


关于kafka
一、kafka中的基本概念:
主题和分区:分区的主要意义主要是为了提高消费的并发度。一个生产者,可以启8个消费者来跑。分区的数量主要是为了平衡生产和消费的速度。kafka没有队列的概念,可以把分区理解为队列。
偏移量:发消息的时候每一个消息存到分区里面都有offset偏移量,消费的时候是以群组进行消费。
二、kafka中的生产和消费流程
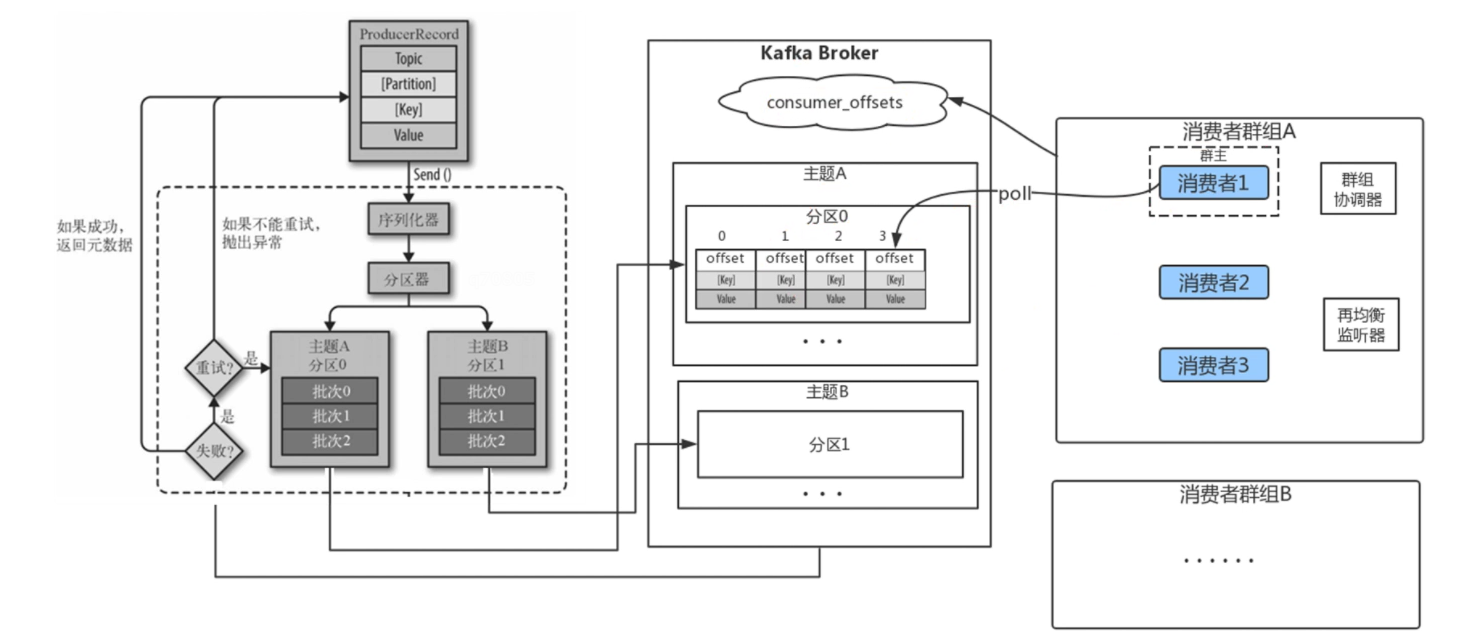
三、kafka一条消息发送和消费的流程(非集群)
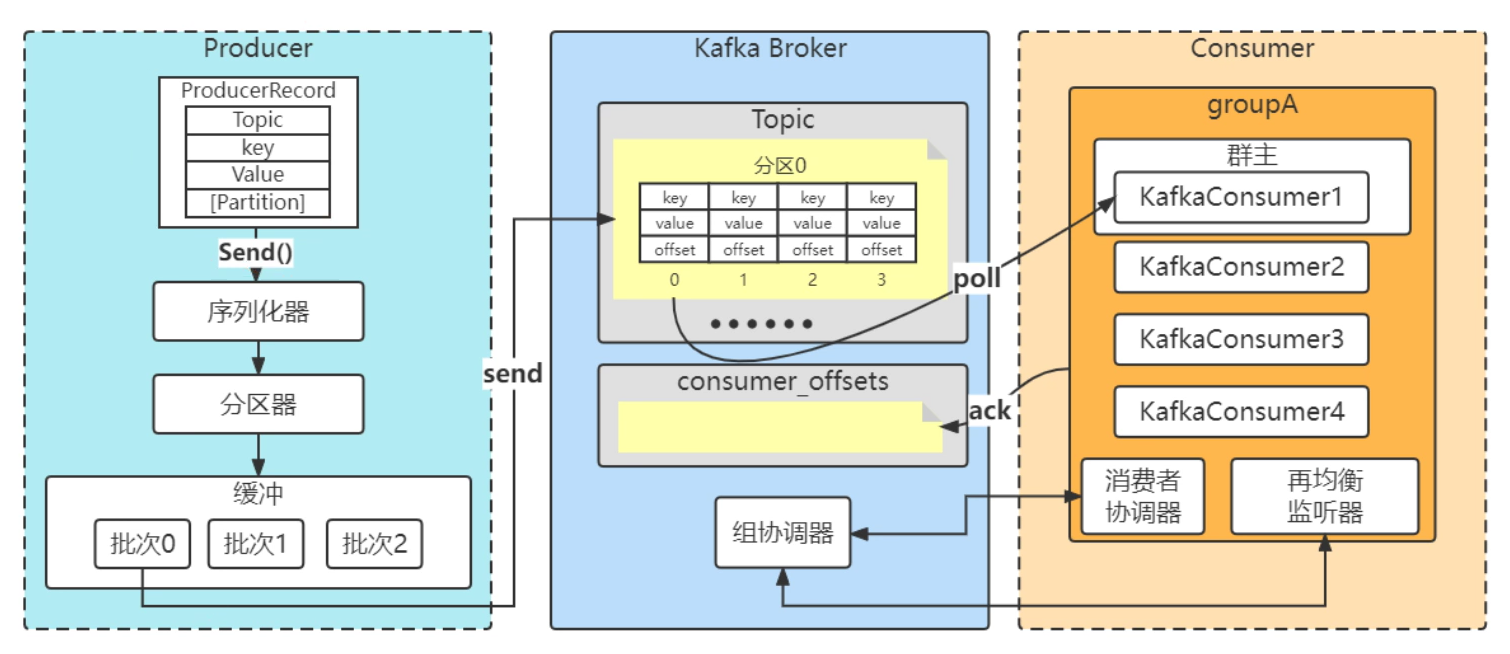
一个java简单的kafka生产消费入门例子:
kafka生产者:
package com.msb.simple;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* kafka生产者
*/
public class HelloKafkaProducer {
public static void main(String[] args) {
Properties properties = new Properties();
/**
* 指定连接的kafka服务器地址,这里默认本地,默认端口
* 可以配置多台服务器,逗号分隔,这种一般搭建的是集群,其中一个宕机,生产者依然可以连上
*/
properties.put("bootstrap.servers", "127.0.0.1:9092");
/**
* 设置键值的序列化
* 序列化的本质是,将对象 -> 二进制字节数组,能够在网络上传输,网络通讯层计算机只认byte[]
*/
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
//构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
//构建消息
ProducerRecord<String, String> record = new ProducerRecord<>("msb", "teacher", "lijin");
//发送消息
producer.send(record);
System.out.println("message is sent.");
//释放连接
producer.close();
}
}kafka消费者:
package com.msb.simple;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 消费者入门
*/
public class HelloKafkaConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
/**
* 设置键值的反序列化;生产者发过来的是byte[]。
* 和生产者序列化的方式一样,使用对应的反序列化
*/
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
//设置group id
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
//构建kafka消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
//订阅主题,可以订阅多个
consumer.subscribe(Collections.singletonList("msb"));
try {
while (true) {
/**
* 调用消费者拉取消息
* 每隔1s拉取一次消息
* 其实是poll时,超过1s就超时,是timeout的概念
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
String key = record.key();
String value = record.value();
System.out.println("接收到消息: key = " + key + ", value = " + value);
}
}
