法!!!!!!
.
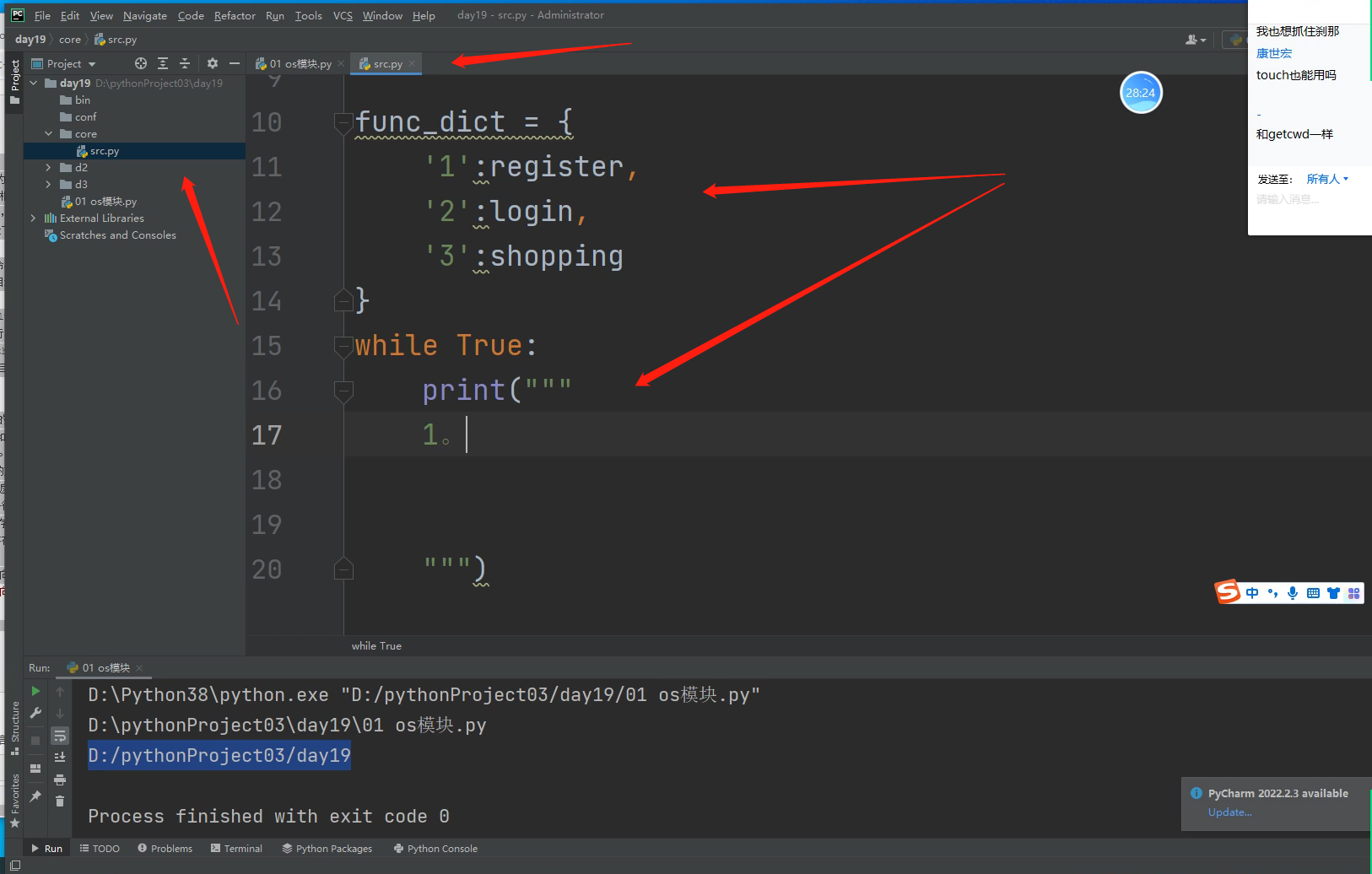
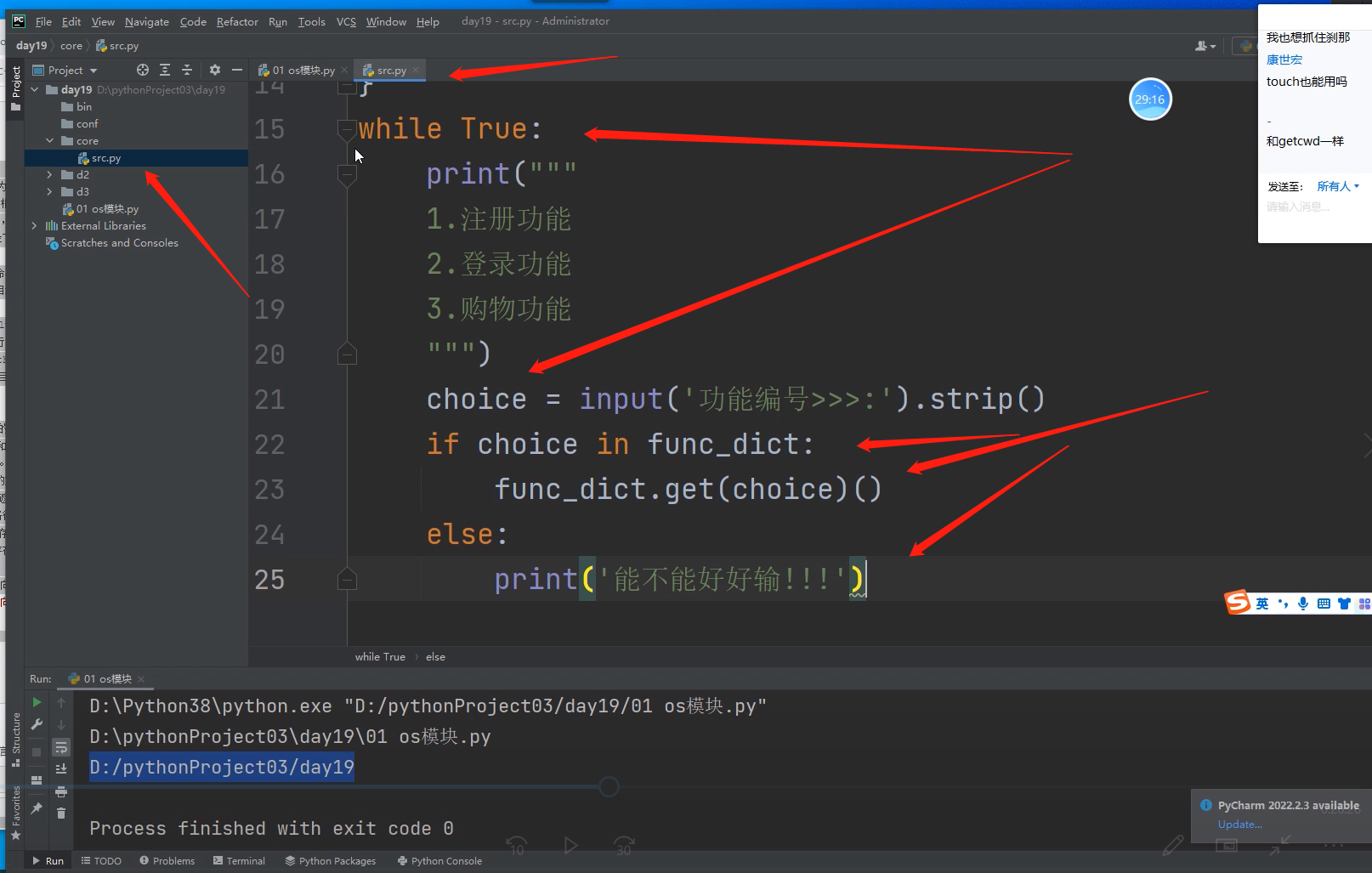
这样一个注册功能就大概写好了
.
再开始写登录功能
.
.
.
.
.
创建项目流程 重要!!!!!!!!!!!!!!
.
.
.
.
