python第十七课--索引与迭代区别,模块导入,循环导入等问题
昨日内容回顾
-
异常处理的语法结构
try: 待监测的代码(可能会出错的代码) except 具体的错误类型 as e: 具体错误类型对应的解决策略 except Exception as e: 万能异常统一处理策略 else: 待监测的代码没有出错会执行的子代码 finally: 无论发送什么 最后都走的子代码 1.断言 assert 2.主动抛异常 raise -
异常处理的实战应用
1.异常处理的语法结构尽量少用 2.被try监测的代码尽量的少 3.异常处理的使用场景 一些低概率事件无法控制的可能发送的场景 for循环底层代码实现 -
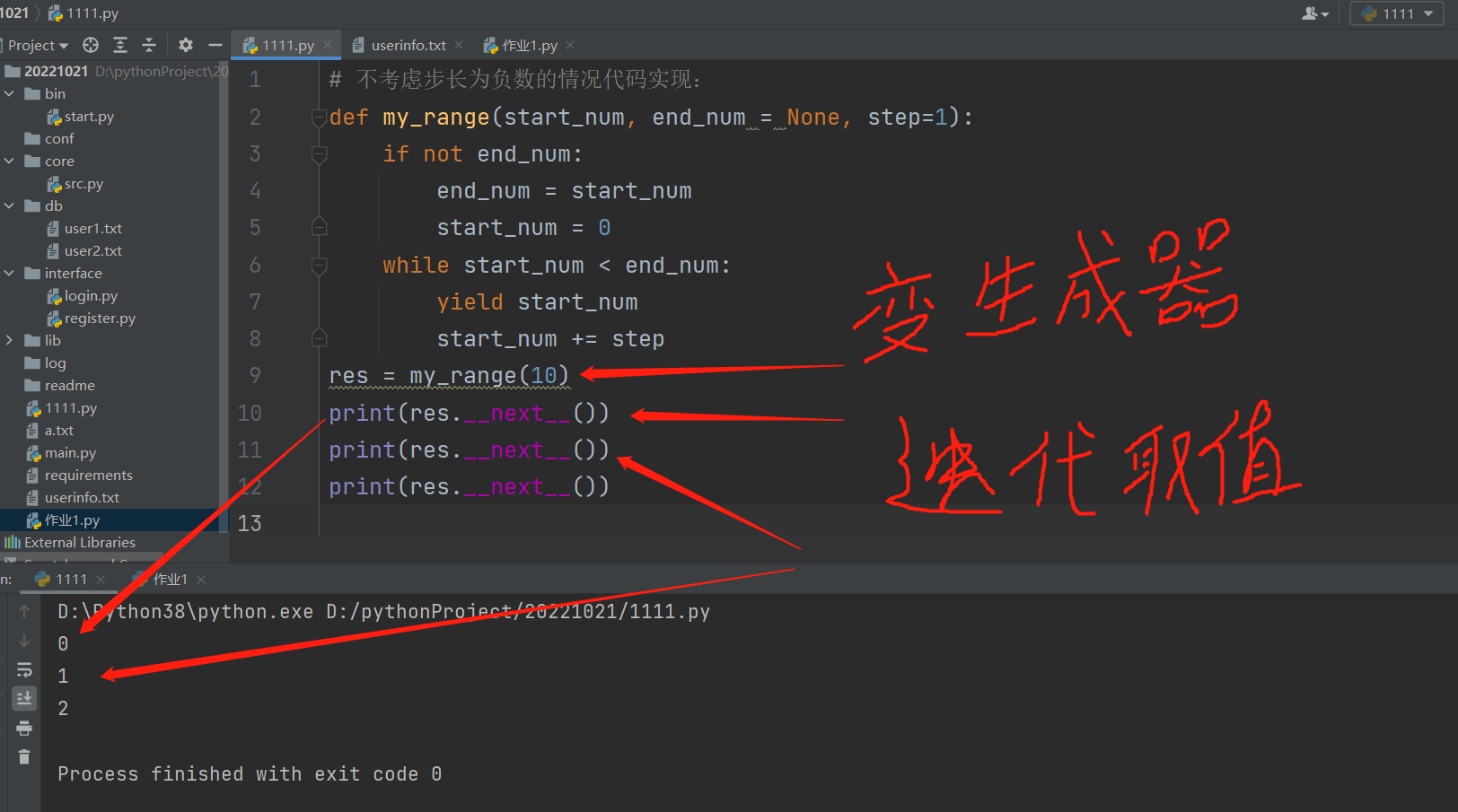
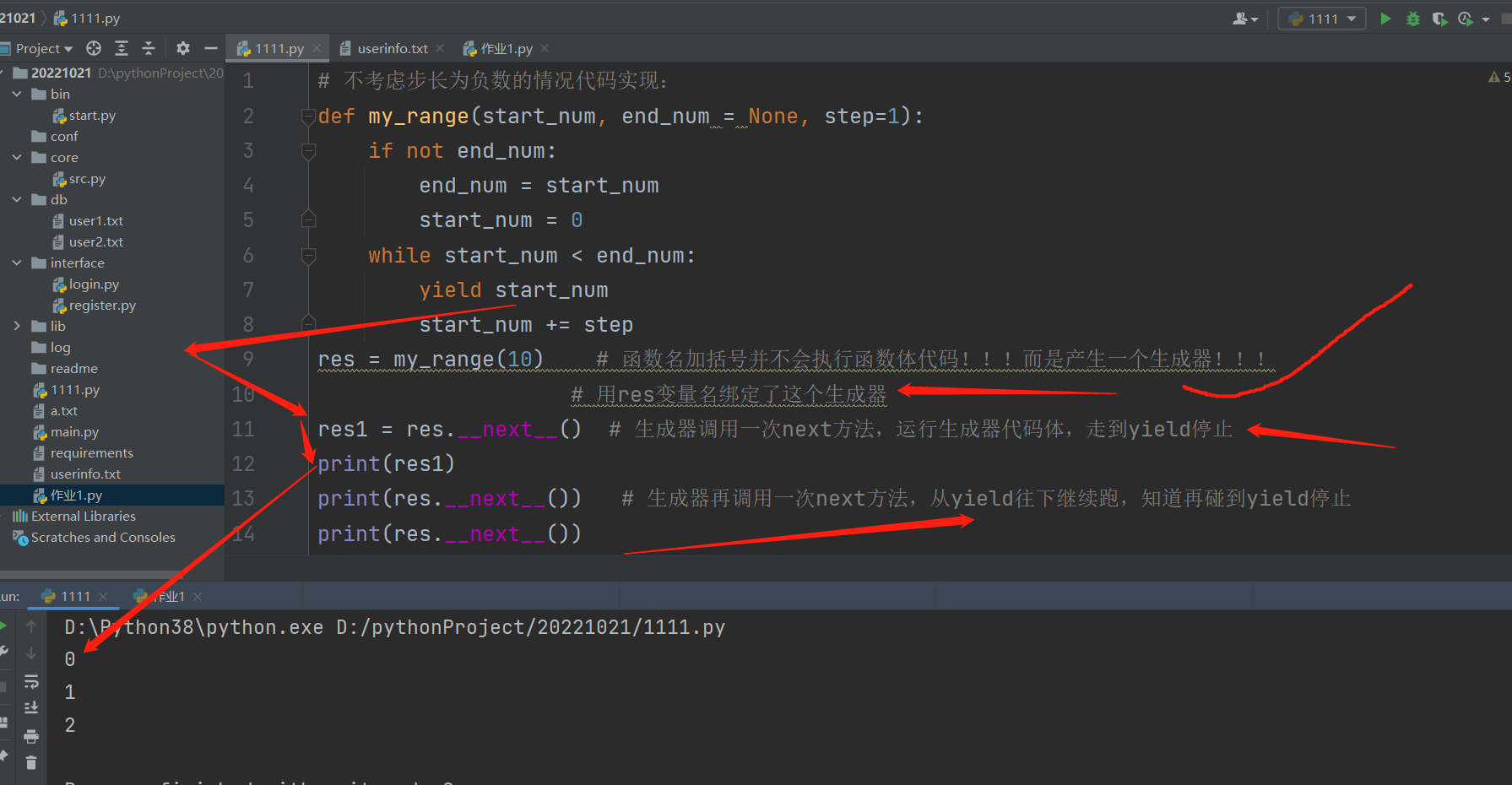
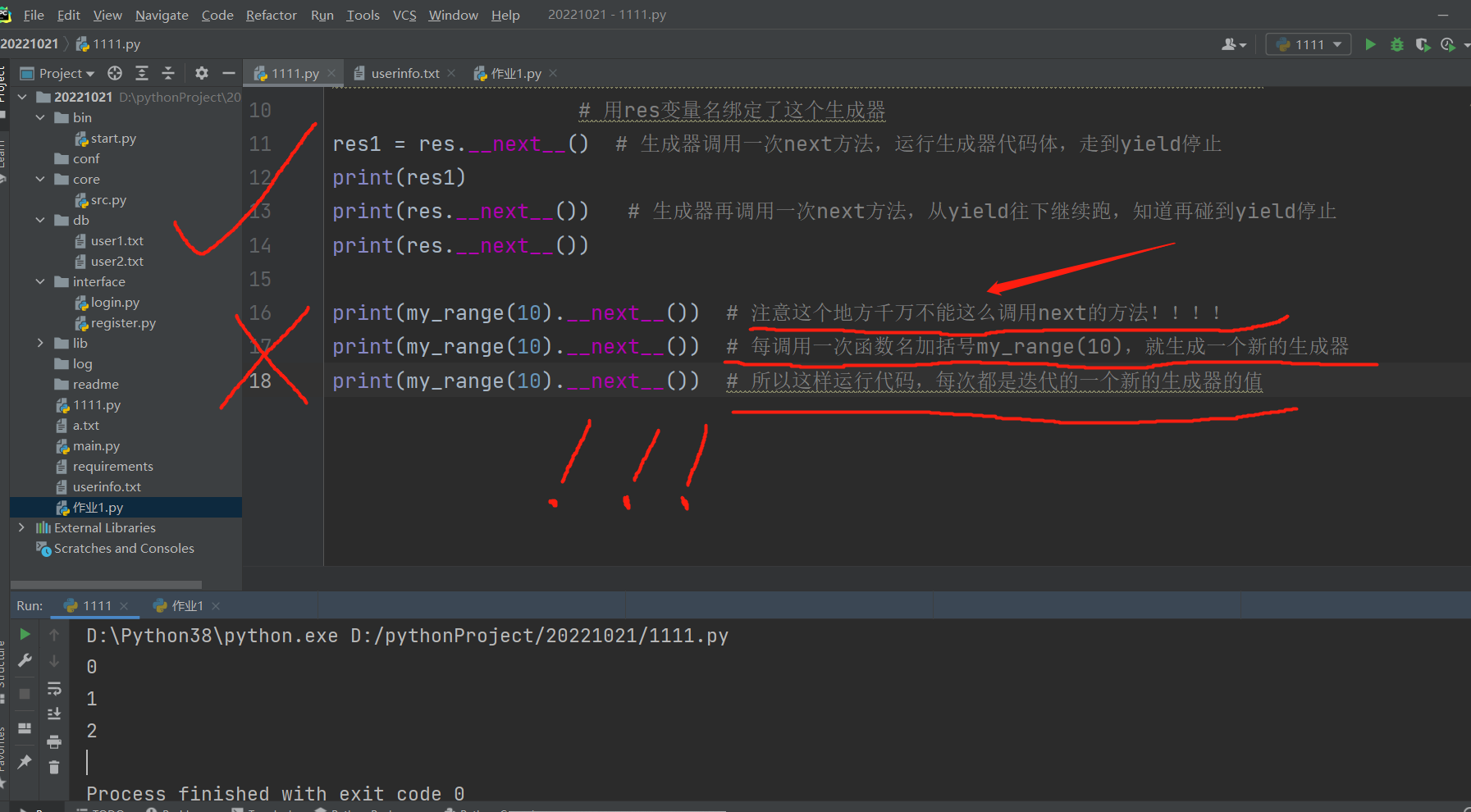
生成器
1.函数体代码内含有关键字yield !!!!! 2.函数名加括号并不会执行函数体代码!!!而是产生一个生成器!!! 3.生成器对象执行双下next才会走函数体代码并且遇到yield就停顿!!!!!! 4.yield关键字的功能: 停顿代码 返回数据值 接收外部数据
.
.
-
自定义range方法
两个参数 一个参数 三个参数 -
yield冷门用法
生成器对象.send() 将send括号里面的数据传给yield前面的变量名,并再次调用双下next方法的 -
生成器表达式
生成器表达式其实也是简化写法
1.简化代码
2.节省内存
> # 今日内容概要
* 索引取值与迭代取值的差异
* 模块简介
* 导入模块的两种句式
* 导入模块的句式补充
* 循环导入问题及解决策略
* 判断文件类型
* 模块的查找顺序
* 模块的绝对导入与相对导入
> # 今日内容详细
### 索引取值与迭代取值的差异
```python
l1 = [11, 22, 33, 44, 55]
1.索引取值
可以任意位置,任意次数取值
不支持无序类型的数据取值
2.迭代取值
只能从前往后依次取值,无法后退
支持所有类型的数据取值(无序与有序)
ps:两者的使用需要结合实际应用场景
.
.
.
.
.
.
模块简介
1.模块的本质
内部具有一定的功能(代码)的py文件
2.python模块的历史
python刚开始的时候所有搞其他编程语言的程序员都看不起 甚至给python起了个外号>>>:调包侠(贬义词)
随着时间的发展项目的复杂度越来越高 上面那帮人也不得不用一下python 然后发现真香定律>>>:调包侠(褒义词)
3.python模块的表现形式
1.py文件(py文件也可以称之为是模块文件)
2.含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
3.已被编译为共享库或DLL的c或C++扩展(了解) 就是 第三方插件
4.使用C编写并链接到python解释器的内置模块(了解) 就是 内置模块
.
.
.
.
模块的分类
1.自定义模块
我们自己写的模块文件
2.内置模块
python解释器提供的模块
3.第三方模块
别人写的模块文件(python背后真正的大佬)
.
.
.
.
.
导入模块的两种句式
"""
强调:
1.一定要搞清楚谁是执行文件 谁是被导入文件!!!!!
