


Python、Amos汽车用户满意度数据分析:BERT情感分析、CatBoost、XGBoost、LightGBM、ACSI、GMM聚类、SHAP解释、MICE插补、PCA降维、熵权法
全文链接:https://tecdat.cn/?p=44650
原文出处:拓端数据部落公众号

关于分析师

在此对 Jiajun Tang 对本文所作的贡献表示诚挚感谢,他在浙江工商大学完成了应用统计专业的硕士学位,专注数据分析领域。擅长 Python、stata、spss、机器学习、深度学习、数据分析 。
Jiajun Tang 曾在科技领域从事数据分析师相关工作,参与过多源异构数据处理、用户满意度建模等项目,积累了丰富的数据分析与机器学习建模实践经验。最近的参与包括为汽车行业客户提供基于数据分析的用户体验优化与决策支持方案,助力企业精准把握市场需求,构建差异化竞争优势。
专题:汽车用户满意度多维度数据分析与建模实践
引言
在汽车市场竞争日趋激烈的当下,用户满意度已成为企业核心竞争力的关键指标,精准挖掘用户体验痛点、量化各维度影响因素对满意度的作用机制,是车企优化产品设计与服务体系的核心需求。作为数据科学家,我们始终致力于通过数据分析技术为企业提供可落地的决策支撑,而用户满意度分析正是数据驱动业务优化的典型场景。本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。
阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
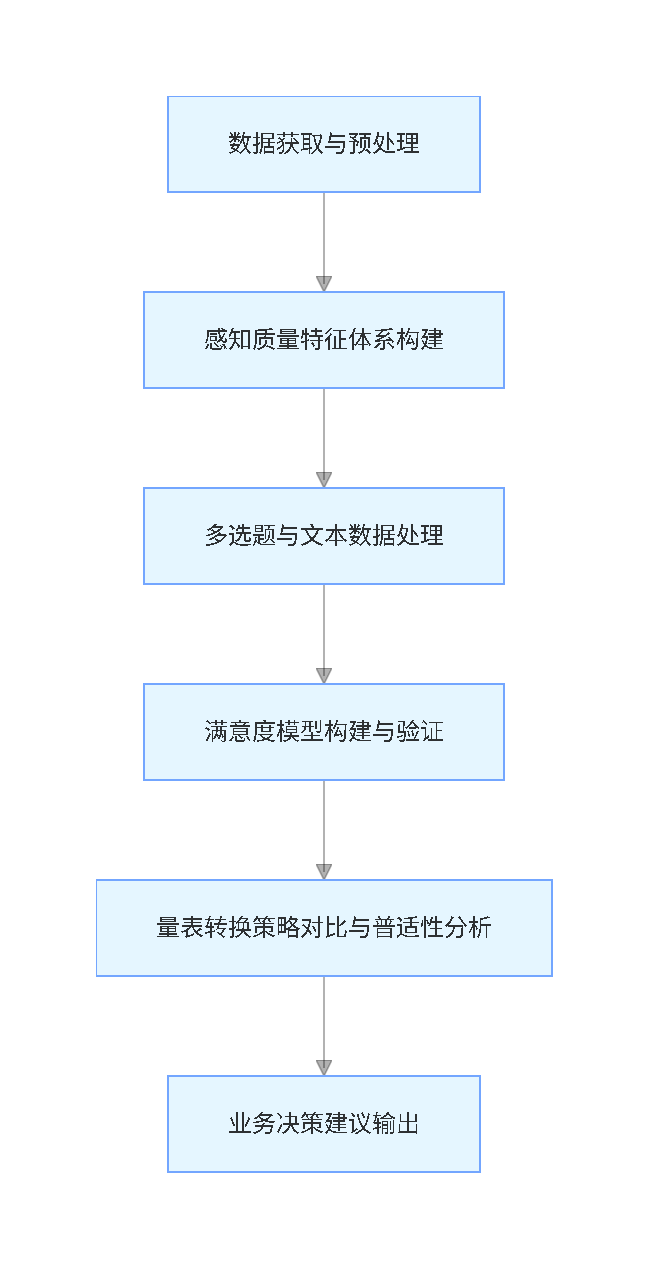
本专题围绕汽车用户满意度数据展开全流程分析,从数据预处理入手,通过构建感知质量特征体系、处理多选题与文本数据,最终基于ACSI模型完成满意度影响机制建模,并探索量表转换的普适性。整个分析过程融合了多种数据分析方法,既解决了实际业务中数据缺失、多类型数据融合等问题,也为车企精准提升用户满意度提供了量化依据。我们还提供24小时响应"代码运行异常"求助的应急修复服务,让大家明白"买代码不如买明白",同时保证人工创作比例,直击"代码能运行但怕查重、怕漏洞"的痛点。
分析脉络流程图(竖版)
项目文件目录结构
数据获取与预处理
数据概况与样本特征
本次分析所用数据源自汽车用户调研问卷,涵盖整车、销售、售后三类问卷数据,样本量分别为16907、3295和4059。问卷包含用户特征、车型特征、购车决策影响因素及各维度满意度评价等内容,全面覆盖用户购车全生命周期体验。
数据截图
用户基本情况分析
样本性别、年龄及城市等级分布如下: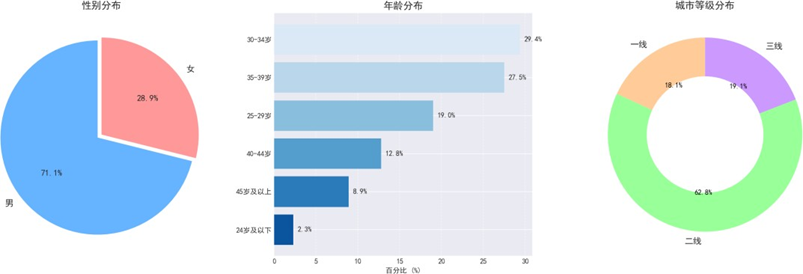
男性用户占比71.1%,女性占28.9%,与行业购车用户性别分布基本吻合,且近60%男性购车会参考配偶意见,车企需重视女性决策影响力。年龄结构上,30-34岁群体占比最高(29.4%),30-39岁群体合计占比56.9%,成为消费主力。城市等级分布中,二线城市占62.8%,一线城市占18.1%,三线城市占19.1%,样本分布契合不同城市用户的购车需求特征,为后续分场景分析提供支撑。
受教育程度与职业情况分析如下: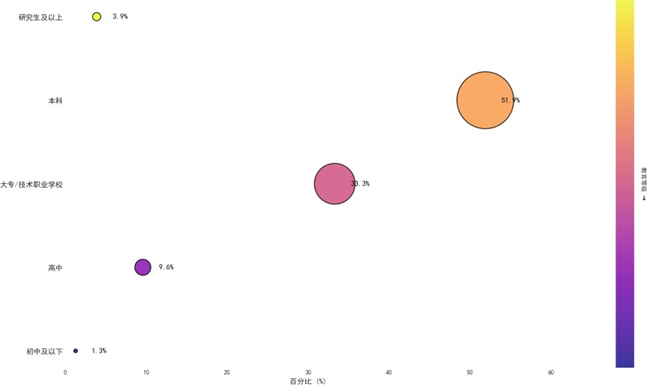
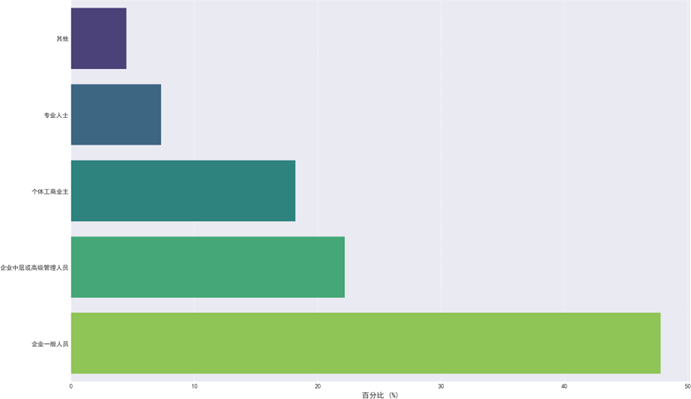
受教育程度以本科学历为主(51.9%),专科/高职次之(33.3%),与30-39岁主力消费群体的高等教育普及率相符。职业分布中,企业一般人员占比最高(47.8%),其次为企业中高管(22.2%)和个体工商业主(18.2%),这些群体的收入水平与购车需求高度匹配,为质量可靠性、性能设计、销售服务等核心维度的分析提供了有效样本基础。
汽车行驶里程分布
汽车行驶里程分布中,5千公里以内和5-1万公里的短期里程占比73.1%,对应3-12个月新用户;1-2万公里和2万公里以上的中长期里程覆盖1-3年用户,该分布契合行业新车使用规律,可全面捕捉用户全生命周期体验变化。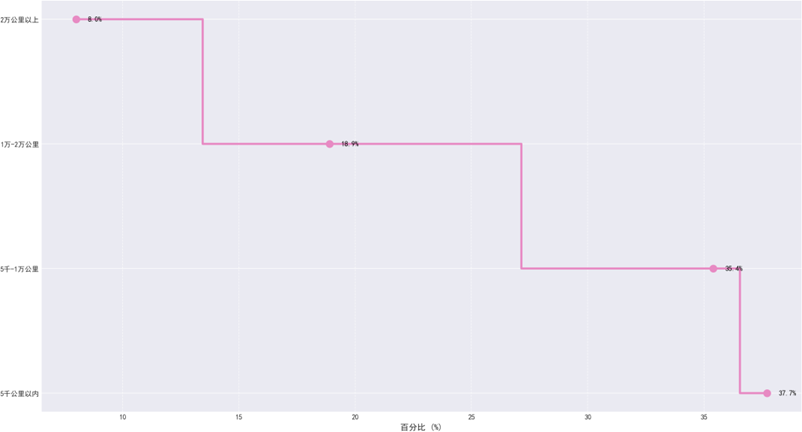
数据预处理实施
缺失值处理
我们首先对三类问卷数据的缺失值进行可视化分析: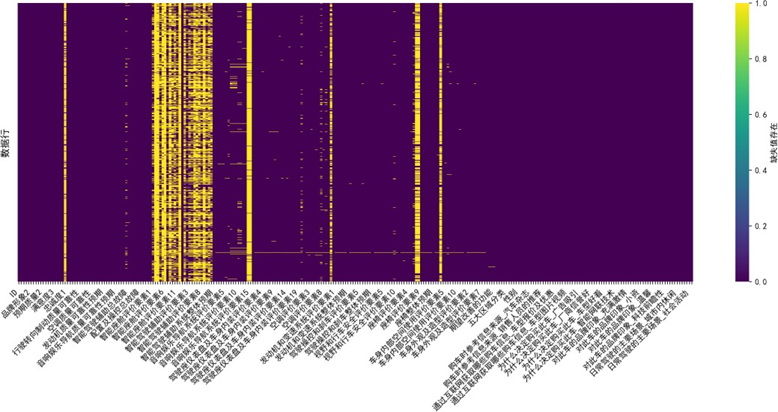


分析发现,缺失值主要集中于"购车决策动因"“信息获取渠道"及"品牌认知"三个维度,经验证这些维度为多选题设计,缺失本质为"未选择该选项”,反映用户真实决策行为,故不进行填补;而感知质量细项指标的缺失值采用列均值填补,确保质量评价数据的完整性,填补后列均值偏差≤0.5%,满足分析要求。
异常值与重复值处理
通过Python检索发现,评分数值均在0-10的合理范围,无异常值;利用duplicated().sum()函数统计并剔除重复行,去重后数据维度无变化,说明原始数据质量良好。