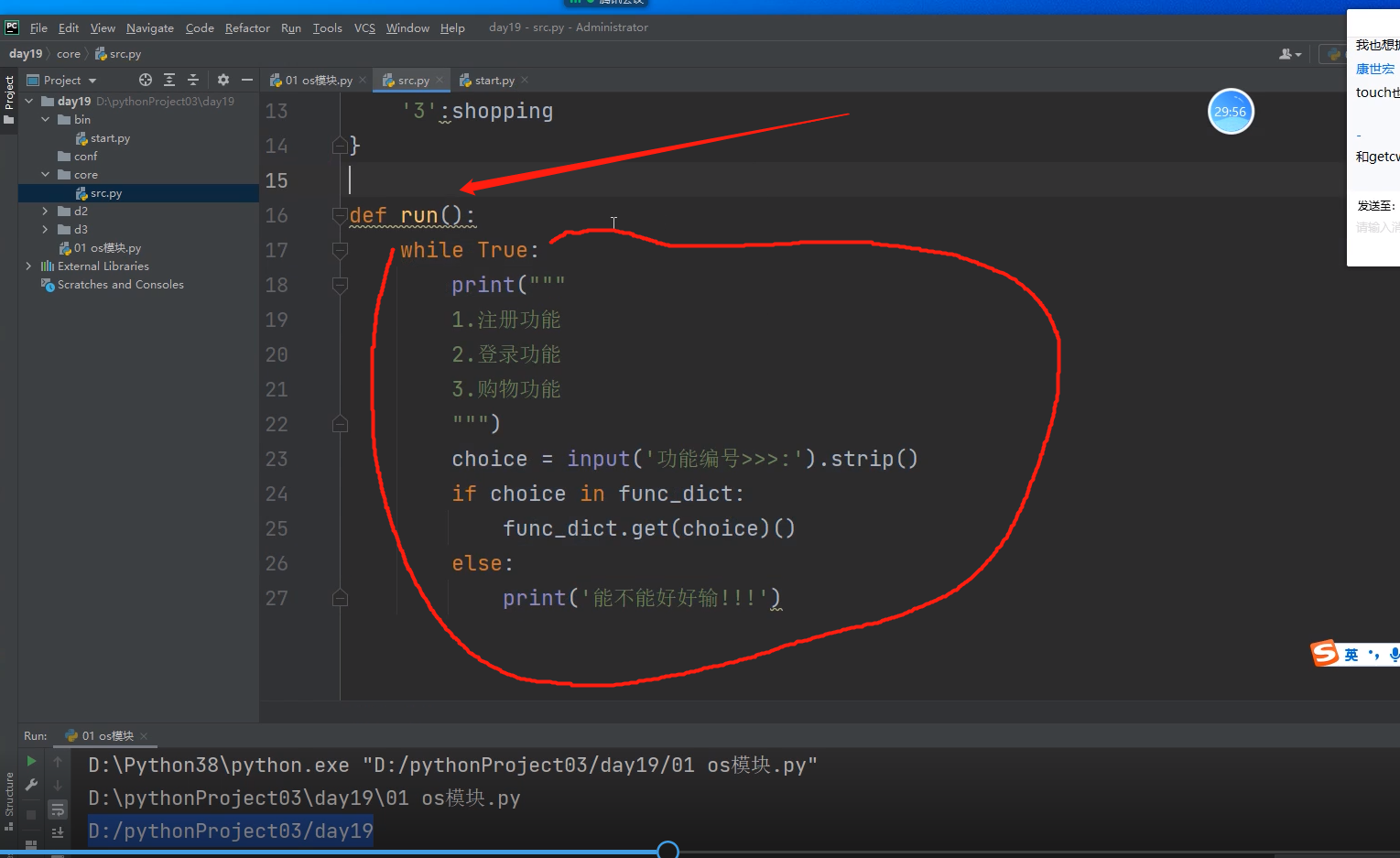
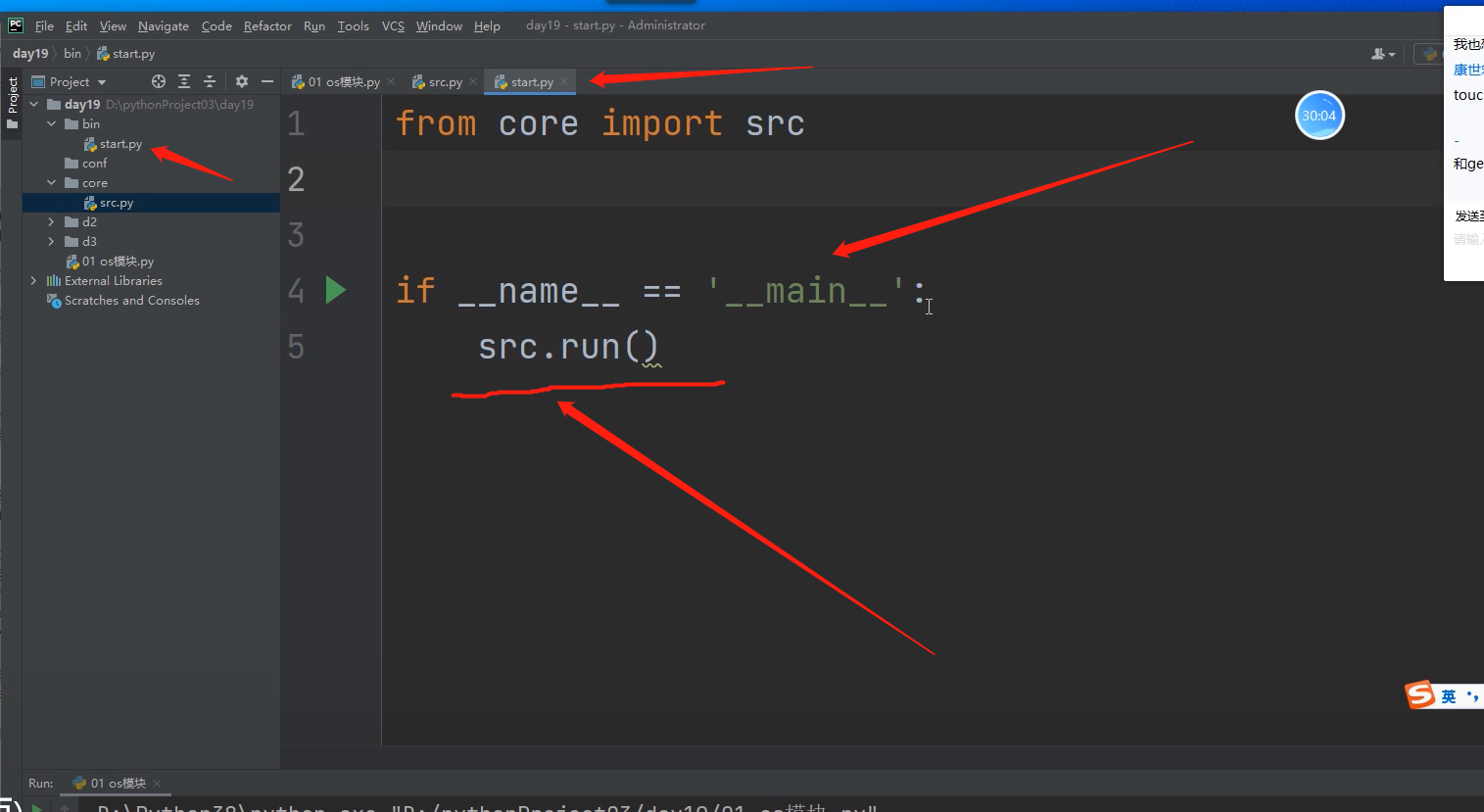
项目框架大体好了
.

.
这个时候有一个问题,在start文件导src模块文件的时候是直接form core import src 导的,
因为pycharm帮我们把项目文件的路径D:\pythonprojecto3\day19,给添加到sys.path环境变量中了,
所以站在day19路径下,是能够看到core文件的!!!所以src的模块文件虽然在core文件下,
依然可以在bin文件下的start文件中进行导入操作!!!
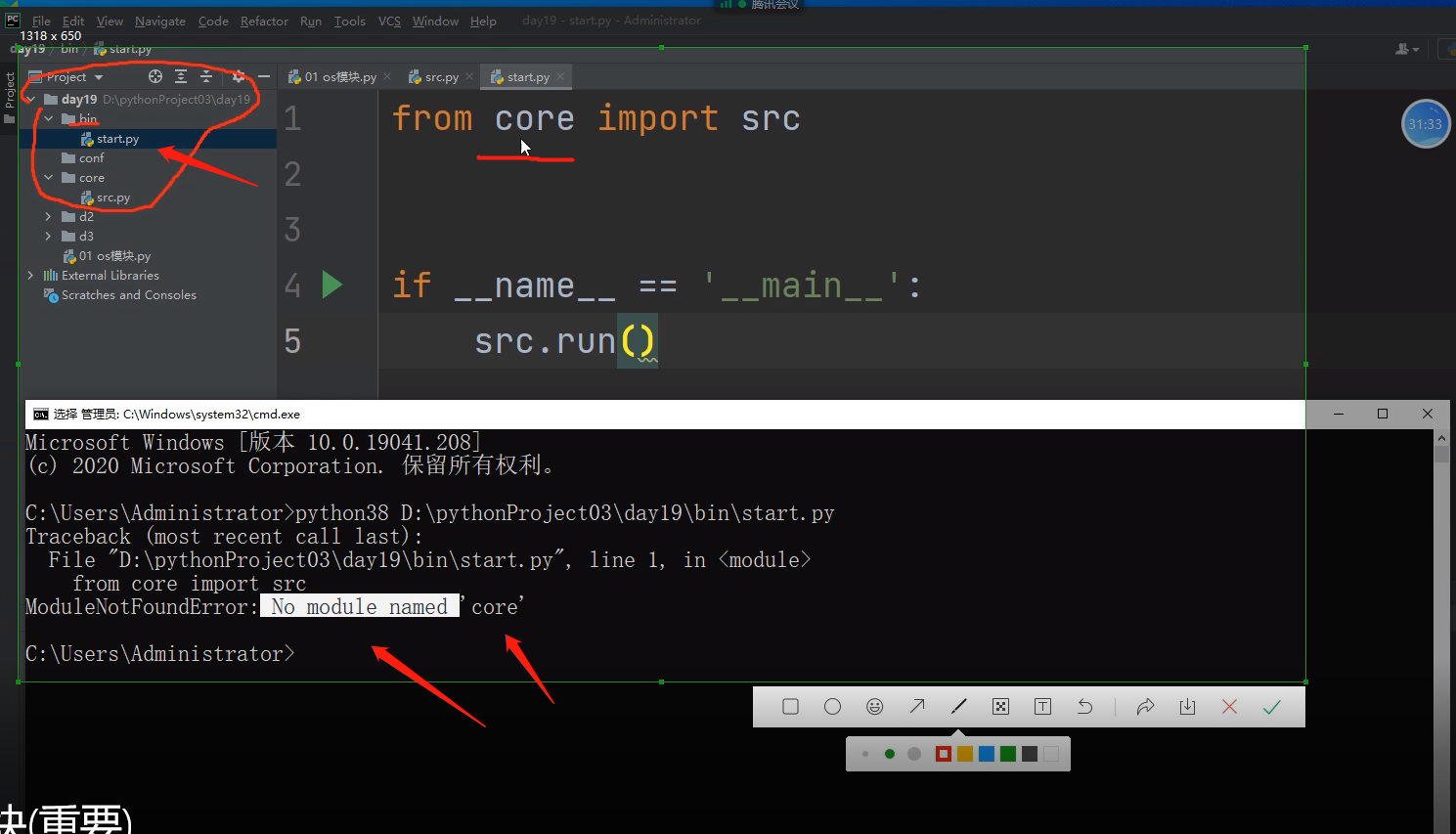
但是同样的代码到python解释器中就运行不起来了!!!
因为如果pycharm不自动添加路径,sys.path是以执行文件所在的路径为准的!!!
