python第十六课-----异常的类型与处理,生成器与迭代器用法
1. 作业讲解
登录校验装饰器+用户权限
1.有几个普通函数
2.需要在执行之前添加校验用户信息的功能
3.编写一个校验用户是否登录的装饰器
4.定义全局变量存储用户是否登录的信息(由于不单单需要记录用户登录状态还需要记录当前用户的权限 所以使用了字典)
5.装饰器每次获取用户信息之前先判断用户是否已登录
如果没有登录则获取用户名和密码
如果登录了则获取当前登录的执行权限
6.装饰器内部如何获取当前用户想要执行的功能编号
有参装饰器
7.登录之后获取执行权限然后判断功能编号是否存在于执行权限内
昨日回顾
重要内置函数
1 .map()
映射 map(func,array...) array是可迭代对象 map方法会依次迭代array,得到的值依次传给匿名函数(也可以是有名函数),而map函数得到的结果仍然是迭代器。
map会根据提供的函数对指定的序列做映射。第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列.

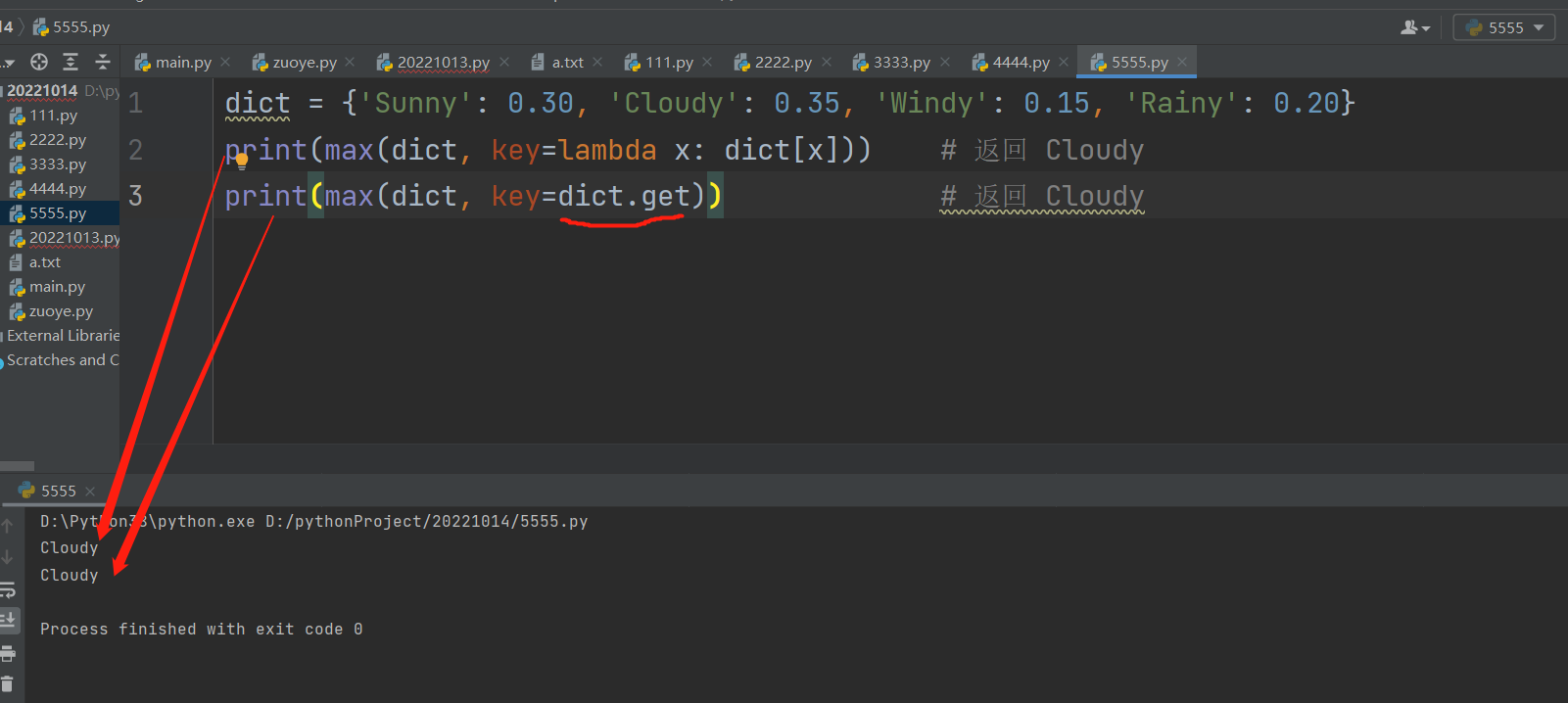
2 .max() .min()
def max(*args, key=None):
res = max(d1, key=lambda k: d1.get(k))
d1是字典 key是关键字参数,默认为none,不传值就默认for循环迭代出得值直接比较大小。
当给key传值后字典for循环出的值会经过函数处理后比较大小,最终得出最大值所对应的键!!
3 .reduce()
函数先从列表(或序列)中取出2个元素执行指定函数,并将输出结果与第3个元素传入函数,输出结果再与第4个元素传入函数,…,以此类推,直到列表每个元素都取完。
传多个值返回一个值,会对参数序列中元素进行累积。(累积包括累加、累乘、等)
res=reduce(func,array) 假设func等于lambda x,y:x+y,先对array迭代一次得到的值最为x,再迭代一次的值作为y,x与y相加后的值再作为x,array迭代三次的值作为y,如此往复直到array结束!!!
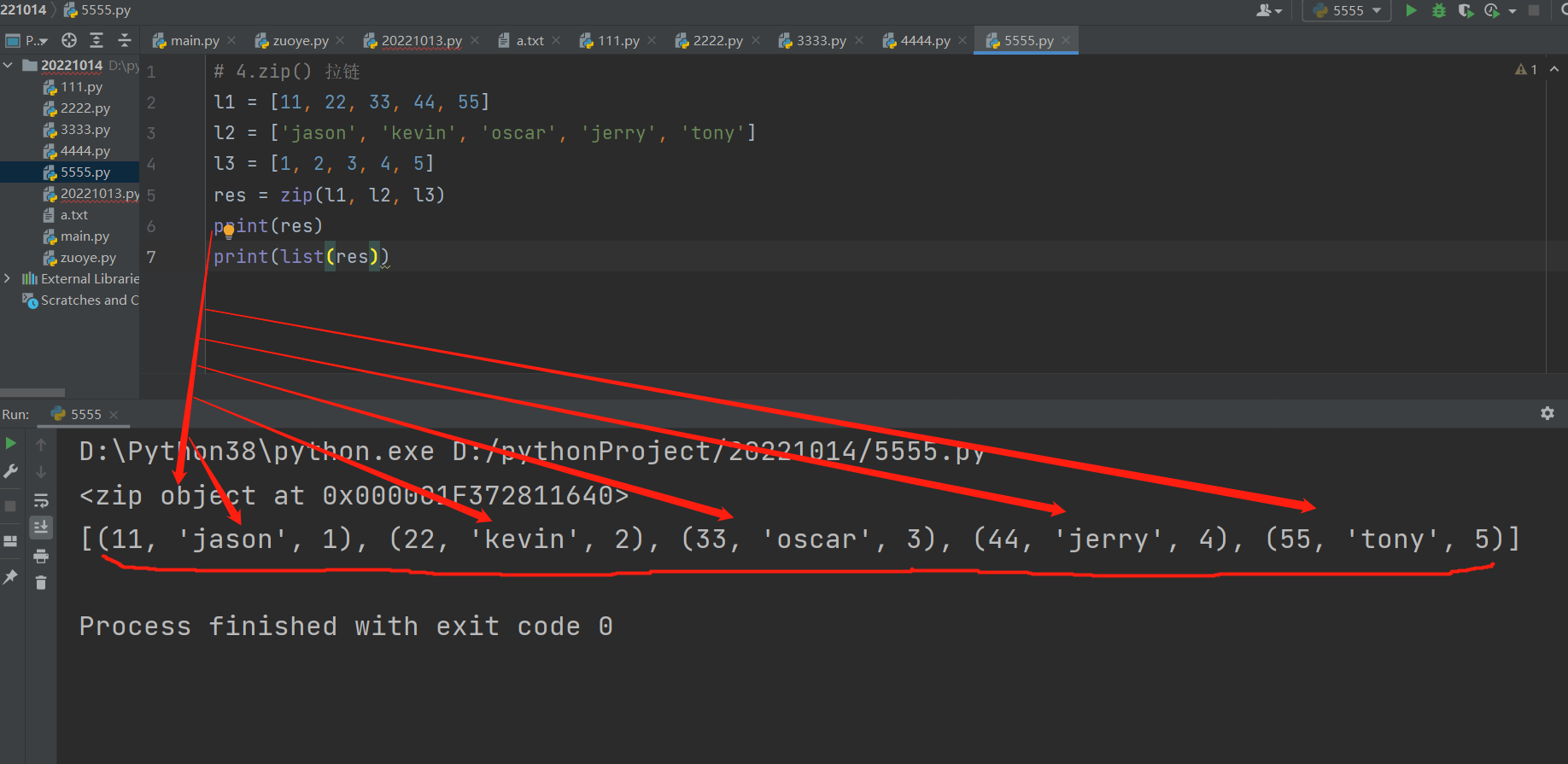
4 .zip() 拉链
l1 = [11, 22, 33, 44, 55]
l2 = ['jason', 'kevin', 'oscar', 'jerry', 'tony']
l3 = [1, 2, 3, 4, 5]
res = zip(l1, l2, l3)
print(list(res))
[(11, 'jason', 1), (22, 'kevin', 2), (33, 'oscar', 3), (44, 'jerry', 4), (55, 'tony', 5)]
它从每个迭代器中聚合元素,返回一个元组的迭代器,当最短的输入迭代被耗尽时,迭代器就停止了。zip的 最终结果一组一组的元组,每个元组里面的数据是要拉链的迭代器的每一次迭代的取值,但最终zip方法最终的返回值无法直接打印,可以想成生成了工厂,工厂里面可以产生每次拉链操作产生的元组,必须最后用list转化一下,才能一次性全部拿出所有拉链出的元组数据。
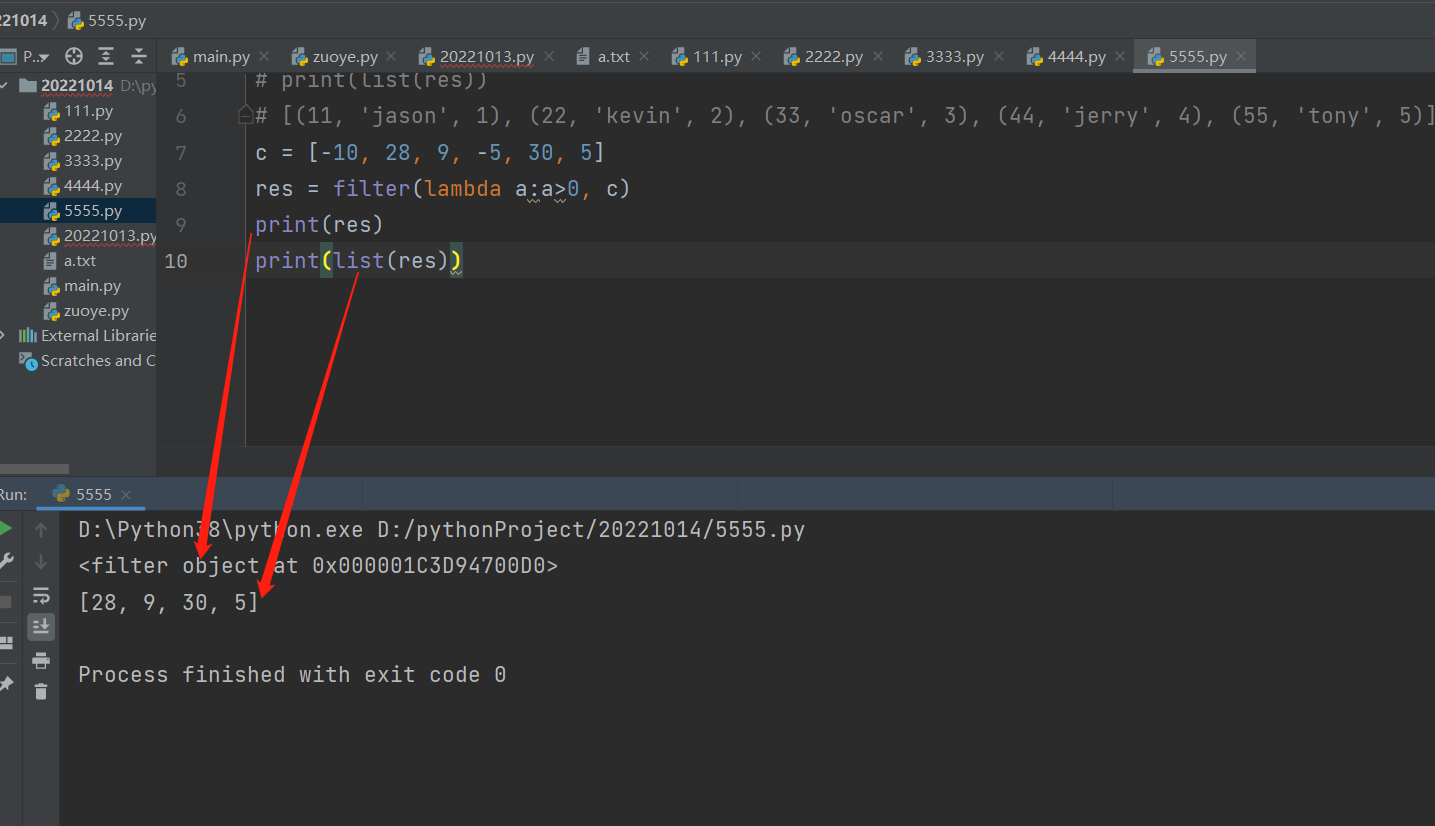
5 .filter() 过滤
它主要用来根据特定条件过滤迭代器中不符合条件的元素,返回一个惰性计算的filter对象或迭代器。需要用list函数进行转换,才能得到符合的条件元素组成的新列表。
filter(function or None, iterable)
function:函数,作用是对iterable中的每个元素判断是否符合特定条件。
None:不调用任何函数,只对可迭代对象中的元素本身判断真假,保留为真的元素。
iterables:可迭代对象(序列、字典等)。
c = [-10, 28, 9, -5, 30, 5]
res = filter(lambda a:a>0, c)
print(res)
print(list(res))
<filter object at 0x000001915DFF00D0>
[28, 9, 30, 5]
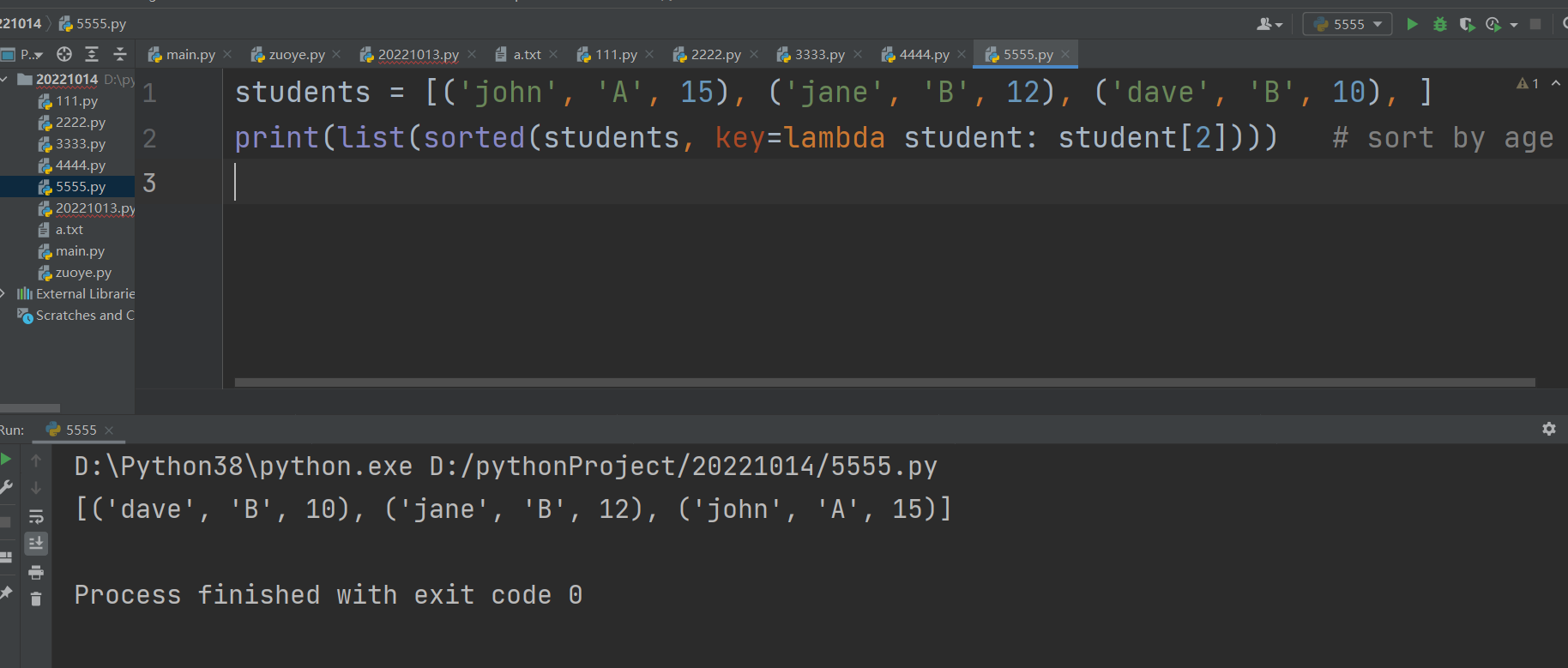
6 .sorted()
如果对python中的列表进行排序,可以使用List类的成员函数sort,该函数会在原空间上进行操作,对列表本身进行修改,不返回副本。语法如下:
L.sort(cmp=None, key=None, reverse=False)
sorted函数就比sort函数要强大许多了,sort只能对列表进行排序,sorted可以对所有可迭代类型进行排序,并且返回新的已排序的列表。语法如下:
sorted(iterable, cmp=None, key=None, reverse=False)
iterable可迭代对象 比较函数cmp
重要内置函数
1 其他进制转十进制用 .int() 十进制往其他进制转用 二bin() 八oct() 十六hex()
2 .bytes()
class bytes([source[, encoding[, errors]]])
可选形参source可以传入字符串,int,iterable 可迭代对象等
如果source是字符串,则必须指定encoding参数
3 .abs() 其主要作用是对传入的参数,返回其的绝对量或绝对值。
4 .all() 可迭代对象中所有的数都为true,才是True
用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。 语法结构 all(iterable)
any() 可迭代对象中有一个值为True,就为True
用来判断一个可迭代对象中是否至少有一个值为True,如果是则返回True,否则返回False。
相当于对可迭代对象的所有元素做or运算,但是返回的结果只有True或False。
5 .callable()对象是否是可调用 callable(object)
用于检查一个对象是否是可调用的。如果返回 True,对象仍然可能调用失败;但如果返回 False,则调用对象绝对不会成功。
6 .enumerate() 枚举
enumerate(sequence, [start=0])
sequence -- 一个序列、迭代器或其他支持迭代对象。 start -- 下标起始位置的值。
7.chr() 基于ASCII码做数字与字母的转换A-Z 65-90 a-z 97-122
print(chr(65))
A
ord('A') 基于ASCII码字母与数字的转换
65
8.eval() exec() 识别字符串中python代码并执行
9.isinstance() 用来判断一个对象是否是一个已知的类型
isinstance(object,classtype)
A = "I love you"
ans = isinstance(A, str)
print(ans)
True
10.dir() 返回括号内对象 通过点的方式能够调用的名字
11.divmod() 用来做除法运算的(a,b)
内置的divmod函数可以返回当参数1 除以参数2 时包含商和余数的元组。
divmod(5,3)
(1, 2) 商和余数
12.pow() sum() round()
pow函数表示幂的运算 pow(x,y)表示x的y次幂。
sum求和 round 四舍六入
今日内容概要
- 异常处理语法结构
- 异常处理实战应用
- 生成器对象
- 生成器对象实现range方法
- 生成器表达式
- 生成器笔试题
- 模块简介
今日内容详细
异常常见类型
SyntaxError 语法错误 /'sɪntæks/
NameError
IndexError 索引错误
KeyError 键错误
IndentationError 缩进错误 /ˌɪndɛn'teʃən/
异常处理语法结构
try的作用就是当程序员感觉某一段带码可能会报错,又不想因为这一段代码影响整体代码的运行,就需要将这一段代码缩进到try下面,作为try的子代码,这样就算这一段代码真的报错了,try会将代码错误的信息过滤掉,从而不影响后续代码的整体运行。
1.基本语法结构
try:
待监测的代码(可能会出错的代码)
except 错误类型:
针对上述错误类型制定的方案
2.查看错误的信息 exception 异常、例外
try:
待监测的代码(可能会出错的代码) 待监测的代码一但真的报错,将错误的类型与except后面的错误类型进行比较,如果错误类型一致,则运行except的子代码
except 错误类型 as e:
# e就是异常类的对象,包含了一些异常信息,下一行打印e就能看到错误信息
# 因为异常类里面有个双下str方法,所以打印e会触发类里面的双下str方法
# 双下str方法里面返回错误信息出来了!!!
# except 错误类型类 as e 这里e是错误类型类的对象!!!
针对上述错误类型制定的方案
.
.
.
.
.