相关文章
专题:2025年游戏科技的AI革新研究报告
原文链接:https://tecdat.cn/?p=44082
感知质量特征体系构建
核心思路
数据集涵盖满意度、品牌形象、感知质量(含质量可靠性、性能设计、销售服务质量、售后服务质量)等核心指标,我们采用"降维—赋权"两步法构建各维度综合得分:先通过因子分析(PCA)降维,剔除冗余信息,再用熵权法基于数据变异程度客观赋权,计算综合得分,确保评价体系的科学性与客观性。
质量可靠性特征构建
因子相关性分析
分析发现"智能驾驶辅助总故障"变量存在完全零值分布,各子系统故障数据也普遍存在高零值占比现象(平均89.4%)。为此,我们对所有故障变量进行加总转换,构建复合指标,该指标作为负向代理变量,数值与系统可靠性呈显著负相关,既解决了高零值分布的干扰,又保留了故障信息的工程意义。
特征变量相关性分析显示,核心质量可靠性指标(如发动机、行驶转向制动、智能座舱)呈中高度正相关(相关系数最高达0.75),验证了整车质量感知的系统协同效应;质量可靠性预期指标间存在中度正相关,体现用户质量预期的"跨系统传导效应";"故障水平"与质量指标呈负相关,验证了指标设计合理性,为后续故障影响分析提供支撑。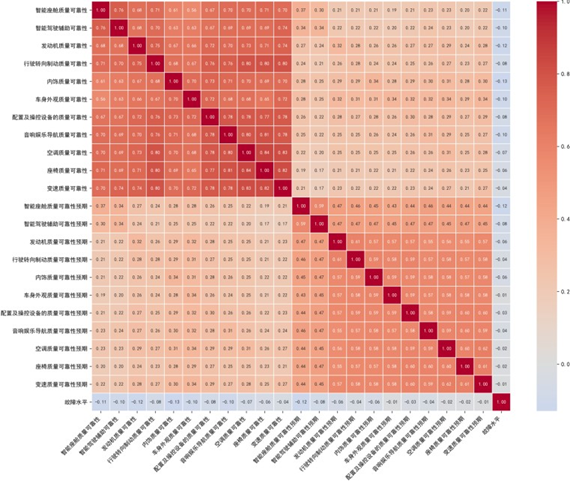
主成分提取与综合得分计算
设定保留80%累积方差,通过PCA将23个子因子压缩为8个主成分,有效降低数据维度并保留核心信息;再用熵权法计算各主成分权重,最终得到质量可靠性综合得分。得分范围为0.325-0.649,呈单峰近似正态分布,峰值位于0.50附近,低分段(<0.40)与高分段(>0.60)样本占比均<5%,无极端异常值,数据离散性适中,说明构建的评价体系能有效刻画用户质量感知的集中趋势与个体差异。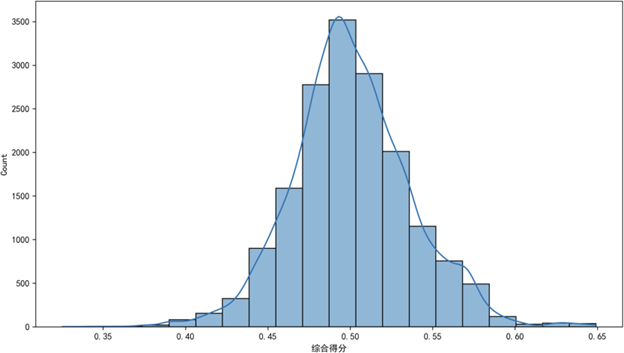
性能设计特征构建
性能设计维度含11个主因子(各平均含12个子因子)及3个开放题项。我们先以0.7为阈值剔除高相关变量,减少多重共线性干扰;对开放题采用SnowNLP库进行情感分析,将文本评价转换为[0,1]标准化情感分数,实现文本信息的量化。
通过PCA对25个总体评价因子降维,保留8个主成分(累计解释方差81.24%),满足信息保留要求;再用熵权法计算各主成分权重,得到性能设计综合得分。得分范围为0.288-0.692,呈单峰分布,峰值集中于0.48-0.52,均值趋近于0.50,反映用户对整车性能设计的综合感知处于中等偏上区间。得分核心区间为0.35-0.65(累计占比超95%),核密度曲线近似正态分布,说明用户对性能设计的评价分布均匀,未出现"高/低评价双群体"的分化特征,为后续优化策略制定提供了稳定的基础数据。
性能设计因子相关性可视化
各主因子下属子因子相关性热力图(部分)如下: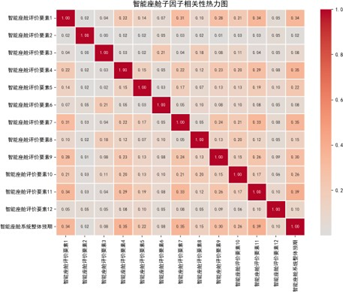
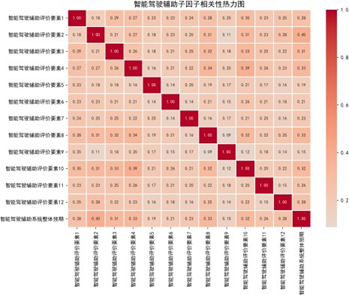
分析显示,各主因子下属子因子相关系数整体较低,相对独立,说明子因子设计具有良好的区分度;而总体评价指标间呈中高强度正相关,如音响娱乐与驾驶舱内饰相关系数达0.9,验证了用户对性能设计的整体感知一致性。
多选题及文本数据处理
多选题数据处理:MICE链式插补
由于三类问卷样本量不均衡(整车16907份、销售3295份、售后4059份),直接建模会导致特征覆盖不全,我们采用MICE(多组链式方程插补)法处理缺失数据。该方法通过建立变量间的条件概率模型,迭代预测并填充缺失值,能更好地保留数据的变异性和变量间的相关性,优于传统均值填充等方法。
具体实施中,以"客户ID"和"满意度"为键纵向合并数据集,构建定制化预测模型,经10轮迭代插补并约束值在0-1区间,生成逻辑自洽的完整数据集。插补前后数据的核密度对比显示,填补数据保留了原始数据的分布特征,未引入异常值,验证了插补模型的合理性。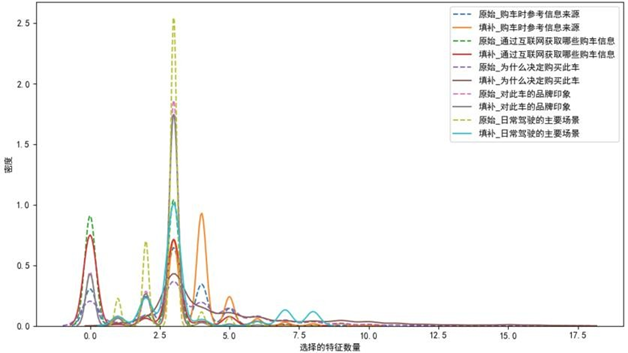
随后对多选题合计得分进行自然对数变换,合成"购车信息关注度"“互联网购车信息获取程度”“购车动机”“品牌认知度”"驾驶场景覆盖度"5个新指标,这些指标能有效反映用户在购车决策各环节的行为特征,为后续消费者分群与满意度影响因素分析提供了丰富的特征支撑。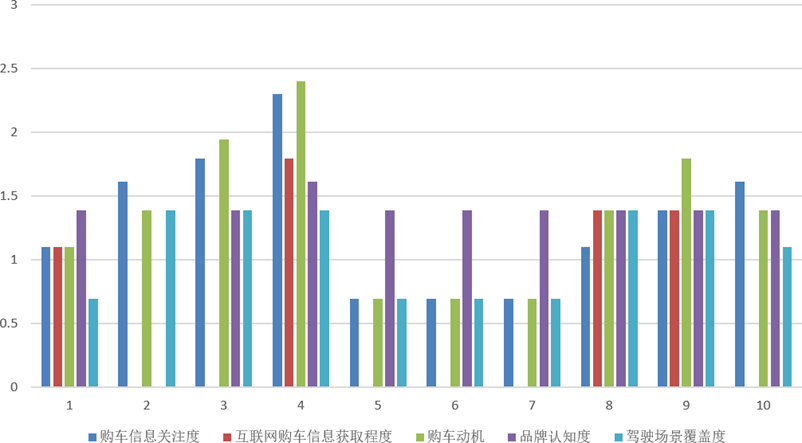
文本数据处理:基于BERT的情感分析
BERT模型原理与适配
BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer编码器的预训练语言模型,通过双向语义建模、掩码语言模型(MLM)和下一句预测(NSP)等预训练任务,能精准捕捉文本全局上下文信息,突破传统单向模型的语义局限。本次使用的BERT-base-chinese模型针对中文场景优化,采用字向量输入,避免分词误差,可有效处理中文评论文本中的成语、网络用语等复杂语义单元。
