
问题产生
最近新上线的系统偶尔会报FullGC时间过长(>1s)的告警,查看GC日志,如下图所示:

看到GC日志,我第一时间关注到的不是GC耗时,而是GC触发的原因:Metadata GC Threshold
也就是 FullGC 触发的原因是因为Metaspace大小达到了GC阈值。在监控系统里面看了一下Metaspace的大小变化趋势,如下图所示:
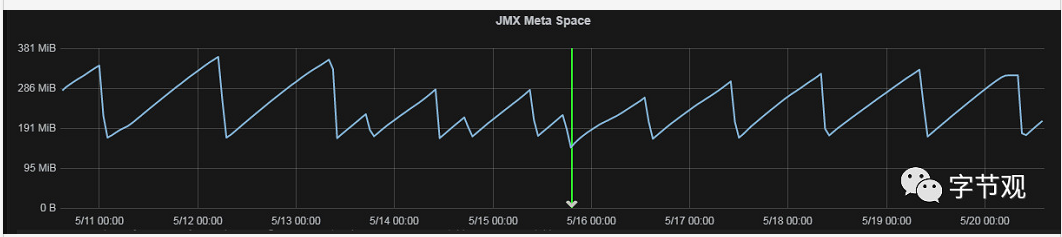
按照以往的经验,Metaspace在系统稳定运行一段时间后占用空间应该比较稳定才对,但是从上图来看,Metaspace显然是呈现大幅波动。为什么呢?
相关知识
我们知道Metaspace主要存储类的元数据,比如我们加载了一个类,那么这个类的信息就会按照一定的数据结构存储在Metaspace中。
Metaspace的大小和加载类的数目有很大关系,加载的类越多,Metaspace占用内存也就越大。
Metaspace被分配于堆外空间,默认最大空间只受限于系统物理内存。跟它相关的比较重要的两个JVM参数:
-XX:MetaspaceSize -XX:MaxMetaspaceSize
MaxMetaspaceSize,大家从名字也能猜到是指Metaspace最大值。
而MetaspaceSize可能就比较容易让人误解为是Metaspace的最小值,其实它是指Metaspace扩容时触发FullGC的初始化阈值。
在GC后Metaspace会被动态调整:如果本次GC释放了大量空间,那么就适当降低该值,如果释放的空间较小则适当提高该值,当然它的值不会大于MaxMetaspaceSize.
另外一个相关知识是:Metaspace中的类需要满足什么条件才能够被当成垃圾被卸载回收?
条件还是比较严苛的,需同时满足如下三个条件的类才会被卸载:
-
该类所有的实例都已经被回收;
-
加载该类的ClassLoader已经被回收;
-
该类对应的java.lang.Class对象没有任何地方被引用。
排查过程
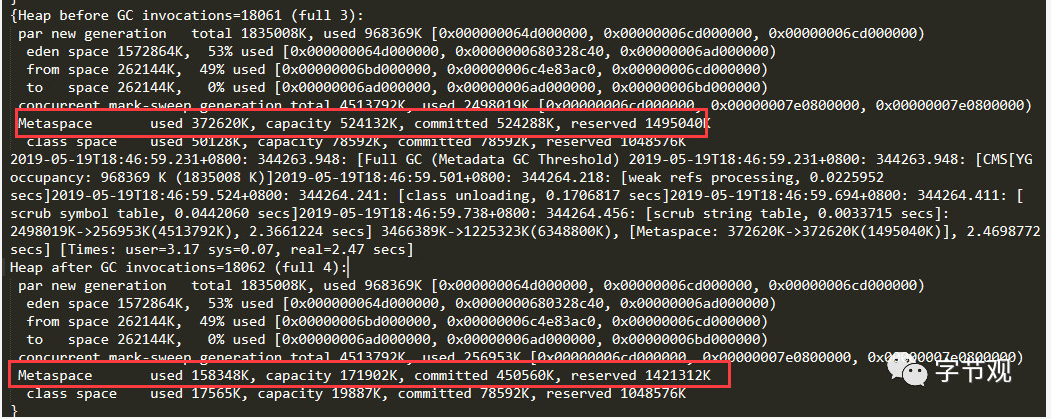
我们可以回过头再细看GC日志,可以看出Metaspace已使用内存在FullGC后明显变小(372620K -> 158348K),说明Metaspace经过FGC后卸载了很多类。
从这点来看,我们有理由怀疑系统可能在频繁地生成大量”一次性“的类,导致Metaspace所占用空间不断增长,增长到GC阈值后触发FGC。
那么这些被回收的类是什么呢?
