


Python梯度提升树GBT、随机森林、决策树对链家多城市二手房数据价格预测与区域差异可视化分析——基于数据爬取与特征工程优化|附代码数据
全文链接:https://tecdat.cn/?p=44342
原文出处:拓端数据部落公众号
分析师:Liping Xiao

引言
随着国内房地产市场进入精细化发展阶段,二手房交易已成为楼市流通的核心组成部分,购房者、投资者及行业从业者对市场动态与价格趋势的精准把握需求日益迫切。作为数据科学家,我们始终相信“数据驱动决策”的核心价值——从海量房产信息中挖掘规律,既能为普通购房者提供理性参考,也能为行业调控提供数据支撑。
本文内容改编自我们为某房地产咨询机构完成的实际项目,团队通过链家平台爬取多城市二手房数据,构建了一套从数据采集到模型落地的完整解决方案,已在实际业务中验证有效性。文章将详细拆解“数据爬取-清洗-分析-建模-优化”的全流程:先通过Python爬取三个城市各区二手房核心信息,经数据预处理后开展多维度可视化分析,再利用决策树(DT)、梯度提升树(GBT)、随机森林(RF)三种模型实现价格预测,最后通过异常值处理与网格搜索优化模型性能。
本文内容源自过往项目技术沉淀与已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
数据爬取
数据清洗
探索式数据分析
特征工程
模型训练 DT/GBT/RF
模型优化 异常值处理+网格搜索