需要说明的是,BERT的官方仓库Hugging Face国内可访问,但部分海外服务器资源可能受网络影响,国内替代品有阿里云PAI、百度飞桨PaddleNLP等平台提供的中文预训练模型,功能与适配性均能满足情感分析需求。
情感分析实施与结果
我们将"最满意""最不满意"评论文本分别标注为正、负情感样本,按8:2比例划分训练集与验证集,基于BERT-base-chinese模型微调3轮构建情感分析模型。模型评估结果显示,消极与积极类别的精确率、召回率及F1分数均达0.99,整体准确率0.99,宏平均与加权平均指标亦维持0.99的高水平,体现模型在正负类别识别中实现了精确性与覆盖性的卓越平衡。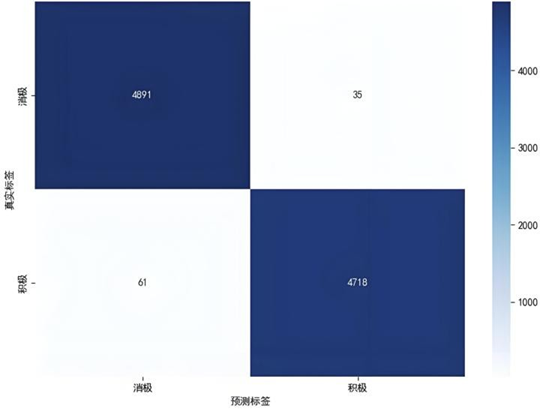
通过词云图探索文本高频词汇,直观呈现用户关注焦点:

“最不满意"文本中"油耗”"隔音"高频出现,反映用户核心痛点;“最满意"文本中"空间”“油耗”"外观"占比领先,体现产品核心优势。同时,"最不满意"文本中出现"没有不满意"表述,需通过规则校准避免误判。
情感倾向分布核密度图显示: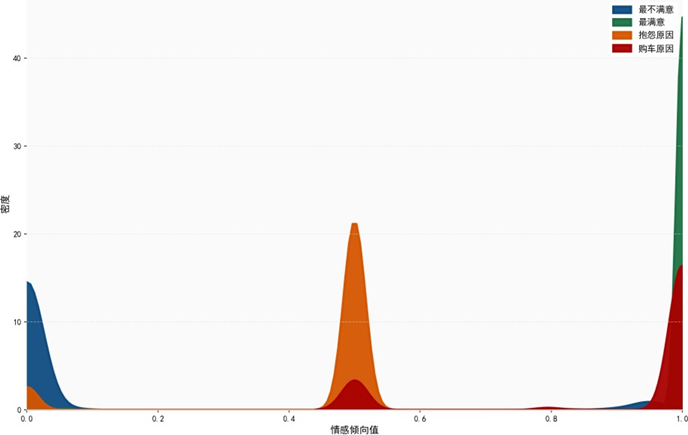
“最不满意的地方"情感值趋近0(消极),含"无"的"抱怨原因”“购车最主要原因"文本情感值为0.5(中性),“最满意的地方"情感值趋近1(积极),分布界限清晰,验证了模型分类的有效性。
我们将四项情感倾向指标(最满意、最不满意、抱怨原因、购车主要原因)合成"整体情感倾向"综合指标,采用德尔菲法确定权重,综合反映用户整体情感态度。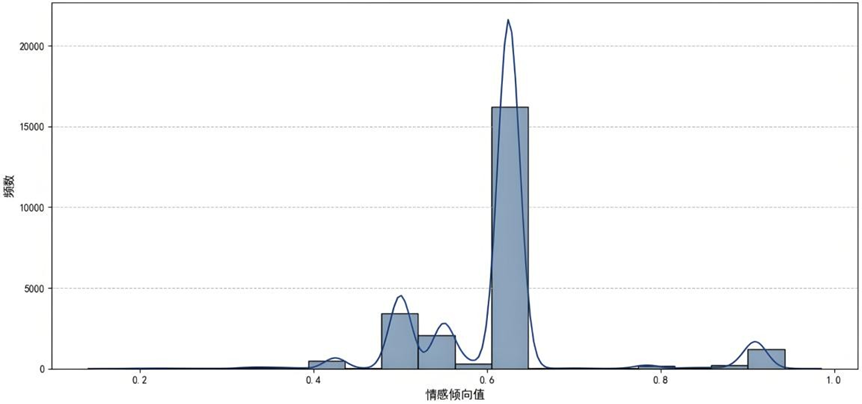
整体情感倾向值在0.6附近形成显著峰值,超半数样本属于"中性偏正面"评价(整体认可但存局部不满),构成品牌体验的"基础共识区间”;[0.4,0.5]区间存在次高峰,10%-20%样本持"中性偏负面"情感,隐含体验缺口与流失风险,可定义为"沉默的流失隐患群体”;极端正面评价([0.8,1.0]区间)占比极低,但作为品牌口碑核心传播源具有战略价值,整体分布呈现显著多样性,反映用户体验的多维复杂性。
相关代码(修改后,省略部分训练细节):
-
import pandas as pd
-
import torch
-
from torch.utils.data import Dataset, DataLoader
-
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
-
import matplotlib.pyplot as plt
-
import seaborn as sns
-
from sklearn.model_selection import train_test_split
-
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
-
from wordcloud import WordCloud
-
import numpy as np
-
import os
-
# 创建结果文件夹
-
result_dir = "文本情感分析"
-
os.makedirs(result_dir, exist_ok=True)
-
# 设置中文字体
-
plt.rcParams['font.sans-serif'] = ['SimHei']
-
plt.rcParams['axes.unicode_minus'] = False
-
# 本地模型路径(国内可访问的本地部署路径)
-
local_model_path = r"D:\Python\bert-base-chinese"
-
output_model_path = r"D:\Python\bert-base-chinese-finetuned"
-
os.makedirs(output_model_path, exist_ok=True)
-
# 加载分词器
-
tokenizer = BertTokenizer.from_pretrained(local_model_path)
-
# 定义数据集类
-
class SentimentDataset(Dataset):
-
def __init__(self, texts, labels, tokenizer, max_length=128):
-
self.encodings = tokenizer(texts, truncation=True, padding='max_length', max_length=max_length)
-
self.labels = labels
-
def __getitem__(self, idx):