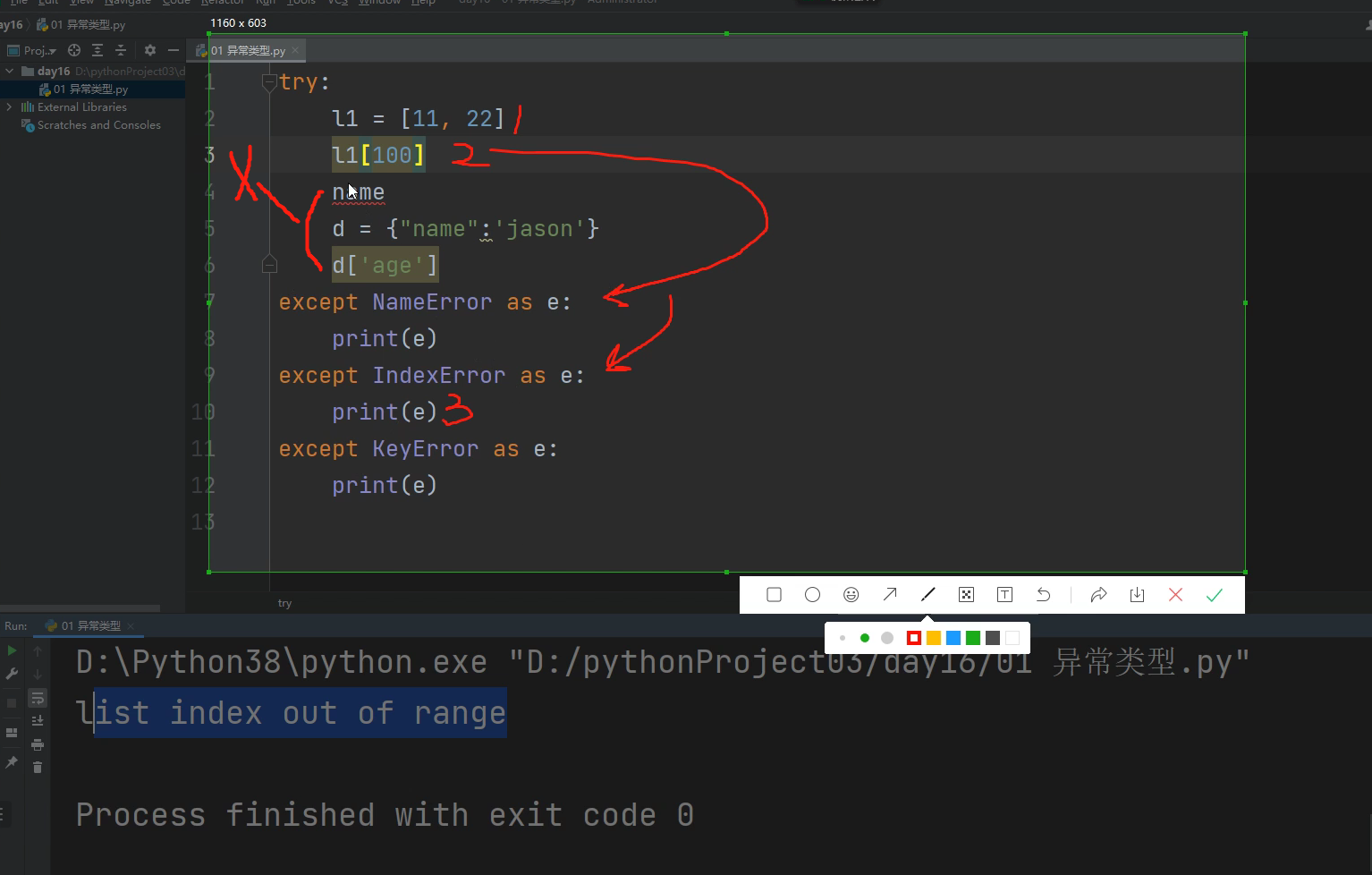
3.针对不同的错误类型制定不同的解决方案
try:
待监测的代码(可能会出错的代码)
except 错误类型1 as e: # e就是系统提示的错误信息
针对上述错误类型1制定的方案
except 错误类型2 as e: # e就是系统提示的错误信息
针对上述错误类型2制定的方案
except 错误类型3 as e: # e就是系统提示的错误信息
针对上述错误类型3制定的方案
这种两种方法都有个坏处,一旦实际运行的代码错误类型不是except后面预测的错误类型,还是会报错
一旦被监测的代码里面,发现第一个报错代码后,就会直接取核对是不是except后面的错误类型,后续的代码就不走了!!!
.
.
.
.
.
4. 万能异常 Exception/BaseException 重要!!!
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
.
.
.
.
.
5. 万能异常可以结合 else使用
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e就是系统提示的错误信息
针对各种常见的错误类型全部统一处理
else:
print('mcw') # 的子代码正常运行结束没有任何的报错后, 再执行else子代码
.
.
.
.
.
6.结合finally使用
try:
待监测的代码(可能会出错的代码)
except Exception as e: # e是异常类的对象
针对各种常见的错误类型全部统一处理
else:
# try的子代码正常运行结束没有任何的报错后 再执行else子代码
finally:
# 无论try的子代码是否报错,最后都要执行finally子代码
.
.
.
.
.
.
异常处理补充
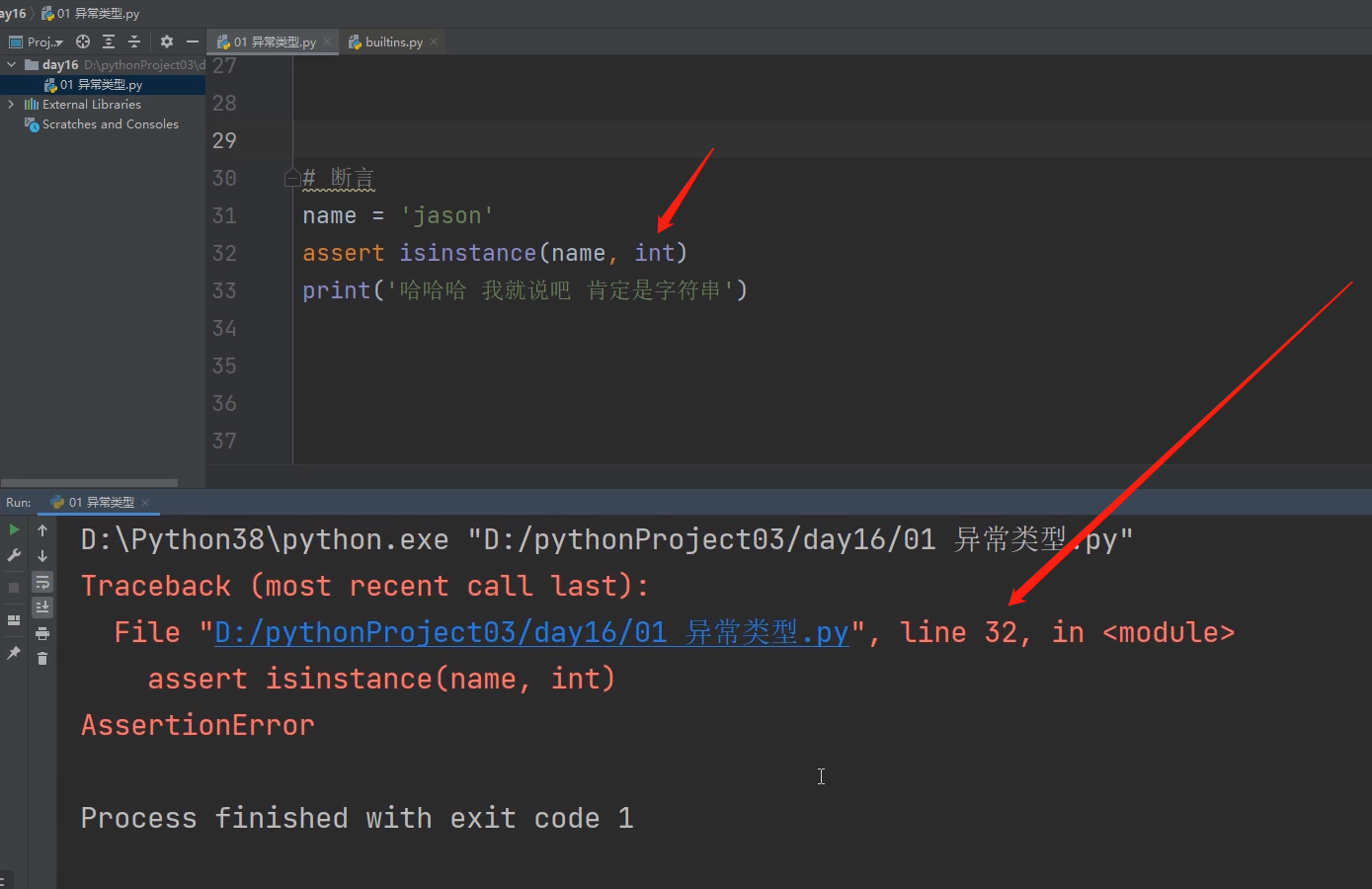
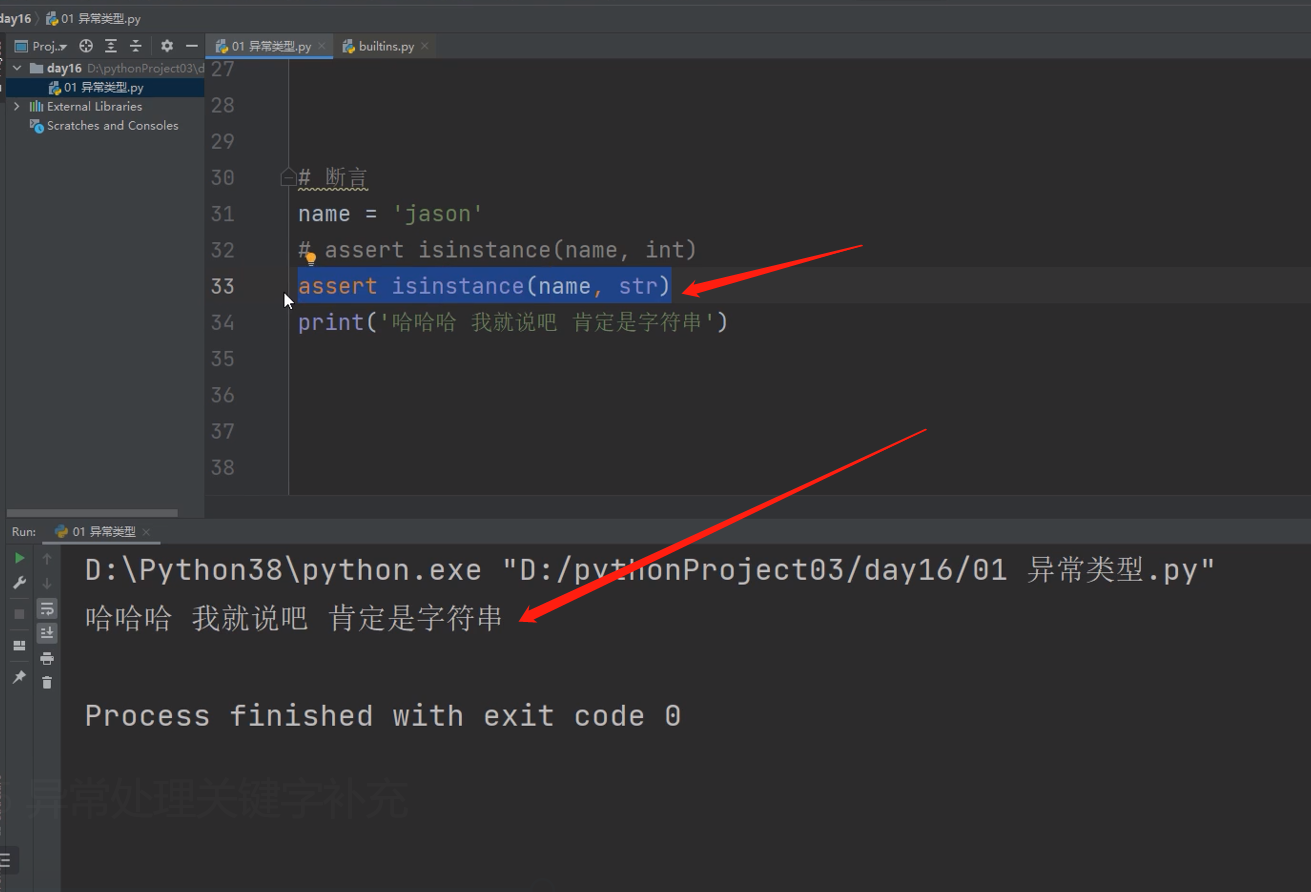
1.断言 后面的条件判断出True,代码正常运行,如果判断出False,就直接报错了
name = 'jason'
assert isinstance(name, str)
print('哈哈哈 我就说吧 肯定是字符串')
.