结果输出 价格预测+区域洞察
项目背景与目标
项目背景
在居住品质升级与楼市结构调整的双重驱动下,二手房市场的区域差异、价格影响因素愈发复杂。不同城市、同一城市不同区域的房价受地理位置、房屋属性、建筑年代等多重因素影响,传统经验判断已难以适应市场变化。基于此,我们聚焦三个代表性城市,通过数据挖掘技术构建分析与预测体系,填补市场洞察的精准度缺口。
项目目标
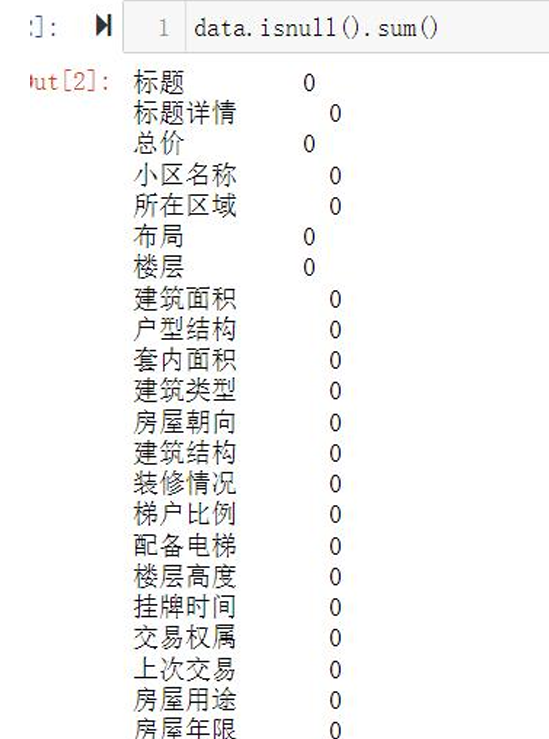
- 数据爬取:通过Python requests库获取链家平台二手房核心字段,包括房源位置、面积、户型、总价、单价等关键信息。
- 数据清洗:完成去重、缺失值填充、异常值处理、数据类型转换等预处理,保障数据质量。
- 数据可视化:通过直方图、词云图、地理分布图等工具,直观呈现市场分布与价格特征。
- 特征工程:筛选并编码对房价有显著影响的特征,构建高效建模数据集。
- 模型训练:基于DT、GBT、RF三种算法构建价格预测模型,评估不同因素对房价的影响。
- 模型优化:通过异常值剔除与网格搜索调整参数,提升模型预测精度。
- 技术实现:依托Python生态,结合pandas、numpy、matplotlib等库完成全流程开发。
数据采集与预处理
数据采集
本次数据来源于链家网二手房板块,通过分析网页URL规律,设计了分城市、分区的爬虫方案。先爬取目标城市各区域的URL,再按分页规则遍历每一页房源,最后下载单套房源的HTML文件并提取信息。
