


拓端数据tecdat|python代写缺失值处理案例分析:泰坦尼克数据
缺失值处理
真实数据往往某些变量会有缺失值。
首先,我们用 info( ) 语句操作,看到整份数据的大概情况:
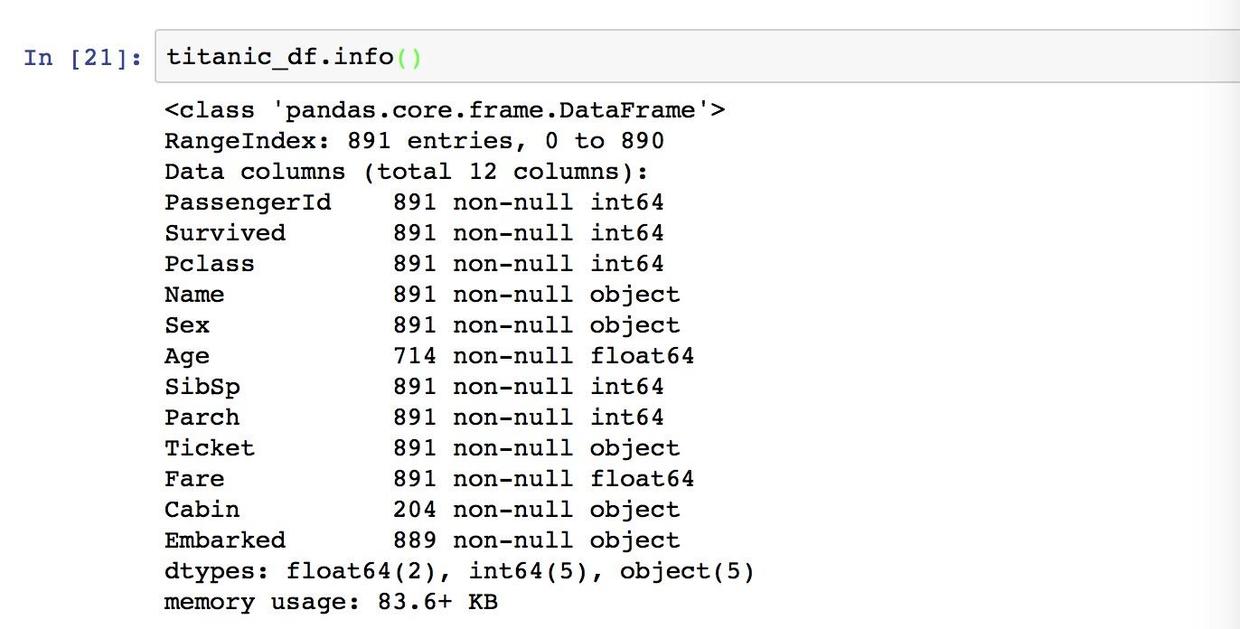
titanic_df.info()
从这份数据我们可以发现,这里一共有 891 行数据,所以在中间那一列数据中看到的不是 891 个数据的,都是有缺失值的。比如年龄Age这一列,有714个非空数值,就有 891-714=177 个缺失值。又比如船舱号码 cabin,缺失值就更多了。登船码头的缺失值比较少,后面可以不用处理。
这些缺失值是怎么处理的呢?一般是三种处理方法:不处理/丢弃/填充。
这里,cabin有超过70%以上的缺失值,我们可以考虑直接丢掉这个变量。 -- 删除某一列数据
像Age这样的重要变量,有20%左右的缺失值,我们可以考虑用中位值来填补。-- 填补缺失值
我们一般不提倡去掉带有缺失值的行,因为其他非缺失的变量可能提供有用的信息。-- 删除带缺失值的行
删除带缺失值的行(一般不建议):df.dropna( )
删除某一列:df.drop('column_name', axis=1, inplace=True)
