
ES 性能调优
ES 的默认配置,是综合了数据可靠性、写入速度、搜索实时性等因素。实际使用时,我们需要根据公司要求,进行偏向性的优化。
写优化
假设我们的应用场景要求是,每秒 300 万的写入速度,每条 500 字节左右。
针对这种对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略。
综合来说,可以考虑以下几个方面来提升写索引的性能:
-
加大 Translog Flush ,目的是降低 Iops、Writeblock。
-
增加 Index Refresh 间隔,目的是减少 Segment Merge 的次数。
-
调整 Bulk 线程池和队列。
-
优化节点间的任务分布。
-
优化 Lucene 层的索引建立,目的是降低 CPU 及 IO。
①批量提交
ES 提供了 Bulk API 支持批量操作,当我们有大量的写任务时,可以使用 Bulk 来进行批量写入。
每次提交的数据量为多少时,能达到最优的性能,主要受到文件大小、网络情况、数据类型、集群状态等因素影响。
通用的策略如下:Bulk 默认设置批量提交的数据量不能超过 100M。数据条数一般是根据文档的大小和服务器性能而定的,但是单次批处理的数据大小应从 5MB~15MB 逐渐增加,当性能没有提升时,把这个数据量作为最大值。
我们可以跟着,感受一下 Bulk 接口,如下所示:
$ vi request $ cat request { "index" : { "_index" : "chandler","_type": "test", "_id" : "1" } } { "name" : "钱丁君","age": "18" } $ curl -s -H "Content-Type: application/json" -XPOST localhost:9200/_bulk --data-binary @request; echo {"took":214,"errors":false,"items":[{"index":{"_index":"chandler","_type":"test","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}}]} $ curl -XGET localhost:9200/chandler/test/1?pretty { "_index" : "chandler", "_type" : "test", "_id" : "1", "_version" : 1, "found" : true, "_source" : { "name" : "钱丁君", "age" : "18" } }
Bulk 不支持 Gget 操作,因为没什么用处。
②优化存储设备
ES 是一种密集使用磁盘的应用,在段合并的时候会频繁操作磁盘,所以对磁盘要求较高,当磁盘速度提升之后,集群的整体性能会大幅度提高。
磁盘的选择,提供以下几点建议:
-
使用固态硬盘(Solid State Disk)替代机械硬盘。SSD 与机械磁盘相比,具有高效的读写速度和稳定性。
-
使用 RAID 0。RAID 0 条带化存储,可以提升磁盘读写效率。
-
在 ES 的服务器上挂载多块硬盘。使用多块硬盘同时进行读写操作提升效率,在配置文件 ES 中设置多个存储路径,如下所示:
path.data:/path/to/data1,/path/to/data2。
避免使用 NFS(Network File System)等远程存储设备,网络的延迟对性能的影响是很大的。
③合理使用合并
Lucene 以段的形式存储数据。当有新的数据写入索引时,Lucene 就会自动创建一个新的段。
随着数据量的变化,段的数量会越来越多,消耗的多文件句柄数及 CPU 就越多,查询效率就会下降。
由于 Lucene 段合并的计算量庞大,会消耗大量的 I/O,所以 ES 默认采用较保守的策略,让后台定期进行段合并,如下所述:
-
索引写入效率下降:当段合并的速度落后于索引写入的速度时,ES 会把索引的线程数量减少到 1。
这样可以避免出现堆积的段数量爆发,同时在日志中打印出“now throttling indexing”INFO 级别的“警告”信息。
-
提升段合并速度:ES 默认对段合并的速度是 20m/s,如果使用了 SSD,我们可以通过以下的命令将这个合并的速度增加到 100m/s。
PUT /_cluster/settings { "persistent" : { "indices.store.throttle.max_bytes_per_sec" : "100mb" } }
④减少 Refresh 的次数
Lucene 在新增数据时,采用了延迟写入的策略,默认情况下索引的 refresh_interval 为 1 秒。
Lucene 将待写入的数据先写到内存中,超过 1 秒(默认)时就会触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将 Refresh 周期延长,例如 30 秒。
这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的Heap内存。
如下所示:
index.refresh_interval:30s
⑤加大 Flush 设置
Flush 的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到 512MB 或者 30 分钟时,会触发一次 Flush。
index.translog.flush_threshold_size 参数的默认值是 512MB,我们进行修改。
增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统的文件缓存系统留下足够的空间。
⑥减少副本的数量
ES 为了保证集群的可用性,提供了 Replicas(副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以 Replicas 的数量会严重影响写索引的效率。
当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢。