} catch (Exception e) {
e.printStackTrace();
//释放连接
consumer.close();
}
}
}org.apache.kafka的maven配置:
pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kafka</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>msb-kafka-client</name>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<mainClass>com.msb.MsbKafkaClientApplication</mainClass>
<skip>true</skip>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
四、发送消息时自定义序列化,发送一个java对象:
该自定义实现只是为了演示怎么用,小例子,因为如果user加了属性,这部分代码要跟着改,所以仅仅只是演示怎么自定义使用。
自定义序列化器
package com.msb.selfserial;
import org.apache.kafka.common.serialization.Serializer;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
/**
* 自定义序列化器
*/
public class UserSerializer implements Serializer<User> {
/**
* 将user对象进行序列化,就是将user转化为byte[]
* 可以这么定义这个字节数组:
* 前4位是id + 4位name的长度 + name字符串转化后的字节数组
* 因为:
* int类型是4位;
* 字符串的长度也是int类型,也只需要4位;
* String字符串可以很长很长,所以设计一个长度。
*/
@Override
public byte[] serialize(String topic, User data) {
byte[] name;
int nameSize;
if (data == null) {
return null;
}
if (data.getName() != null) {
name = data.getName().getBytes(StandardCharsets.UTF_8);
nameSize = data.getName().length();
} else {
name = new byte[0];
nameSize = 0;
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + nameSize);
buffer.putInt(data.getId());
buffer.putInt(nameSize);
buffer.put(name);
return buffer.array();
}
}自定义反序列化器
package com.msb.selfserial;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.Deserializer;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
/**
* 自定义反序列化器
*/
public class UserDeserializer implements Deserializer<User> {
@Override
public User deserialize(String topic, byte[] data) {
if (data == null) {
return null;
}
if (data.length < 8) {
throw new SerializationException("error data size.");
}
ByteBuffer buffer = ByteBuffer.wrap(data);