2.以后开发项目的时候py文件的名称一般是纯英文
不会含有中文甚至空格,也不要命名为纯数字,模块名命名成纯数字后,在其他执行文件里面会出现无法导入的情况!!!!!
test.py views.py 出现
3.导入模块文件不需要填写后缀名 只需要写文件名就行了
"""
--------------------------------------------------------
#### 1.import句式 导入py文件
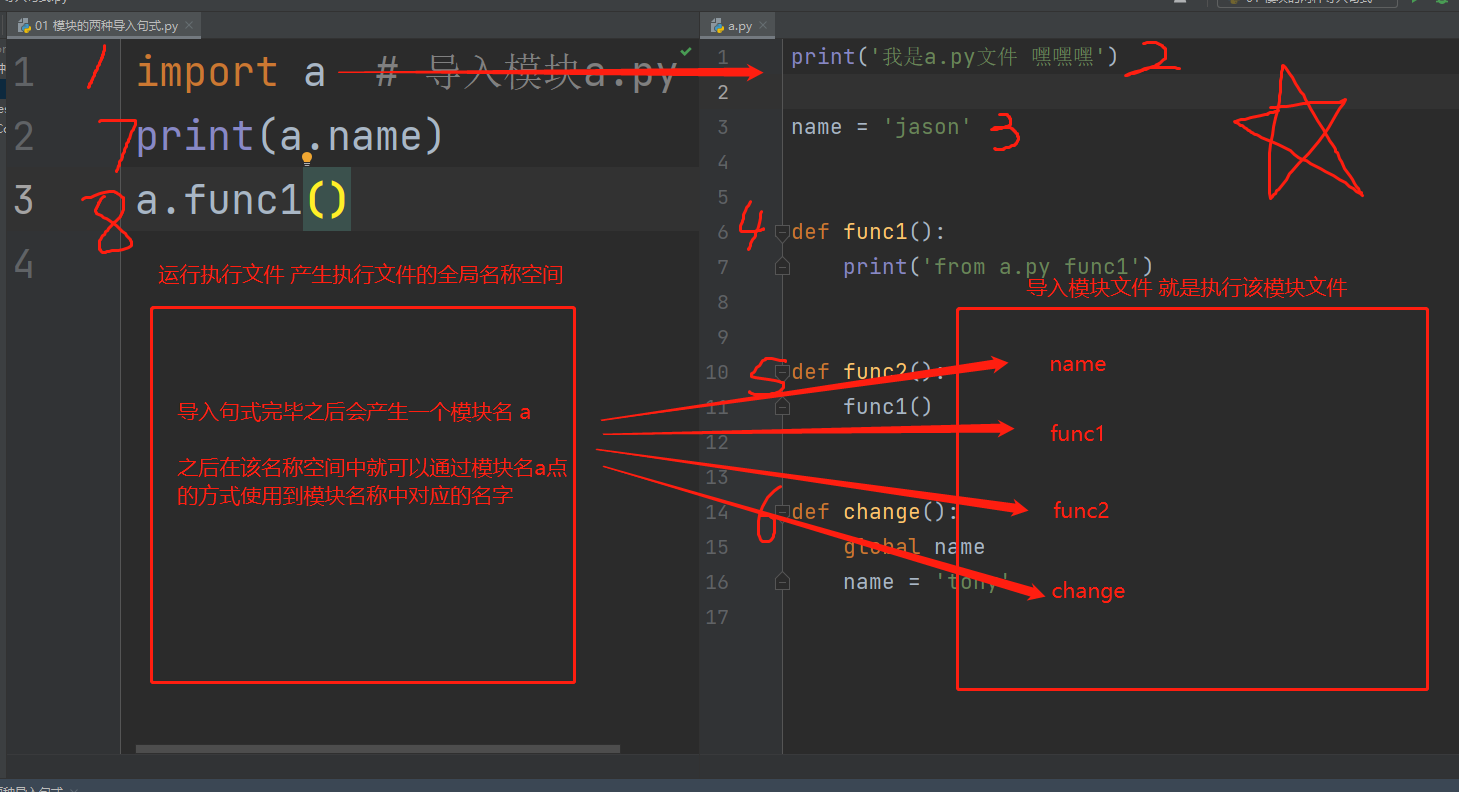
import有进口,输入的意思,这里译为导入
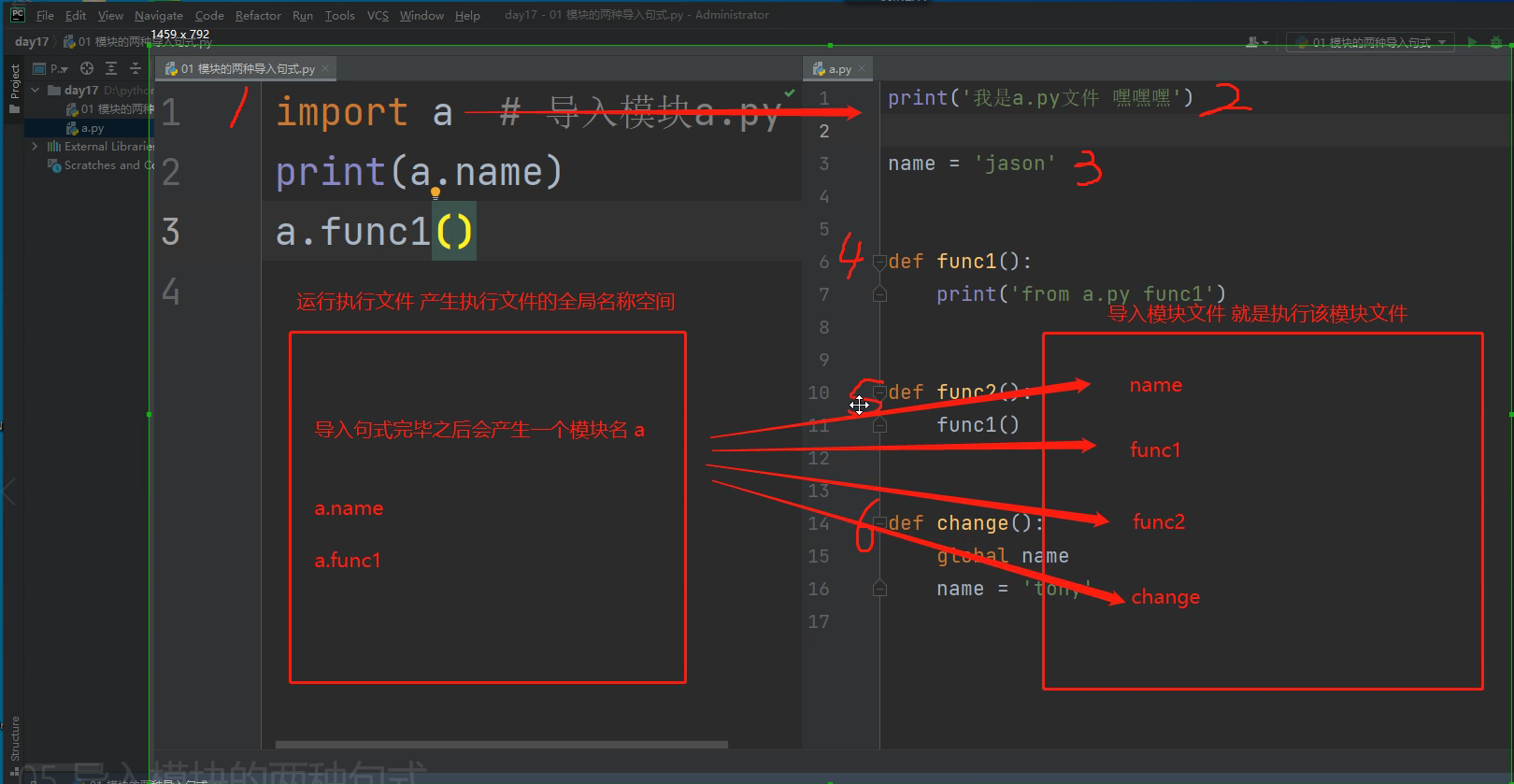
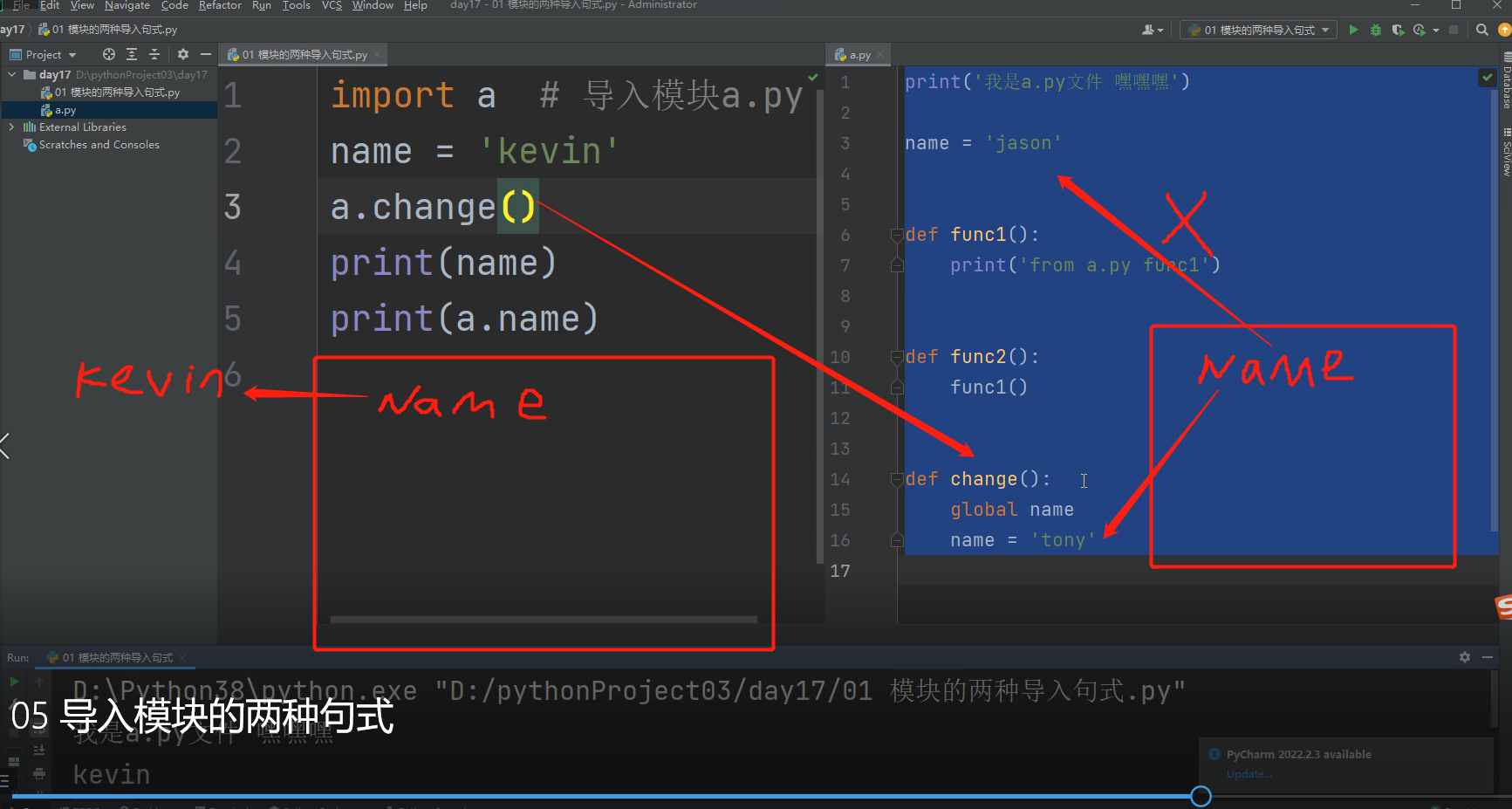
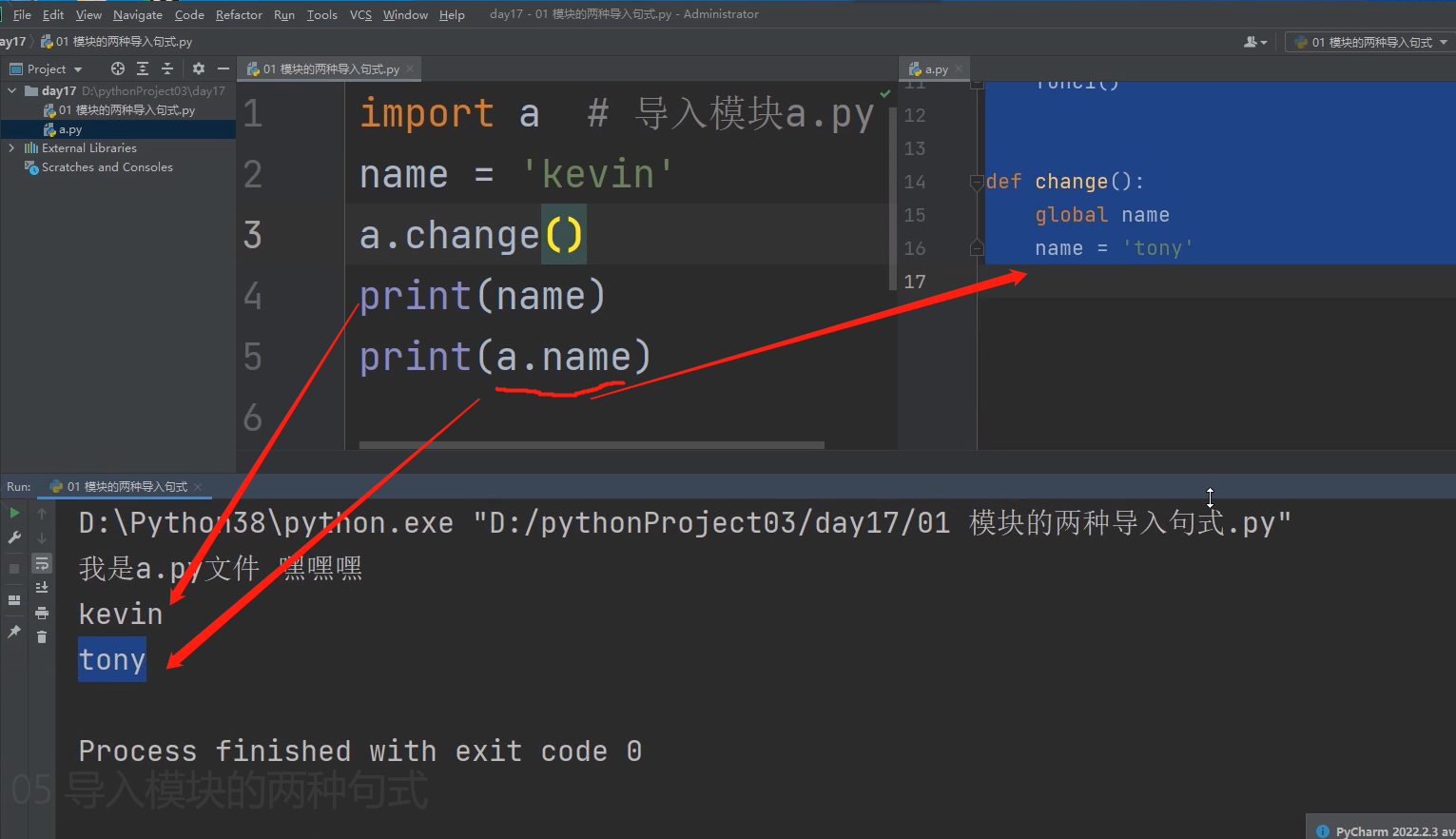
以import a 为例研究底层原理 import a 意思就是导入模块a.py文件到当前执行文件
"""
1.先产生执行文件的名称空间
2.执行被导入文件的代码将产生的名字放入被导入文件的名称空间中
3.在执行文件的名称空间中产生一个模块的名字!!!!!!