填充缺失值:df.column_name.fillna( )
axis=1,代表删除的是一列的数据,也就是 column_name 这一列。inplace=True,表示在 df 这个原始数据上面进行修改。
其实我们这节课重点的是最后一个:填充缺失值。fill 是填充,na 是缺失值的代称。
我们在 info( ) 这个运行中可以看到 Age 的缺失值不少,下面将使用中位数来填充 缺失值。
填补年龄数据中的缺失值
直接使用所有人年龄的中位数来填补
为了方便后面的比较,我们首先用 describe 统计数据。
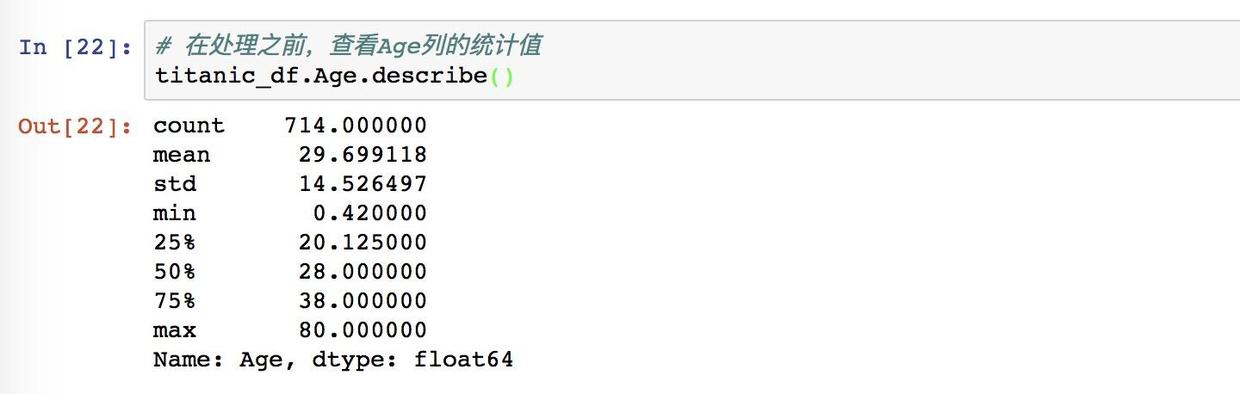
查看Age列的统计值
这份数据照样是可以看到,非缺失值 count 是有 714,平均值 mean 是 29.6岁,标准差 std 是 14.5,这时可以注意一下 50% 那个数据:28。

中位数
为了防止数据有改动,我们在开始之前需要重新载入数据。
正确的中位数可以使用 median 的方法获取,得到的数和上面的 50% 的数是一样的。
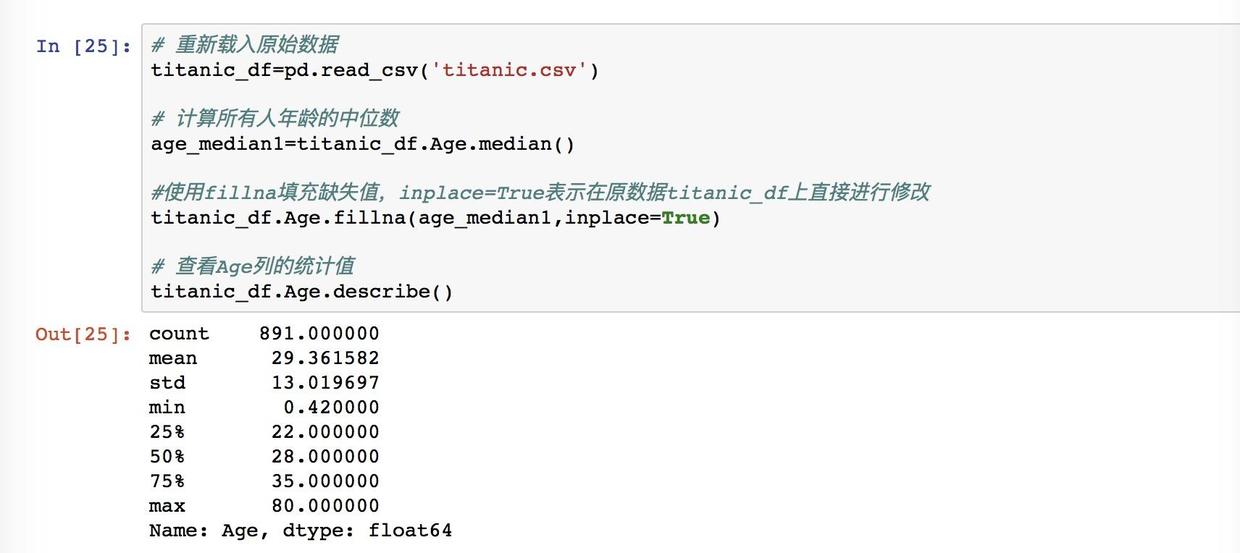
填充年龄缺失值