int id = buffer.getInt();
int nameSize = buffer.getInt();
byte[] nameByte = new byte[nameSize];
buffer.get(nameByte);
String name = new String(nameByte, StandardCharsets.UTF_8);
return new User(id, name);
}
}生产者
package com.msb.selfserial;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* kafka生产者
*/
public class ProducerUser {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", UserSerializer.class);
KafkaProducer<String, User> producer = new KafkaProducer<String, User>(properties);
//构建消息
ProducerRecord<String, User> record = new ProducerRecord<>("msb-user", "teacher", new User(1, "lijin"));
//发送消息
producer.send(record);
System.out.println("message is sent.");
//释放连接
producer.close();
}
}消费者
package com.msb.selfserial;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class ConsumerUser {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", UserDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
//构建kafka消费者对象
KafkaConsumer<String, User> consumer = new KafkaConsumer<String, User>(properties);
//订阅主题,可以订阅多个
consumer.subscribe(Collections.singletonList("msb-user"));
try {
while (true) {
ConsumerRecords<String, User> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, User> record : records) {
String key = record.key();
User user = record.value();
System.out.println("接收到消息: key = " + key + ", value = " + user);
}
}
} catch (Exception e) {
e.printStackTrace();
consumer.close();
}
}
}实体类-User:
package com.msb.selfserial;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
/**
* 实体类:User
*/
@Getter
@Setter
@ToString
public class User {
private int id;
private String name;
public User(int id) {
this.id = id;
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
}
五、分区器的使用
比如生产者在发送消息的时候,kafka的topic中存在4个分区,现在想要将发送第1条消息发到分区0,第二条消息发到分区1,第三条消息发到分区2,第四条消息发到分区3,请问怎么做?