为了弄清楚这点,我增加了如下两个JVM启动参数来观察类的加载、卸载信息:
-XX:TraceClassLoading -XX:TraceClassUnloading
加了这两个参数后,系统跑了一段时间,从Tomcat的catalina.out日志中发现大量如下的日志:
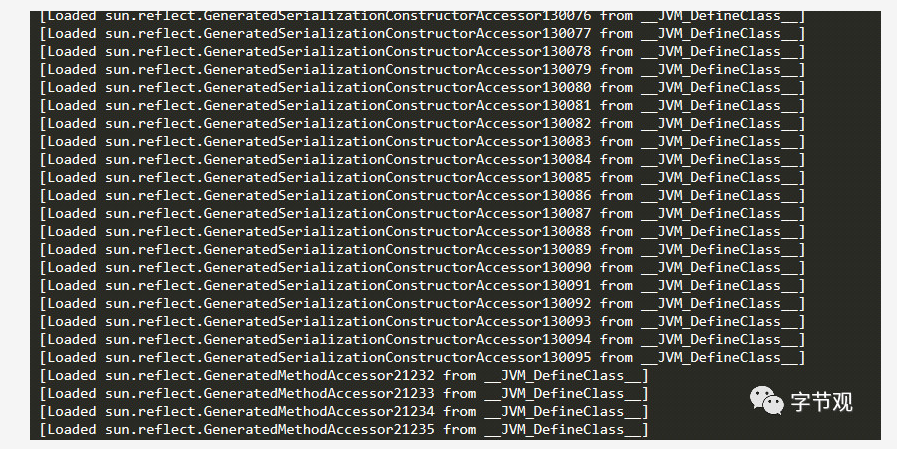
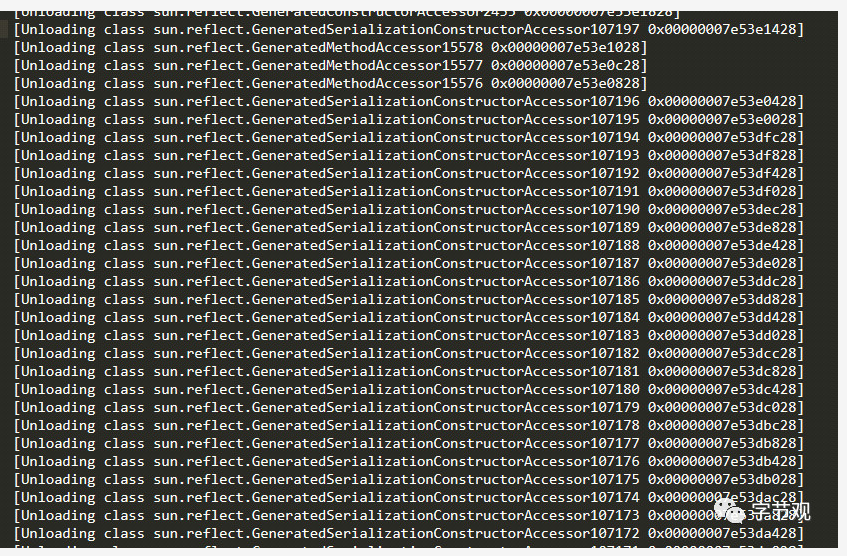
到此基本可以确定Metaspace增长的元凶是这些类,那么这些类
sun.reflect.GeneratedSerializationConstructorAccessorXXX
是干嘛的呢?又是从哪里引进来的呢?我也是一脸懵逼~~
根据类名Google了一把,找到了@寒泉子写的《从一起GC血案谈到反射原理》,这篇文章对这些类的来源解释得很透彻。在这里我简单总结如下:
Method method = XXX.class.getDeclaredMethod(xx,xx);method.invoke(target,params);
这些类的来源是反射,类似上面所示的反射代码应该大家都写过或者看过,我们常用的大多数框架比如Spring、Dubbo等都大量使用反射。
出于性能的考虑,JVM会在反射代码执行一定次数后,通过动态生成一些类来将”反射调用”变为“非反射调用”,以达到性能更好。而这些动态生成的类的实例是通过软引用SoftReference来引用的。
我们知道,一个对象只有软引用SoftReference,如果内存空间不足,就会回收这些对象的内存;如果内存空间足够,垃圾回收器不会回收它。只要垃圾回收器没有回收它,该对象就可以被使用。
那么,究竟在什么时候会被回收呢?
SoftReference中有一个全局变量clock代表最后一次GC的时间点,有一个属性timestamp,每次访问SoftReference时,会将timestamp其设置为clock值。
当GC发生时,以下几个因素影响SoftReference引用的对象是否被回收:
-
SoftReference对象实例多久未访问,通过clock - timestamp得出对象大概有多久未访问;
-
内存空闲空间的大小;
-
SoftRefLRUPolicyMSPerMB常量值;
是否保留SoftReference引用对象的判断参考表达式,true为不回收,false为回收:
clock - timestamp <= freespace * SoftRefLRUPolicyMSPerMB
说明:
-
clock - timestamp:最后一次GC时间和SoftReference对象实例timestamp的属性的差。就是这个SoftReference引用对象大概有多久未访问过了
-
freespace:JVMHeap中空闲空间大小,单位为MB。
-
SoftRefLRUPolicyMSPerMB:每1M空闲空间可保持的SoftReference对象生存的时长(单位ms)。这个参数就是一个常量,默认值1000,可以通过参数:-XX:SoftRefLRUPolicyMSPerMB进行设置。
查看了一下我们系统的JVM参数配置,发现我们把SoftRefLRUPolicyMSPerMB设置为0了,这样就导致软引用对象很快就被回收了。进而导致需要频繁重新生成这些动态类。
为了验证这个猜测,我把SoftRefLRUPolicyMSPerMB改成了6000进行观察,发现果然猜得没错。
系统启动后不久Metaspace的使用空间基本保持不变了,运行几天后也没再出现因为Metaspace大小达到阈值而触发FGC。至此问题解决。
References
假笨说-从一起GC血案谈到反射原理:
https://mp.weixin.qq.com/s/5H6UHcP6kvR2X5hTj_SBjA?
Java的强引用,软引用,弱引用,虚引用及其使用场景:
http://blogxin.cn/2017/09/16/java-reference/
转载自:石衫的架构笔记 微信公众号