4.在执行文件中使用该模块名点的方式,就可以使用模块名称空间中所有的名字!!!!!!
"""
.
.
.
.
.
.
.
.
.
.
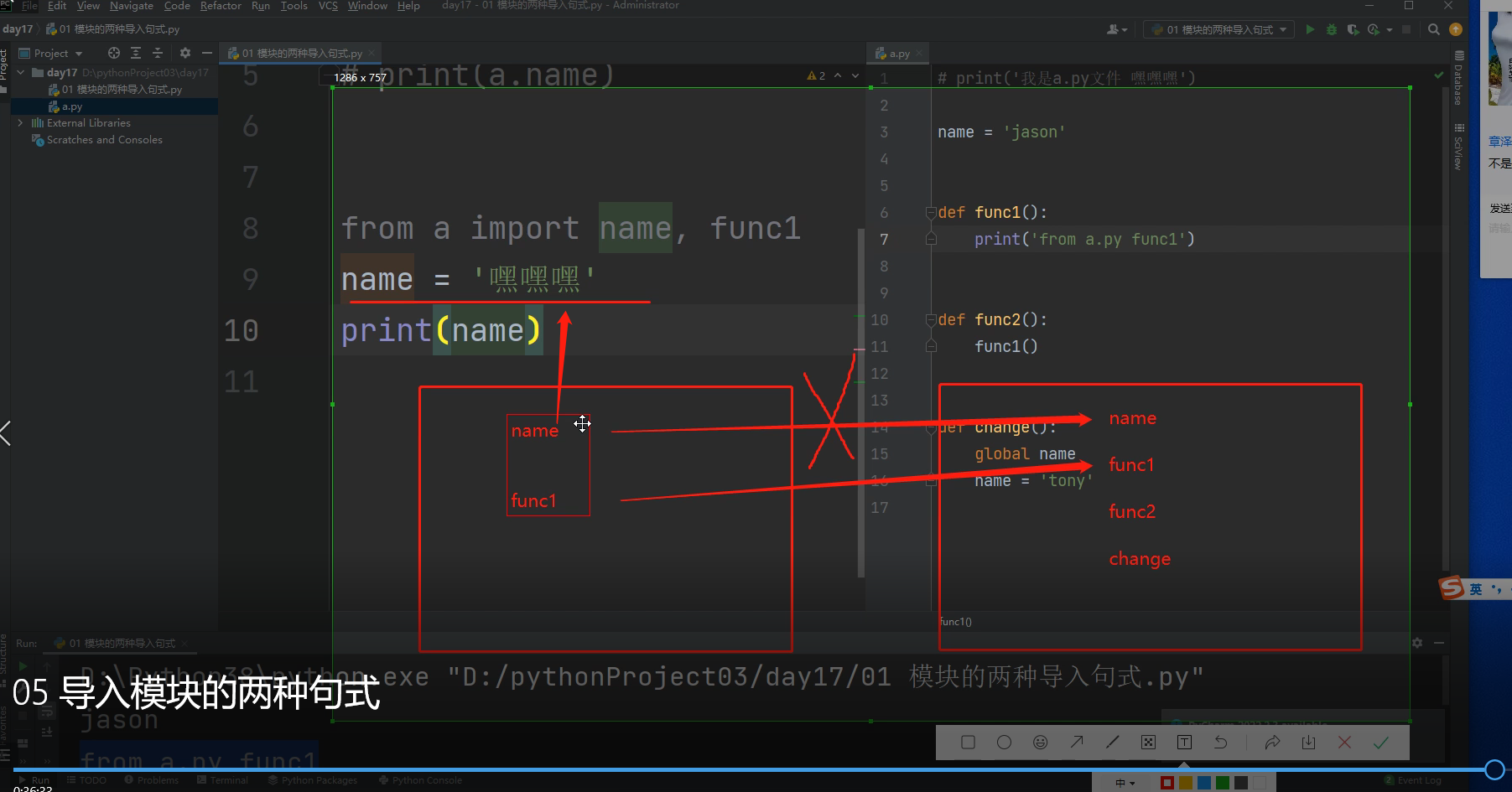
2.from...import...句式 导入py文件中的某个名字
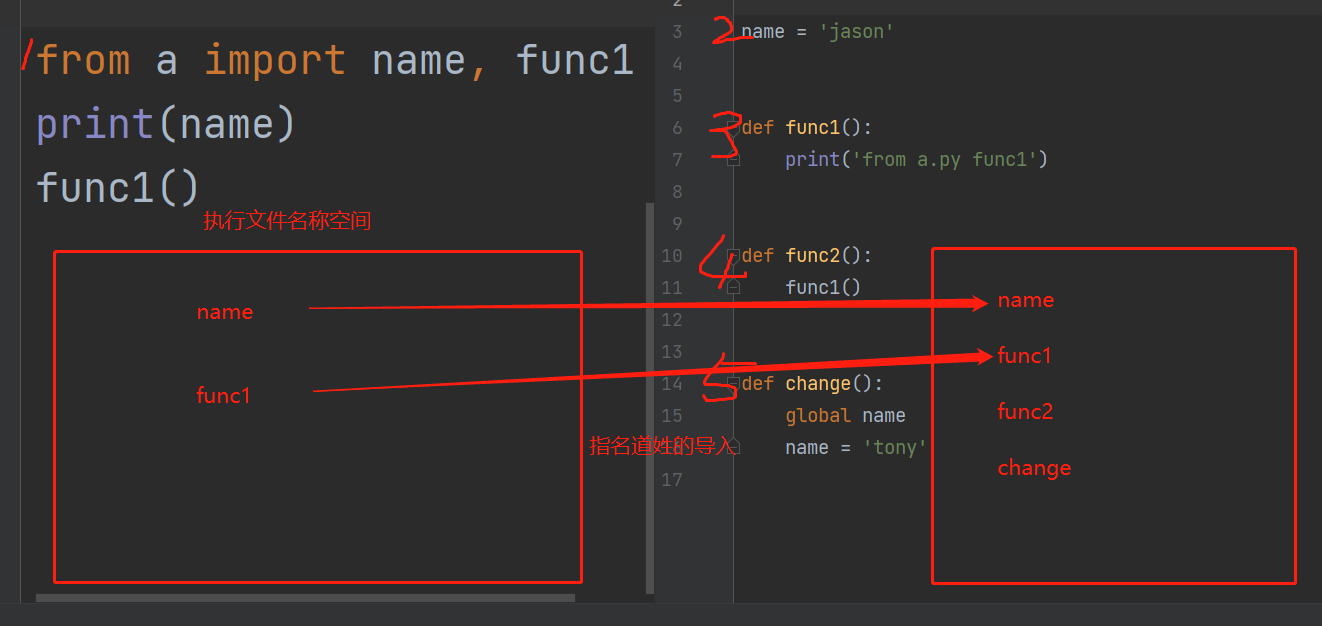
from a import name 将模块a文件中name导入一个到当前执行文件
以from a import name,func1为例 研究底层原理
"""
1.先产生执行文件的名称空间
2.执行被导入文件的代码,将产生的名字放入被导入文件的名称空间中
3.在执行文件的名称空间中,产生对应的名字,绑定模块名称空间中对应的名字
4.在执行文件中直接使用名字,就可以访问名称空间中对应的名字
"""
.
.
.
.
.
.
.
导入模块补充说明
1.import与from...import...两者优缺点
import句式 正常情况下用import句式!!!
由于使用模块名称空间中的名字都需要模块名点的方式才可以用
所以不会轻易的被执行文件中的名字替换掉
但是每次使用模块名称空间中的名字都必须使用模块名点才可以
from...import...句式
指名道姓的导入模块名称空间中需要使用的名字 不需要模块名点
但是容易跟执行文件中名字冲突!!!!!!
.
.
.
.
.
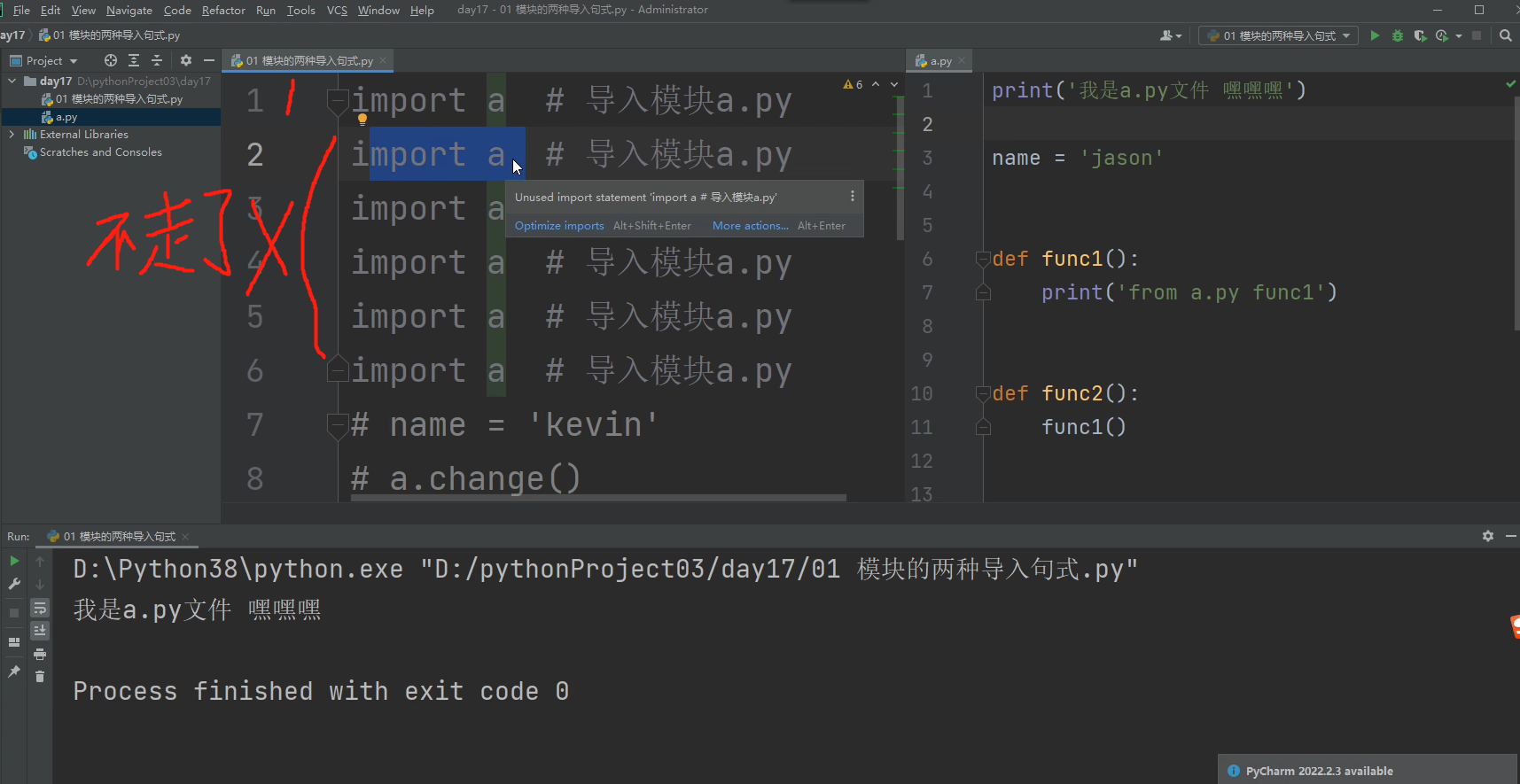
2.重复导入模块 很重要!!!!!!
当次程序运行时,在一个文件里面,代码在执行的过程中中,解释器只会导入一次模块。后续重复的导入模块语句并不会执行!!!!!!
比如在一个test.py文件里面,多次导入aaa.py 文件 只有第一次导入会执行
import aaa
import aaa
import aaa
import aaa
.
.
.
.
.
3.起别名
第一种给模块名起别名:import wuyongerciyuan as wy
将很长的模块名用as起一个别名,这样在调用后续的该模块名中的名字时,就可以不用写这个长的模块名了!!!
第二种给模块里面的变量名起别名:from wuyongerciyuan import zhangzehonglovezhanghong as zz
这种就是将模块里面的名字起了一个别名,着用后续调用这个长名字的时候就可以直接用别名调用了!!!
第三种:想给模块里面多个变量名起别名:from a import name as n,func1 as f1
将变量名name起了个别名n 将变量名func1起了个别名f1
.
.
.
.
.
4.涉及到多个模块导入
import a # 如果模块功能相似度不高 推荐使用第一种
import wuyongerciyuan
import a, wuyongerciyuan # 相似度高可以使用第二种
.
.
.
.
.
.
.