前面我们写入门消费者程序时,并没有指定分区器,那么没有使用吗?其实是有默认的分区器的,DefaultPartitioner,它是根据key值来分区。
1.系统自带的分区器
查看代码
package com.msb.selfpartiton;
import com.msb.selfserial.User;
import com.msb.selfserial.UserSerializer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.clients.producer.RoundRobinPartitioner;
import org.apache.kafka.clients.producer.UniformStickyPartitioner;
import org.apache.kafka.clients.producer.internals.DefaultPartitioner;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* 系统自带的分区器
*/
public class SysPartitionProducer {
/**
* 默认分区器:
* 发送10条消息,采用默认的分区器,key值都是一样的,这样是发到不同的分区,还是相同的分区呢?
* 做这个试险前,需要将kafka的启动配置,server.properties中的num.partitions=1改成num.partitions=4,这样表示创建一个topic主题,底下就有4个分区。
* 都是相同的分区,因为默认的分区器DefaultPartitioner只是根据key值来分区。
* 所以下面测试程序中循环中key值都一样所以都发往一个分区了。
*
* 统一粘性分区器:
*
*/
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", UserSerializer.class);
//默认分区器
//properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DefaultPartitioner.class);
//轮询分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);
properties.put("partitioner.availability.timeout.ms", "0");
properties.put("partitioner.ignore.keys", "true");
//统一粘性分区器
//properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, UniformStickyPartitioner.class);
KafkaProducer<String, User> producer = new KafkaProducer<>(properties);
try {
for (int i = 0; i < 10; i++) {
ProducerRecord<String, User> record = new ProducerRecord<>("msb", "teacher", new User(1, "lijin"));
Future<RecordMetadata> future = producer.send(record);
RecordMetadata recordMetadata = future.get();
System.out.println(i + "," + "offset:" + recordMetadata.offset() + "," + "partition:" + recordMetadata.partition());
}
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
producer.close();
}
System.out.println("message is sent.");
}
}
2.自定义分区器
说明一下,其实我们在构建消息的时候也可以指定分区,new ProducerRecord<>("msb", 0, "teacher", "lijin"),类似这样。但是如果指定了分区,那么设置的分区器就没有作用了,无论配什么分区器都没用了,new ProducerRecord里面设置的partition优先级别最高。只会把每条消息都发送到partition:0
自定义分区器:
package com.msb.selfpartiton;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;
/**
* 自定义分区器,以value值进行分区
*/
public class SelfPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取分区数量
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
int num = partitionInfos.size();
// 将value转成正整数 再和分区数量进行模运算
return Utils.toPositive(Utils.murmur2(valueBytes)) % num; //来自DefaultPartitioner的处理,只不过默认的分区是按照key的值来分区的。
}
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public void close() {
}
}使用自定义分区器:
package com.msb.selfpartiton;
import com.msb.selfserial.User;
import com.msb.selfserial.UserSerializer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.clients.producer.RoundRobinPartitioner;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* 生产者,使用自定义的分区器
*/
public class SelfPartitionProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
//自定义区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, SelfPartitioner.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
try {
for (int i = 0; i < 10; i++) {
//构建消息
ProducerRecord<String, String> record = new ProducerRecord<>("msb", "teacher", "lijin" + i);
//指定partition
//ProducerRecord<String, String> record = new ProducerRecord<>("msb", 0, "teacher", "lijin");
Future<RecordMetadata> future = producer.send(record);
RecordMetadata recordMetadata = future.get();
System.out.println(i + "," + "offset:" + recordMetadata.offset() + "," + "partition:" + recordMetadata.partition());
}
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
producer.close();
}
System.out.println("message is sent.");
}
}
六、以异步的方式发送消息
上面的例子producer.send之后返回future,都是在主线程里面future.get(),如果想通过异步线程,怎么做?