核心爬虫代码(修改后关键片段):
-
import requests
-
import os
-
from lxml import etree
-
import pandas as pd
-
# 定义爬取函数:参数为城市URL和城市名称
-
def crawl_city_houses(city_url, city_name):
-
# 创建城市对应的存储文件夹
-
city_dir = f'htmls/{city_name}'
-
if not os.path.exists(city_dir):
-
os.makedirs(city_dir)
-
# 请求城市首页,获取各区链接
-
response = requests.get(city_url, headers=headers)
-
html = etree.HTML(response.text)
-
area_urls = html.xpath('//div[@data-role="ershoufang"]//a/@href')
-
area_names = html.xpath('//div[@data-role="ershoufang"]//a/text()')
-
# 遍历各区,爬取分页数据
-
for area_url, area_name in zip(area_urls, area_names):
-
area_dir = f'{city_dir}/{area_name}'
-
if not os.path.exists(area_dir):
-
os.makedirs(area_dir)
爬取流程与代码示意:
信息提取代码示意: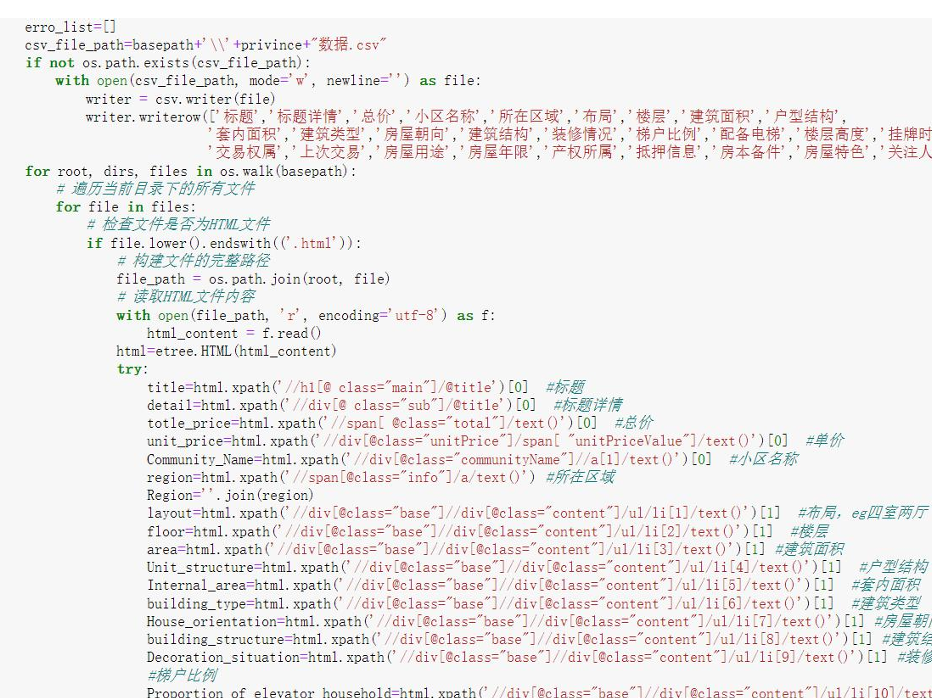
数据清洗
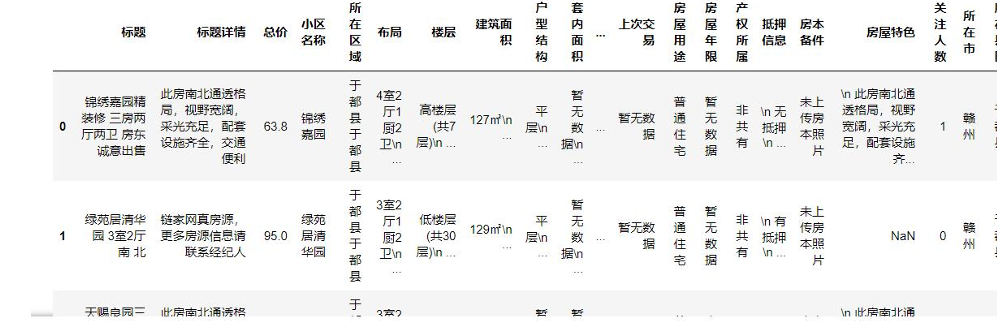
三个城市的原始数据采用相同提取逻辑,因此清洗流程保持一致,以下以赣州数据为例说明核心步骤:
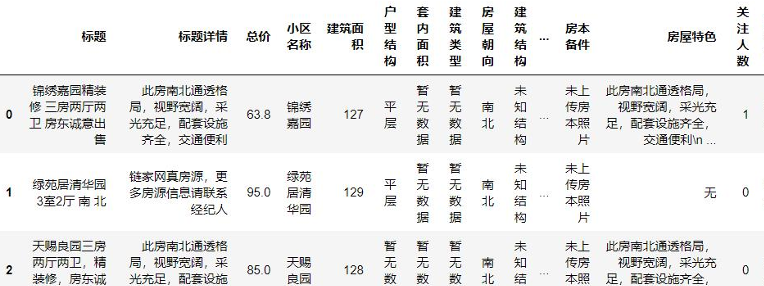
- 读取数据并查看基础信息:
![]()
![]()
- 缺失值处理:房屋特色等描述型字段用“无”填充,数值型字段根据分布特征填充均值或中位数。
![]()
- 数据格式优化:去除字符型数据中的空格与换行符,删除冗余字段(如“所在区域”因已有“所在市”“所在县区”可剔除)。
![]()
- 特征拆分与提取:

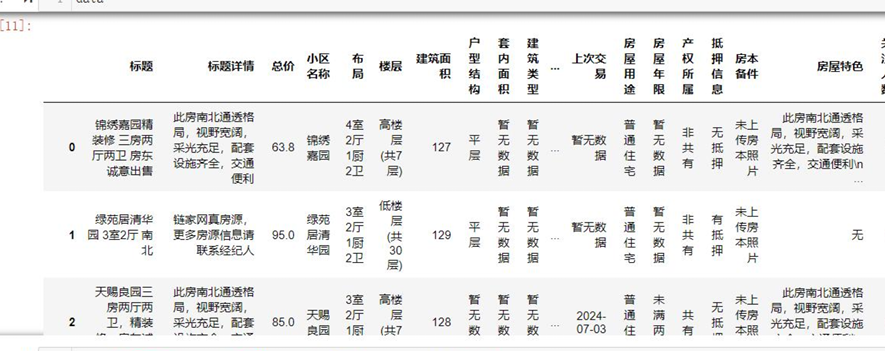
- 从“面积”字段中提取数字,转换为浮点型用于建模。
![]()
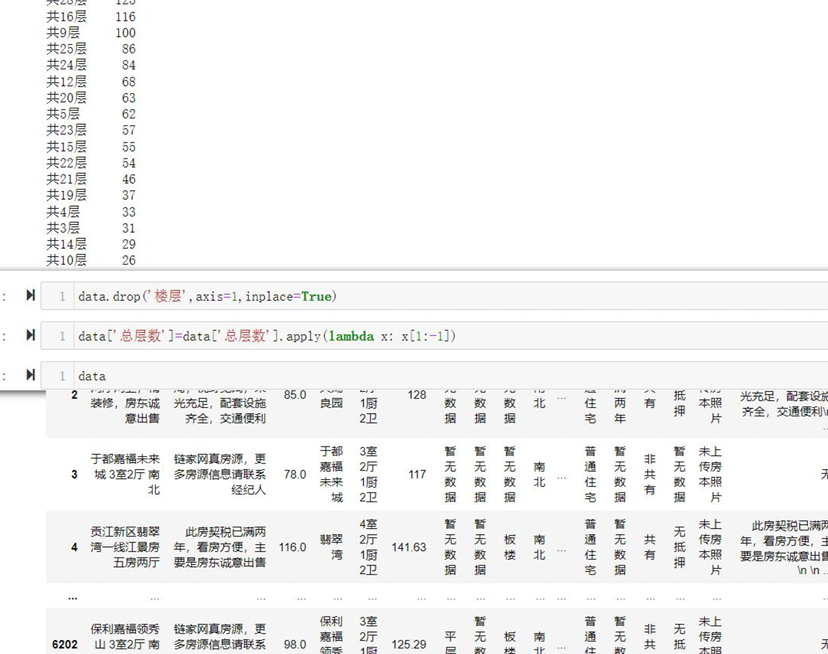
- 将“楼层”字段拆分为“楼层高度”(低/中/高)和“总层数”两个独立特征。
![]()
- 从“户型”字段中提取“室、厅、厨、卫”的数量,转换为整型特征。