-
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
-
item['labels'] = torch.tensor(self.labels[idx])
-
return item
-
def __len__(self):
-
return len(self.labels)
-
# 读取数据
-
df = pd.read_excel('文本数据.xlsx', sheet_name='Sheet1')
-
# 准备训练数据
-
positive_texts = df['最满意的地方_开放题'].dropna().tolist()
-
positive_labels = [1] * len(positive_texts)
-
negative_texts = df['最不满意的地方_开放题'].dropna().tolist()
-
negative_labels = [0] * len(negative_texts)
-
all_texts = positive_texts + negative_texts
-
all_labels = positive_labels + negative_labels
-
# 划分训练集和验证集
-
train_texts, val_texts, train_labels, val_labels = train_test_split(
-
all_texts, all_labels, test_size=0.2, random_state=42
-
)
-
# 创建数据集
-
train_dataset = SentimentDataset(train_texts, train_labels, tokenizer)
-
val_dataset = SentimentDataset(val_texts, val_labels, tokenizer)
-
# 加载模型
-
model = BertForSequenceClassification.from_pretrained(local_model_path, num_labels=2)
-
# 定义训练参数(省略部分优化器细节参数)
-
training_args = TrainingArguments(
-
output_dir=output_model_path,
-
learning_rate=2e-5,
-
per_device_train_batch_size=8,
-
num_train_epochs=3,
-
weight_decay=0.01,
-
eval_strategy="epoch",
-
save_strategy="epoch",
-
load_best_model_at_end=True,
-
metric_for_best_model="accuracy",
-
)
-
# 定义评估函数
-
def compute_metrics(eval_pred):
-
predictions, labels = eval_pred
-
predictions = np.argmax(predictions, axis=1)
-
return {
-
'accuracy': accuracy_score(labels, predictions),
-
'report': classification_report(labels, predictions, target_names=['消极', '积极'])
-
}
-
# 初始化Trainer并训练
-
trainer = Trainer(
-
model=model,
-
args=training_args,
-
train_dataset=train_dataset,
-
eval_dataset=val_dataset,
-
compute_metrics=compute_metrics,
-
)
-
trainer.train() # 省略训练过程中的日志输出细节
-
trainer.save_model(output_model_path)
-
# 增强版情感分析函数
-
def enhanced_sentiment_analysis(text):
-
if pd.isna(text) or text == "无":
-
return 0.5
-
text = str(text).strip()
-
# 自定义规则校准语义复杂性
-
if "暂时没有" in text or ("暂时" in text and "没有" in text):
-
return 0.9
-
if "没有" in text and "最满意" in text:
-
return 0.05
-
if '没有' in text and '不满意' in text:
-