循环导入问题 重要
# 1.循环导入
两个文件之间彼此导入彼此并且相互使用各自名称空间中的名字 极容易报错
# 2.如何解决循环导入问题
1.确保名字在使用之前就已经准备完毕
2.我们以后在编写代码的过程中应该尽可能避免出现循环导入
-------------------------------------------------------------
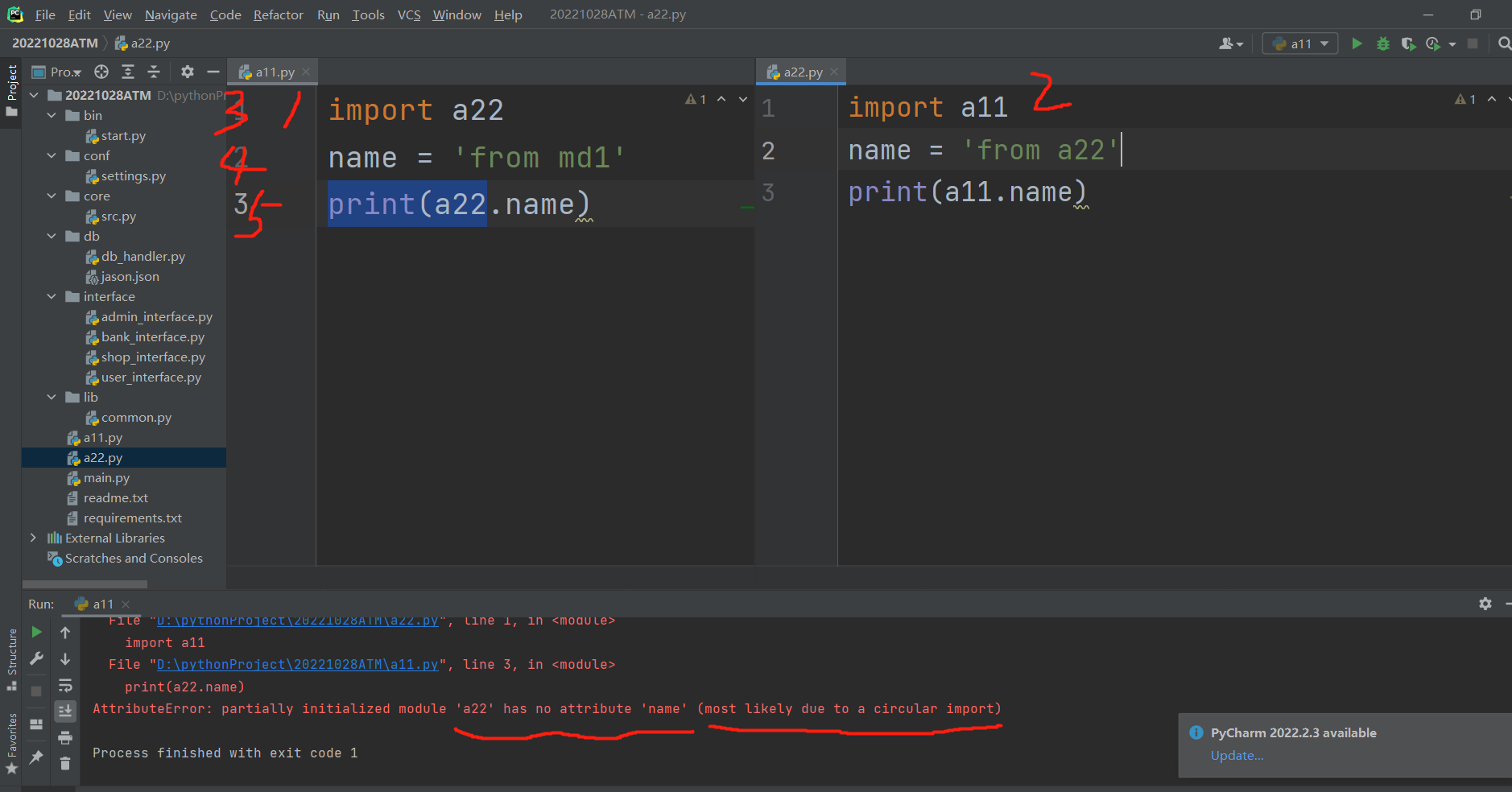
# 最经典的一个循环导入例题,在a11里面运行函数,
第一步:先执行import a22
第二步:再运行a22里面的函数代码,首先会运行 import a11
第三步:又会去运行a11里面的函数代码,这个时候还是先运行import a22
第四步:但由于已经执行过一次import a22,所以再执行import a22时,就不执行了,直接往下走了
第五步:这样往下走到print(a22.name)时就出问题,a22里面只走到第一行,下面都没走了,
所以在a11里面通过a22.name根本拿不到a22里面的变量名name!!!所以报错找不到!!!
一旦出现循环导入,就会导致被导入文件里面的代码不能能被执行!!!
这样使用文件里面,使用被导入文件里面的变量时,就会报错!!!
.
.
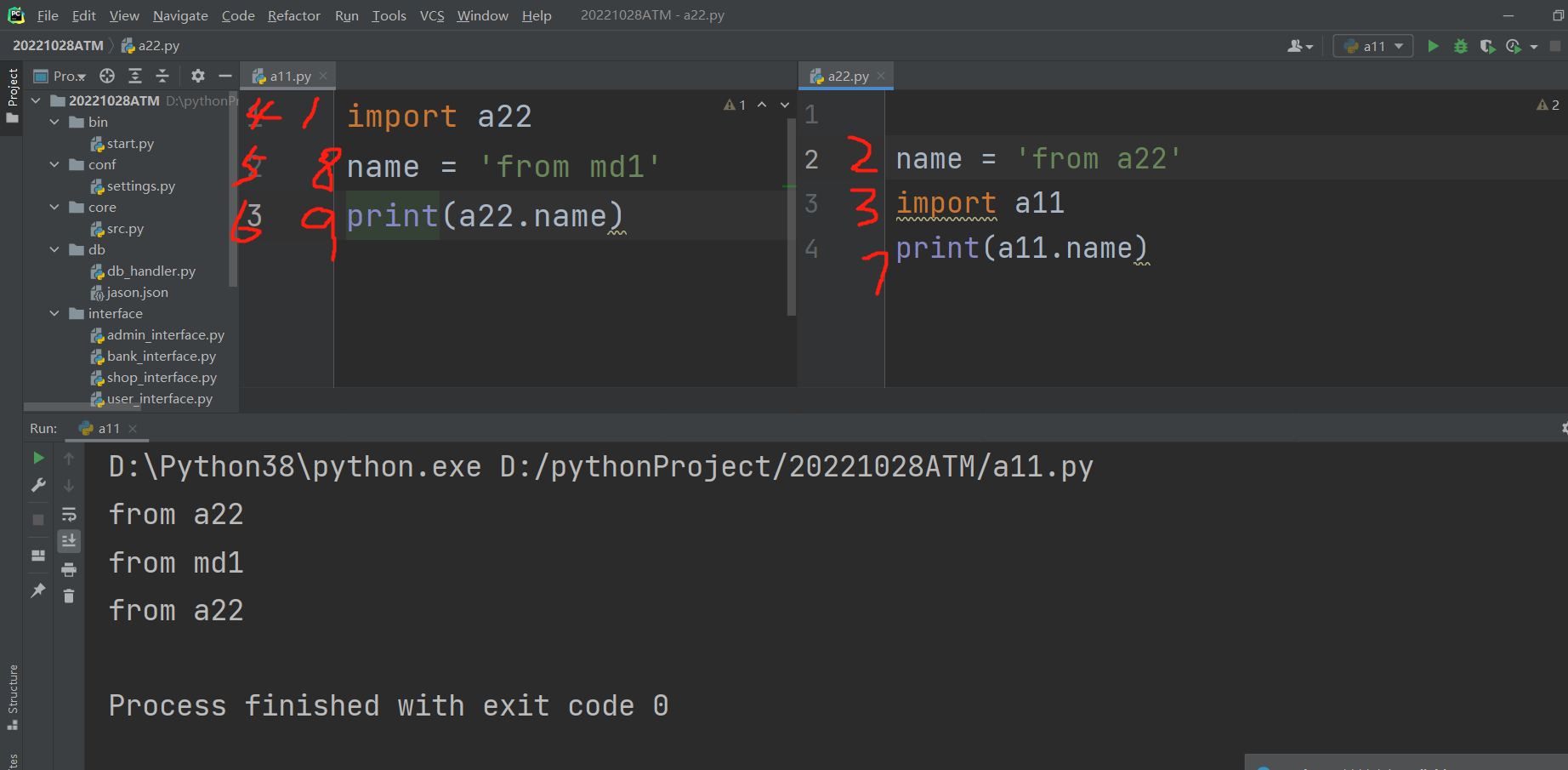
解决办法也很简单,就直接把name = 'from a22' 放到导入句式的上面去

.
这个地方为什么多打了一行,见图!!!!
.
.
.
# test1.py内容
import app_flask.blueprints.test2 as test2 # 1
print(111) # 3
print(111111) # 4
print(111111111) # 5
kkk = 'qqq' # 6
print(test2.name) # 7 报错 因为test2.py里面代码还没执行了
-----------------------------------------
# test2.py内容
from app_flask.blueprints import test1 # 2
print(222)
print(222222)
print(222222222)
name = "123"
print(test1.kkk)
# 右键运行test1.py文件,执行流程
-----------------------------------------
-----------------------------------------
-----------------------------------------
test1.py内容
import app_flask.blueprints.test2 as test2 # 1
print(111) # 7 13
print(111111) # 8 14
print(111111111) # 9 15
kkk = 'qqq' # 10 16
print(test2.name) # 11 17
test2.py内容
print(222) # 2
print(222222) # 3
print(222222222) # 4
name = "123" # 5
from app_flask.blueprints import test1 # 6
print(test1.kkk) # 12
# 右键运行test1.py文件,执行流程,与结果
222
222222
222222222
111
111111
111111111
123
qqq
111
111111
111111111
123
### 导入句式总结
### 不管是导入文件名还是导入文件里的变量,都是要将被导入的文件从上到下的代码运行一遍的
### 同一个文件里有多次导入同一个文件,文件只会被导入一次,导入代码也只会生效一次
### 这也是为什么运行到第6步时,从上到下执行test1.py时,不会再次执行步骤1的导入了,直接往下走了
### 导入句式执行完了,就相当于一个函数执行完了,导入句式下面的代码,还是要正常执行的!!!
### 所以我们看到步骤6的导入句式执行完了,test1.py里面从上到下执行一遍后,还会继续步骤12
### 步骤1的导入句式执行完了,test2.py里面从上到下执行一遍后,步骤13-17还是会正常执行的!!!
.
.
.
.
.
.
.
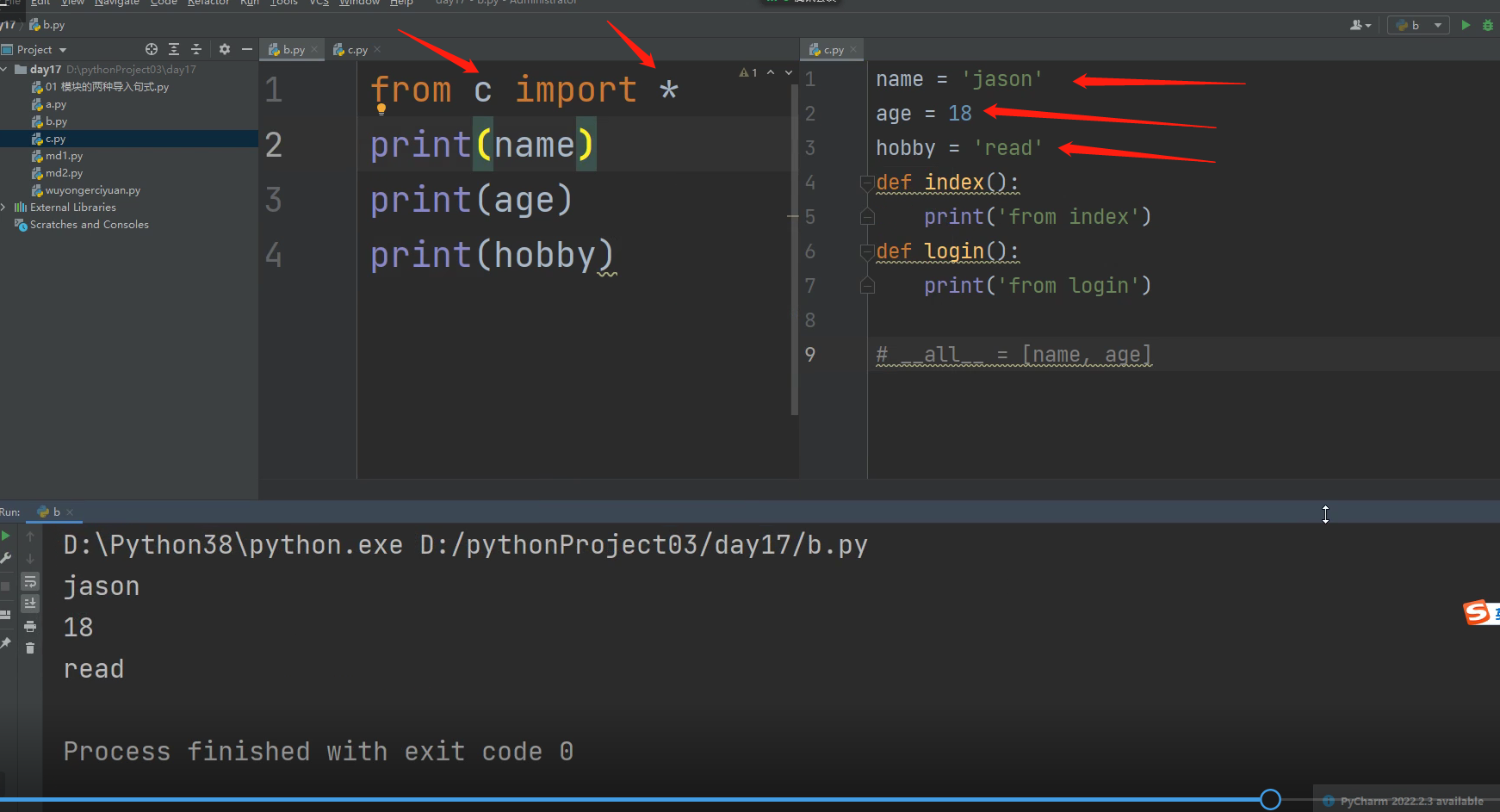
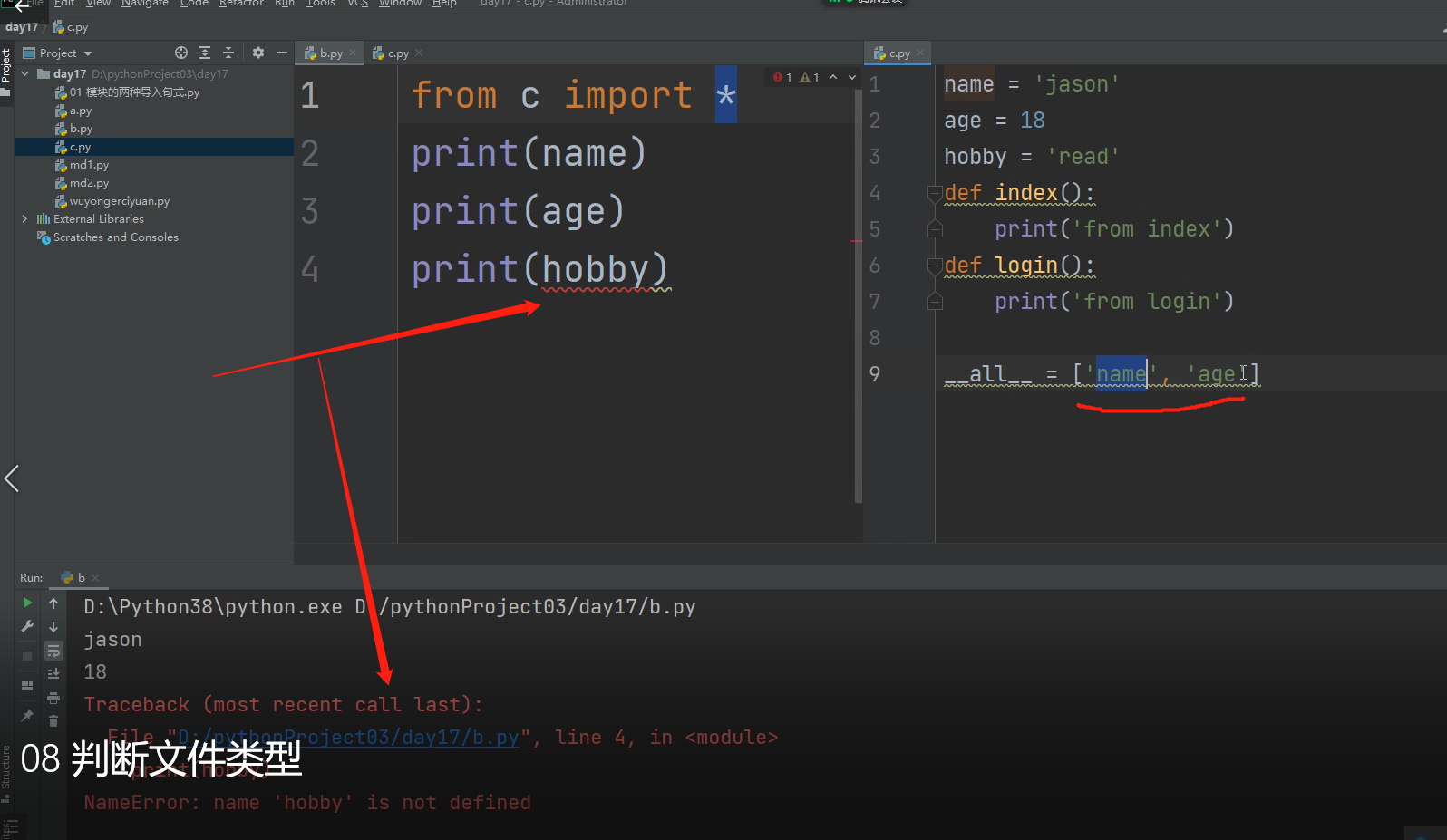
from import 方法 补充知识
from a import * *默认是将模块名称空间中,所有的名字导入!!!!!