把中位数赋值给 age_median1,这个操作体现在第二行代码。我的理解是,要是这里不重新赋值的话,后面需要用到这个中位数的时候,就需要完整码出 titanic_df.Age.median( ) 这一句,重新赋值就可以直接使用 age_median1 来代替稍微长一点的句子了。
titanic_df.Age.fillna(age_median1,inplace=True) 中,因为使用到Age这列数据,然后用 fillna 来实现填充,所以语句用 titanic_df.Age.fillna( ) 来表达,括号里面需要填的参数就是需要填充的值,也就是里面的缺失值都是由刚刚赋值的 age_median1 来代替。逗号后面再加上inplace=True,表示在原来的 df 数据中进行修改了,如果不加上这个参数,就需要把填充后的值重新赋值给 Age 这一列,所以 inplace 这个动作是为了简单起见。
再来看我们得到的结果,这个时候的非空缺失值已经变成了891,平均值也从原本的29.7降到了29.4,因为我们刚刚填充的中位数是28,比原来的平均值小,所以会有所新的平均值也会有所下降。
上面讲的是所有人的年龄中位数,现在我们进一步来思考:性别因素,会怎么影响结果呢?
考虑性别因素,分别用男女乘客各自年龄的中位数来填补
由于上面的操作已经对原始数据进行修改了,所以要是我们需要重新分类,那就要重新载入原始数据,不然后面的操作都会以上一步填充了所有年龄缺失值的基础上操作的哦!这个亏我吃过。。。

性别的中位数
我们得到的女性中位数是 27,男性的是 29,还是有差距的吧!我们后面需要用到的是,用得出的中位数来填充男女的缺失值。
接下来的步骤,按照以前,通常的思路是用布尔型索引取到女性中缺失值的数据,然后用 27 重新赋值;同理可求男性的操作。
但是我们这节课学了fillna 这个新的方法啊!
不过刚刚我们使用 fillna 的时候,填充的只是一个数值,这里不止一个数值,就需要根据不同的情况来填充。此时可以用到 Pandas 中里的一个小技巧,Pandas 的值在运算的过程中,会根据索引的值来进行自动的匹配。在这里我们可以看到这里的索引是 female 和 male 两个值,如果原始数据也可以用性别来进行索引的话,就可以用 fillna 自动匹配相应的索引形式进行填充了。
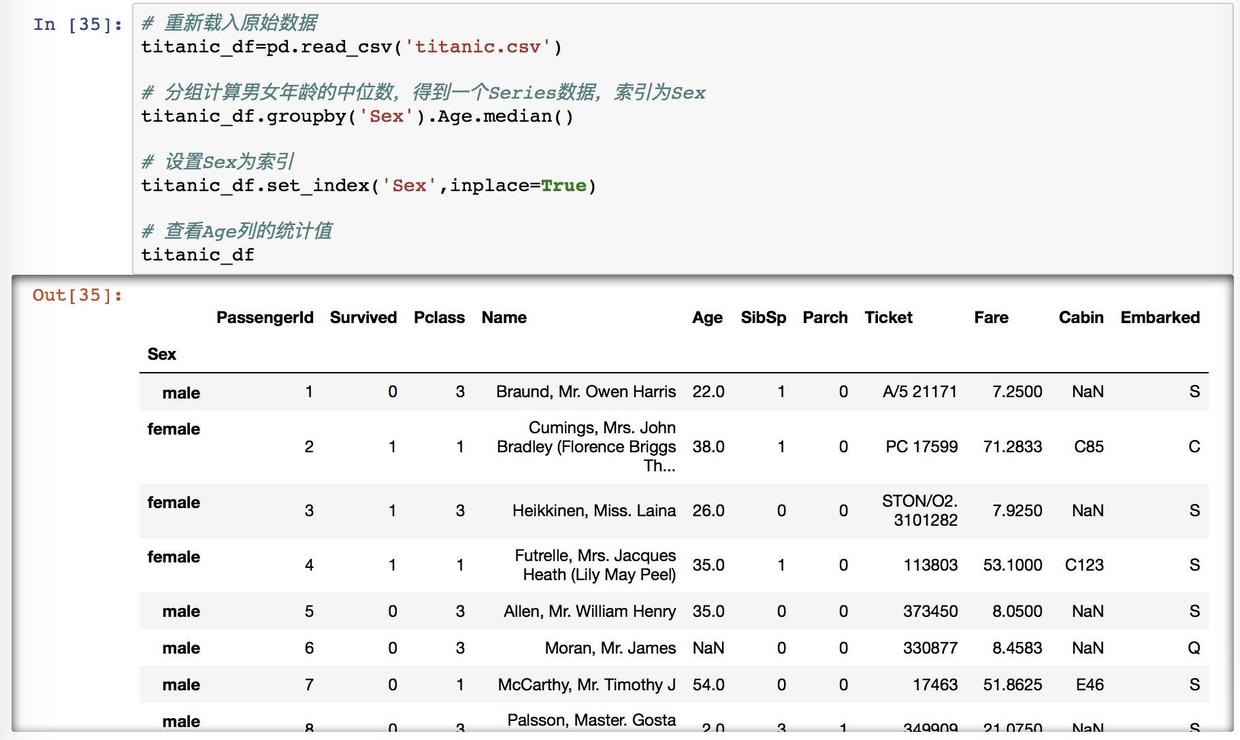
fillna 进行性别分类索引