如果我们需要大批量进行写入操作,可以先禁止 Replica 复制,设置 index.number_of_replicas: 0 关闭副本。在写入完成后,Replica 修改回正常的状态。
读优化
①避免大结果集和深翻
在上一篇讲到了集群中的查询流程,例如,要查询从 from 开始的 size 条数据,则需要在每个分片中查询打分排名在前面的 from+size 条数据。
协同节点将收集到的n×(from+size)条数据聚合,再进行一次排序,然后从 from+size 开始返回 size 条数据。
当 from、size 或者 n 中有一个值很大的时候,需要参加排序的数量也会增长,这样的查询会消耗很多 CPU 资源,从而导致效率的降低。
为了提升查询效率,ES 提供了 Scroll 和 Scroll-Scan 这两种查询模式。
Scroll:是为检索大量的结果而设计的。例如,我们需要查询 1~100 页的数据,每页 100 条数据。
如果使用 Search 查询:每次都需要在每个分片上查询得分最高的 from+100 条数据,然后协同节点把收集到的 n×(from+100)条数据聚合起来再进行一次排序。
每次返回 from+1 开始的 100 条数据,并且要重复执行 100 次。
如果使用 Scroll 查询:在各个分片上查询 10000 条数据,协同节点聚合 n×10000 条数据进行合并、排序,并将排名前 10000 的结果快照起来。这样做的好处是减少了查询和排序的次数。
Scroll 初始查询的命令是:
$ vim scroll $ cat scroll { "query": { "match": { "name": "钱丁君" } }, "size":20 } $ curl -s -H "Content-Type: application/json; charset=UTF-8" -XGET localhost:9200/chandler/test/_search?scroll=2m --data-binary @scroll; echo {"_scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAAGFlB6Y3QtNk9oUmdpc09Tb21rX2NXQXcAAAAAAAAABxZQemN0LTZPaFJnaXNPU29ta19jV0F3AAAAAAAAAAgWUHpjdC02T2hSZ2lzT1NvbWtfY1dBdwAAAAAAAAAJFlB6Y3QtNk9oUmdpc09Tb21rX2NXQXcAAAAAAAAAChZQemN0LTZPaFJnaXNPU29ta19jV0F3","took":14,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":1,"max_score":0.8630463,"hits":[{"_index":"chandler","_type":"test","_id":"1","_score":0.8630463,"_source":{ "name" : "钱丁君","age": "18" }}]}}
以上查询语句的含义是,在 chandler 索引的 test type 里查询字段 name 包含“钱丁君”的数据。
scroll=2m 表示下次请求的时间不能超过 2 分钟,size 表示这次和后续的每次请求一次返回的数据条数。
在这次查询的结果中除了返回了查询到的结果,还返回了一个 scroll_id,可以把它作为下次请求的参数。
再次请求的命令,如下所示:
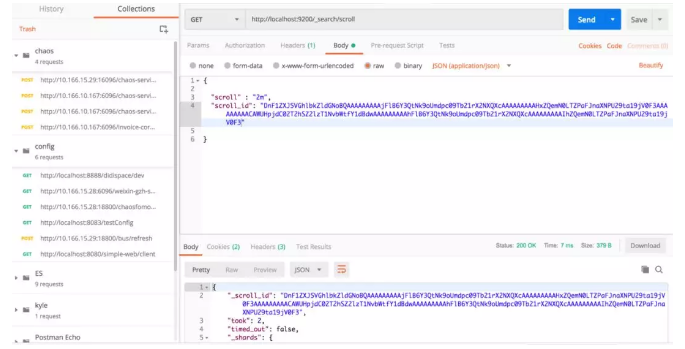
因为这次并没有到分片里查询数据,而是直接在生成的快照里面以游标的形式获取数据。
所以这次查询并没有包含 index 和 type,也没有查询条件:
-
"scroll": "2m":指本次请求的时间不能超过 2 分钟。
-
scroll_id:是上次查询时返回的 scroll_id。
Scroll-Scan:Scroll 是先做一次初始化搜索把所有符合搜索条件的结果缓存起来生成一个快照,然后持续地、批量地从快照里拉取数据直到没有数据剩下。
而这时对索引数据的插入、删除、更新都不会影响遍历结果,因此 Scroll 并不适合用来做实时搜索。
其思路和使用方式与 Scroll 非常相似,但是 Scroll-Scan 关闭了 Scroll 中最耗时的文本相似度计算和排序,使得性能更加高效。
为了使用 Scroll-Scan,需要执行一个初始化搜索请求,将 search_type 设置成 Scan,告诉 ES 集群不需要文本相似计算和排序,只是按照数据在索引中顺序返回结果集:
$ vi scroll $ cat scroll { "query": { "match": { "name": "钱丁君" } }, "size":20, "sort": [ "_doc" ] } $ curl -H "Content-Type: application/json; charset=UTF-8" -XGET 'localhost:9200/chandler/test/_search?scroll=2m&pretty=true' --data-binary @scroll { "_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAABWFlB6Y3QtNk9oUmdpc09Tb21rX2NXQXcAAAAAAAAAVxZQemN0LTZPaFJnaXNPU29ta19jV0F3AAAAAAAAAFgWUHpjdC02T2hSZ2lzT1NvbWtfY1dBdwAAAAAAAABZFlB6Y3QtNk9oUmdpc09Tb21rX2NXQXcAAAAAAAAAWhZQemN0LTZPaFJnaXNPU29ta19jV0F3", "took" : 3, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : null, "hits" : [ { "_index" : "chandler", "_type" : "test", "_id" : "1", "_score" : null, "_source" : { "name" : "钱丁君", "age" : "18" }, "sort" : [ 0 ] } ] } }