这样就可以再后续,能直接调用到模块a里面的所有名字了!!!
__all__ = ['名字1', '名字2'] 针对*可以限制拿的名字,列表里面写几个名字,后面执行文件中只能拿到模块文件里面的几个名字。
但是限制力很弱,只针对from a import * 这种形式的,其他形式的不能限制!!!

.
.
.
.
.
.
.
.
.
.
.
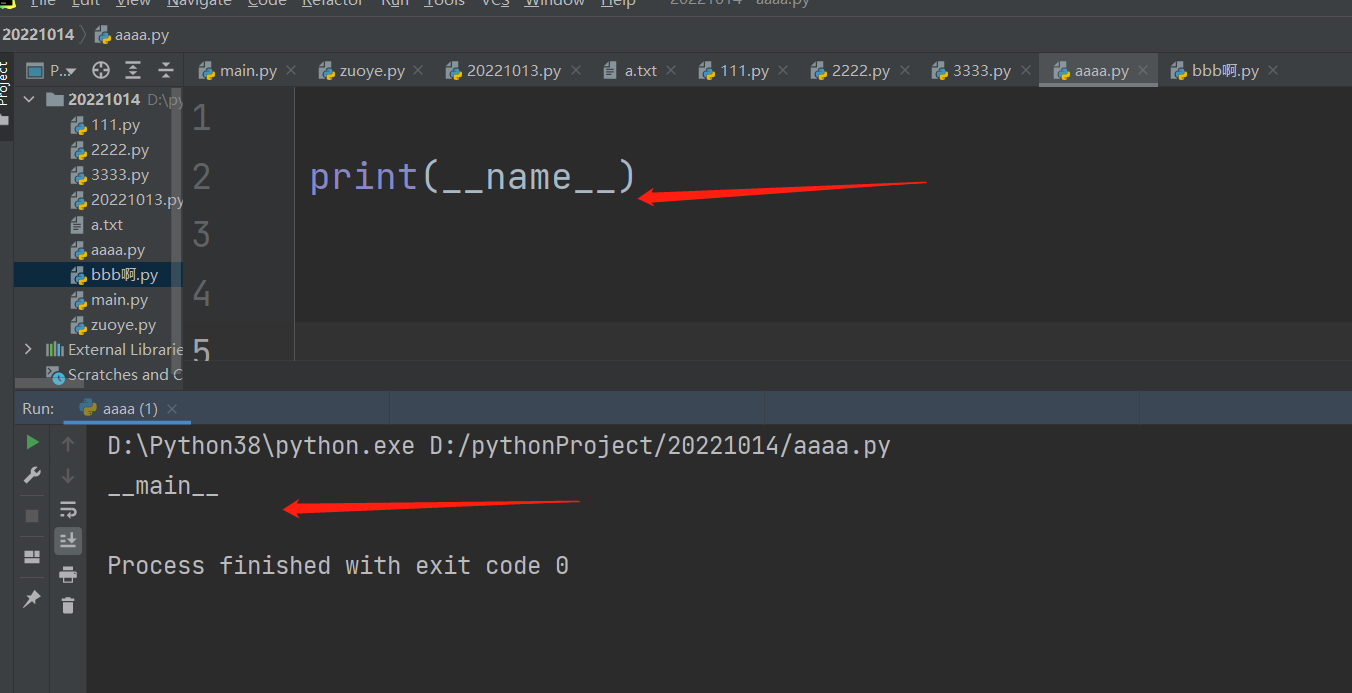
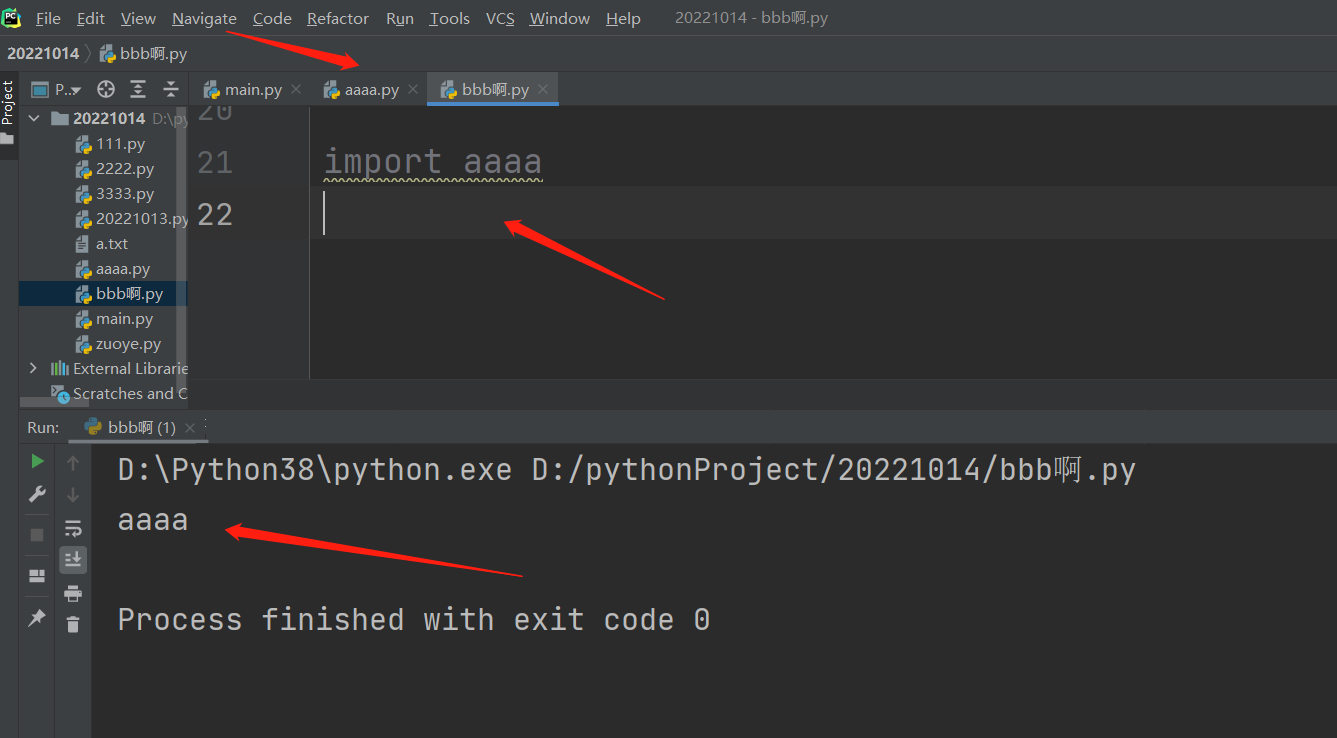
判断文件类型 重要!!!!!
双下__name__对应的值会随着文件类型的变化而发生变化!!!!!!
所有的py文件都可以直接打印__name__对应的值
双下__name__方法,在任意一个py文件里面,如果直接执行打印的话,都是显示__main__
双下__name__对应的值会随着文件类型的变化而发生变化!!!!!!
当py文件是执行文件的时候__name__对应的值是__main__
当py文件是被导入文件的时候__name__对应的值是模块名
.
.
.
.
.
.
.
.
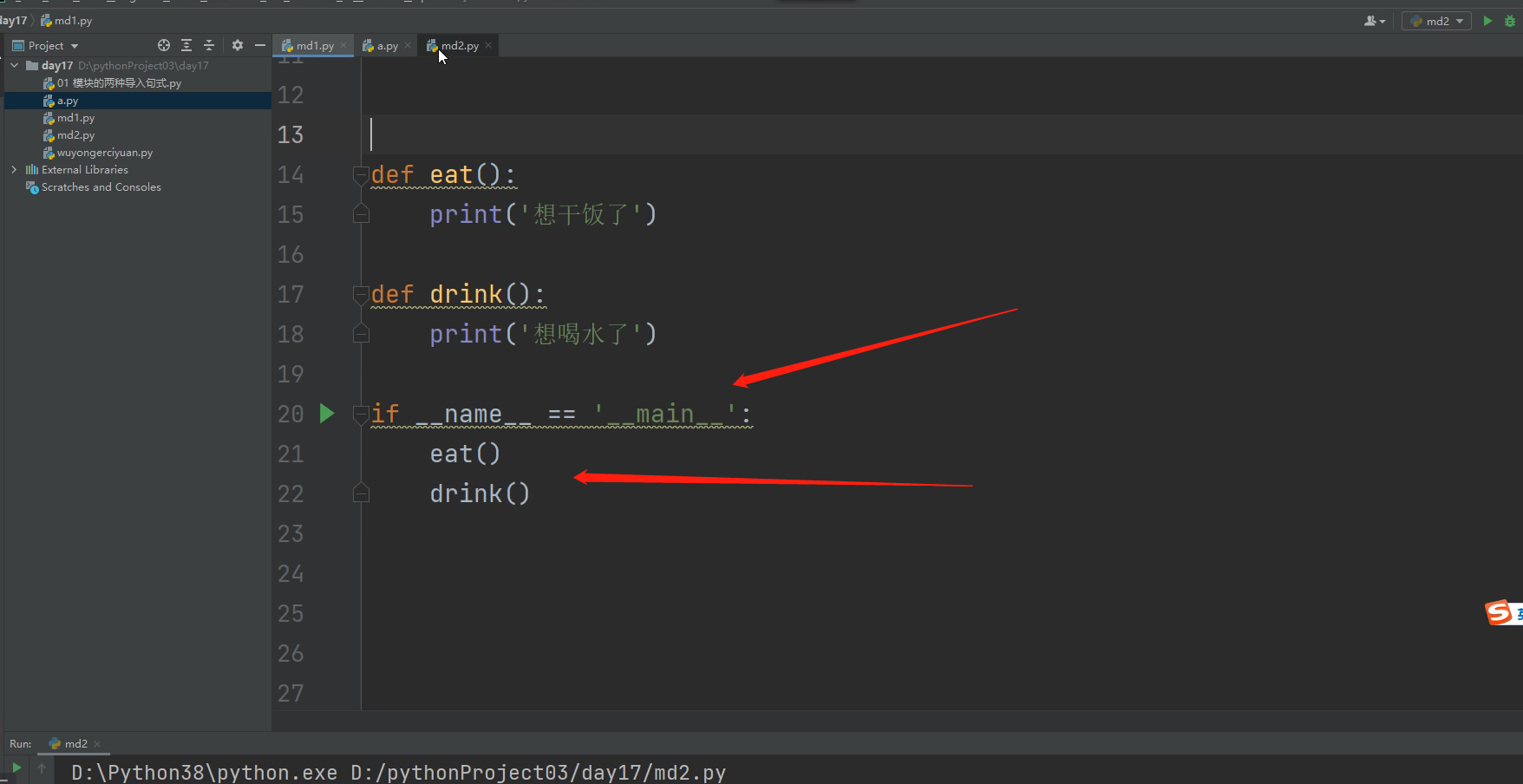
if __name__ == '__main__': # 判断双下__name__的结果是不是__main__
print('哈哈哈 我是执行文件 我可以运行这里的子代码')
if这句话的目的就是让你能够区分:
哪些代码是模块被导入的时候要执行的!!!!!!!!!
哪些代码是模块被导入时,开发者不想让别人执行的!!!!!!!!!
上述脚本可以用来区分所在py文件内python代码的执行
使用场景:
1.模块开发阶段
2.项目启动文件
比如模块的开发者在一个模块写了一个函数,开发者肯定会对该函数进行各种调用与测试,运行看看正不正常,但是后续该模块被别人导入的时候,别人可能并不想导入该模块后就直接运行该模块中的函数体代码,这个时候模块的开发者,又不想改变现在模块中的函数调用与测试相关的代码,这个时候就把调用测试相关的代码上面加一行if __name__ == '__main__': 再把相关的代码缩进一下,成为if的子代码,
这样只有当这个文件是执行文件时,if下面的代码才能正常运行,其他人导入该模块后,当运行到if __name__ == '__main__': 这行代码时,__name__的结果就变成了该模块的名字了,所以不符合条件,不会运行if的子代码了!!!!!!!!
这样对模块的使用者与模块的开发者都很方便!!!!!!
.
.
.
.
.
.
.
.
.
.
导入模块的时候,模块的查找顺序 重要!!!!!!
1.最先 内存
import aaa
import time
time.sleep(15) # 在这段代码运行的过程中,手动将模块aaa文件删除
print(aaa.name)
aaa.func1() # 依然能够调用aaa文件里面的代码
# 但是当程序运行结束后,再次运行该程序时,就报错了,因为内存中模块aaa的相关数据都被清除掉了!!!所以再次运行时不能正常运行了!!!
2.其次 内置
import time 导入模块,一定是先找内置的模块time,找不到才去找自定义的模块time!!!
print(time)
print(time.name)
"""
以后在自定义模块的时候尽量不要与内置模块名冲突!!!!!!
如果导入的模块文件名叫time,这个时候在在打印time的时候,会优先的内置的模块里面找time,而不会去找自定义的模块文件time
优先找内置中的变量名
"""
3.最后 执行文件所在的sys.path(系统环境变量)
当我们在导入模块的时候,一定要看执行的文件在什么地方!!!
你要找的模块必须就在当前的路径下,也就是该执行文件的上一层文件夹打开后,一看能看到的所有文件!!!也就是执行文件所属的直属文件夹下,必须又该要有被导入的文件,才能执行普通的导入操作!!!否则会报错!!!
一定要以执行文件为准!!!