return 0.95 # 双重否定视为高度积极
-
# 模型预测核心逻辑(省略输入预处理细节)
-
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
-
with torch.no_grad():
-
outputs = model(**inputs)
-
probabilities = torch.softmax(outputs.logits, dim=1)
-
return probabilities[0][1].item()
-
# 批量情感分析与可视化(省略部分重复绘图代码)
-
for col in df.columns:
-
if df[col].dtype == object:
-
df[col + '_情感倾向'] = df[col].apply(enhanced_sentiment_analysis)
满意度模型构建与验证
ACSI模型理论基础
ACSI(美国顾客满意度指数)模型由顾客期望、感知质量、感知价值、顾客满意度、顾客抱怨和顾客忠诚六个核心构念组成,基于因果关系理论构建。该模型假设顾客会根据既往消费经验评估未来产品质量与价值,其中顾客期望、感知质量和感知价值为前置变量,通过影响核心中介变量顾客满意度,进而作用于顾客抱怨与忠诚两个结果变量,形成完整的因果传导链条,是国际上广泛应用的满意度评价框架。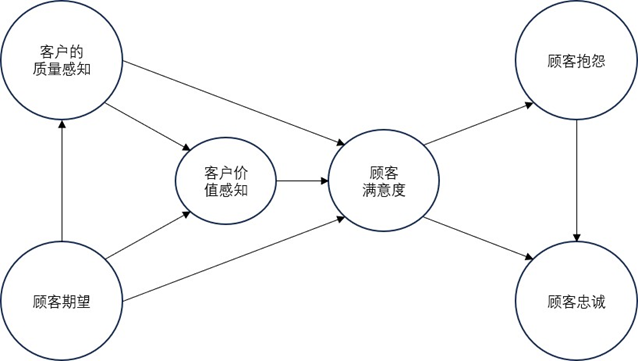
模型假设与实证检验
结合汽车行业特点,我们提出四项研究假设:
- 感知质量对顾客满意度具有显著正向影响(感知质量涵盖质量可靠性、性能设计、销售服务、售后服务四大维度);
- 顾客满意度对品牌忠诚度具有显著正向影响(忠诚度体现为重复购买意愿与品牌推荐行为);
- 顾客满意度对抱怨行为具有显著负向影响(传统认知中满意度越高,抱怨越少);
- 顾客抱怨对顾客忠诚有显著的负向影响(传统认知中抱怨会降低忠诚度)。
通过Amos28.0软件进行结构方程模型拟合与检验,模型适配性指标均达优良水平:
- 绝对拟合指标:GFI=0.985、AGFI=0.976(均>0.9),RMR=0.01、RMSEA=0.045(均<0.05),表明模型对样本数据拟合优度极高,残差极小;
- 相对拟合指标:CFI=0.986、NFI=0.985、TLI=0.981(均远>0.9),显著优于独立模型,证实变量间因果关系的捕捉能力;
- 泛化能力指标:ECVI=0.088<0.1,说明模型避免过拟合,泛化能力良好。
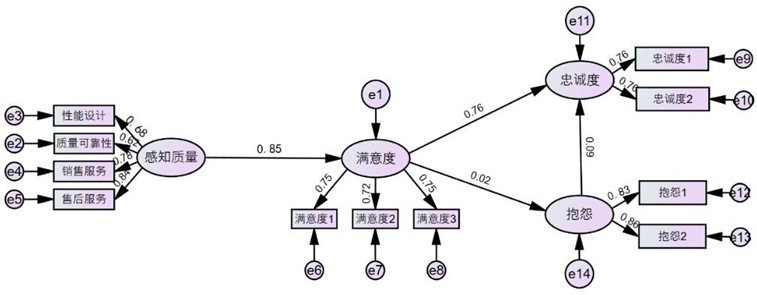
路径关系检验结果如下:![]()
- 感知质量对顾客满意度的路径系数为0.85(CR=45.235,p<0.001),假设1成立,表明感知质量是影响满意度的核心驱动因素,用户对产品与服务的实际体验直接决定满意度水平;
- 顾客满意度对忠诚度的路径系数为0.76(CR=92.947,p<0.001),假设2成立,说明高满意度能显著增强用户的品牌忠诚,推动重复购买与口碑传播;
- 顾客满意度对抱怨的路径系数为0.022(CR=3.462,p<0.001),与假设3相反,呈显著正向影响。这一结果可通过情绪强化理论解释:满意的用户更愿意提出抱怨以改善体验,维护自身高期望,而非单纯因不满产生抱怨;
- 顾客抱怨对忠诚度的路径系数为0.088(CR=13.38,p<0.001),与假设4相反,呈显著正向影响。结合顾客恢复理论,当用户抱怨得到妥善处理时,会感受到品牌对其需求的重视,进而增强信任与忠诚,将负面体验转化为正向情感。
IPA模型补充诊断
为精准定位优化优先级,我们引入重要性—表现分析(IPA)模型,通过计算质量可靠性、性能设计、销售服务、售后服务四大核心维度的重要性与表现得分,构建二维决策矩阵,划分优势区、维持区、机会区、改进区四个象限。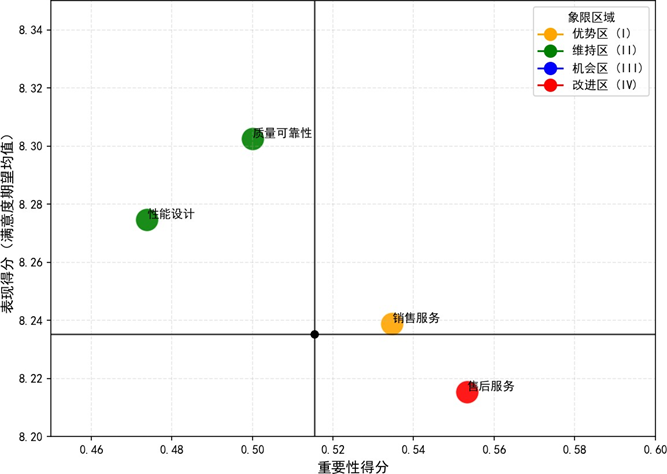
- 优势区(Ⅰ象限):销售服务,重要性与表现双高,是品牌差异化竞争的核心优势,需通过标准化流程+场景化创新持续强化;
- 维持区(Ⅱ象限):质量可靠性、性能设计,表现超均值但重要性略低,是满意度的"基础稳定剂",建议以轻量化迭代维持现有投入,避免资源过度配置;
- 改进区(Ⅳ象限):售后服务,高重要性但低表现,存在明显体验缺口,是短期资源投入的战略优先级领域,需通过优化服务响应效率、构建分层服务方案等措施快速填补短板;
- 机会区(Ⅲ象限):无指标落入,说明核心维度均无"低重要性—低表现"的低效领域,整体布局相对合理。
感知质量特征交互效应分析(随机森林-SHAP联合框架)
为深入解析感知质量各维度的交互作用机制,我们采用随机森林与SHAP(SHapley Additive exPlanations)联合框架,实现"全局趋势+局部差异"的立体解析,突破单一方法的局限。
方法体系原理