这么做:在调producer.send的时候,传入Callback。
异步发送消息:
package com.msb.simple;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* kafka生产者
*/
public class AsynProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>("msb", "teacher", "lijin");
//发送消息
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e == null) {
//没有异常,输出信息到控制台
System.out.println("offset:" + metadata.offset() + ", partition:" + metadata.partition());
} else {
//出现异常打印
e.printStackTrace();
}
}
});
//释放连接
producer.close();
}
}
七、缓冲
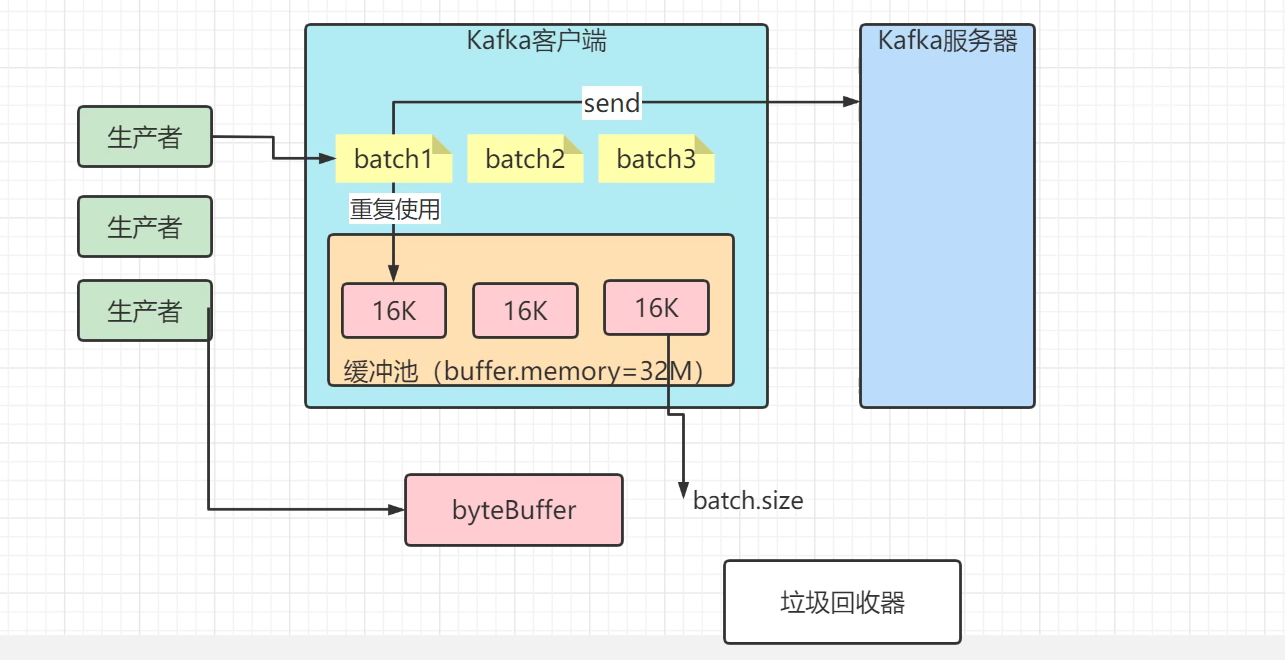
为什么kafka在客户端发送的时候需要做一个缓冲呢?