所以这里要对原来的数值重新设置索引,一开始是 0 1 2 这样的数值,现在要把它设置成性别这一列数据。用 set_index 语句,用 Sex 来进行索引,同时加入参数 inplace=True,表示在原来的数据上进行修改。
inplace=True的含义应该讲了第三遍了,其实我觉得要是不是很明白这个语句的用法时,你可以先不加上这一句,跟着打代码,然后到后面运行的哪一步你发现和老师的代码不一样的时候,你就知道这个语句的重要性了。
我们可以看到这里的运行结果 列索引变成了 Sex,列首索引是 male 和 female ,在行首 Sex 已经不存在了。
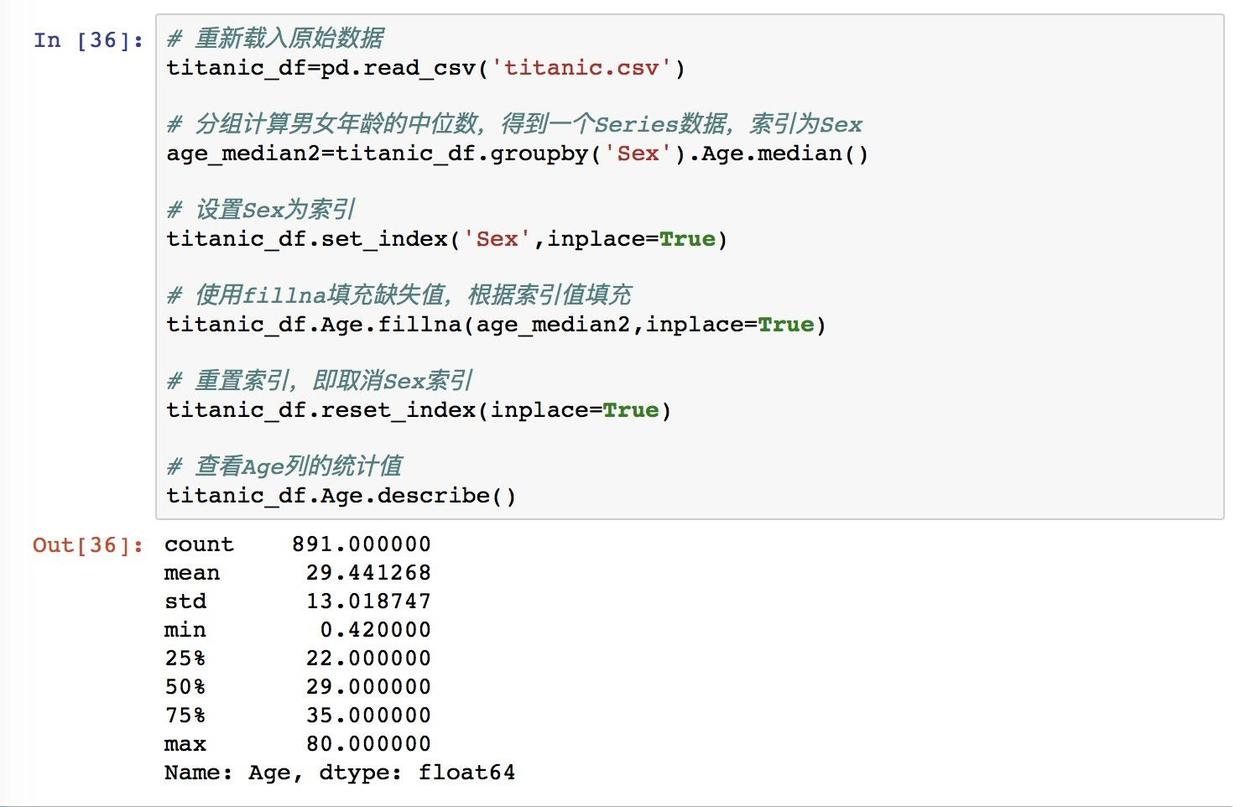
填充性别分类的缺失值
我们将这里分类中位数赋值为 age_median2。填充的套路和上面也是一样一样的,根据 Pandas 的自动匹配,填充的时候会根据索引来匹配不同的值了。因为后续需要用到 Sex 这一列,所以这里也需要重置索引,将索引变成它的列。这里使用 reset_index。
非空值是 891 时就说明缺失值全部填充完毕了,这时候的均值是29.4。
所以到这里,我们把性别分类的缺失值也用各自的中位数填充完毕了。下一步要考虑的是,同时两个因素的影响:
同时考虑性别和舱位因素
那我们首先来看一下,在不同年龄和不同舱位的中位数,有什么变化呢?