我们可以将模块所在的路径也添加到执行文件的sys.path中即可
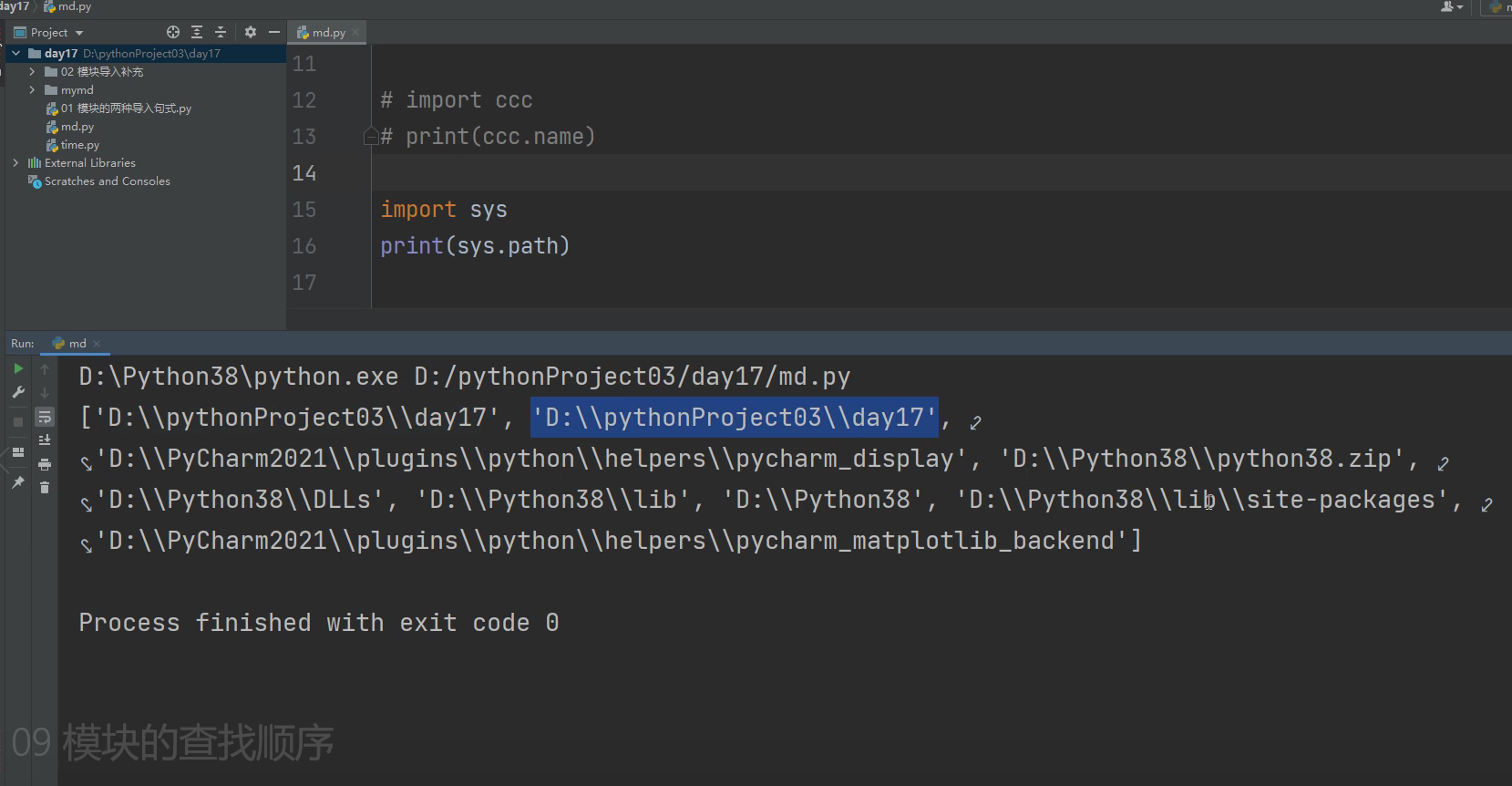
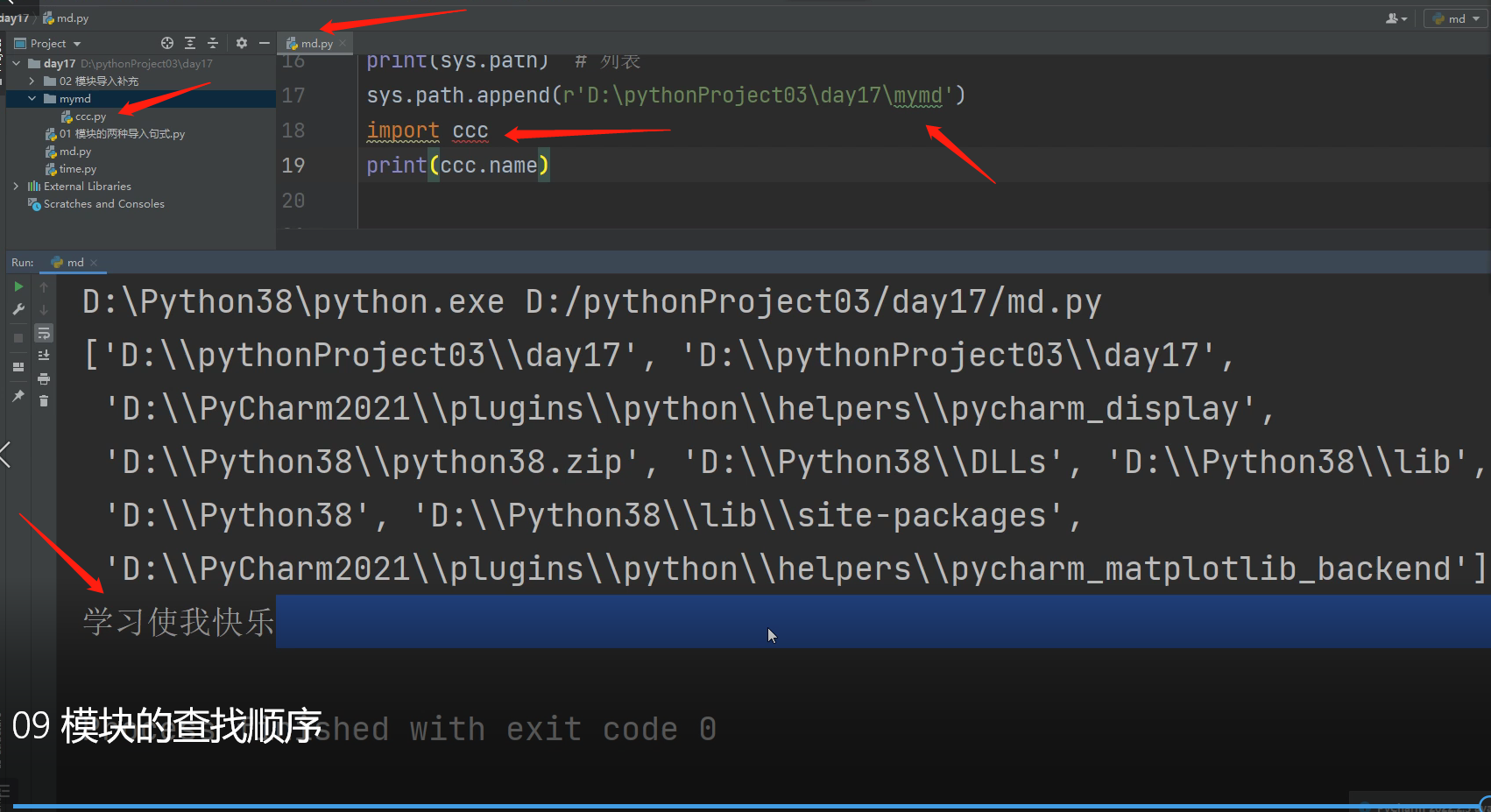
import sys # sys也是一个内置模块就是系统的意思
print(sys.path) # 通过sys.path 就可以看出该结果是一个列表
sys.path.append(r'D:\pythonProject03\day17\mymd') 解决办法,将该ccc所属的文件路径添加进sys.path的文件列表里,就可以了!!!
import ccc
print(ccc.name)
通过添加sys.path的操作,就能够让执行文件在当前路径下查找到不模块文件,可以通过添加的环境变量路径找到模块文件,
所以就能够正常调用了!!!这种只要能够确定模块的文件路径在哪里,在执行导入模块前,添加两行
import sys
sys.path.append(r'模块的文件路径')
就能正常在执行文件中调用该模块文件!!!
就看第一个就行了,如果第一找不到,后面也肯定找不到!!!
.
.
.
.
.
.
.
.
.
模块的绝对导入与相对导入 重要!!!!!!
在不使用sys.path添加路径的方法下,还可以导入模块文件的方法!!!
"""
再次强调:一定要分清楚谁是执行文件!!!
模块的导入全部以执行文件为准!!!!!!
"""
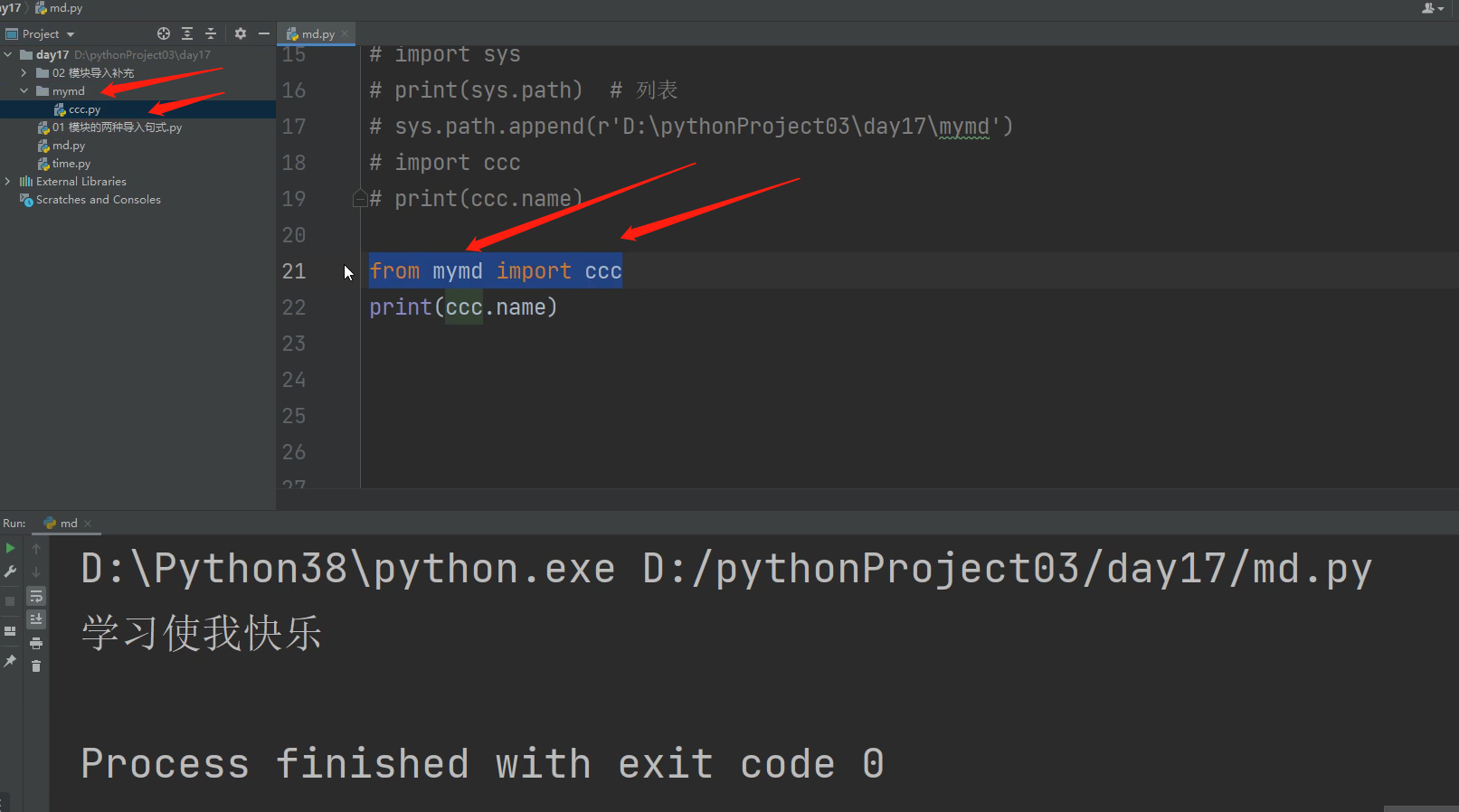
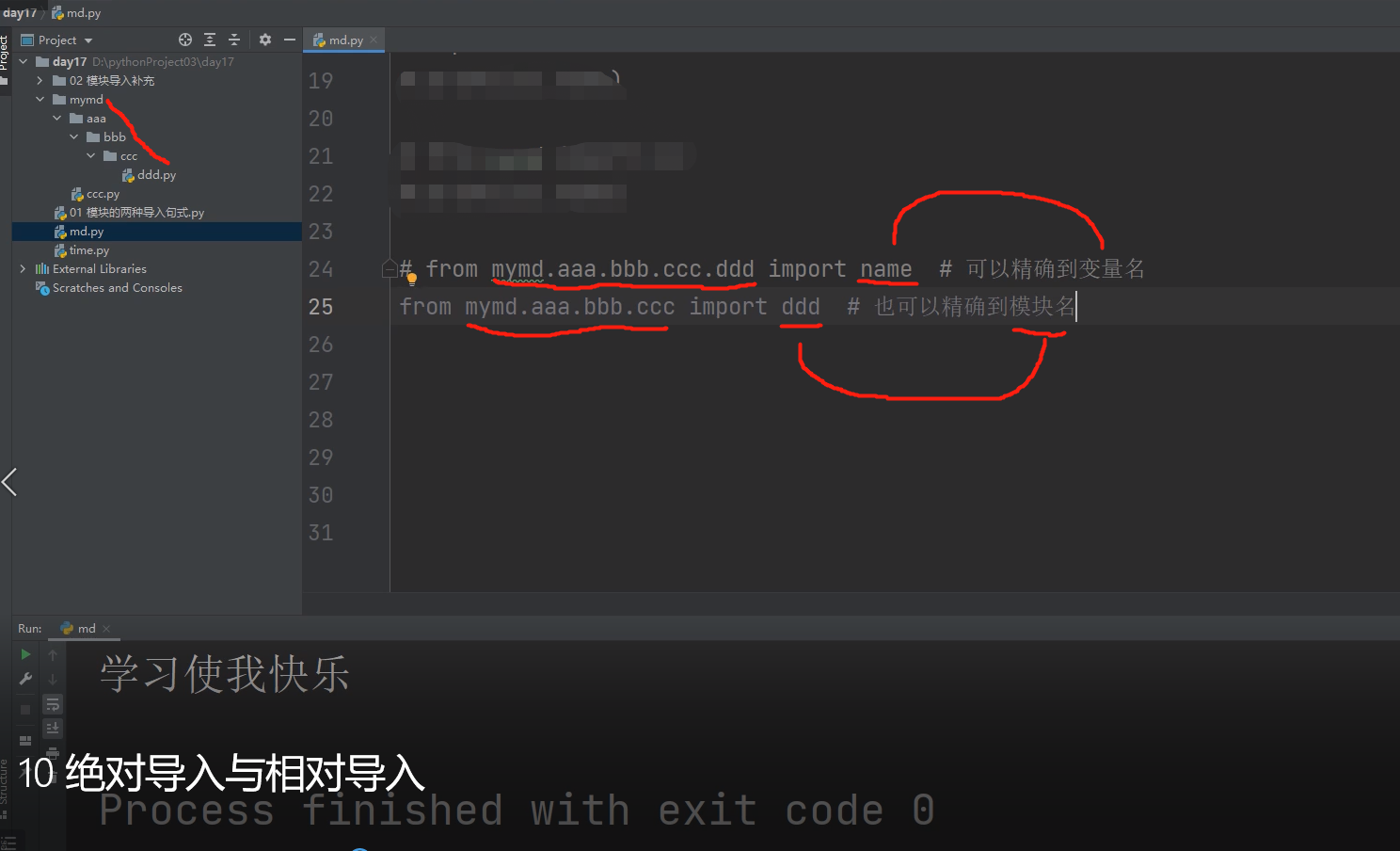
# 绝对导入!!!!!!
这才是form import 方法的最重要的作用!!!