1.减少IO的开销(单个 -> 批次) ---- 需要改配置
2.减少GC(池化技术 ---- 缓冲池)
缓冲发送:主要是这两个参数控制
大小控制:batch.size= 默认16384 (16K)
时间控制:linger.ms= 默认0,就是说一旦有消息来了不会延迟等待,立马发送
缓冲池:池的大小
buffer.memory= 默认32M
消息发送的时候,调用send方法,做好了序列化器,设置好了分区器,开始发送的时候,当多个消息要发到同一个分区的时候,生产者就会把它放到同一个批次,batch.size可以指定这个批次的内存大小,是以字节进行计算的。
还有个是减少了GC,如果没有缓冲池,生产者发送完消息后,byteBuffer没有被使用了,垃圾回收器就会回收。有了缓冲池减少了GC。不然每次生产者发送消息的时候都要new ByteBuffer,再来发送,耗时。
八、群组消费

kafka的群组消费 ---- 负载均衡建立在分区级别
开始试验,server.properties中的配置为:num.partitions=4。生产者会往topic中的四个分区发送消息。
注意:在增加consumer后,我们可能要稍微等一下,等Consumer做好负载再均衡。之后再重新启动consumer去消费,才会看到效果。大概是5s钟,Broker中的组协调器知道分区数多少,group里面有几个消费者,再均衡监听器发现多了consumer,这时候就会将topic中的分区进行重新分配,再对分区进行消费重分配的过程中,consumer是无法消费的,是阻塞住的。在触发一次负载再均衡时,在触发完成之前,消费者会阻塞。
生产者发送消息:
package com.msb.consumergroup;
import com.msb.selfpartiton.SelfPartitioner;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.clients.producer.UniformStickyPartitioner;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
/**
* kafka生产者:发送多条消息
*/
public class KafkaProducerGroup {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.serializer", StringSerializer.class);
properties.put("value.serializer", StringSerializer.class);
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, SelfPartitioner.class);
//构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
//发送消息
for (int i = 0; i < 8; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("msb", null, "lijin" + i);
Future<RecordMetadata> future = producer.send(record);
RecordMetadata recordMetadata = future.get();
System.out.println(i + "," + "offset:" + recordMetadata.offset() + "," + "partition:" + recordMetadata.partition());
}
System.out.println("message is sent.");
producer.close();
}
}GroupA的Consumer1~5:
package com.msb.consumergroup;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class GroupAConsumer1 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "groupA");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList("msb"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
String key = record.key();
String value = record.value();
int partition = record.partition();
System.out.println("接收到消息: partition = " + partition + " , key = " + key + ", value = " + value);
}
}
} catch (Exception e) {
e.printStackTrace();
consumer.close();
}
}
}GroupB的Consumer1:
package com.msb.consumergroup;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class GroupBConsumer1 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "groupB");
//如果配置的是earliest,那么会将分区的,从头开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//这是默认配置,从已提交的offset开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList("msb"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
String key = record.key();
String value = record.value();
int partition = record.partition();
System.out.println("接收到消息: partition = " + partition + " , key = " + key + ", value = " + value);
}
}
} catch (Exception e) {
e.printStackTrace();
consumer.close();
}
}
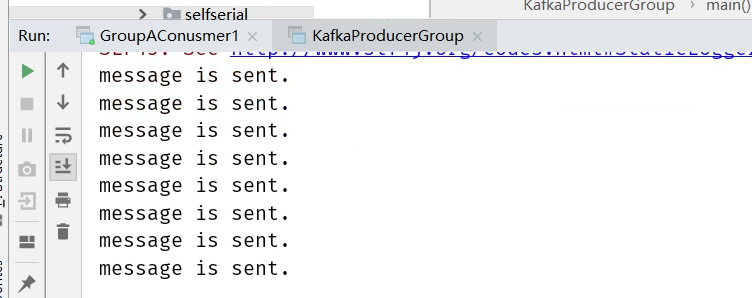
}1.生产者发送8条消息,只启动1个消费者GroupAConsumer1时,收到全部消息:

2.生产者发送8条消息,启动GroupAConsumer1、GroupAConsumer2:
GroupAConsumer1消费了分区0、1
GroupAConsumer2消费了分区2、3

3、生产者发送8条消息,启动GroupAConsumer1、GroupAConsumer2、GroupAConsumer3:
GroupAConsumer1消费了分区0、1
GroupAConsumer2消费了分区2
GroupAConsumer3消费了分区3