.
.
.
2.主动抛异常 关键字 raise
name = 'jason'
if name == 'jason':
raise Exception('老子不干了')
else:
print('正常走')
.
.
.
.
.
异常处理实战应用
1.异常处理能尽量少用就少用
2.被try监测的代码能尽量少就尽量少
3.当代码中可能会出现一些无法控制的情况报错才应该考虑使用
eg: 代码在请求网址时,断网
编写网络爬虫程序请求数据时,断网
课堂练习:
使用while循环+异常处理+迭代器对象 完成for循环迭代取值的功能
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
iterable1 = l1.__iter__() # 生成一个迭代器
while True: # 通过while循环对迭代器进行迭代取值
try:
print(iterable1.__next__())
except Exception as e: # 当迭代取值最后没有值取的时候,利用try语法接收报错
break # break 推出while循环
.
.
.
.
.
生成器 generator
1.本质
还是内置有__iter__和__next__的迭代器
--------------------------------------------
2.区别
迭代器对象是解释器自动提供的
数据类型\文件对象>>>:迭代器
生成器对象是程序员编写出来的
需要代码、关键字去产生>>>:迭代器(生成器)
.
.
.
.
.
3.创建生成器的基本语法!!!!!!
函数体代码中填写yield关键字
def my_iter():
print('哈哈哈 椰子汁很好喝')
yield # 若函数体包含yield关键字,再调用函数,并不会执行函数体代码,得到的返回值即生成器
res = my_iter() 先调用一下变成迭代器对象
res.__next__() 对生成器进行迭代取值
注意:
像列表这些数据,要先调用双下iter方法后才能变声成为迭代器或生成器。
生成器函数,直接调用函数名加括号就能变身成为生成器,不需要再点双下iter方法了!!!
注意1:
1.生成器函数名加括号不会执行函数体代码,而是先变身成为生成器!!!!!!
2.函数体代码中如果有yield关键字 ,那么函数名加括号并不会执行函数体代码。
3.会生成一个生成器对象(迭代器对象)!!!!!!
注意2:
使用加括号之后的结果调用__next__才会执行函数体代码
-------------------------------------------------
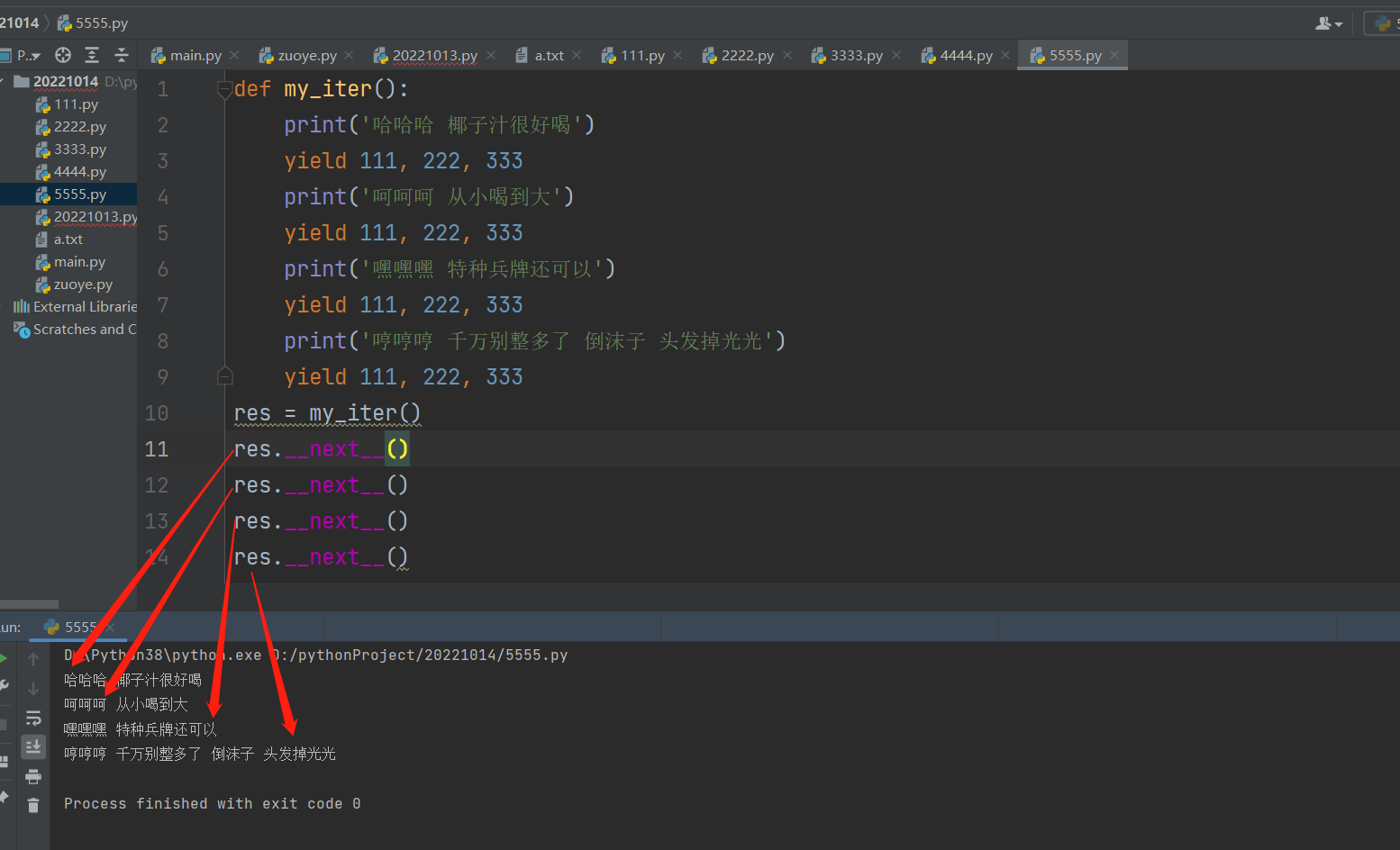