随机森林通过Bootstrap抽样和特征随机子空间策略构建多棵决策树,节点分裂过程天然具备特征交互捕获能力;SHAP基于博弈论Shapley值,计算每个特征对预测结果的边际贡献,构建可加性模型,能将黑盒模型的预测结果分解为基准值与各特征贡献之和,实现全局与局部层面的可解释性分析。
PDP全局交互效应可视化
通过部分依赖图(PDP)解析特征的边际效应与交互效应: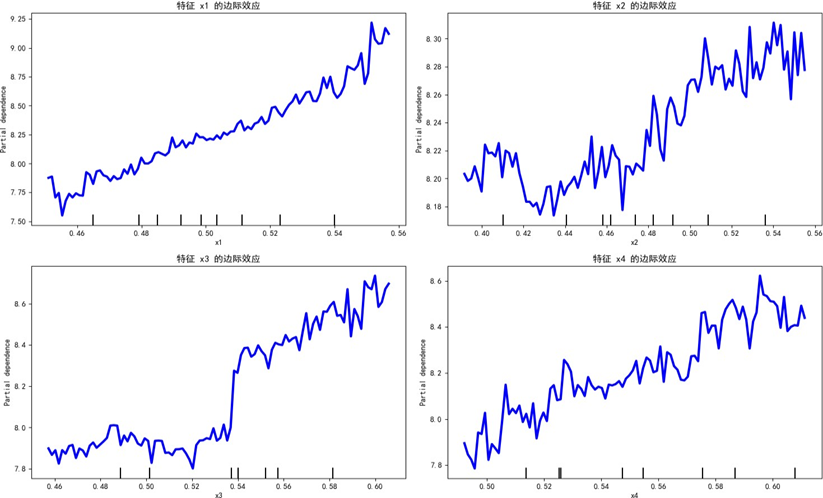
单特征边际效应分析显示,质量可靠性、性能设计、销售服务、售后服务四大维度与感知质量均呈正向关联,但曲线存在非线性波动,表明特征与目标值间存在阈值效应或饱和效应等复杂关系,而非简单线性关联。
特征交互依赖图(部分)如下: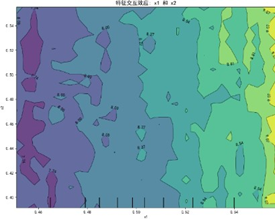
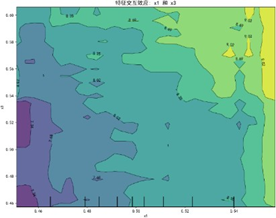
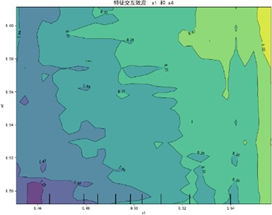

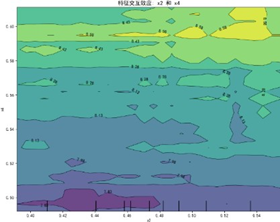
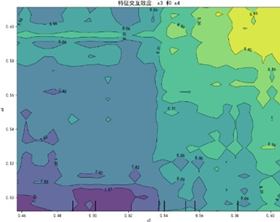
交互图中暖色调区域对应感知质量预测高值,冷色调对应低值,揭示特征高值组合普遍呈现正向协同效应——当两特征同步处于较高区间时,联合作用对感知质量的推动更显著(如质量可靠性与售后服务高值区预测值较低值区提升约15%),表明聚焦特征协同优化是提升感知质量的核心路径。
SHAP局部交互效应归因分析
SHAP蜂群图与依赖图进一步深化分析: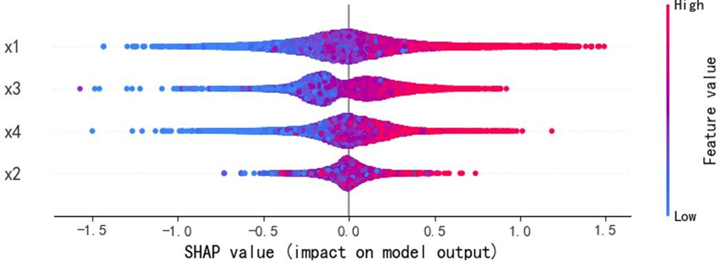
蜂群图显示,质量可靠性(x1)与感知质量呈强正相关,高值(红色)集中对应正SHAP值(显著推升预测),低值(蓝色)集中对应负SHAP值(显著抑制预测);销售服务(x3)、售后服务(x4)呈弱正相关,影响幅度弱于质量可靠性;性能设计(x2)为弱影响特征,SHAP值持续围绕0波动,对预测的边际贡献差异极小。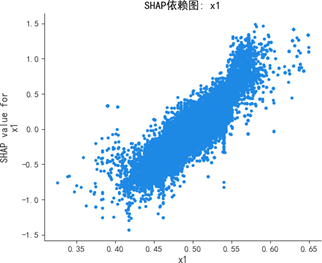
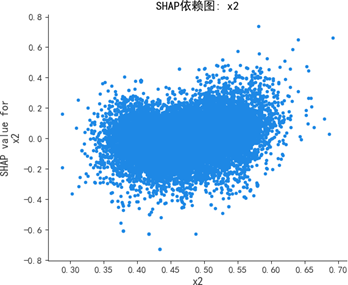
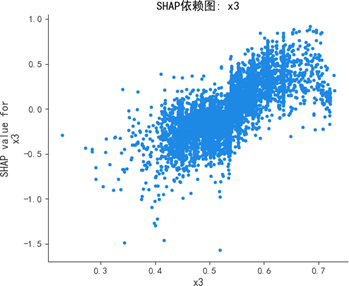
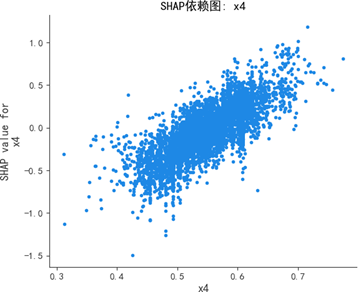
SHAP依赖图进一步揭示:质量可靠性为线性正向特征,取值增大时SHAP值持续上升,影响稳定且显著;销售服务存在阈值效应,当得分超过某一临界值时SHAP值跃升,正向贡献骤增;售后服务弱正向但波动显著,稳定性较差;性能设计交互效应复杂,SHAP值分散无明确趋势,边际效应难以单独解析。
通过随机森林与SHAP的互补分析,明确了各特征的差异化作用模式,为后续业务优化提供了精准的量化依据——如优先强化质量可靠性、突破销售服务阈值、稳定售后服务质量等。
多模型对比与最优模型选择
为构建更精准的满意度预测模型,我们对比了随机森林、XGBoost、LightGBM、CatBoost四种主流机器学习算法,通过拟合效果图、学习曲线及性能指标综合评估模型优劣。
模型拟合效果与学习曲线
各模型预测—真实值拟合效果图(部分):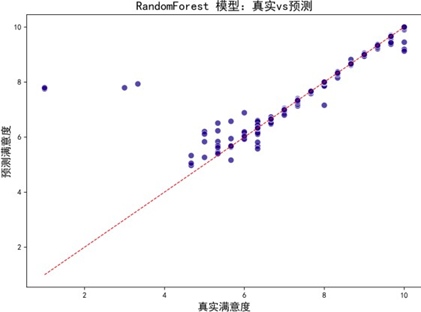
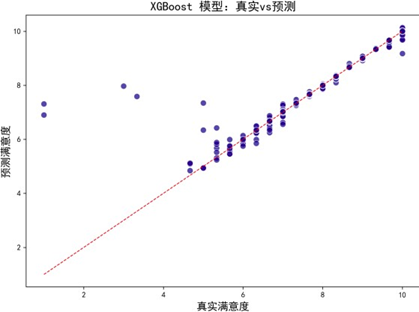
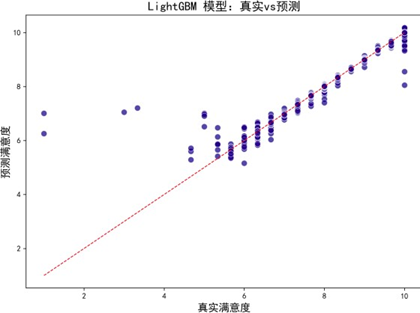
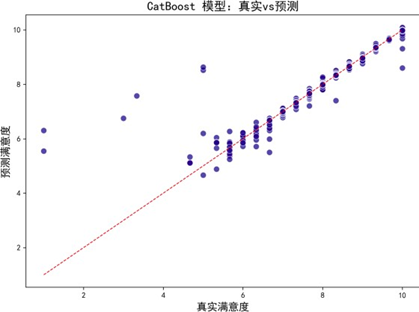
拟合效果图显示,各模型预测偏差均较低,与真实值一致性良好。学习曲线进一步评估模型泛化能力: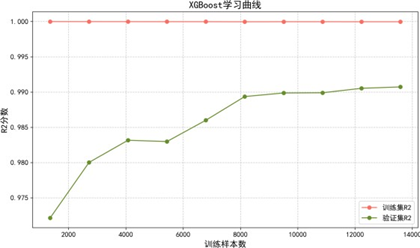
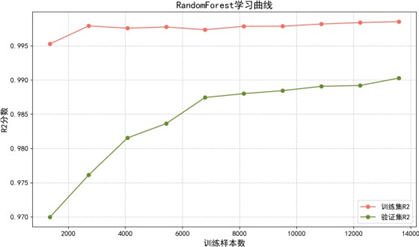
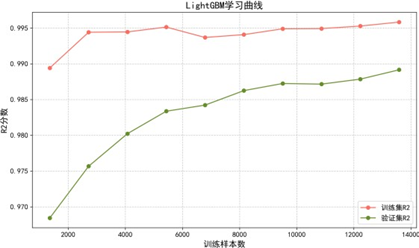
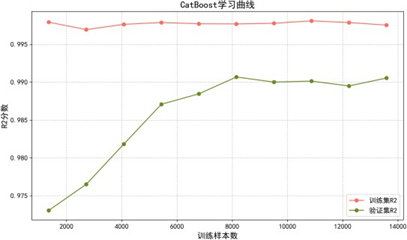
学习曲线分析表明:
- 随机森林:通过Bagging集成与特征采样天然具备正则化效果,小样本时存在轻微欠拟合,数据量增加后泛化能力稳步提升,无显著过拟合;
- XGBoost:通过贪心分裂、L1/L2正则及剪枝策略平衡拟合与泛化,数据量增加后方差降低,有效缓解过拟合;
- LightGBM:采用直方图算法与GOSS采样优化效率,拟合与泛化平衡最优,训练集与验证集性能差异小,方差低;
- CatBoost:通过有序提升与类别编码处理,对数据分布变化敏感,中期因样本分布波动性能略有震荡,最终稳定收敛,泛化稳健性强。
模型性能评估与超参数调优
基于R²、MAE、MSE三项核心指标评估模型性能:
| 模型 | R² | MAE | MSE |
|---|---|---|---|
| 随机森林 | 0.9227 | 0.0193 | 0.0285 |
| XGBoost | 0.9568 | 0.0152 | 0.0213 |
| LightGBM | 0.9315 | 0.0173 | 0.0237 |
| CatBoost | 0.9752 | 0.0128 | 0.0172 |
CatBoost模型表现最优,R²达0.9752,较次优模型提升约2%,MSE低至0.0172,较其他模型降低20%-30%,拟合优度与误差控制能力均领先。
通过网格搜索算法对CatBoost进行超参数调优,定义学习率、最大树深度、迭代次数等关键参数空间,采用五折交叉验证评估各参数组合性能: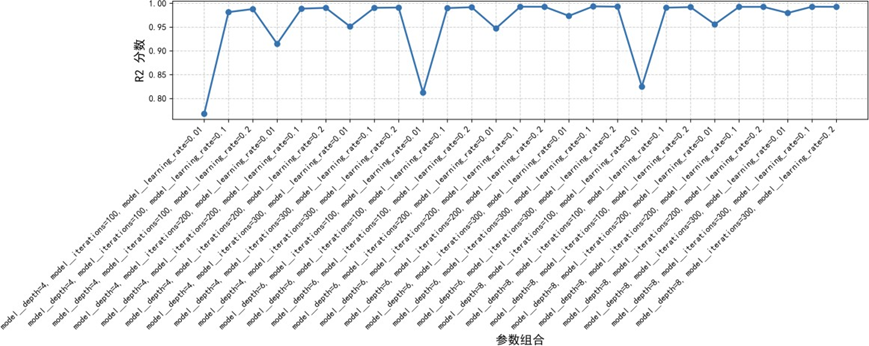
当学习率为0.1、最大深度为6、迭代次数为300时,模型达到最优性能,R²提升至0.9935,进一步提升了预测精度。
CatBoost模型SHAP可解释性分析
对优化后的CatBoost模型进行SHAP可解释性分析,揭示核心影响因素: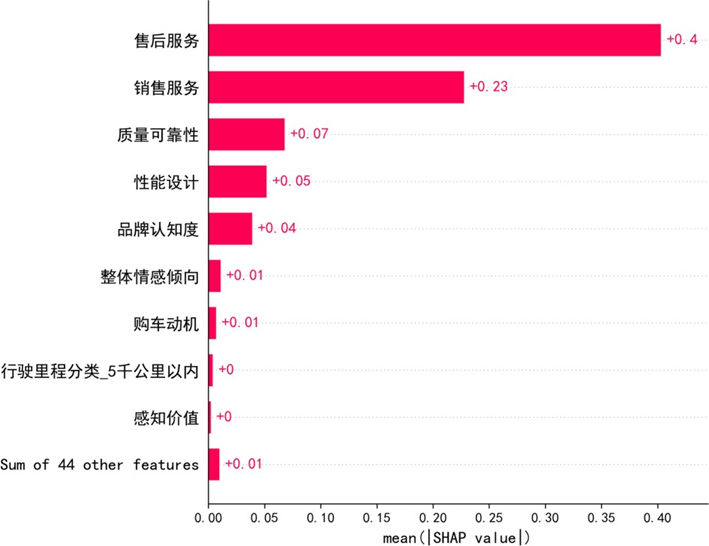
SHAP特征重要性显示,售后服务(0.40)、销售服务(0.23)对满意度的解释力最强,是核心驱动因素;质量可靠性(0.07)、性能设计(0.05)、品牌认知度(0.04)等呈显著正向影响,其余44项特征总贡献仅0.01,边际效应可忽略。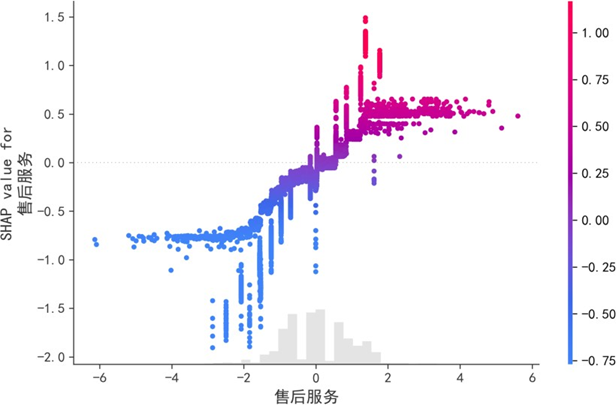
售后服务的SHAP依赖图表明,其对满意度的影响呈非线性:评分<2时SHAP值多为负,抑制满意度;评分>2后,SHAP值随评分上升呈非线性增长,且增长速率逐渐加快,凸显售后服务质量突破临界值后的显著正向效应。
通过SHAP瀑布图解析典型样本的预测逻辑: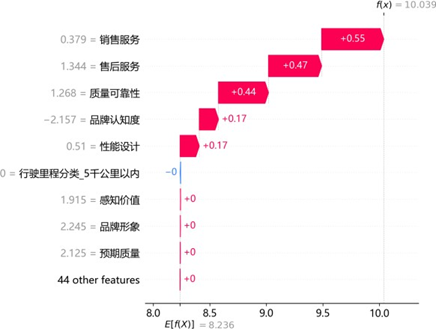
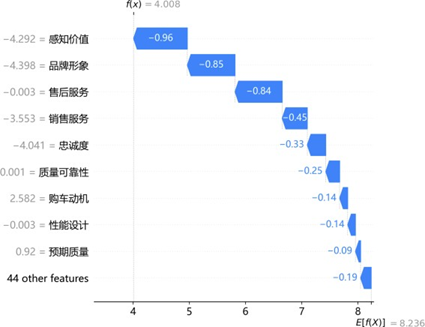
高满意度样本中,销售服务(0.55)、售后服务(0.47)、质量可靠性(0.44)及品牌认知度(0.17)为核心正向驱动,共同推升预测值显著高于均值;低满意度样本中,感知价值(-0.96)、品牌形象(-0.85)、售后服务(-0.84)及销售服务(-0.45)为关键负向拖累,即使质量可靠性等存在微弱正向贡献,仍无法抵消整体抑制效应。同一特征(如售后服务)在不同样本中呈现双向差异贡献,印证其影响的非线性与情境依赖性,为精准化服务策略制定提供了微观层面的依据。
量表转换策略对比与普适性分析
传统十级量表调研存在繁琐性问题,不利于快速收集用户反馈,我们探索通过K-means聚类与GMM(高斯混合模型)将其转换为更简洁的二分法(满意/不满意)与五级量表,并验证转换后模型的有效性与普适性。
K-means二分法量表转换与建模
转换规则与验证
K-means是基于距离的硬聚类算法,通过迭代优化质心位置,将数据划分为紧凑且分离的簇。我们采用K-means++初始化策略(优化初始质心选择),将十级量表映射为二分法(0=不满意,1=满意),该方法能动态适配数据分布,较固定阈值法更适应偏态数据特征。
转换后各子维度的高—低分组频率分布(部分):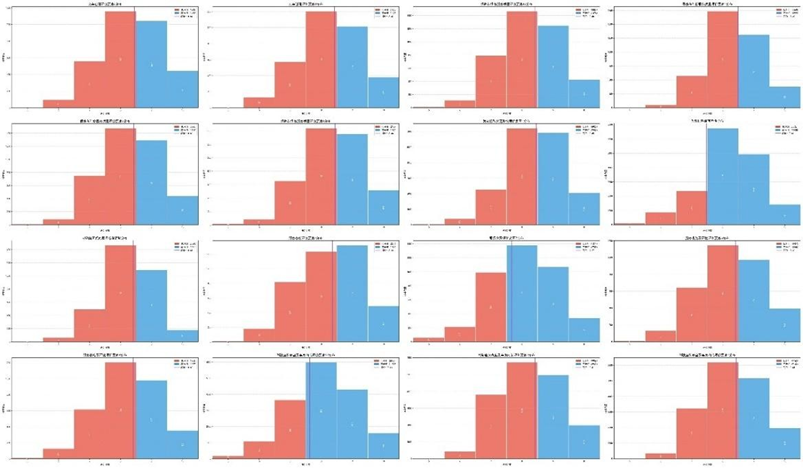
分布分析显示,高分组在"交车过程评价""保养服务质量"等维度呈右偏分布(峰值3-5分),低分组在1-3分占比显著,二者边界清晰;K-means自适应阈值能有效划分群体,即使在"智能网联功能体验"等偏态分布维度也能精准区分,验证了转换规则的合理性。
通过轮廓系数(多数维度>0.7)与Calinski-Harabasz指数(部分维度突破10,000)评估聚类质量,结果表明簇内紧凑性与簇间分离度良好,聚类结构具有统计显著性。
品牌偏好交叉分析
二分法分组与品牌属性的交叉分布通过桑基图可视化: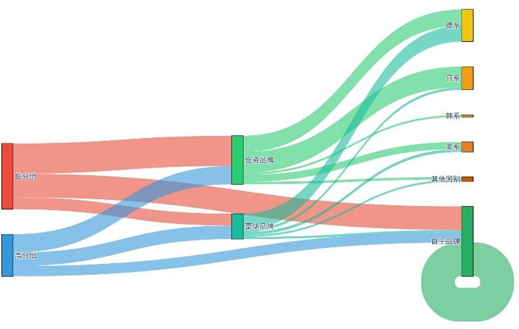
桑基图清晰呈现:0分组(不满意)更偏好合资品牌的德系/日系车型,1分组(满意)更倾向豪华品牌;这种群体品牌偏好异质性,为车企差异化营销提供了精准依据——如对0分组用户推送合资品牌优化升级信息,对1分组用户强化豪华品牌专属服务体验。
二分法下ACSI模型构建
参照感知质量特征构建方法,对二分法数据进行PCA降维与熵权法赋权,计算各维度综合得分: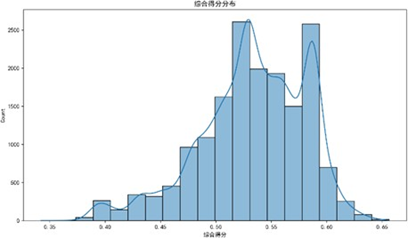
综合得分分布特征显示,质量可靠性得分集中于0.50-0.60(单峰分布),表现稳定;性能设计峰值在0.40-0.50(左偏分布),需突破高分段;销售服务低分段占比高,为核心短板;售后服务分布分散、两极分化,需强化中间段稳定性。