4、生产者发送8条消息,启动GroupAConsumer1、GroupAConsumer2、GroupAConsumer3、GroupAConsumer4:
GroupAConsumer1消费了分区0
GroupAConsumer2消费了分区1
GroupAConsumer3消费了分区2
GroupAConsumer4消费了分区3

5、生产者发送8条消息,启动GroupAConsumer1、GroupAConsumer2、GroupAConsumer3、GroupAConsumer4、GroupAConsumer5:
GroupAConsumer1消费了分区0
GroupAConsumer2消费了分区1
GroupAConsumer3消费了分区2
GroupAConsumer5消费了分区3
GroupAConsumer4没有任何消费
小结:
单个群组中不同消费者,可以动态的增加、删除消费者,消费的核心原则是以分区作为负载均衡。一个分区不能被一个群组中的多个消费者消费,因为这会让消息没有顺序。
6、增加GroupBConsumer1,并且启动:
会发现GroupBConsumer1将之前分区中的所有消息都消费了。因为auto.offset.reset配置的是earliest,会将分区的消息offset从头开始消费。
九、手动提交
上面例子中的消费者消费代码,只要拿到了消息就是自动提交的。这种消费模式很容易造成问题,比如我在获取消息并且进行处理时,明明抛出异常了,消费没来及,但是在kafka来说,消费者拿到消息了就不管了,认为你已经提交了。这种称之为自动提交的消费模式。可以改成手动的。
将properties中的配置:enable.auto.commit 设置成false就可以了。在消费完后进行提交。如果不进行提交的话,再次消费的话又会从原offset开始拿。
手动提交代码例子:
package com.msb.commit;
import org.apache.kafka.clients.consumer.CommitFailedException;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class ConsumerCommit {
/**
* 同步提交:
* commitSync之后立马进行ack确认,往consumer_offsets中写偏移量,consumer_offsets是一个特殊的目录,专门保存消费者的偏移量。
* commitSync会带来阻塞,因为他要等ack是否确认完成,甚至会不断尝试,直到提交成功为止。所以可能会给性能造成下降。
*
* 异步提交:
* 所以手动提交的话最好采用commitAsync,不会阻塞线程。
*
* 所以一般在接受消息处理业务完毕时就进行异步提交。最后再finally中再进行一次同步提交,以防万一。
*/
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
//取消自动提交
properties.put("enable.auto.commit", false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList("msb"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
String key = record.key();
String value = record.value();
int partition = record.partition();
System.out.println("接收到消息: partition = " + partition + " , key = " + key + ", value = " + value);
}
//异步提交,不阻塞应用程序的线程,不会重试(有可能失败)
consumer.commitAsync();
}
} catch (CommitFailedException e) {
System.out.println("Commit Failed:");
e.printStackTrace();
} catch (Exception e) {
consumer.close();
} finally {
//同步提交,会阻塞我们应用的线程,并且会重试(一定成功)
consumer.commitSync();
}
}
}
如果每次消费的消息条数很多,这种提交的频次是否可以自己控制呢?比如我想做到消费10条提交一次。可以采用如下的自定义提交方式:
手动提交(自定义的方式):
package com.msb.commit;
import org.apache.kafka.clients.consumer.CommitFailedException;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
/**
* 消费者,手动提交,自定义的方式
*/
public class ConsumerSpecial {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092");
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
//取消自动提交
properties.put("enable.auto.commit", false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
//当前偏移量
Map<TopicPartition, OffsetAndMetadata> currOffsets = new HashMap<>();
int count = 0;
try {
consumer.subscribe(Collections.singletonList("msb"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
String key = record.key();
String value = record.value();
int partition = record.partition();
System.out.println("接收到消息: partition = " + partition + " , key = " + key + ", value = " + value);
count++;
currOffsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1, "no meta"));
//每10条提交一次(特定的偏移量)
if (count % 10 == 0) {
consumer.commitAsync(currOffsets, null);
}
}
}
} catch (CommitFailedException e) {
System.out.println("Commit Failed:");
e.printStackTrace();
} catch (Exception e) {
consumer.close();
} finally {
consumer.commitSync(currOffsets);
}
}
}
--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号