注意:Elasticsearch 2.1.0 版本之后移除了 search_type=scan,使用 "sort": [ "_doc"] 进行代替。
Scroll 和 Scroll-Scan 有一些差别,如下所示:
-
Scroll-Scan不进行文本相似度计算,不排序,按照索引中的数据顺序返回。
-
Scroll-Scan 不支持聚合操作。
-
Scroll-Scan 的参数 Size 代表着每个分片上的请求的结果数量,每次返回 n×size 条数据。而 Scroll 每次返回 size 条数据。
②选择合适的路由
ES 中所谓的路由和 IP 网络不同,是一个类似于 Tag 的东西。在创建文档的时候,可以通过字段为文档增加一个路由属性的 Tag。在多分片的 ES 集群中,对搜索的查询大致分为如下两种。
ES 内在机制决定了拥有相同路由属性的文档,一定会被分配到同一个分片上,无论是主分片还是副本。
查询时可以根据 Routing 信息,直接定位到目标分片,避免查询所有的分片,再经过协调节点二次排序。
如图 1 所示:
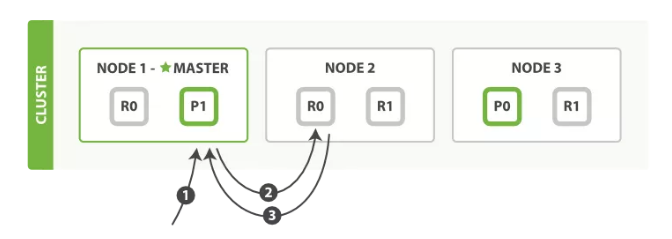
图 1
如果在查询条件中不包含 Routing,在查询时就遍历所有分片,整个查询主要分为 Scatter、Gather 两个过程:
-
Scatter(分发):请求到达协调节点之后,协调节点将查询请求分发给每个分片。
-
Gather(聚合):协调点在每个分片上完成搜索,再将搜索到的结果集进行排序,将结果数据返回给用户。
如图 2 所示:

图 2
通过对比上述两种查询流程,我们不难发现,使用 Routing 信息查找的效率很高,避免了多余的查询。
所以我们在设计 Elasticsearch Mapping 时要合理地利用 Routing 信息,来提升查询的效率。
例如,在大型的本地分类网站中,可以将城市 ID 作为 Routing 的条件,让同一个城市的数据落在相同的分片中。
默认的公式如下:
shard = hash(routing)%number_of_primary_shards
不过需要注意的是,根据城市 ID 进行分片时,也会容易出现分片不均匀的情况。
例如,大型城市的数据过多,而小城市的数据太少,导致分片之间的数据量差异很大。
这时就可以进行必要的调整,比如把多个小城市的数据合并到一个分片上,把大城市的数据按区域进行拆分到不同分配。
③SearchType
在 Scatter、Gather 的过程中,节点间的数据传输和打分(SearchType),可以根据不同的场景选择。
如下所示:
-
QUERY_THEN_FETCH:ES 默认的搜索方式。第一步,先向所有的分片发请求,各分片只返回文档的相似度得分和文档的 ID,然后协调节点按照各分片返回的分数进行重新排序和排名,再取出需要返回给客户端的 Size 个文档 ID。
第 2 步,在相关的分片中取出文档的详细信息并返回给用户。
-
QUERY_AND_FETCH:协调节点向所有分片发送查询请求,各分片将文档的相似度得分和文档的详细信息一起返回。
然后,协调节点进行重新排序,再取出需要返回给客户端的数据,将其返回给客户端。由于只需要在分片中查询一次,所以性能是最好的。
-
DFS_QUERY_THEN_FETCH:与 QUERY_THEN_FETCH 类似,但它包含一个额外的阶段:在初始查询中执行全局的词频计算,以使得更精确地打分,从而让查询结果更相关。
QUERY_THEN_FETCH 使用的是分片内部的词频信息,而 DFS_QUERY_THEN_FETCH 使用访问公共的词频信息,所以相比 QUERY_THEN_FETCH 性能更低。
-
DFS_QUERY_AND_FETCH:与 QUERY_AND_FETCH 类似,不过使用的是全局的词频。
④定期删除
由于在 Lucene 中段具有不变性,每次进行删除操作后不会立即从硬盘中进行实际的删除,而是产生一个 .del 文件记录删除动作。
随着删除操作的增长,.del 文件会越来也多。当我们进行查询操作的时候,被删除的数据还会参与检索中,然后根据 .del 文件进行过滤。.del 文件越多,查询过滤过程越长,进而影响查询的效率。
当机器空闲时,我们可以通过如下命令删除文件,来提升查询的效率:
$ curl -XPOST localhost:9200/chandler/_forcemerge?only_expunge_deletes=true {"_shards":{"total":10,"successful":5,"failed":0}}
定期对不再更新的索引做 optimize (ES 2.0 以后更改为 Force Merge API)。
这 Optimze 的实质是对 Segment File 强制做合并,可以节省大量的 Segment Memory。
堆大小的设置
ES 默认安装后设置的内存是 1GB,对于任何一个现实业务来说,这个设置都太小了。
如果是通过解压安装的 ES,则在 ES 安装文件中包含一个 jvm.option 文件,添加如下命令来设置 ES 的堆大小:
-Xms10g
-Xmx10g
Xms 表示堆的初始大小,Xmx 表示可分配的最大内存,都是 10GB。
确保 Xmx 和 Xms 的大小是相同的,其目的是为了能够在 Java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。
也可以通过设置环境变量的方式设置堆的大小。服务进程在启动时候会读取这个变量,并相应的设置堆的大小。比如:
export ES_HEAP_SIEZE=10g
也可以通过命令行参数的形式,在程序启动的时候把内存大小传递给 ES,如下所示:
./bin/elasticsearch -Xmx10g -Xms10g
这种设置方式是一次性的,在每次启动 ES 时都需要添加。
假设你有一个 64G 内存的机器,按照正常思维思考,你可能会认为把 64G 内存都给 ES 比较好,但现实是这样吗, 越大越好?虽然内存对 ES 来说是非常重要的,但是答案是否定的!