基于二分法数据构建ACSI模型,拟合指标均达优良水平(GFI=0.955、AGFI=0.925、CFI=0.958等),核心路径关系与原十级量表模型一致,验证了二分法转换的有效性。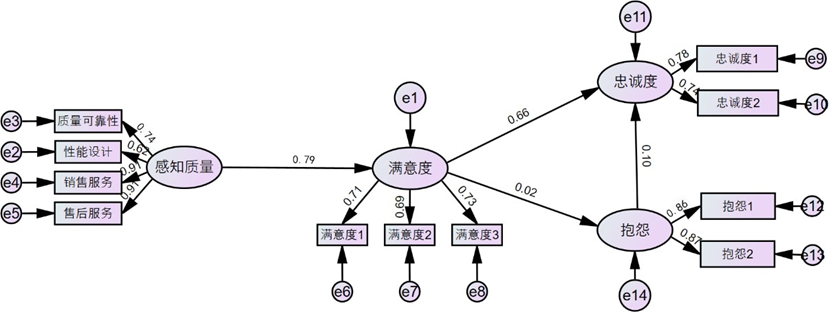
GMM五级量表转换与建模
转换原理与特征验证
GMM(高斯混合模型)是概率生成模型,假设观测数据由K个高斯分布混合生成,通过EM(期望最大化)算法迭代估计分布参数(均值、方差、权重),实现软聚类(每个样本有属于各簇的概率)。该方法能捕捉数据的概率分布特征,较K-means硬聚类更灵活,适合量表的精细划分。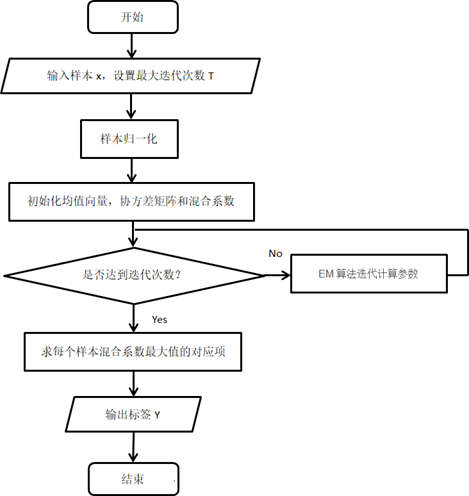
通过GMM将十级量表转换为五级量表(1=极不满意至5=极满意),转换后各子维度频率分布(部分):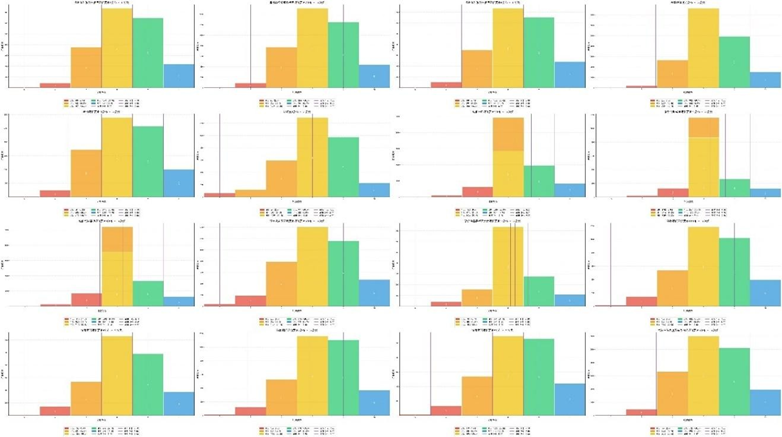
多数维度呈"中间集中"的正态分布(3-4级占比超60%),与GMM拟合的概率分布一致;部分维度(如"智能网联功能体验")呈偏态分布,反映用户体验短板,GMM能精准识别此类差异,较传统均匀分段法更具科学性。
聚类质量评估显示,各维度轮廓系数普遍接近1,Calinski-Harabasz指数在体验型指标(如"服务响应时效")中显著高于感知型指标(如"品牌感知"),样本点集中于"高指数—高轮廓系数"区域,验证了五分类的可靠性。
品牌偏好与综合得分分析
五分类群体与品牌属性的交叉分布桑基图: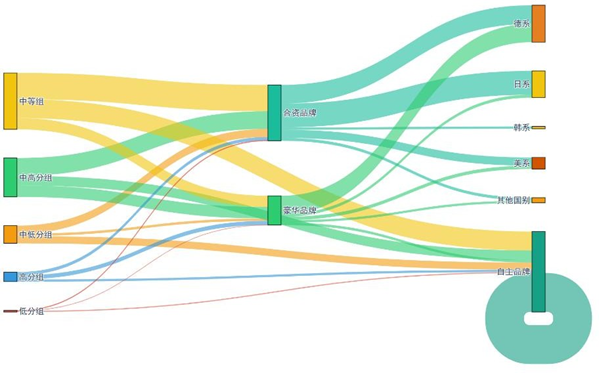
高分组(4-5级)集中选择豪华品牌(德系/日系为主),中高分组(3-4级)兼顾合资与豪华品牌,中等组(3级)偏好合资德系/日系,中低分组(2-3级)分散选择合资日系/韩系及自主品牌,低分组(1-2级)多倾向合资韩系/美系与自主品牌,为分层营销与服务提供了更精细的依据。
对GMM转换后数据进行PCA降维与熵权法赋权,计算各维度综合得分,分布特征显示:质量可靠性表现稳定、高分段占比高;性能设计分布均衡,需聚焦用户需求优化;销售服务与售后服务需重点关注中间段体验修复,提升整体稳定性。
GMM下ACSI模型构建
基于GMM转换数据构建ACSI模型,拟合指标优良(GFI=0.980、AGFI=0.966、CFI=0.981等),核心路径关系与原模型一致,进一步验证了量表转换的有效性。
普适性分析结论
两种量表转换方法代入ACSI模型后,核心结论与原十级量表完全一致,表明尺度转换未改变潜变量核心结构(如"感知质量→满意度→忠诚"的因果路径),仅需区分"高/低表现"即可维持变量影响逻辑。同时,K-means硬聚类与GMM软聚类的分类结果均支持相同结论,佐证了聚类方法的兼容性与数据群体分类边界的明确性。
结构方程模型对观测变量尺度转换的包容性是结论普适性的核心原因——只要观测题项能反映潜变量的"高低水平",无论采用十级、二分还是五级量表,模型的因果推断基础均不受影响。这一发现为企业实际调研提供了灵活选择:可根据调研场景(如快速问卷、深度调研)选择合适的量表尺度,在降低调研成本的同时,保证分析结论的一致性与可靠性。
总结与业务建议
核心结论
- 感知质量是满意度的核心驱动因素,其中售后服务与销售服务的贡献度最高,质量可靠性与性能设计为基础支撑,四者协同优化能显著提升用户满意度;
- 满意度与抱怨、忠诚的关系突破传统认知:满意用户更愿意提出抱怨(正向影响),妥善处理抱怨能增强忠诚(正向影响),形成"满意→主动反馈→抱怨修复→忠诚强化"的正向循环;
- 量表转换具有普适性,K-means二分法与GMM五级量表转换后,ACSI模型结论与原十级量表一致,企业可灵活选择量表尺度以适配不同调研需求;
- 用户体验存在显著异质性:二线城市、30-39岁、企业一般人员/中高管是核心消费群体,品牌偏好呈现分层特征,豪华品牌用户更关注服务质量,合资品牌用户重视性价比,自主品牌用户对基础性能要求较高。
业务建议
- 产品端:构建全链路质量闭环管理,通过用户抱怨数据反推产品优化(如针对"油耗"“隔音"等痛点升级技术);将抽象质量转化为可感知信息(如"50万公里模拟测试记录”),强化用户质量感知;
- 服务端:优先改进售后服务短板,建立"24小时智能响应通道"与分层服务方案;巩固销售服务优势,打造标准化+场景化的服务流程;建立高效抱怨处理机制,将抱怨转化为忠诚提升契机;
- 营销端:基于用户分层特征制定差异化策略,对核心消费群体精准推送产品与服务信息;激活高忠诚用户的口碑传播价值,授予"品牌体验官"身份,通过新品试驾、定制化活动等放大口碑效应;
- 调研端:根据实际需求选择量表尺度,快速调研采用二分法降低用户填写成本,深度调研采用五级量表获取更精细的体验数据,提升调研效率与效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号