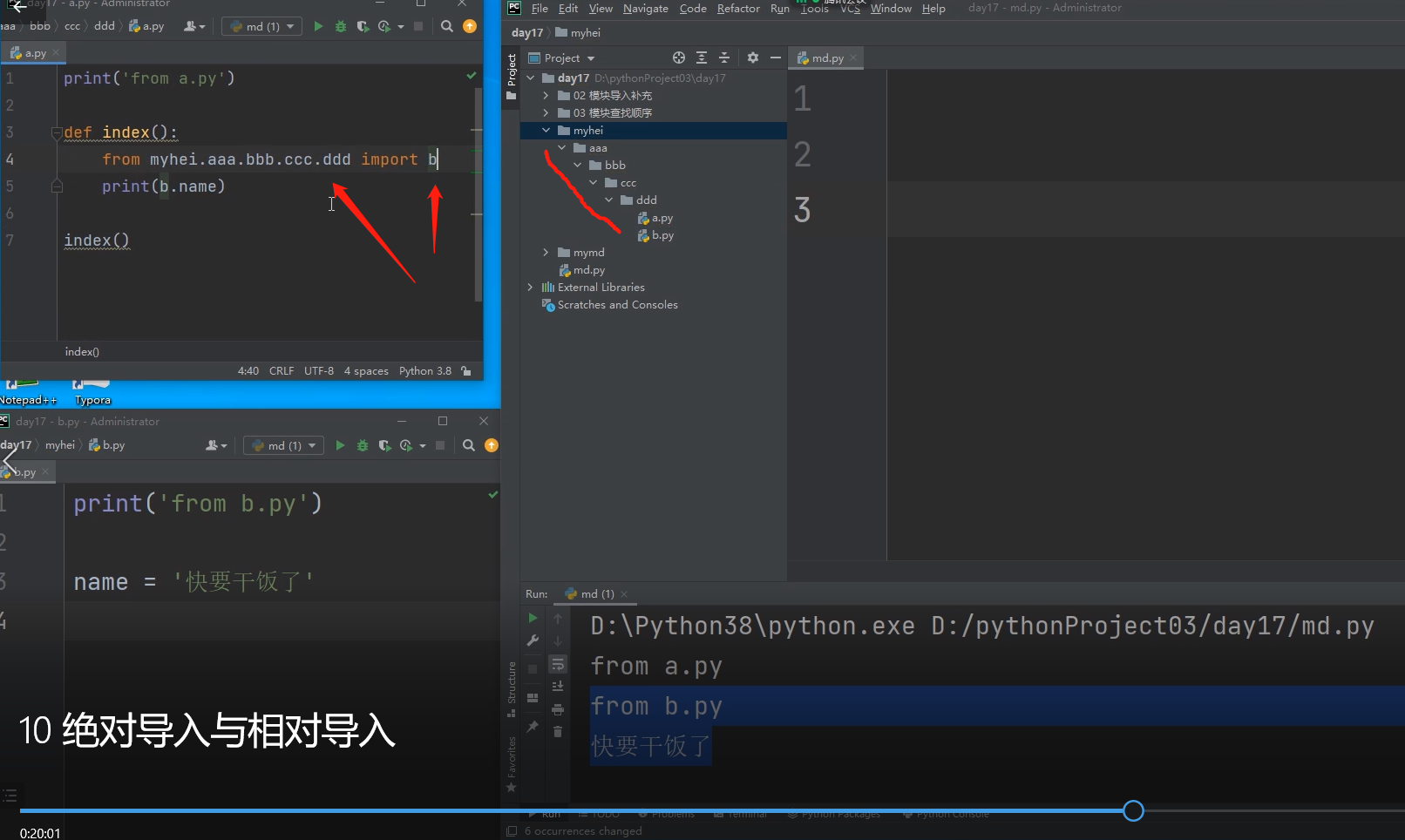
from mymd import ccc 站在执行文件的角度,按照项目根目录一层层往下查找
from mymd.aaa.bbb.ccc.ddd import name # 可以精确到变量名
from mymd.aaa.bbb.ccc import ddd # 也可以精确到模块名
ps:套路就是按照项目根目录一层层往下查找,只要执行文件与模块文件都在项目的根目录下就行!!!
最简单也是最推荐用的模块导入方法!!!
----------------------------------------------------------
# 相对导入!!! 用的不是太多!!!
# 优先使用绝对导入!!!
.在路径中表示当前目录
..在路径中表示上一层目录
..\..在路径中表示上上一层目录
不在依据执行文件所在的sys.path 而是以模块自身路径为准!!!!!
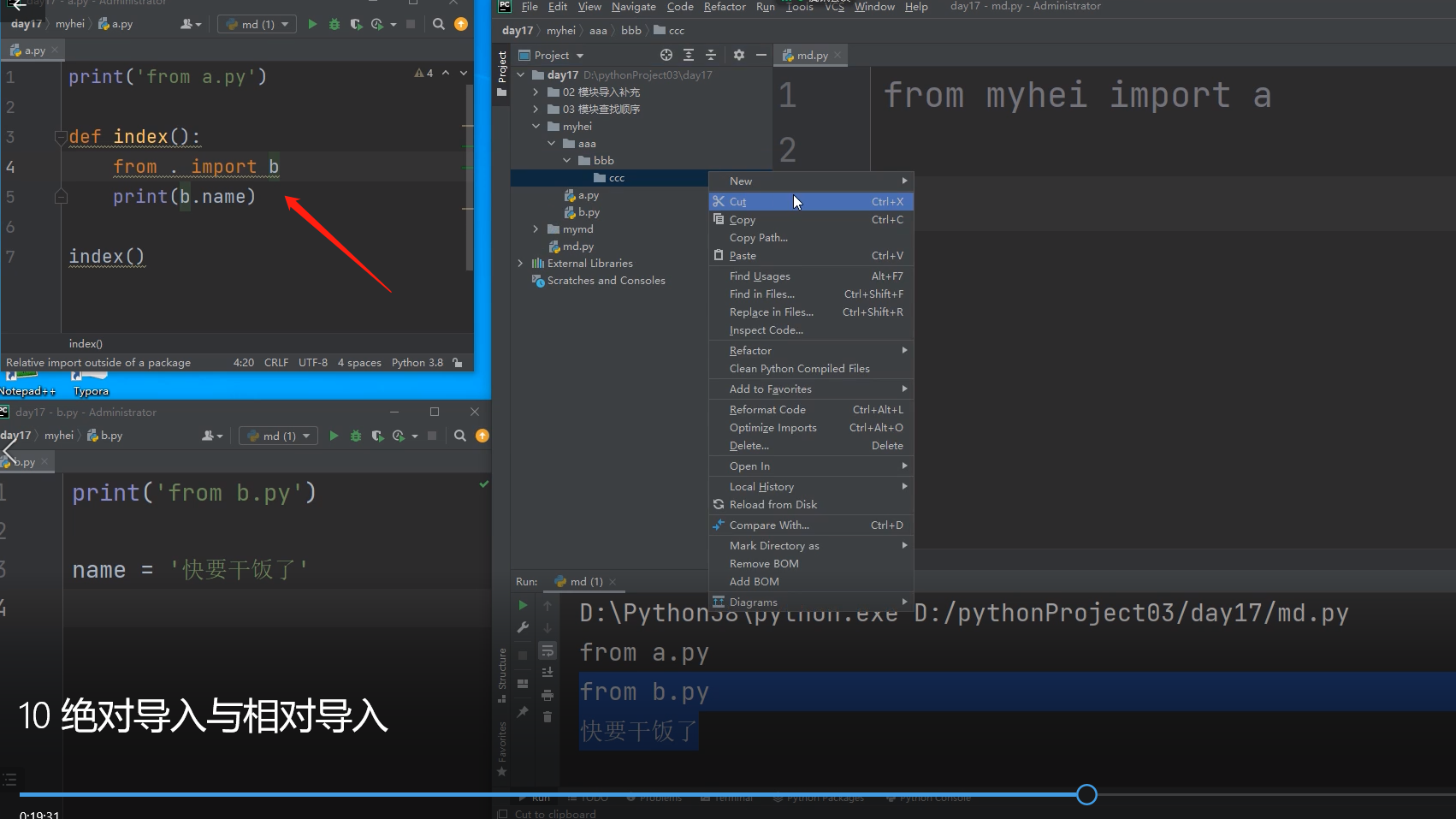
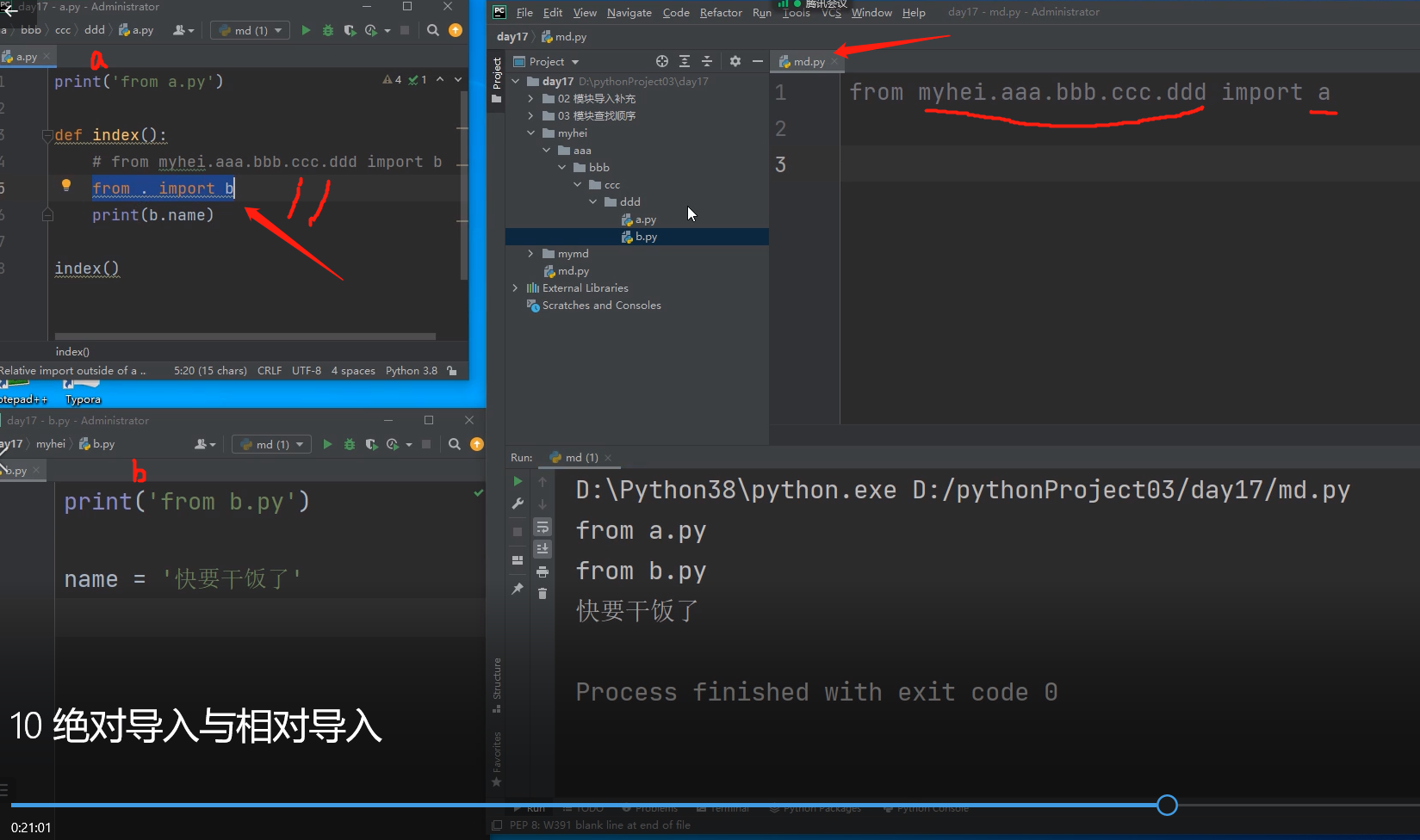
from . import b
相对导入只能用于模块文件中 不能在执行文件中使用!!!!!!
不推荐用,局限性很强!!!用了相对导入的模块文件直接就被定死了,只能是模块文件了不能是执行文件了!!!
'''
相对导入使用频率较低 一般用绝对导入即可 结构更加清晰
'''
绝对导入:
.
.
相对导入:
.
.
.
.