groupby 分组的对象分别是 Pclass 舱位 和 Sex 性别,由于这里需要考量的有两个因素:性别和舱位,所以这里需要使用到中括号,后面加上用 Age.median 就可以得到分组的中位数了。
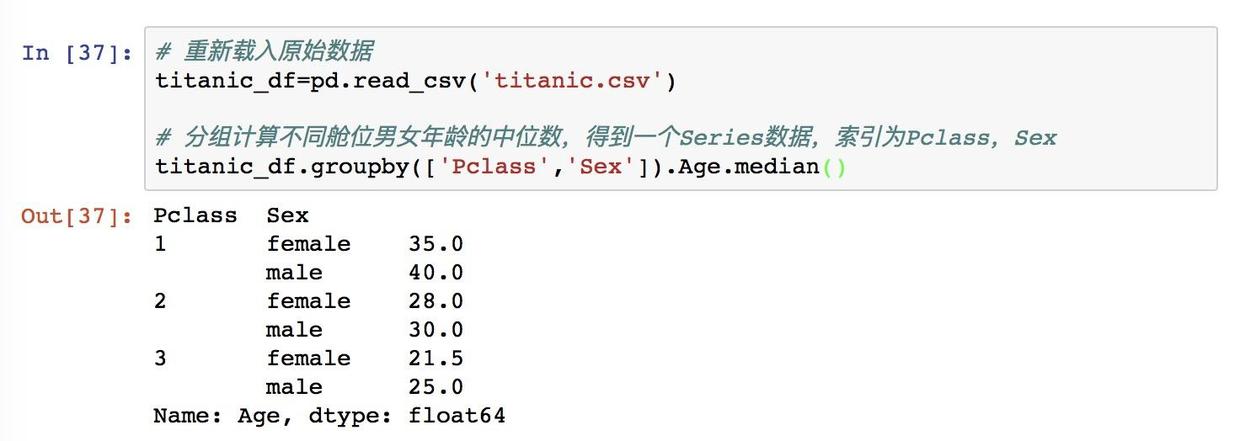
不同舱位男女年龄的中位数
这里就有两个索引,分别是舱位和性别,我们可以看到,随着舱位的下降,它的年龄也是在下降的。用我们的话理解就是,年轻人普遍比年长的穷啊,年龄大一点的人积累的财富也多一点。
那接下来我们就用得出的中位数来各自重新赋值给舱位和性别。这时还是可以用 fillna 的,但是需要设置二重索引。
