spark 2.0.2 集群搭建
由于之前已经搭建过hadoop相关环境,现在搭建spark的预备工作只有scala环境了
一,配置scala环境
1.解压tar包后,编辑/etc/profile

2.source /etc/profile
3.scala -version

4.分发到其他两台机器上
二.搭建spark集群
1.配置spark环境变量

2.进入spark的conf目录下
cp -a spark-env.sh.template spark-env.sh
cp -a slaves.template slaves
3.修改spark-env.sh,这里依然指定master为hadoop002
1 export JAVA_HOME=/opt/module/jdk1.8.0_181
2 export SCALA_HOME=/opt/module/scala-2.10.1
3 export SPARK_MASTER_IP=192.168.101.102
4 export SPARK_WORKER_MEMORY=1g
5 export HADOOP_CONF_DIR=/opt/module/hadoop-2.7.7
4.修改slaves
1 hadoop003 2 hadoop004
5.分发到其他两台机器
6.启动集群
先启动zk,然后启动hdfs,yarn,最后来到spark目录下
执行sbin/start-all.sh启动spark
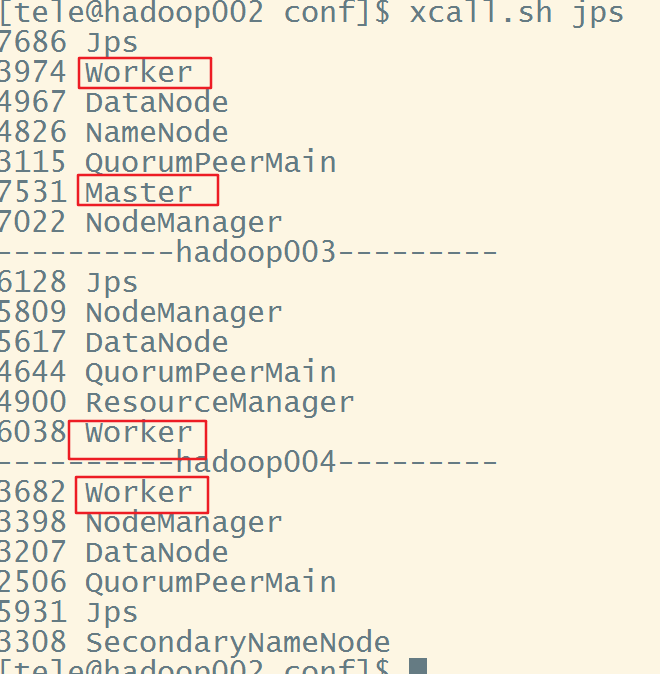
7.查看,虽然我们没有配置hadoop002为slaves,但显然此时它也是一个worker(下次重新启动时就只有Masrter节点就不会有worker进程了)
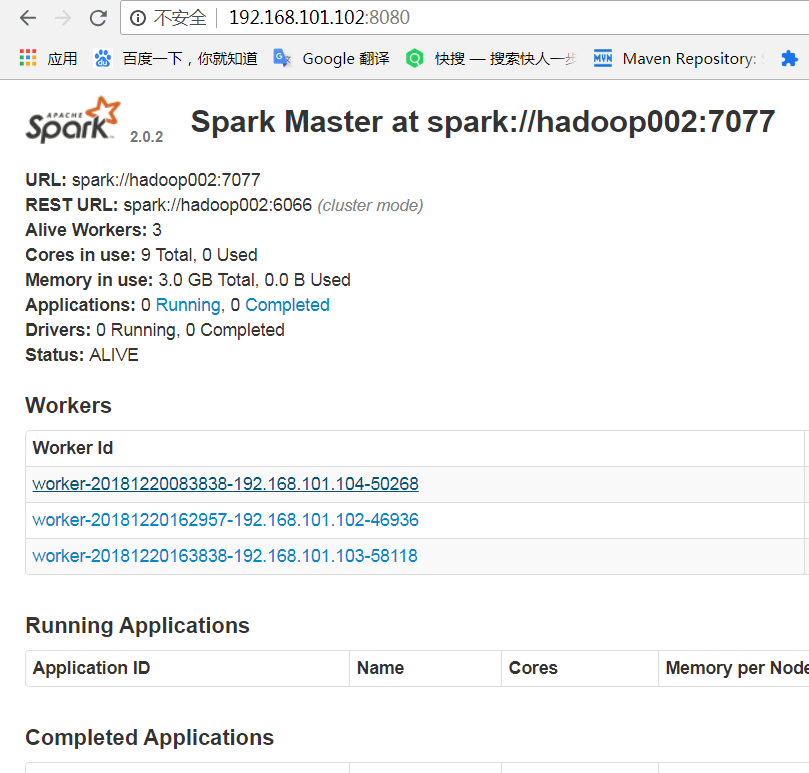
也可以打开8080端口,查看UI
8.停止时先在spark目录下sbin/stop-all.sh 然后停止yarn,再停止hdfs.最后zk

 浙公网安备 33010602011771号
浙公网安备 33010602011771号