因为 ES 堆内存的分配需要满足以下两个原则:
-
不要超过物理内存的 50%:Lucene 的设计目的是把底层 OS 里的数据缓存到内存中。
Lucene 的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。
如果我们设置的堆内存过大,Lucene 可用的内存将会减少,就会严重影响降低 Lucene 的全文本查询性能。
-
堆内存的大小最好不要超过 32GB:在 Java 中,所有对象都分配在堆上,然后有一个 Klass Pointer 指针指向它的类元数据。
这个指针在 64 位的操作系统上为 64 位,64 位的操作系统可以使用更多的内存(2^64)。在 32 位的系统上为 32 位,32 位的操作系统的最大寻址空间为 4GB(2^32)。
但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在主内存和缓存器(例如 LLC, L1等)之间移动数据的时候,会占用更多的带宽。
Java 使用内存指针压缩(Compressed Oops)技术来解决这个问题。它的指针不再表示对象在内存中的精确位置,而是表示偏移量。
这意味着 32 位的指针可以引用 4GB 个 Byte,而不是 4GB 个 bit。也就是说,当堆内存为 32GB 的物理内存时,也可以用 32 位的指针表示。
不过,在越过那个神奇的边界 32GB 时,指针就会变为普通对象的指针,每个对象的指针都变长了,就会浪费更多的内存,降低了 CPU 的性能,还要让 GC 应对更大的内存。
事实上,当内存到达 40~40GB 时,有效的内存才相当于内存对象指针压缩技术时的 32GB 内存。
所以即便你有足够的内存,也尽量不要超过 32G,比如我们可以设置为 31GB:
-Xms31g
-Xmx31g
32GB 是 ES 一个内存设置限制,那如果你的机器有很大的内存怎么办呢?现在的机器内存普遍增长,甚至可以看到有 300-500GB 内存的机器。
这时我们需要根据业务场景,进行恰当内存的分配:
-
业务场景是以全文检索为主:依然可以给 ES 分配小于 32GB 的堆内存,剩下的交给 Lucene 用作操作系统的文件系统缓存,所有的 Segment 都缓存起来,会加快全文检索。
-
业务场景中有很多的排序和聚合:我们可以考虑一台机器上创建两个或者更多 ES 节点,而不要部署一个使用 32+GB 内存的节点。
仍然要坚持 50% 原则,假设你有个机器有 128G 内存,你可以创建两个 Node,使用 32G 内存。也就是说 64G 内存给 ES 的堆内存,剩下的 64G 给 Lucene。
服务器配置的选择
Swapping 是性能的坟墓:在选择 ES 服务器时,要尽可能地选择与当前应用场景相匹配的服务器。
如果服务器配置很低,则意味着需要更多的节点,节点数量的增加会导致集群管理的成本大幅度提高。
如果服务器配置很高,而在单机上运行多个节点时,也会增加逻辑的复杂度。
在计算机中运行的程序均需在内存执行,若内存消耗殆尽将导致程序无法进行。为了解决这个问题,操作系统使用一种叫作虚拟内存的技术。
当内存耗尽时,操作系统就会自动把内存中暂时不使用的数据交换到硬盘中,需要使用的时候再从硬盘交换到内存。
如果内存交换到磁盘上需要 10 毫秒,从磁盘交换到内存需要 20 毫秒,那么多的操作时延累加起来,将导致几何级增长。
不难看出 Swapping 对于性能是多么可怕。所以为了使 ES 有更好等性能,强烈建议关闭 Swap。
关闭 Swap 的方式如下:
①暂时禁用。如果我们想要在 Linux 服务器上暂时关闭,可以执行如下命令,但在服务器重启后失效:
sudo swapoff -a
②永久性关闭。我们可以修改 /etc/sysctl.conf(不同的操作系统路径有可能不同),增加如下参数:
vm.swappiness = 1 //0-100,则表示越倾向于使用虚拟内存。
注意:Swappiness 设置为 1 比设置为 0 要好,因为在一些内核版本,Swappness=0 会引发 OOM(内存溢出)。
Swappiness 默认值为 60,当设置为 0 时,在某些操作系统中有可能会触发系统级的 OOM-killer,例如在 Linux 内核的内存不足时,为了防止系统的崩溃,会自动强制 Kill 一个“bad”进程。
③在 ES 中设置。如果上面的方法都不能做到,你需要打开配置文件中的 mlockall 开关,它的作用就是运行 JVM 锁住内存,禁止 OS 交换出去。
在 elasticsearch.yml 配置如下:
bootstrap.mlockall: true
硬盘的选择和设置
所以,如果条件允许,则请尽可能地使用 SSD,它的读写性能将远远超出任何旋转介质的硬盘(如机械硬盘、磁带等)。基于 SSD 的 ES 集群节点对于查询和索引性能都有提升。
另外无论是使用固态硬盘还是使用机械硬盘,我们都建议将磁盘的阵列模式设置为 RAID 0,以此来提升磁盘的写性能。