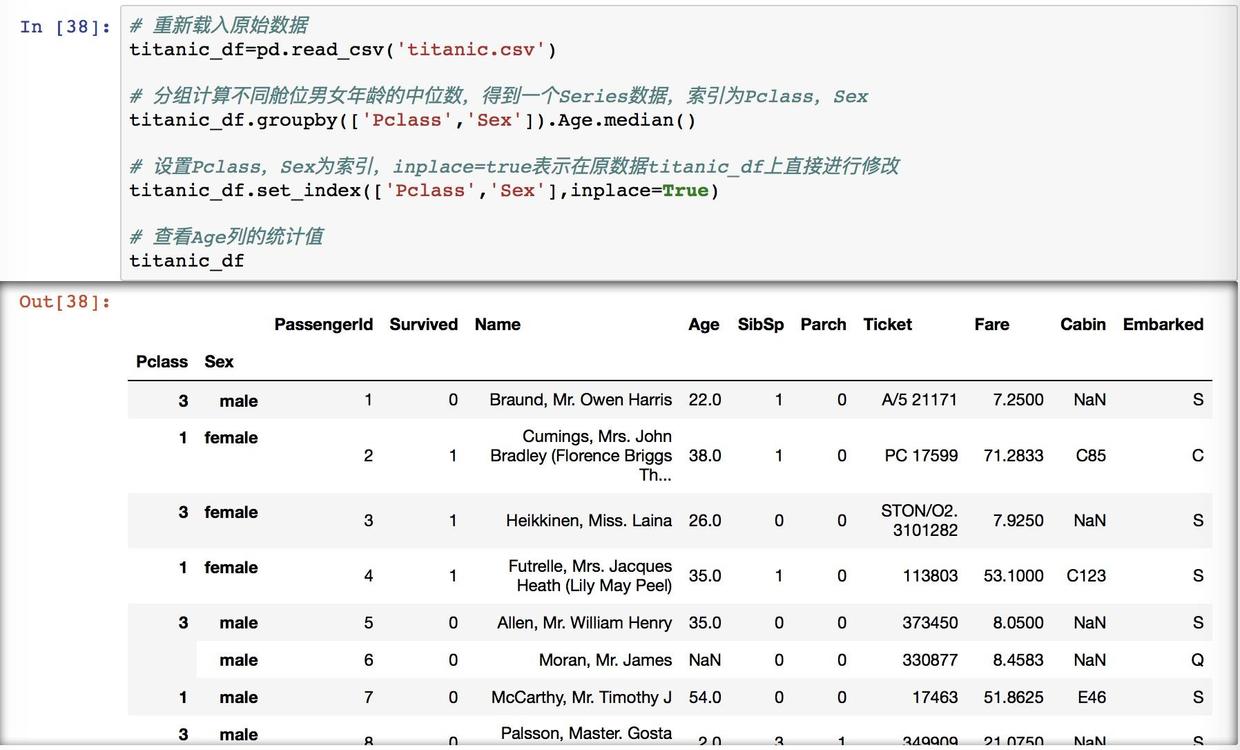
舱位和年龄的分类
套路还是一样的,把这里得出的中位数赋值为 age_median3,然后对索引进行重新的赋值,同样的,这里有两个因素,也是使用中括号,用 set_index 的方法。
然后来看一下重置索引后的数据。看输出我们是可以看到二重索引的,第一列的组合内容一共有 3*2=6 种情况。在列上面,已经没有 Pclass 和 Sex 两列数据了,因为此刻它们已经在索引上了。
现在按同样的方法 fillna ,用索引值来匹配不同的中位数。
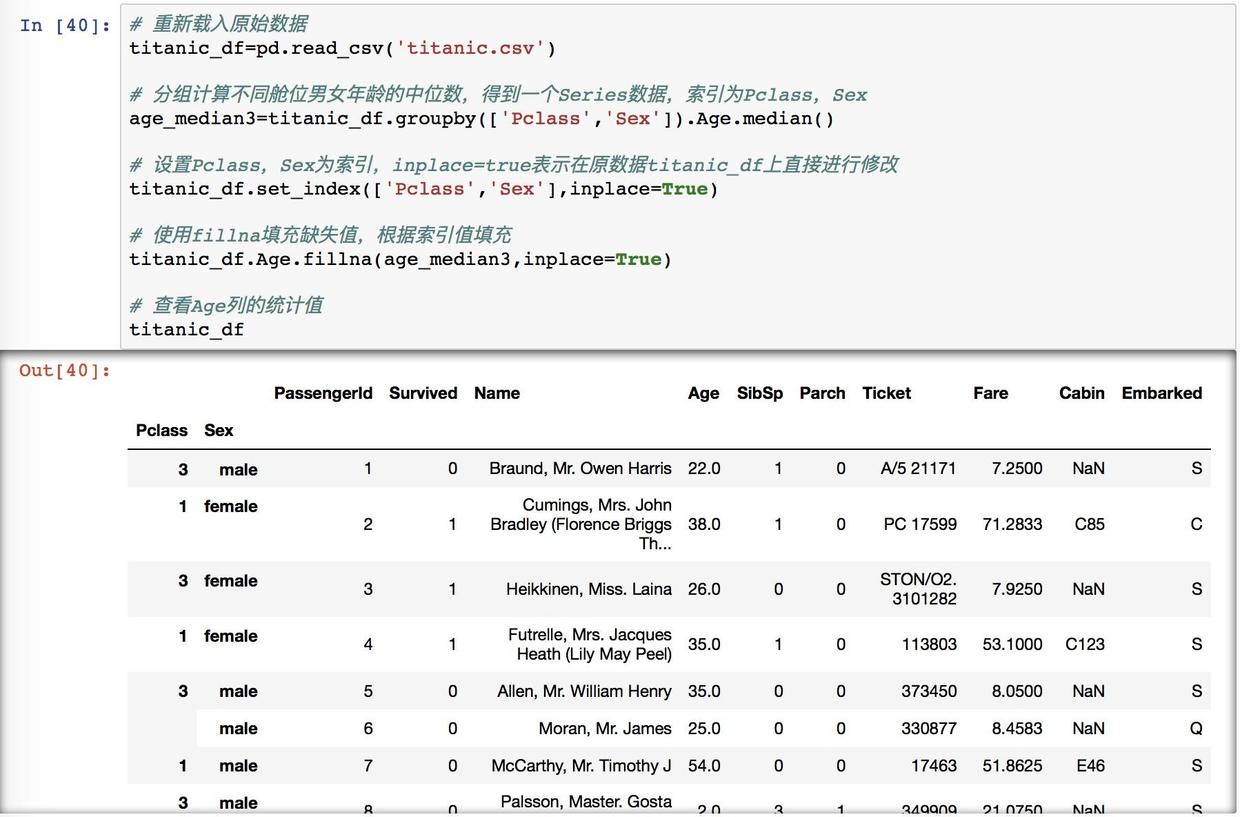
额。。。这两张看起来和上面的一毛一样啊,是我哪里错了吗。。。?