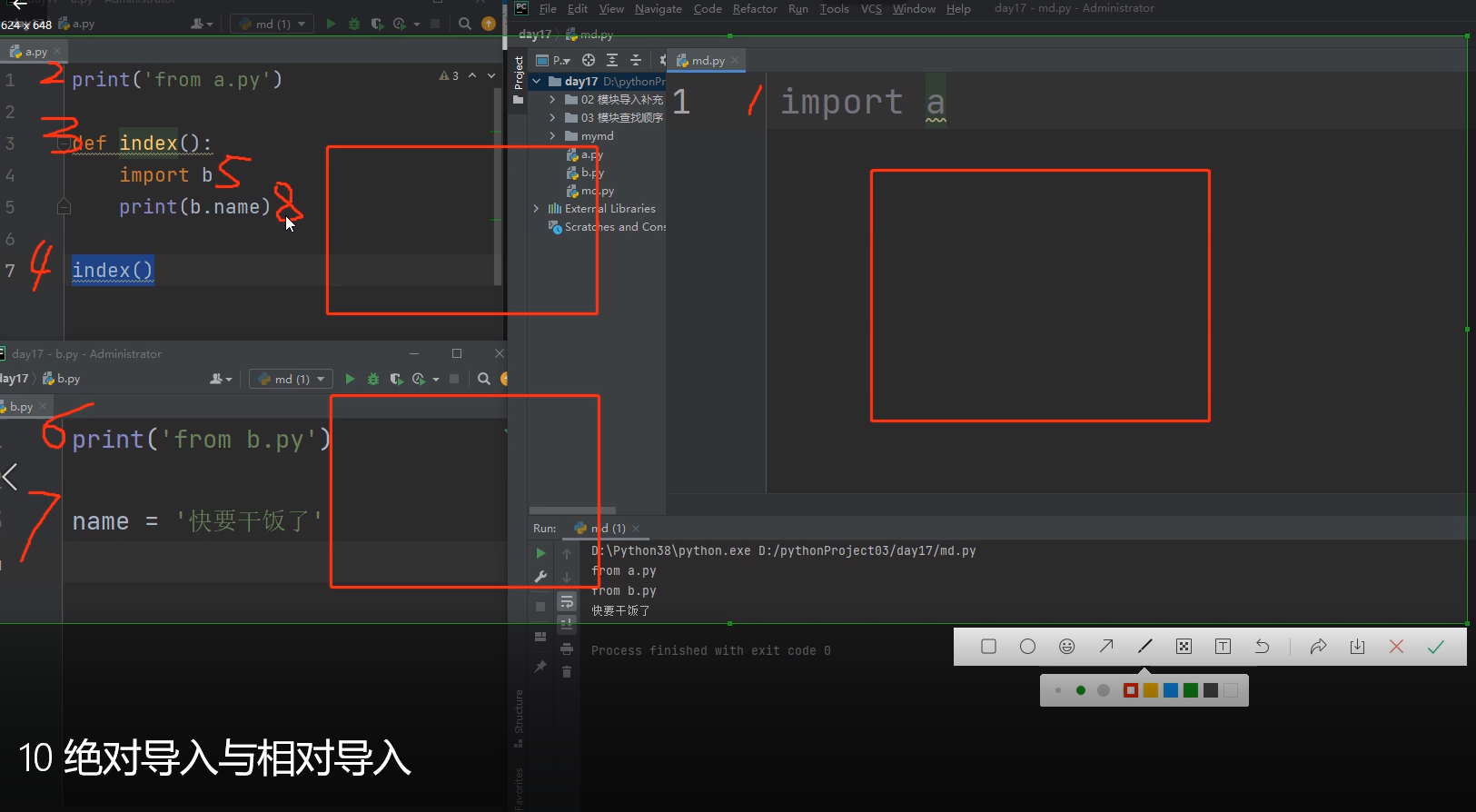
对找模块,只要是单个执行文件启动的,找模块的时候永远都是参照执行文件所在的路径为准!!!
所以在导入b模块的时候是找不到模块b的!!!
因为在根目录day17文件夹下只能直接看到myhei文件夹,而不能看到该文件夹里面的文件!!!全部要以执行文件所在的路径为准!!!
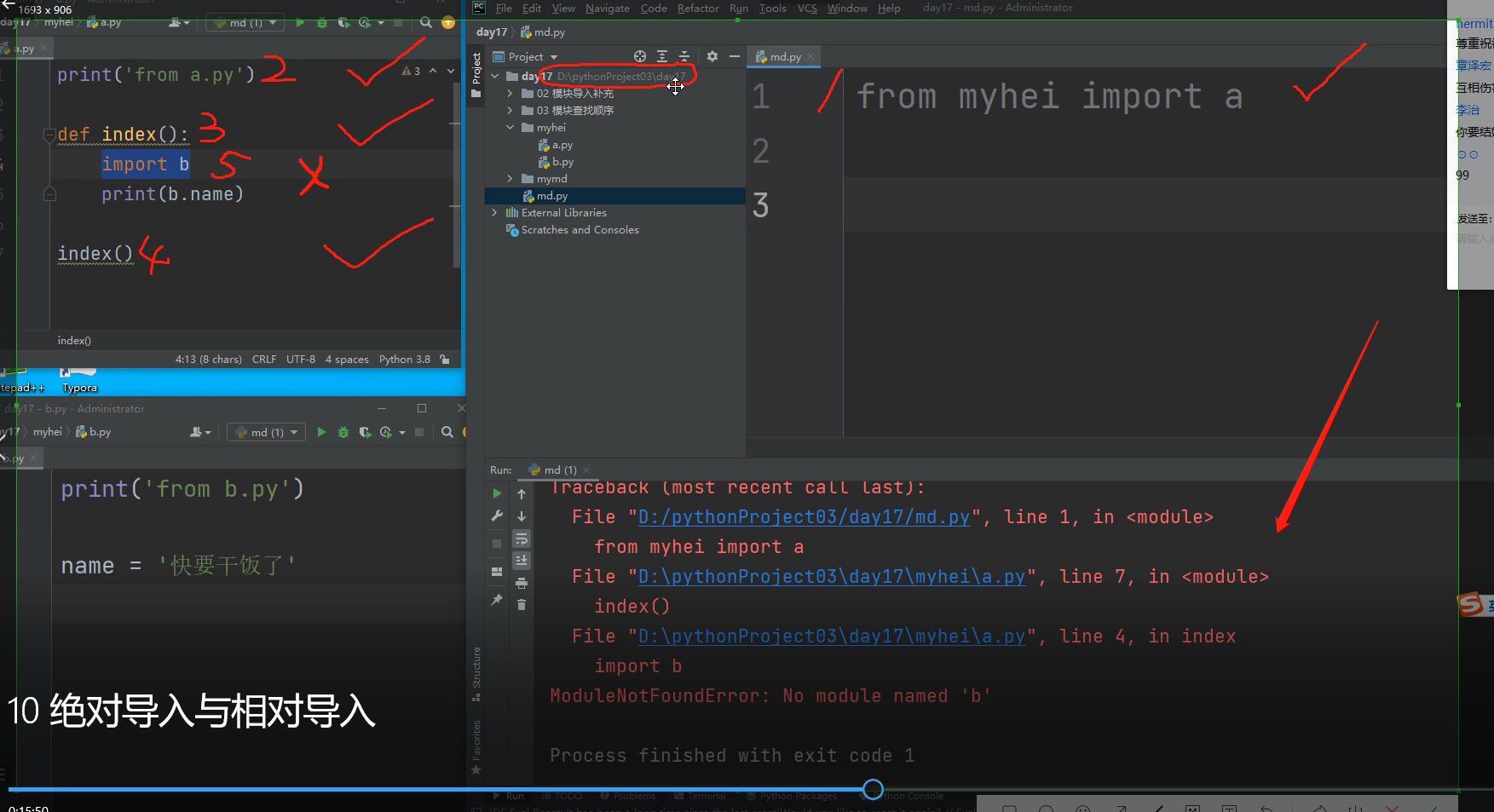
实现方法1:
.
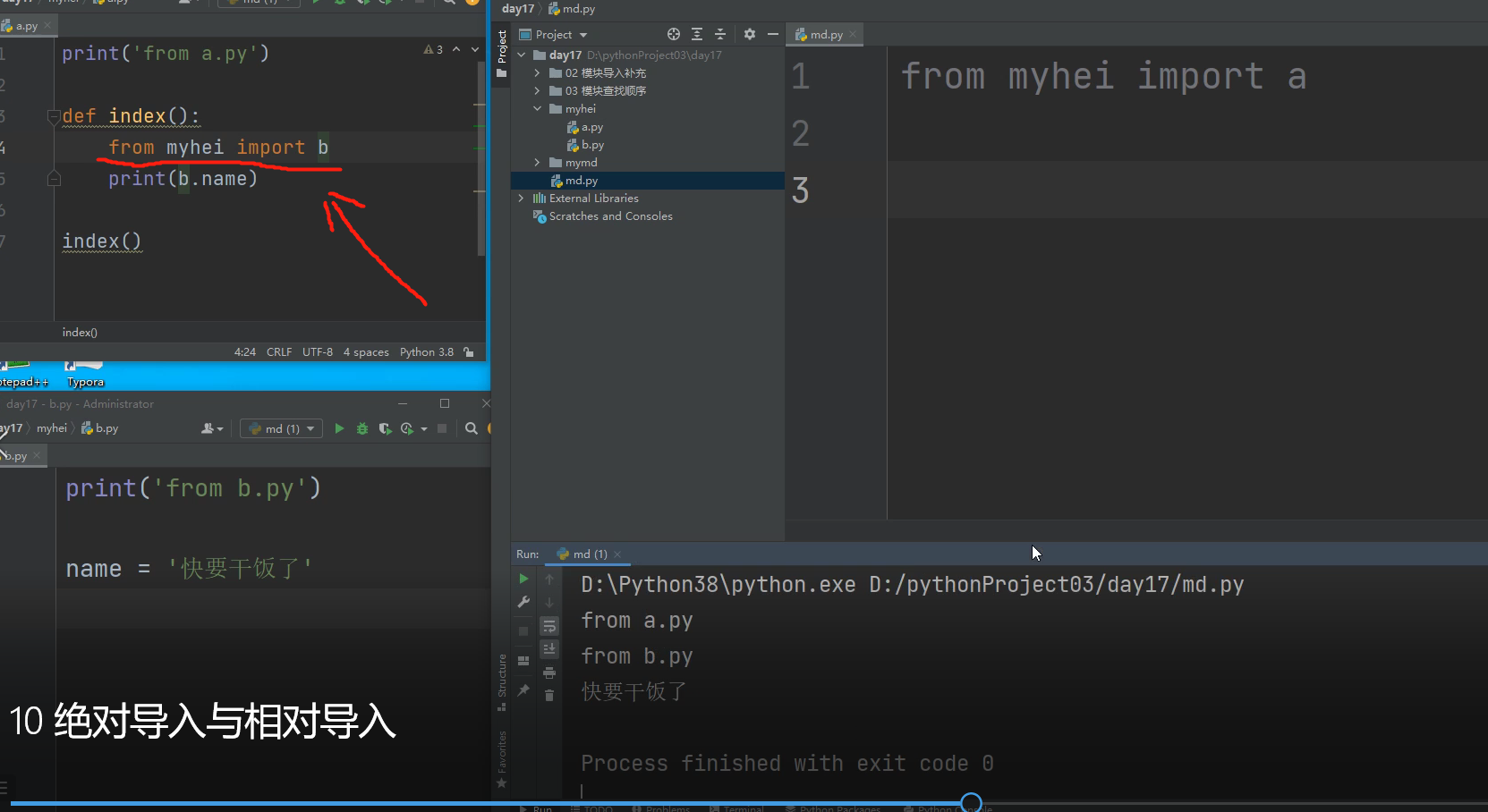
也可以这样相对导入:
.
在模块文件中可以使用相对路径,就可不参考执行文件所在的路径了,而是以模块中调用的其他模块文件相对于自己的相对路径为准!!!
.
.
.
.
.
.
补充知识点
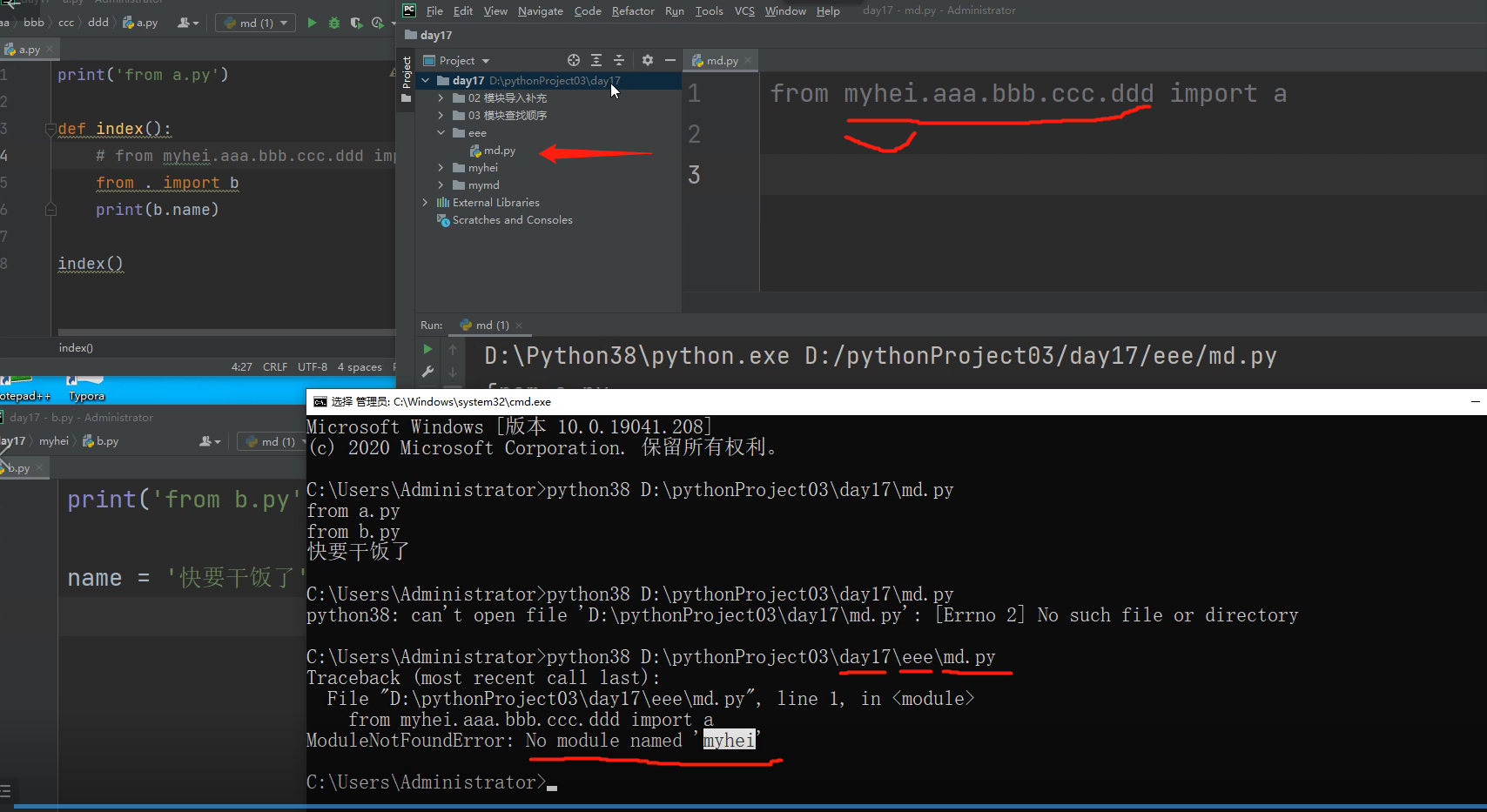
pycharm软件在导入模块文件的时候,会自动将项目的根目录,添加到系统的环境变量sys.path的路径中去,这样站在根目录下,
就可以看到其他的文件了。
所以只要依据项目的根目录往下一层一层的导模块就可以在pycharm软件中将相关的模块导入进来!!!
当用cmd运行时,就不会自动添加了,所以当要导入的模块文件与该执行文件不在同一个文件路径下的话,
是找不到该文件的,所以报错了!!!
.
.
.
.
.
.
.
包
大白话:多个py文件的集合>>>:文件夹
专业:文件夹内部含有__init__.py文件,这样的文件夹就叫包(python2必须要求 python3无所谓)
.
.
.
.
.
.
作业
1.整理今日内容及博客
2.尝试将之前的员工管理系统每个函数拆到不同的py文件中 导入使用
ps:感受感受导来导去的感觉
3.预习明日内容
python常见内置模块

 浙公网安备 33010602011771号
浙公网安备 33010602011771号