接入方式
ES 提供了 Transport Client(传输客户端)和 Node Client(节点客户端)的接入方式,这两种方式各有利弊,分别对应不同的应用场景。
①Transport Client:作为一个集群和应用程序之间的通信层,和集群是安全解耦的。
由于与集群解耦,所以在连接集群和销毁连接时更加高效,适合大量的客户端连接。
②Node Client:把应用程序当作一个集群中的 Client 节点(非 Data 和 Master 节点)。
由于它是集群的一个内部节点,意味着它可以感知整个集群的状态、所有节点的分布情况、分片的分布状况等。
由于 Node Client 是集群的一部分,所以在接入和退出集群时进行比较复杂操作,并且还会影响整个集群的状态,所以 Node Client 更适合少量客户端,能够提供更好的执行效率。
角色隔离和脑裂
①角色隔离
ES 集群中的数据节点负责对数据进行增、删、改、查和聚合等操作,所以对 CPU、内存和 I/O 的消耗很大。
在搭建 ES 集群时,我们应该对 ES 集群中的节点进行角色划分和隔离。
候选主节点:
node.master=true node.data=false
数据节点:
node.master=false node.data=true
最后形成如图 3 所示的逻辑划分:

图 3
②避免脑裂
网络异常可能会导致集群中节点划分出多个区域,区域发现没有 Master 节点的时候,会选举出了自己区域内 Maste 节点 r,导致一个集群被分裂为多个集群,使集群之间的数据无法同步,我们称这种现象为脑裂。
为了防止脑裂,我们需要在 Master 节点的配置文件中添加如下参数:
discovery.zen.minimum_master_nodes=(master_eligible_nodes/2)+1 //默认值为1
其中 master_eligible_nodes 为 Master 集群中的节点数。这样做可以避免脑裂的现象都出现,最大限度地提升集群的高可用性。
只要不少于 discovery.zen.minimum_master_nodes 个候选节点存活,选举工作就可以顺利进行。
ES 实战
ES 配置说明
在 ES 安装目录下的 Conf 文件夹中包含了一个重要的配置文件:elasticsearch.yaml。
ES 的配置信息有很多种,大部分配置都可以通过 elasticsearch.yaml 和接口的方式进行。
下面我们列出一些比较重要的配置信息:
-
cluster.name:elasticsearch:配置 ES 的集群名称,默认值是 ES,建议改成与所存数据相关的名称,ES 会自动发现在同一网段下的集群名称相同的节点。
-
node.nam: "node1":集群中的节点名,在同一个集群中不能重复。节点的名称一旦设置,就不能再改变了。当然,也可以设置成服务器的主机名称,例如 node.name:${HOSTNAME}。
-
noed.master:true:指定该节点是否有资格被选举成为 Master 节点,默认是 True,如果被设置为 True,则只是有资格成为 Master 节点,具体能否成为 Master 节点,需要通过选举产生。
-
node.data:true:指定该节点是否存储索引数据,默认为 True。数据的增、删、改、查都是在 Data 节点完成的。
-
index.number_of_shards:5:设置都索引分片个数,默认是 5 片。也可以在创建索引时设置该值,具体设置为多大都值要根据数据量的大小来定。如果数据量不大,则设置成 1 时效率最高。
-
index.number_of_replicas:1:设置默认的索引副本个数,默认为 1 个。副本数越多,集群的可用性越好,但是写索引时需要同步的数据越多。
-
path.conf:/path/to/conf:设置配置文件的存储路径,默认是 ES 目录下的 Conf 文件夹。建议使用默认值。
-
path.data:/path/to/data1,/path/to/data2:设置索引数据多存储路径,默认是 ES 根目录下的 Data 文件夹。切记不要使用默认值,因为若 ES 进行了升级,则有可能数据全部丢失。
可以用半角逗号隔开设置的多个存储路径,在多硬盘的服务器上设置多个存储路径是很有必要的。
-
path.logs:/path/to/logs:设置日志文件的存储路径,默认是 ES 根目录下的 Logs,建议修改到其他地方。
-
path.plugins:/path/to/plugins:设置第三方插件的存放路径,默认是 ES 根目录下的 Plugins 文件夹。
-
bootstrap.mlockall:true:设置为 True 时可锁住内存。因为当 JVM 开始 Swap 时,ES 的效率会降低,所以要保证它不 Swap。
-
network.bind_host:192.168.0.1:设置本节点绑定的 IP 地址,IP 地址类型是 IPv4 或 IPv6,默认为 0.0.0.0。