为了还原这样的索引,这里用 reset来重置
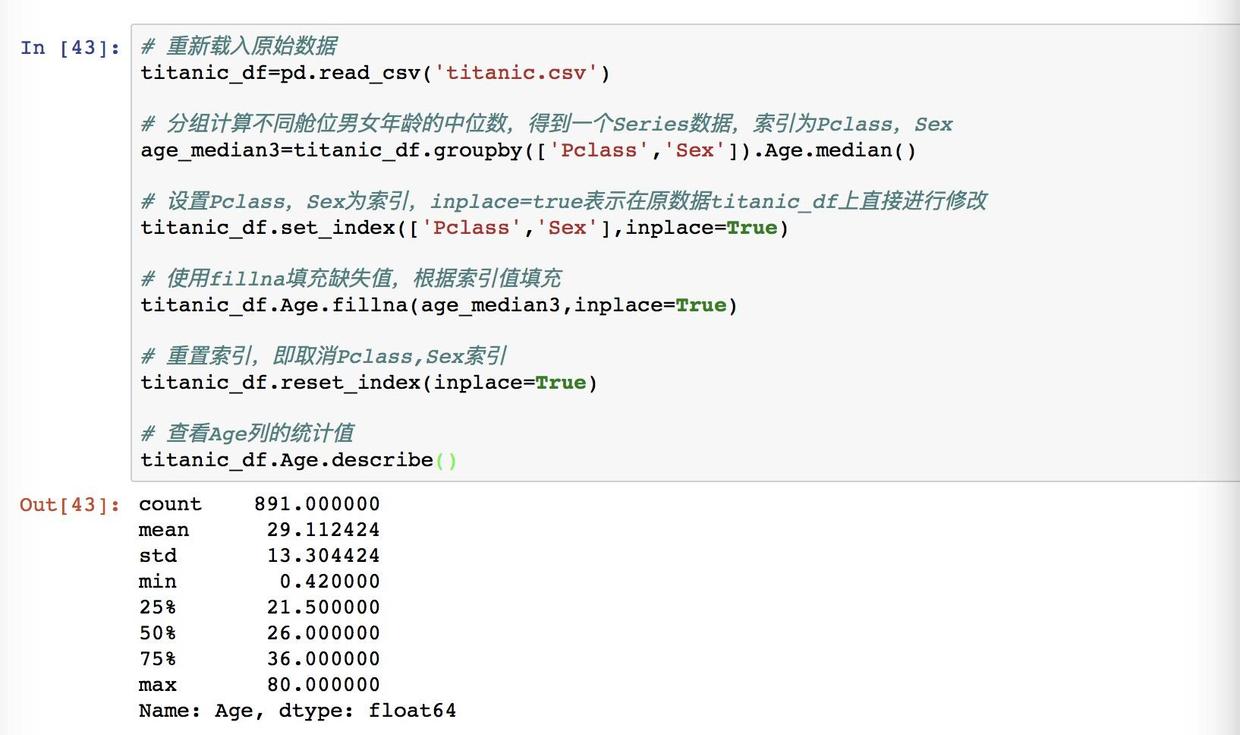
分类填充结果
这里的输出可以看到非空数值已经是891了,表示已经填满缺失值了。平均值下降到了29.1岁,因为三等舱的人数比较多,而且年龄比较小,所以拉低了平均值。
我们总结一下,这里使用的 fillna 的方法,可以对总体的中位数进行操作,或者分类之后对中位数进行操作。分组之后由于有索引,所以同时也需要对原始数据进行索引,对于相同索引值,可以用匹配来进行填充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号