注意3:
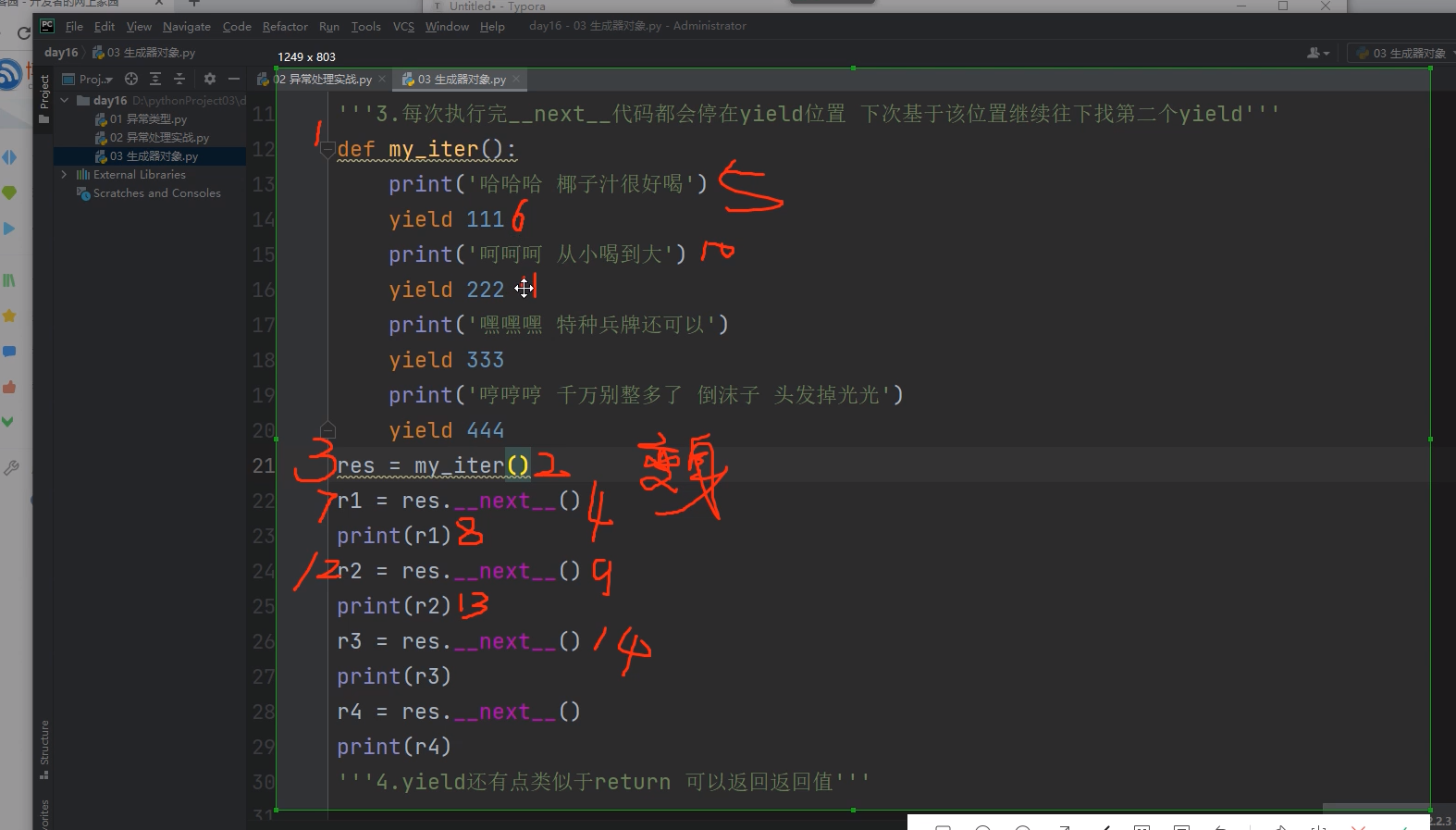
每次执行完__next__代码都会停在yield位置 下次基于该位置继续往下找第二个yield
def my_iter():
print('哈哈哈 椰子汁很好喝')
yield
print('呵呵呵 从小喝到大')
yield
print('嘿嘿嘿 特种兵牌还可以')
yield
print('哼哼哼 千万别整多了 倒沫子 头发掉光光')
yield
注意:4.yield还有点类似于return 可以返回返回值
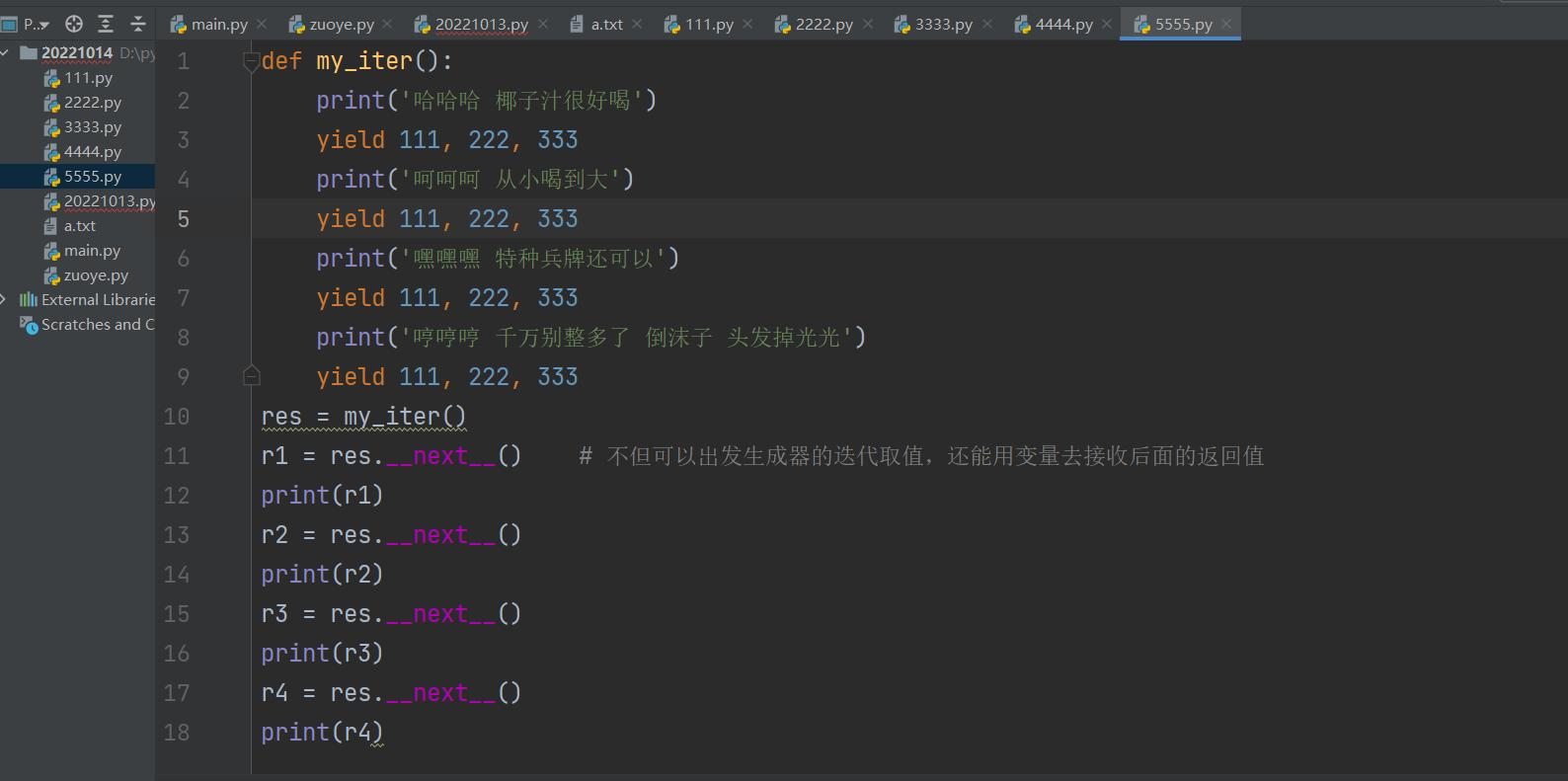
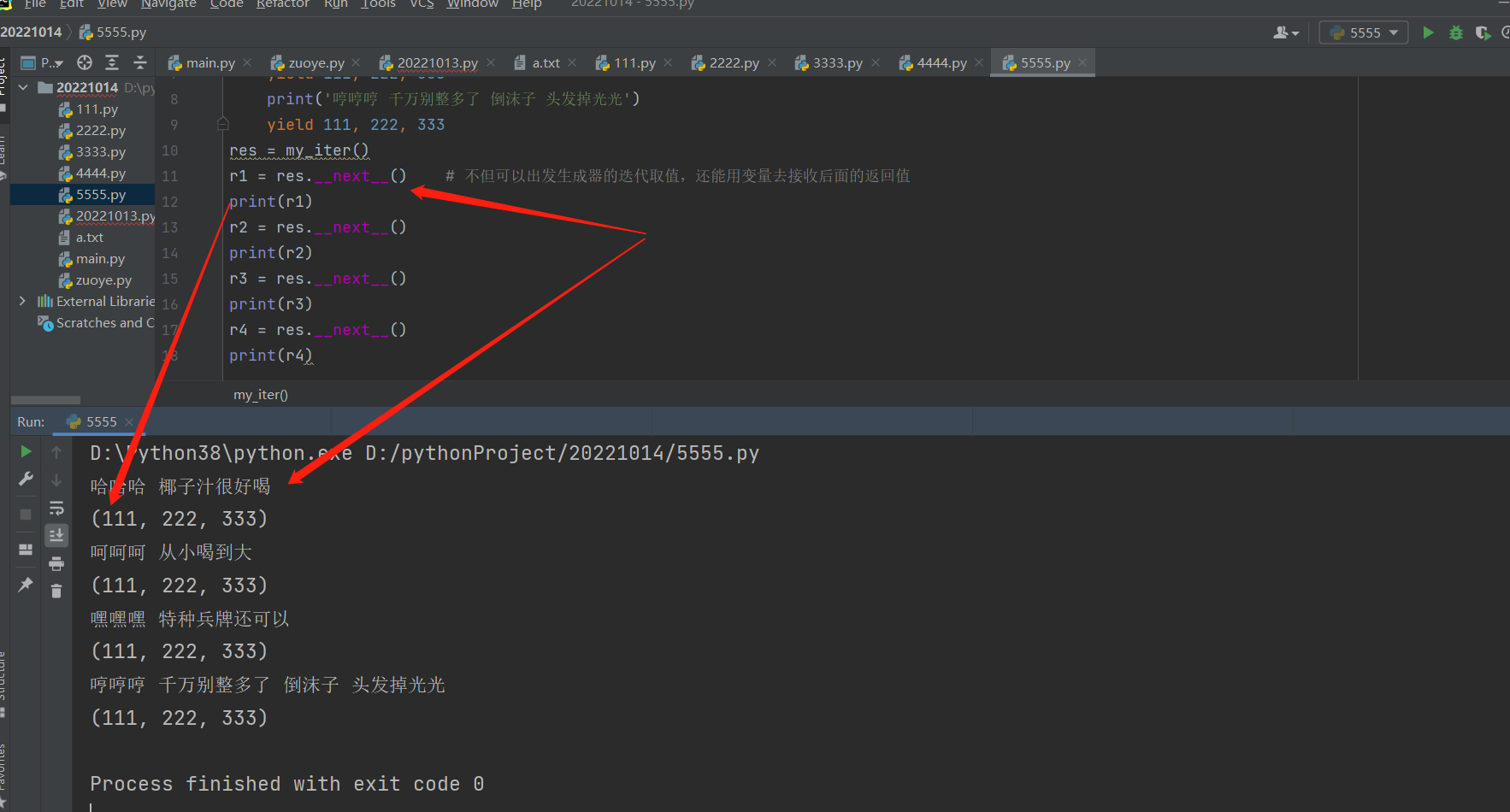
def my_iter():
print('哈哈哈 椰子汁很好喝')
yield 111, 222, 333
print('呵呵呵 从小喝到大')
yield 111, 222, 333
print('嘿嘿嘿 特种兵牌还可以')
yield 111, 222, 333
print('哼哼哼 千万别整多了 倒沫子 头发掉光光')
yield 111, 222, 333 yield 后面的数据如果是多个数据会封成元组返回给变量名
res = my_iter()
r1 = res.__next__() # 不但可以出发生成器的迭代取值,还能用变量去接收后面的返回值
print(r1)
r2 = res.__next__()
print(r2)
r3 = res.__next__()
print(r3)
r4 = res.__next__()
print(r4)
有了yield关键字,我们就有了一种自定义迭代器的实现方式。
yield可以用于返回值,但不同于return,函数一旦遇到return就结束了,
而yield可以保存函数的运行状态挂起函数,用来返回多次值
.
.
.
.
.
.
.
.
生成器的作用
就是节省内存地址
你要才给你产生数据,你不要就是一个内存地址,比较节省空间。
for循环原理!!!!!!!!!!!!!!!!!
for i in l1 循环在工作时,
首先会调用可迭代对象l1内置的__iter__方法变成迭代器对象,
然后while True循环,调用该迭代器对象的__next__方法,运行迭代器的函数体代码,将yield后面的返回值返给i,并执行for循环的子代码,完成一次while循环,周而复始,直到while循环调用迭代器对象的__next__方法后,迭代不出值得时候,except捕捉StopIteration异常,结束while循环。
.
.
.
.
.
.