-
network.publish_host:192.168.0.1:设置其他节点和该节点交互的 IP 地址,如果不设置,则会进行自我判断。
-
network.host:192.168.0.1:用于同时设置 bind_host 和 publish_host 这两个参数。
-
http.port:9200:设置对外服务的 HTTP 端口,默认为 9200。ES 的节点需要配置两个端口号,一个对外提供服务的端口号,一个是集群内部使用的端口号。
http.port 设置的是对外提供服务的端口号。注意,如果在一个服务器上配置多个节点,则切记对端口号进行区分。
-
transport.tcp.port:9300:设置集群内部的节点间交互的 TCP 端口,默认是 9300。注意,如果在一个服务器配置多个节点,则切记对端口号进行区分。
-
transport.tcp.compress:true:设置在节点间传输数据时是否压缩,默认为 False,不压缩。
-
discovery.zen.minimum_master_nodes:1:设置在选举 Master 节点时需要参与的最少的候选主节点数,默认为 1。如果使用默认值,则当网络不稳定时有可能会出现脑裂。
合理的数值为(master_eligible_nodes/2)+1,其中 master_eligible_nodes 表示集群中的候选主节点数。
-
discovery.zen.ping.timeout:3s:设置在集群中自动发现其他节点时 Ping 连接的超时时间,默认为 3 秒。
在较差的网络环境下需要设置得大一点,防止因误判该节点的存活状态而导致分片的转移。
常用接口
虽然现在有很多开源软件对 ES 的接口进行了封装,使我们可以很方便、直观地监控集群的状况,但是在 ES 5 以后,很多软件开始收费。
了解常用的接口有助于我们在程序或者脚本中查看我们的集群情况,以下接口适用于 ES 6.5.2 版本。
①索引类接口
通过下面的接口创建一个索引名称为 indexname 且包含 3 个分片、1 个副本的索引:
PUT http://localhost:9200/indexname?pretty content-type →application/json; charset=UTF-8 { "settings":{ "number_of_shards" : 3, "number_of_replicas" : 1 } }
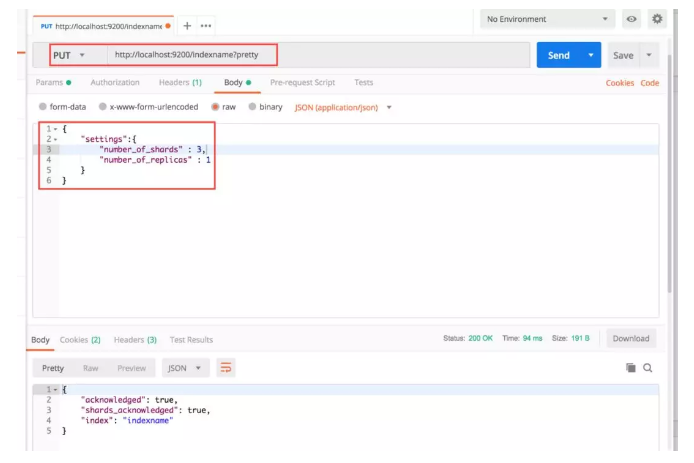
通过下面都接口删除索引:
DELETE http://localhost:9200/indexname
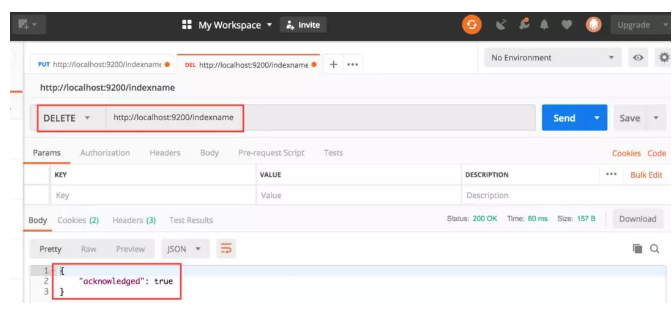
通过该接口就可以删除索引名称为 indexname 的索引,通过下面的接口可以删除多个索引:
DELETE http://localhost:9200/indexname1,indexname2 DELETE http://localhost:9200/indexname*
通过下面的接口可以删除集群下的全部索引:
DELETE http://localhost:9200/_all DELETE http://localhost:9200/*
进行全部索引删除是很危险的,我们可以通过在配置文件中添加下面的配置信息,来关闭使用 _all 和使用通配符删除索引的接口,使用删除索引职能通过索引的全称进行。
action.destructive_requires_name: true
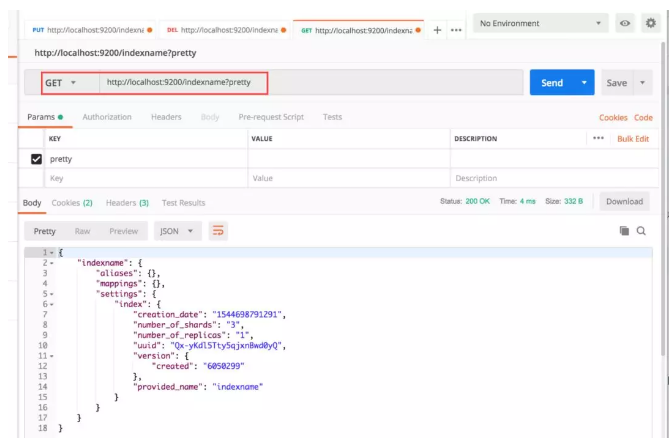
通过下面的接口获取索引的信息,其中,Pretty 参数用语格式化输出结构,以便更容易阅读:
GET http://localhost:9200/indexname?pretty
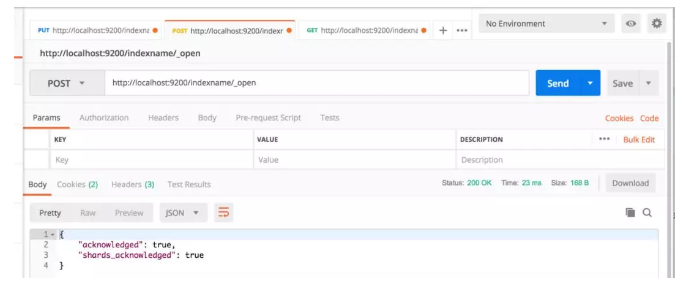
通过下面的接口关闭、打开索引:
POST http://localhost:9200/indexname/_close POST http://localhost:9200/indexname/_open
通过下面的接口获取一个索引中具体 Type 的 Mapping 映射:
GET http://localhost:9200/indexname/typename/_mapping?pretty
当一个索引中有多个 Type 时,获得 Mapping 时要加上 Typename。
②Document 操作
安装 ES 和 Kibana 之后,进入 Kibana 操作页面,然后进去的 DevTools 执行下面操作:
#添加一条document PUT /test_index/test_type/1 { "test_content":"test test" } #查询 GET /test_index/test_type/1 #返回 { "_index" : "test_index", "_type" : "test_type", "_id" : "1", "_version" : 2, "found" : true, "_source" : { "test_content" : "test test" } }
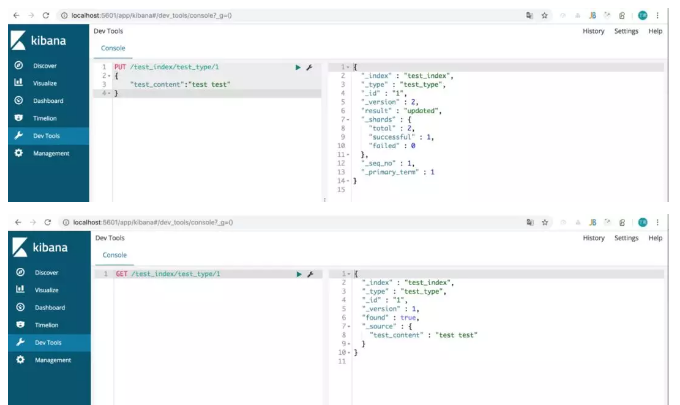
put/index/type/id 说明如下:
-
_index 元数据:代表这个 Document 存放在哪个 Idnex 中,类似的数据放在一个索引,非类似的数据放不同索引,Index 中包含了很多类似的 Document。
-
_type 元数据:代表 Document 属于 Index 中的哪个类别(type),一个索引通常会划分多个 Type,逻辑上对 Index 中有些许不同的几类数据进行分类。
-
_id 元数据:代表 Document 的唯一标识,id 与 Index 和 Type 一起,可以唯一标识和定位一个 Document,可以理解为数据库中主键。我们可以指定 Document 的 id,也可以不指定,由ES自动为我们创建一个 id。
接口应用
①Search 接口
Search 是我们最常用的 API,ES 给我提供了丰富的查询条件,比如模糊匹配 Match,字段判空 Exists,精准匹配 Term 和 Terms,范围匹配 Range:
GET /_search { "query": { "bool": { "must": [ //must_not { "match": { "title": "Search" }}, { "match": { "content": "Elasticsearch" }}, {"exists":{"field":"字段名"}} //判断字段是否为空 ], "filter": [ { "term": { "status": "published" }}, { "terms": { "status": [0,1,2,3] }},//范围 { "range": { "publish_date": { "gte": "2015-01-01" }}} //范围gte:大于等于;gt:大于;lte:小于等于;lt:小于 ] } } }
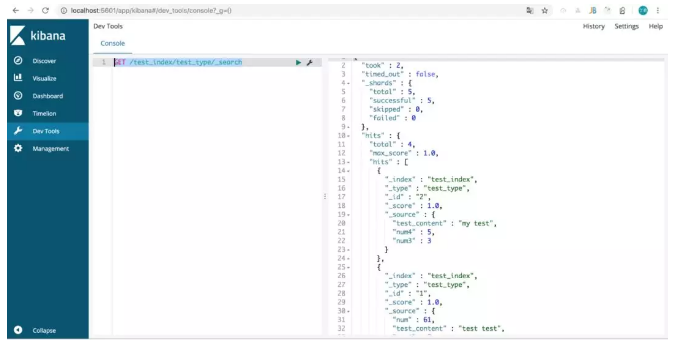
查询索引为 test_index,doc 类型为 test_type 的数据:
GET /test_index/test_type/_search
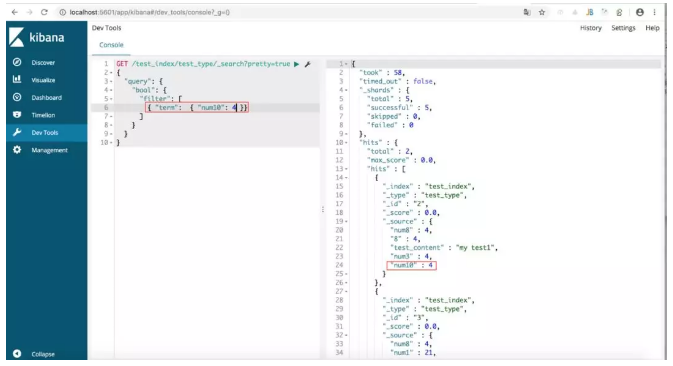
查询索引为 test_index,doc 类型为 test_type,docment 字段 num10 为 4 的数据:
GET /test_index/test_type/_search?pretty=true { "query": { "bool": { "filter": [ { "term": { "num10": 4 }} ] } } }
更多查询条件的组合,大家可以自行测试。
②修改 Mapping
PUT /my_index/_mapping/my_type { "properties": { "new_field_name": { "type": "string" //字段类型,string、long、boolean、ip } } }
如上是修改 Mapping 结构,然后利用脚本 Script 给字段赋值:
POST my_index/_update_by_query { "script": { "lang": "painless", "inline": "ctx._source.new_field_name= '02'" } }
③修改别名
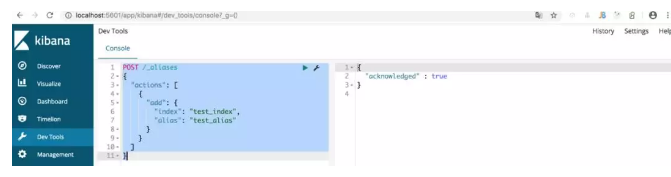
如下给 Index 为 test_index 的数据绑定 Alias 为 test_alias:
POST /_aliases { "actions": [ { "add": { //add,remove "index": "test_index", "alias": "test_alias" } } ] }
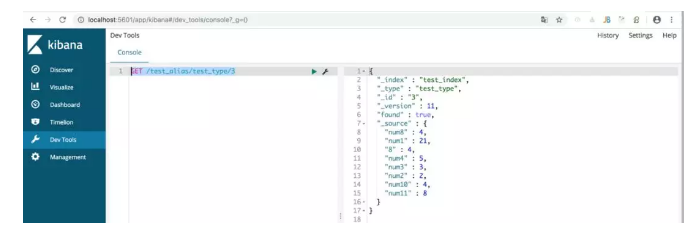
验证别名关联,根据别名来进行数据查询,如下:
GET /test_alias/test_type/3
④定制返回内容
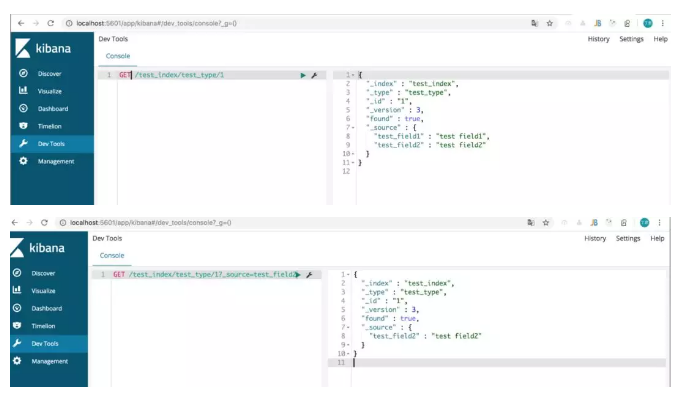
_source 元数据:就是说,我们在创建一个 Document 的时候,使用的那个放在 Request Body 中的 Json 串(所有的 Field),默认情况下,在 Get 的时候,会原封不动的给我们返回回来。
定制返回的结果,指定 _source 中,返回哪些 Field:
#语法: GET /test_index/test_type/1?_source=test_field2 #返回 { "_index" : "test_index", "_type" : "test_type", "_id" : "1", "_version" : 3, "found" : true, "_source" : { "test_field2" : "test field2" } } #也可返回多个field使用都好分割 GET /test_index/test_type/1?_source=test_field2,test_field1
Java 封装
组件 elasticsearch.jar 提供了丰富 API,不过不利于我们理解和学习,现在我们自己来进行封装。
组件 API 使用 RestClient 封装 Document 查询接口:
/** * @param index * @param type * @param id * @param fields * 查询返回字段,可空 * @return * @throws Exception * @Description: * @create date 2019年4月3日下午3:12:40 */ public String document(String index, String type, String id, List<String> fields) throws Exception { Map<String, String> paramsMap = new HashMap<>(); paramsMap.put("pretty", "true"); if (null != fields && fields.size() != 0) { String fieldValue = ""; for (String field : fields) { fieldValue += field + ","; } if (!"".equals(fieldValue)) { paramsMap.put("_source", fieldValue); } } return CommonUtils.toString(es.getRestClient() .performRequest("GET", "/" + index + "/" + type + "/" + id, paramsMap).getEntity().getContent()); }
工程使用,封装:
public String searchDocument(String index, String type, String id, List<String> fields) { try { return doc.document(index, type, id, fields); } catch (Exception e) { log.error(e.getMessage()); ExceptionLogger.log(e); throw new RuntimeException("ES查询失败"); } }
测试用例,代码如下:
/** * ES交互验证-查询、更新等等操作 * * @version * @author 钱丁君-chandler 2019年4月3日上午10:27:28 * @since 1.8 */ @RunWith(SpringRunner.class) @SpringBootTest(classes = Bootstrap.class, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT) public class ESManagerTest { @Autowired private ESBasicManager esBasicManager; @Test public void query() { String result = esBasicManager.searchDocument(ESTagMetadata.INDEX_ALIAS, ESTagMetadata.DOC_TYPE, "188787665220752824", ImmutableList.of("signup_time", "tag_days_no_visit_after_1_order")); System.out.println("----------->" + result); } }
控台输出:
----------->{ "_index" : "crm_tag_idx_20181218_708672", "_type" : "crm_tag_type", "_id" : "188787665220752824", "_version" : 1, "found" : true, "_source" : { "signup_time" : "2017-12-24", "tag_days_no_visit_after_1_order" : "339" } }
转载:
作者:钱丁君
资料参考:《可伸缩服务架构》