此时start文件的路径是D:\pythonprojecto3\day19\bin
站在执行文件路径下,只能看到start文件,无法找到core文件的,所以会报错!!!!!!
.
解决办法,手动将项目的路径复制添加到sys.path里面去
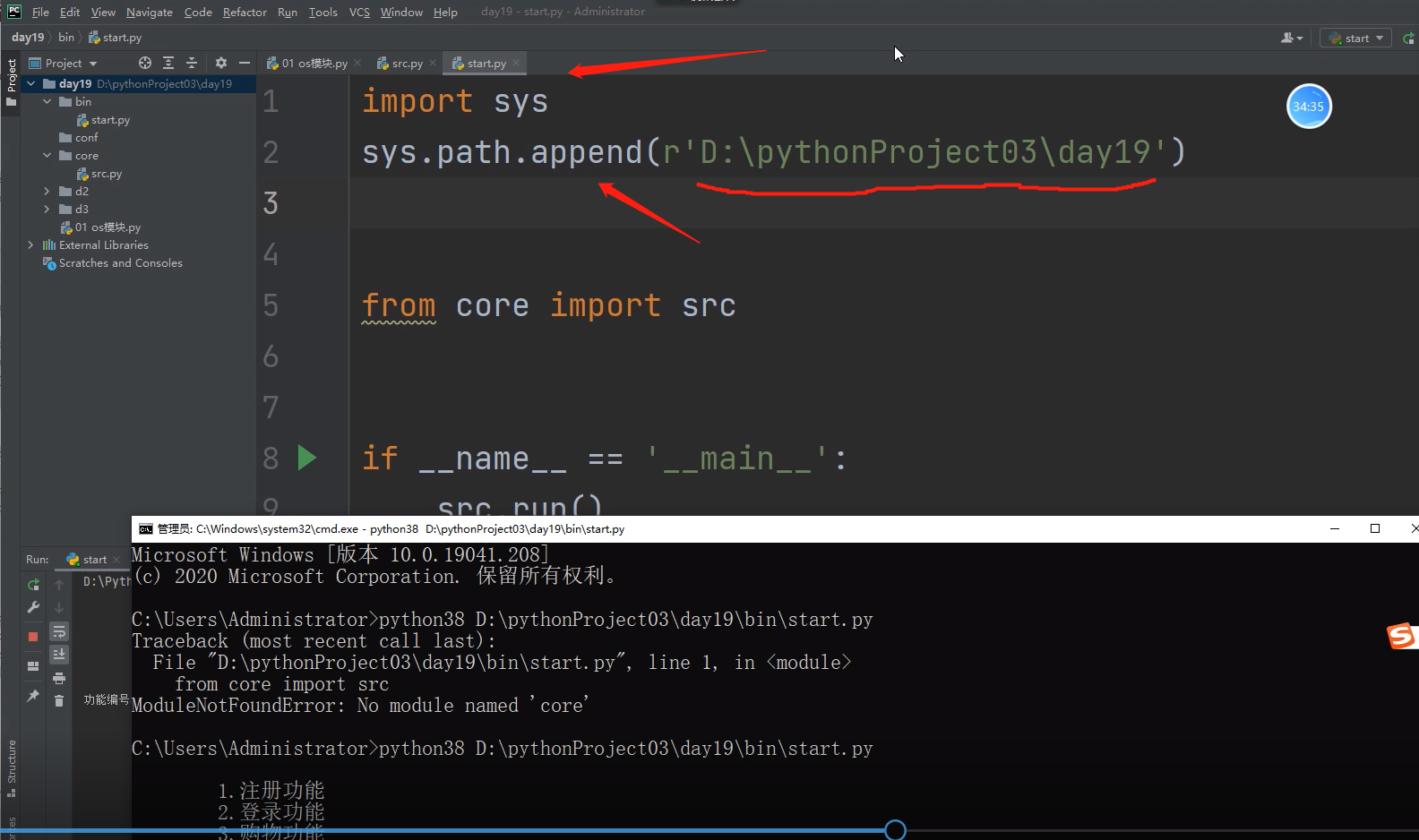
但是将这个文件打包给别认识,别人在运行start文件时,
这个添加的路径和别人的电脑的这个pycharm文件的项目路径很难一致,
那么这个时候这个路径的添加对别人来说就是一个无效添加!!
所以这个地方的项目路径需要动态获取!!!
这时候就需要 os.path.dirname 获取执行文件的目录路径!!!
但这个时候获取的路径里面是包括bin的D:\pythonprojecto3\day19\bin,我们想要的项目文件的路径,
所以该方法嵌套使用一下就可以获取D:\pythonprojecto3\day19路径了!!!