课堂练习
自定义生成器对标range功能(一个参数 两个参数 三个参数 迭代器对象)
for i in range(1, 10):
print(i)
1.先写两个参数的
2.再写一个参数的
3.最后写三个参数
两个参数的情况下:
def my_range(start_num, end_num=None, step=1):
# 判断end_num是否有值 没有值说明用户只给了一个值 起始数字应该是0 终止位置应该是传的值
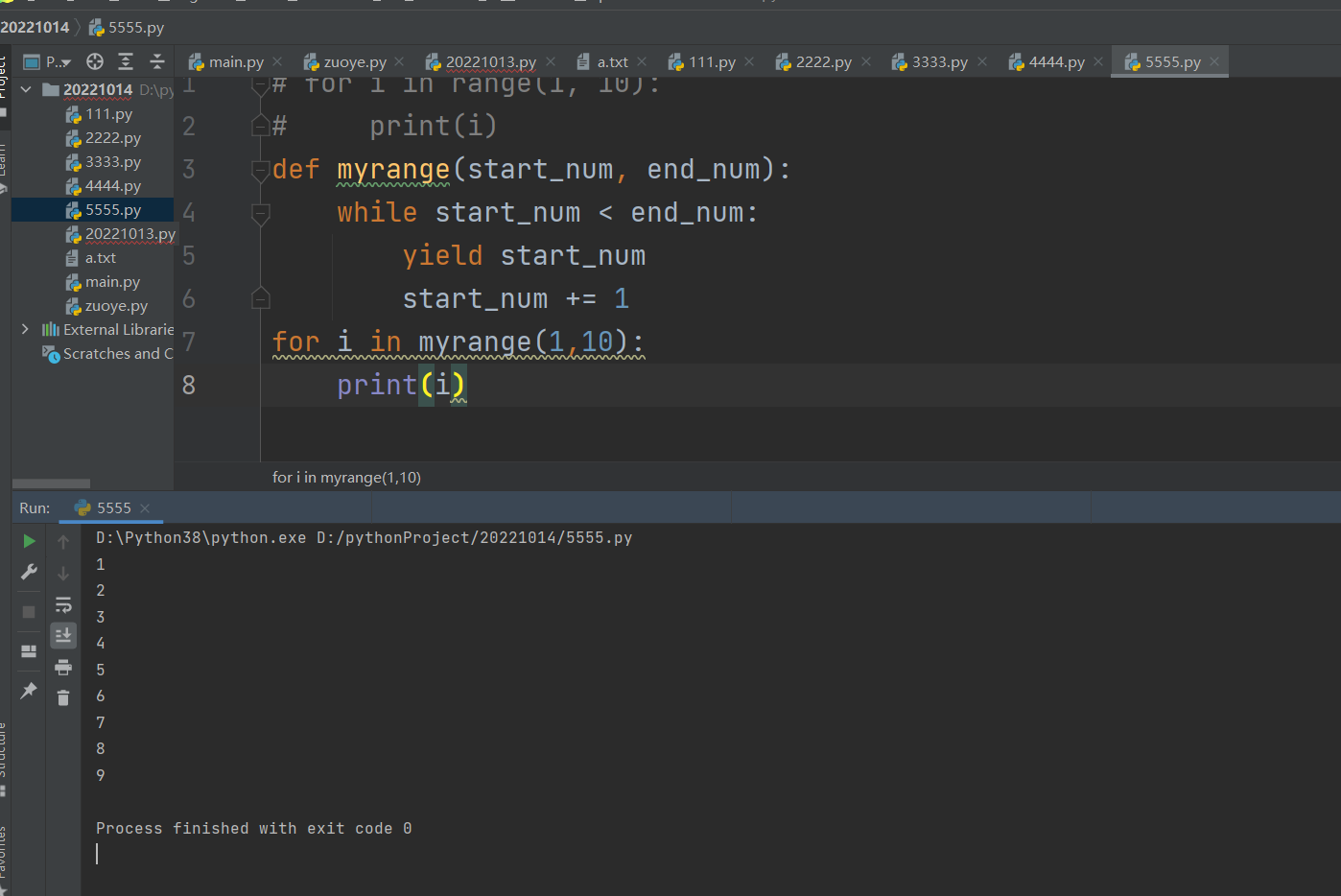
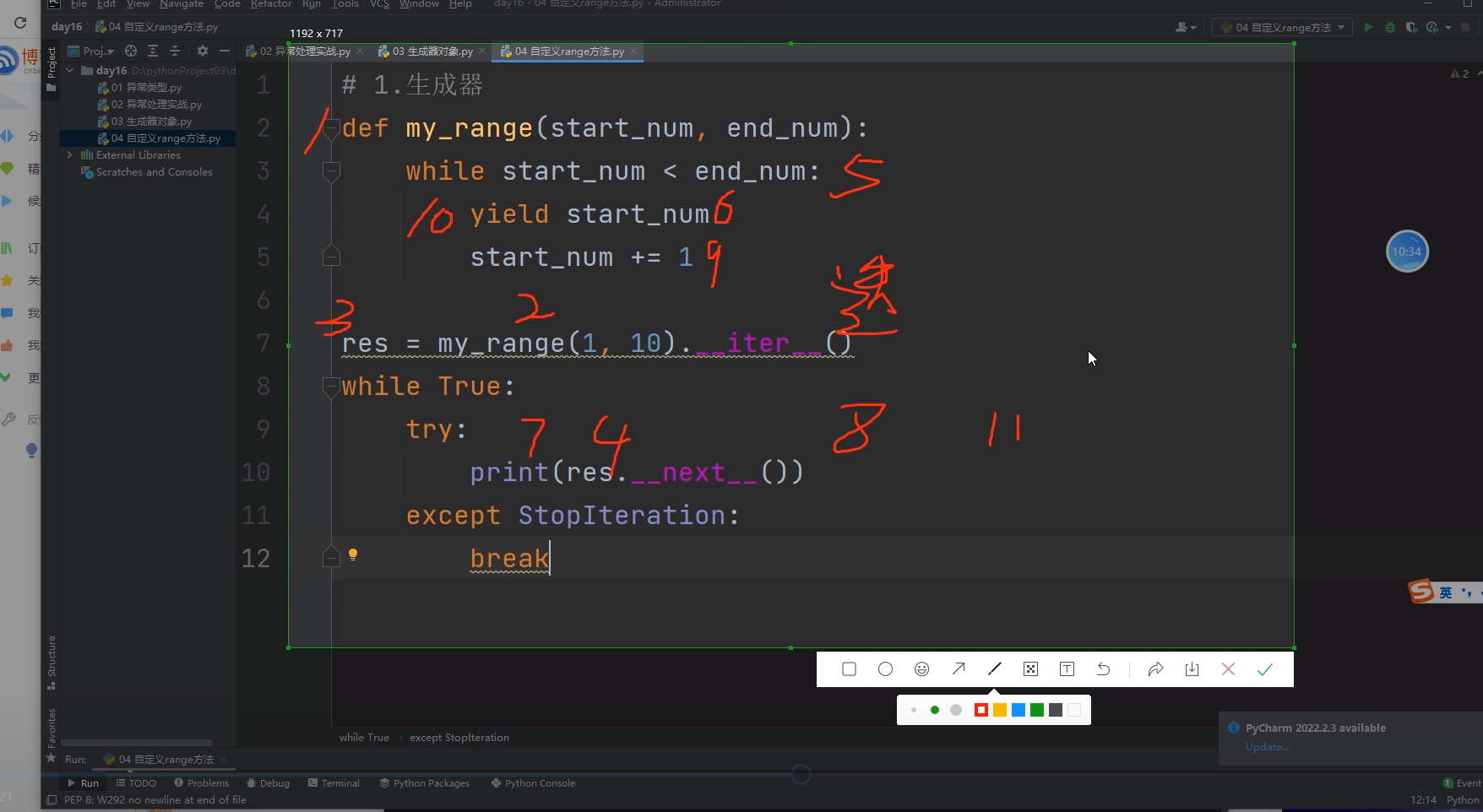
def myrange(start_num, end_num):
while start_num < end_num:
yield start_num
start_num += 1
for i in myrange(1,10):
print(i)
上面for循环的两行代码可以写成:
res = myrange(1,10).__iter__()
while True:
try:
print(res.__next__())
except Exception:
break
最终代码:
def myrange(start_num, end_num=none,step=1): 由两个参数变一个参数时,将第二个参数变成关键字参数,就可以实现传一个参代码也能运行了!!!!
if not end_num: # 判断end_num是否有值,如果没有值说明用户只给了一个值,其实数字应该是0,终止位置应该是传到值 这局语法实际上就是if end_number == None
end_num = start_num # 手动将start_num的内存地址赋值给end_num
start_num = 0 # 手动将0赋值给start_num,这样就实现传一个值,直接就变成传给第二个默认行参的目的了
while start_num < end_num:
yield start_num
start_num += step # 把原来的1换成参数step,用step进行控制每次循环后自增的幅度
这样代码就完成了
。
。
。
for i in my_range(100, 50, -1):
print(i)
思考如何让my_range方法满足可以倒着取值,代码如何继续优化?
for i in XXX
for循环会自动将in后面的可迭代对象调用.双下iter方法,变身成为迭代器或者生成器,
for循环的底层原理是拿到生成器,开始 while True 循环
反复调用.双下next方法。直到用将生成器中的数据迭代完了后,
报错被except接收,结束for循环。
生成器每调一次.双下next方法,才会去走生成器的子代码。代码遇到yield就会停止!!!
把yield后面的数据返回出去,返回的数据被i接收。
也就是说一个生成器函数想要被调用运行,必须先调用双下iter方法变成生成器,