这样这样一个启动文件就大功告成了!!!!!!

.
.
.
.
.
.
作业
1.编写一个统计指定文件类型的脚本工具
输入指定类型的文件后缀
eg:.txt
并给出一个具体路径 之后统计该类型文件在该文件下的个数
ps:简单实现即可 无需优化
2.针对json实操 尝试单文件多用户(一行一个)是否可实现>>>:哪个更方便
不要求完成 单纯体会两种思路的难易
3.编程小练习
有一个目录文件下面有一堆文本文件
eg:
db目录
J老师视频合集
R老师视频合集
C老师视频合集
B老师视频合集
文件内容自定义即可 要求循环打印出db目录下所有的文件名称让用户选择
用户选择哪个文件就自动打开该文件并展示内容
涉及到文件路径全部使用代码自动生成 不准直接拷贝当前计算机固定路径
4.周末大作业(尝试编写)
# 项目功能
1.用户注册
2.用户登录
3.添加购物车
4.结算购物车
# 项目说明
用户数据采用json格式存储到文件目录db下 一个用户一个单独的文件
数据格式 {"name":"jason","pwd":123}
# ps:文件名可以直接用用户名便于校验
用户注册时给每个用户添加两个默认的键值对(账户余额 购物车)
{"balance":15000,"shop_car":{}}
添加购物车功能 商品列表可以自定义或者采用下列格式
good_list = [
['挂壁面',3]
['印度飞饼', 22]
['极品木瓜', 666],
['土耳其土豆', 999],
['伊拉克拌面', 1000],
['董卓戏张飞公仔', 2000],
['仿真玩偶', 10000]
]
用户可以反复添加商品,在购物车中记录数量
{'极品木瓜':[个数,单价]}
结算购物车
获取用户购物车中所有的商品计算总价并结算即可
针对添加购物车和结算只有登录的用户才可以执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号