再调双下next方法,才能运行生成器的代码
.
.
.
.
.
.
.
.
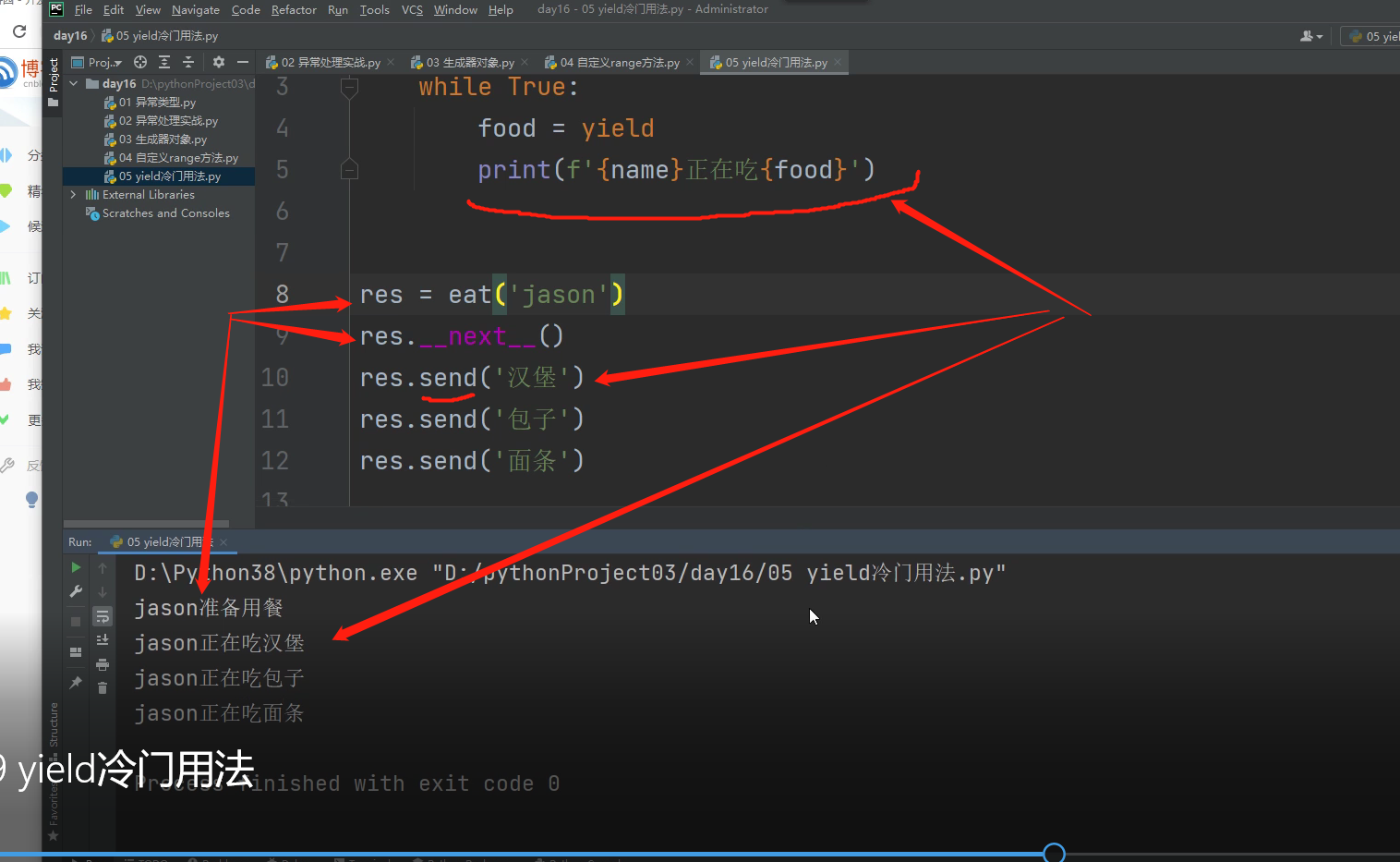
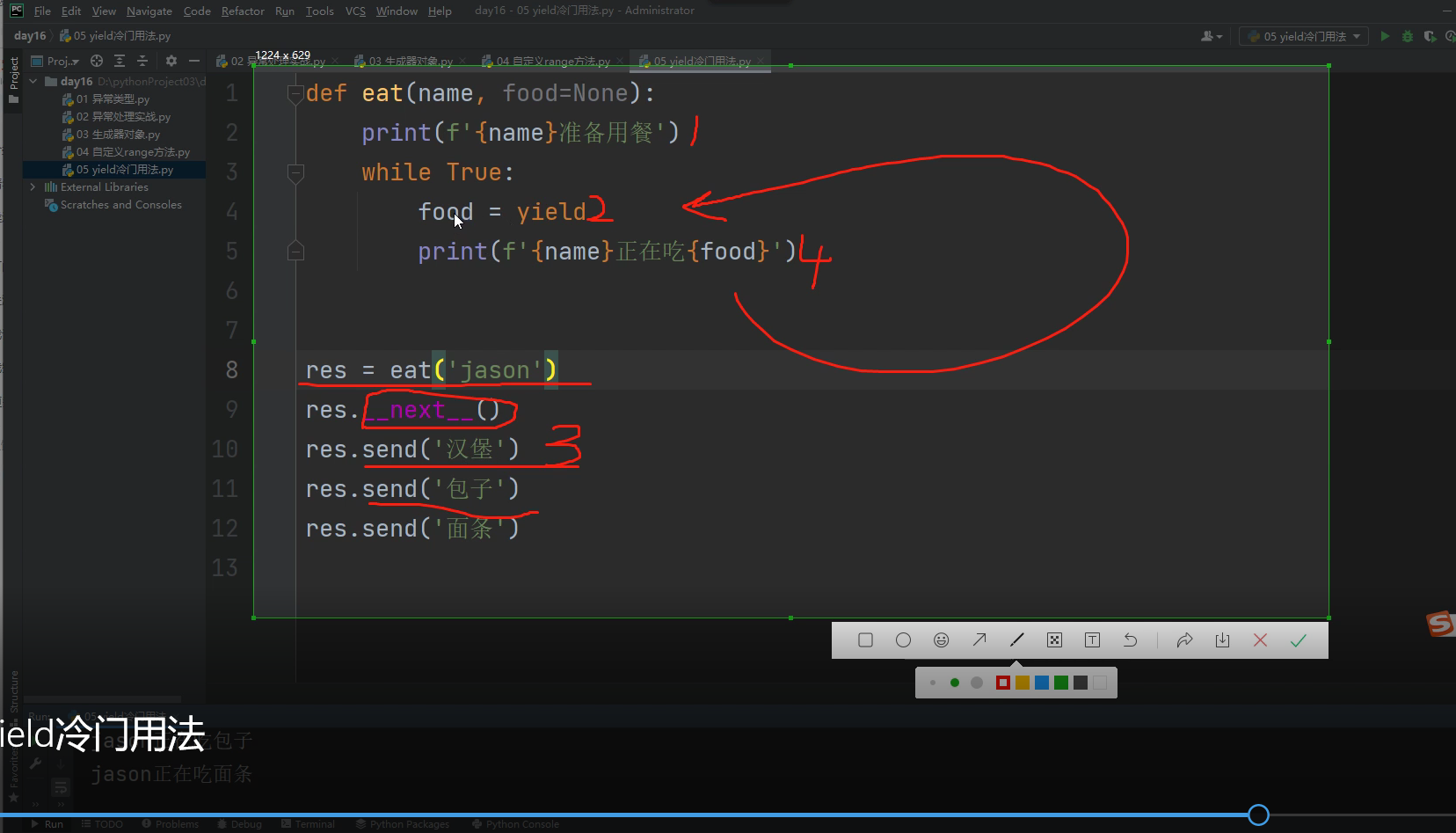
yield冷门用法
send的用法:将括号内的数据传给yield前面的变量名 2.再自动调用__next__
def eat(name, food=None):
print(f'{name}准备用餐')
while True:
food = yield
print(f'{name}正在吃{food}')
res = eat('jason') # 先变成生成器
res.__next__() # 调用next方法对生成器进行迭代
jason准备用餐
res.send('汉堡') # 将括号内的数据传给yield前面的变量名 2.再自动调用__next__
res.send('包子')
res.send('面条')
.
.
.
.
.
.
.
生成器表达式!!!
说白了就是生成器的简化写法!!!!!!
l1 = [i ** 2 for i in range(100)] # 列表生成式
print(l1)
l1 = (i ** 2 for i in range(100)) # 元组生成器
print(l1) # <generator object <genexpr> at 0x000001DFC07F7E40>
for i in l1: # 要用for循环迭代元组生成器才能看到元组生成器里面的值
print(i)
.
.
生成器表达式作用
就是说如果在代码优化的过程中,发现一些,列表,元组等里面的数据是有规律的,就可以考虑用生成器表达式来替代,这样代码在运行的时候就节省内存空间来了!!!!!!!!!!
.
.
.
.
.
面试题(有难度)
大致知道流程即可
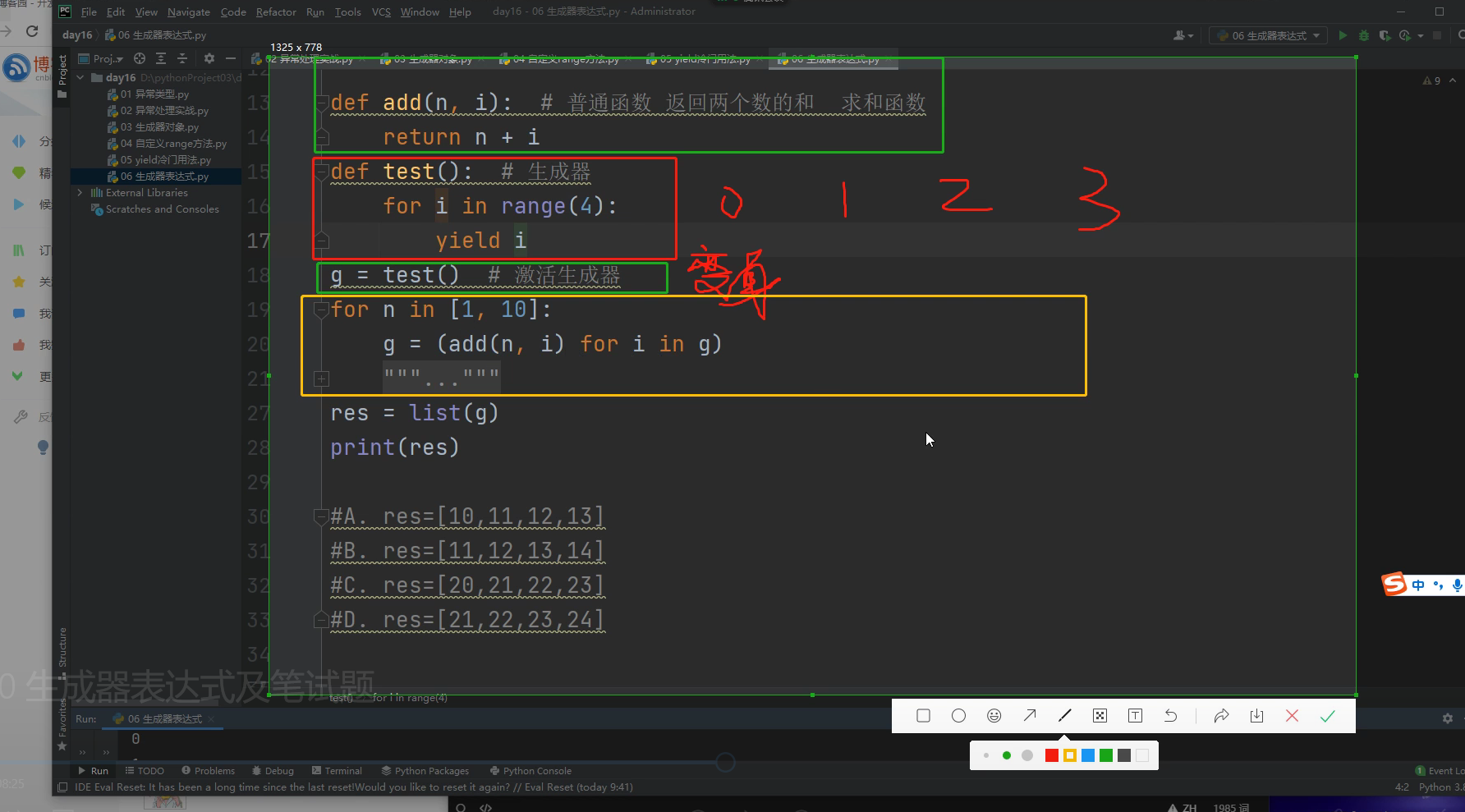
def add(n, i): #1 普通函数 返回两个数的和 求和函数
return n + i
def test(): #2 定义一个生成器函数
for i in range(4):
yield i
g = test() #3 激活生成器 此时这个生成器里面有0、1、2、3、四个数据
for n in [1, 10]: #4 别看错了,这是一个小列表,里面就两个数据1和10
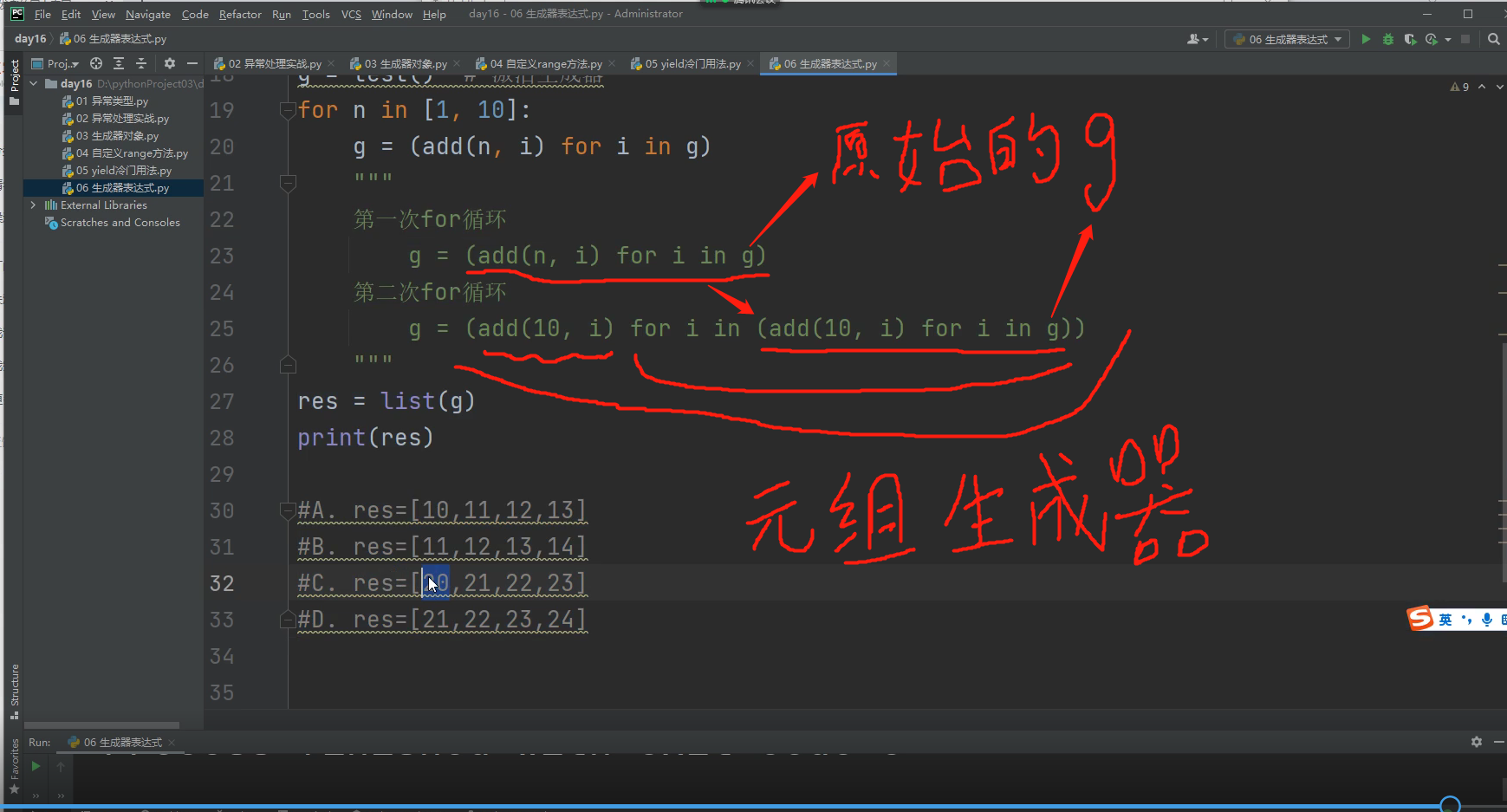
g = (add(n, i) for i in g) # (add(n, i) for i in g)元组生成器表达式
"""
第一次for循环
g = (add(n, i) for i in g)
第二次for循环
g = (add(10, i) for i in (add(10, i) for i in g))
怎么看这个
生成器表达式里面的代码只有在调双下next方法时,才会执行!!!!!
所以外层第一次for循环时,内层代码是不会执行的!!!!!!!!!!
"""
res = list(g)
print(res)
# list(g)先当于for循环g这个生成器,把里面的值迭代出来放列表里,这个时候才会让生成器g去调用双下next方法,才会去执行生成器里面的函数体代码!!!
此时第二次for循环后的生成器g开始调用双下next方法开始运行g的函数体代码
最里层的g里面只含有0123,第一次for出来0和10加,第二次for出来1和10相加,最后内层的元组就是(10,11,12,13),这个时候再对元组进行for循环,此时每次for出来的就是10,11,12,13 再跟10加,所以最终的结果就是()
A. res=[10,11,12,13]
B. res=[11,12,13,14]
C. res=[20,21,22,23]
D. res=[21,22,23,24]
'''不用深入研究 大致知道起始数即可'''
.
.
.
.
.
.
1. 迭代器介绍:
迭代器即用来迭代取值的工具!!!!!!而迭代是重复反馈过程的活动!!!!!!
其目的通常是为了逼近所需的目标或结果.
每一次对过程的重复称为一次“迭代”.
而每一次迭代得到的结果会作为下一次迭代的初始值,单纯的重复并不是迭代!!!!!!
msg = input('>>: ').strip()
while True:
print(msg)
下述while循环才是一个迭代过程,不仅满足重复,而且以每次重新赋值后的index值作为下一次循环中新的索引进行取值,反复迭代,最终可以取尽列表中的值
goods=['mac','lenovo','acer','dell','sony']
count=0
while index < len(goods):
print(goods[count])
count += 1
.
.
.
.
.
2. 可迭代对象 就是可迭代的东西 Iterable
通过索引的方式进行迭代取值,实现简单,但仅适用于序列类型:字符串,列表,元组。
对于没有索引的字典、集合等非序列类型,必须找到一种不依赖索引来进行迭代取值的方式,这就用到了迭代器。
迭代器:可以不依赖索引来进行迭代取值!!!!
要想了解迭代器为何物,必须事先搞清楚一个很重要的概念:可迭代对象(Iterable)。从语法形式上讲,内置有__iter__方法的对象都是可迭代对象,字符串、列表、元组、字典、集合、打开的文件都是可迭代对象:
'123'.__iter__()
[1,2,3].__iter__()
(3,4,5).__iter__()
{7,8,9}.__iter__()
{'name':'jason'}.__iter__()
.
.
.
.
.
3. 迭代器Iterator
可迭代对象调用双下iter()方法 就得到了迭代器(Iterator)。
迭代器是内置有__iter__和__next__方法
-------------------------------------------
执行迭代器.iter()方法得到的仍然是迭代器本身,
执行迭代器.next()方法就会计算出迭代器中的下一个值。
迭代:是Python提供的一种统一的、不依赖于索引的迭代取值方式。
只要存在多个“值”,无论序列类型还是非序列类型都可以按照迭代器的方式取值!!
-------------------------------------------
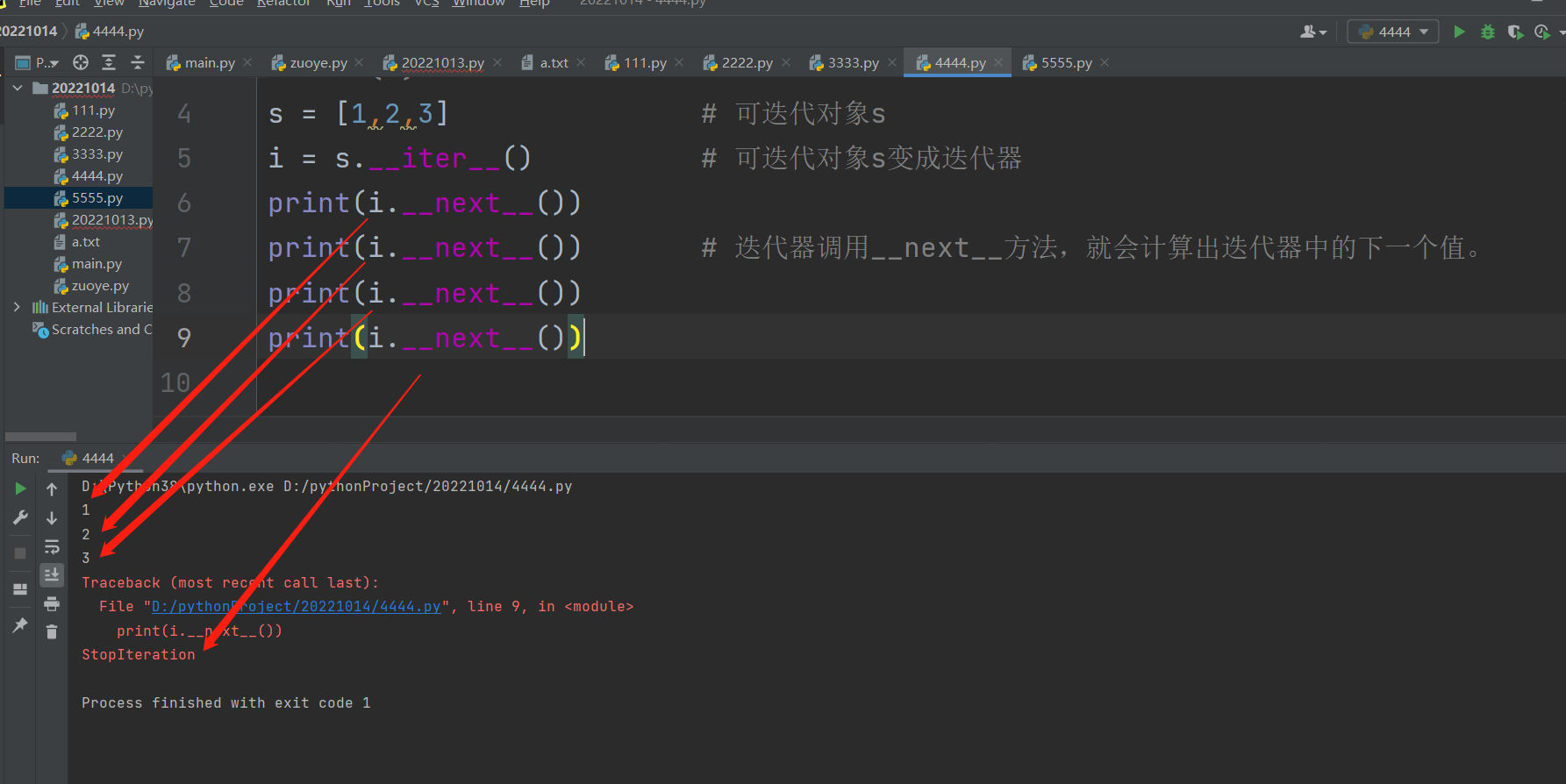
s = [1,2,3] # 可迭代对象s
i = s.__iter__() # 可迭代对象s变成迭代器
print(i.__next__())
print(i.__next__()) # 迭代器继续调用.__next__方法,就会计算出迭代器中的下一个值
print(i.__next__())
print(i.__next__()) # 发现迭代器中无值可取,报异常了
1
2
3
StopIteration # 抛出StopIteration的异常,代表无值可取,迭代结束
i = s.__iter__() 语法与 i=iter(s)一个意思
i.__next__() 语法与next(i) 一个意思
.
.
.
.
.
.
4. for循环原理!!!!!!!!
有了迭代器后,我们便可以不依赖索引取值了,使用while循环的实现方式如下
goods=['mac','lenovo','acer','dell','sony']
i=iter(goods) # 生成一个迭代器对象
while True:
try:
print(next(i)) # 迭代器调用.__iter__方法后,计算出迭代器中产生的第一个值,循环后计算第二个...
except StopIteration: # 捕捉异常终止循环
break
for循环又称为迭代循环,in后可以跟任意可迭代对象,上述while循环可以简写为
goods=['mac','lenovo','acer','dell','sony']
for item in goods:
print(item)
for 循环在工作时,首先会调用可迭代对象goods内置的__iter__方法拿到一个迭代器对象,然后再调用该迭代器对象的__next__方法将取到的值赋给item,执行循环体完成一次循环,周而复始,直到捕捉StopIteration异常,结束迭代。
.
.
.
.
.
5. 迭代器的优缺点
基于索引的迭代取值,所有迭代的状态都保存在了索引中,而基于迭代器实现迭代的方式不再需要索引,所有迭代的状态就保存在迭代器中,然而这种处理方式优点与缺点并存:
优点
1、为序列和非序列类型提供了一种统一的迭代取值方式。
2、惰性计算:迭代器对象表示的是一个数据流,可以只在需要时才去调用__next__来计算出一个值,就迭代器本身来说,同一时刻在内存中只有一个值,因而可以存放无限大的数据流,而对于其他容器类型,如列表,需要把所有的元素都存放于内存中,受内存大小的限制,可以存放的值的个数是有限的。
缺点
1、除非取尽,否则无法获取迭代器的长度
2、只能取下一个值,不能回到开始,更像是‘一次性的’,迭代器产生后的唯一目标就是重复执行next方法直到值取尽,否则就会停留在某个位置,等待下一次调用next;若是要再次迭代同个对象,你只能重新调用iter方法去创建一个新的迭代器对象,如果有两个或者多个循环使用同一个迭代器,必然只会有一个循环能取到值。
.
.
.
.
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号