![]()
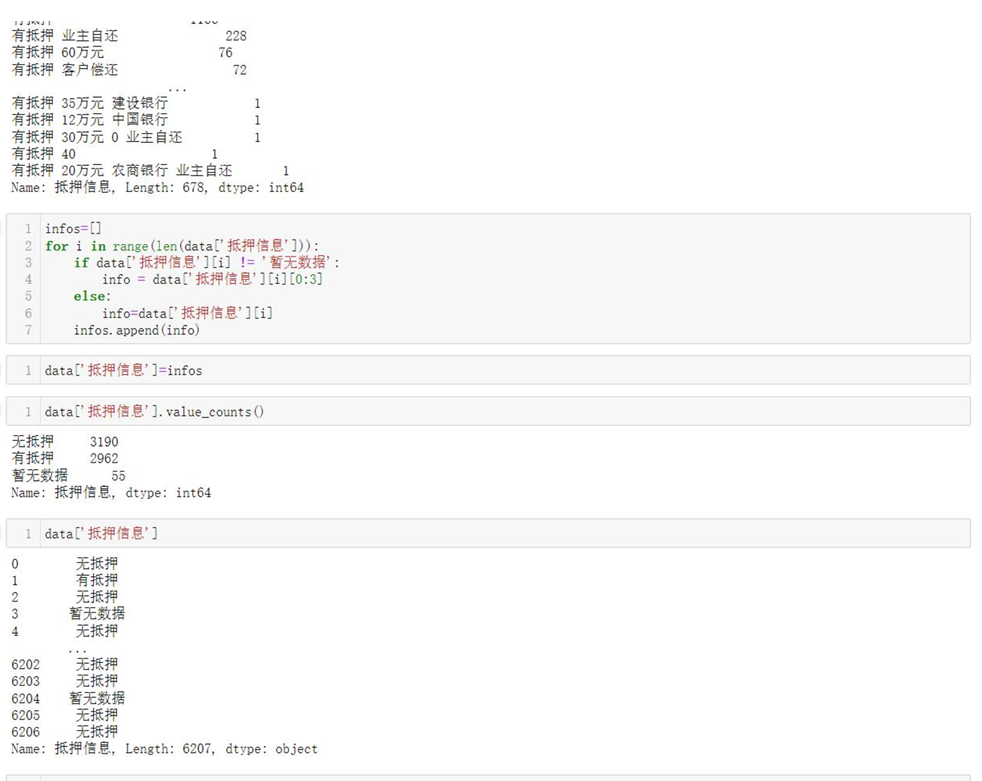
- 简化“抵押信息”字段,归类为“有抵押、无抵押、暂无数据”三类。
![]()
探索式数据分析
通过可视化工具从区域分布、价格特征、房源属性等维度解析数据,以下为三个城市的核心分析结果:
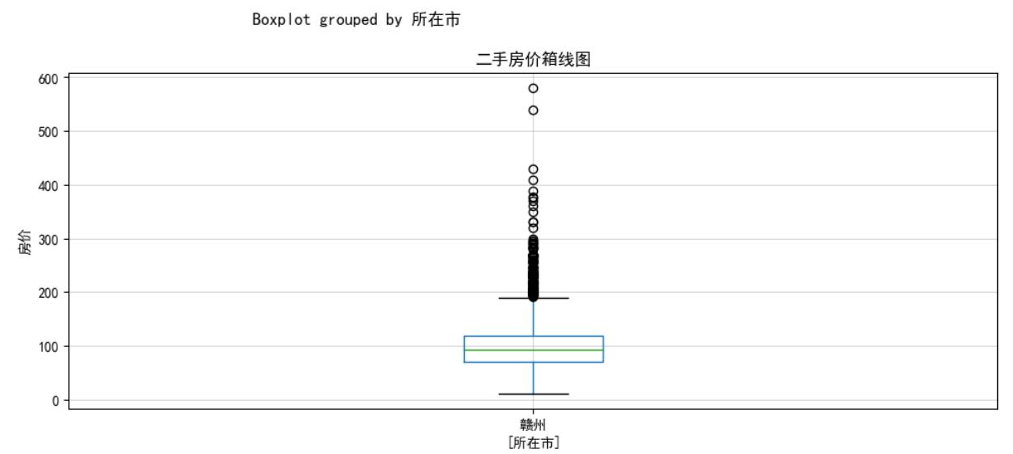
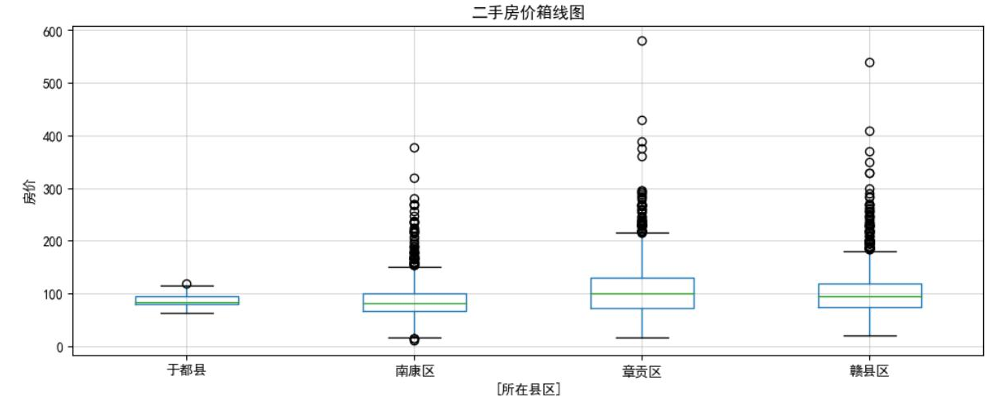
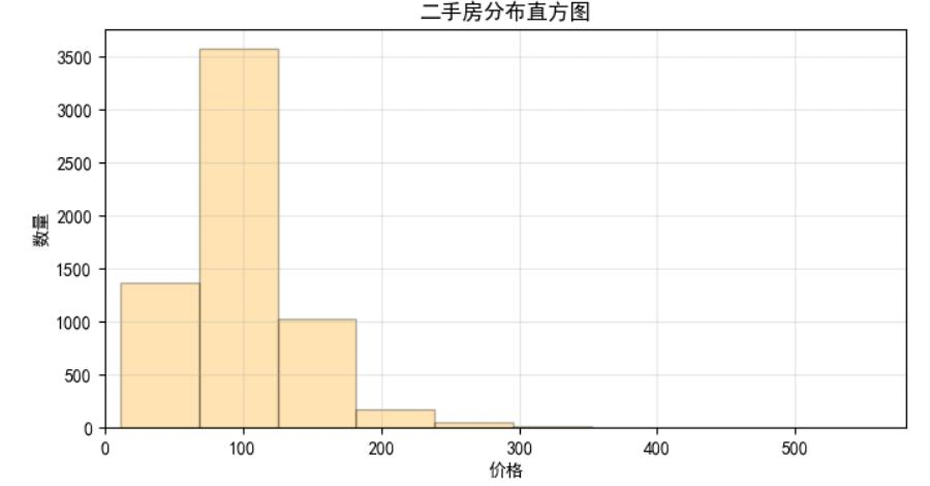
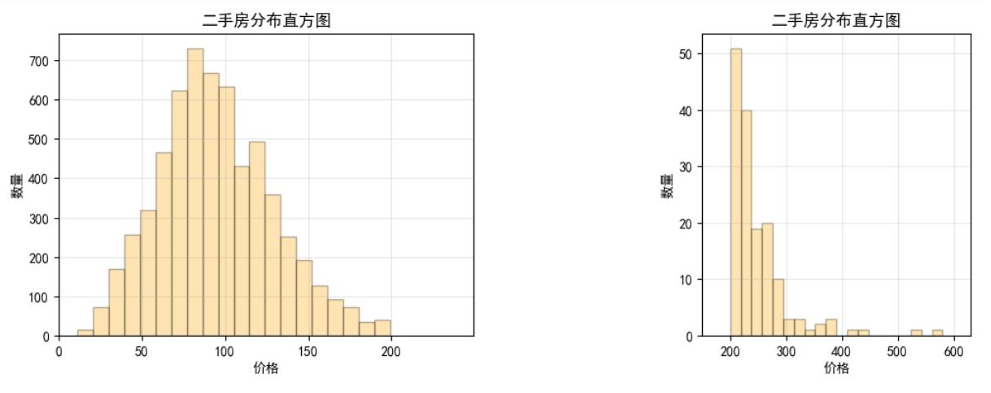
赣州数据可视化
- 各县区房源数量分布:直观呈现不同区域的房源流通活跃度。
![]()
- 房源相关特征分布:展示房屋属性的整体特征,为后续特征筛选提供依据。
![]()
![]()
![]()
- 房价分布直方图:因高价房源占比极低,分高低价(以1000万为界)分别展示,更清晰呈现价格集中区间。
![]()
![]()
- 房源标题词云图:提炼市场热门宣传关键词,反映购房者关注焦点,词云图生成代码如下。
![]()
![]()
![]()




相关文章

Python电影票房预测模型研究——贝叶斯岭回归Ridge、决策树、Adaboost、KNN分析猫眼豆瓣数据
原文链接:https://tecdat.cn/?p=43754
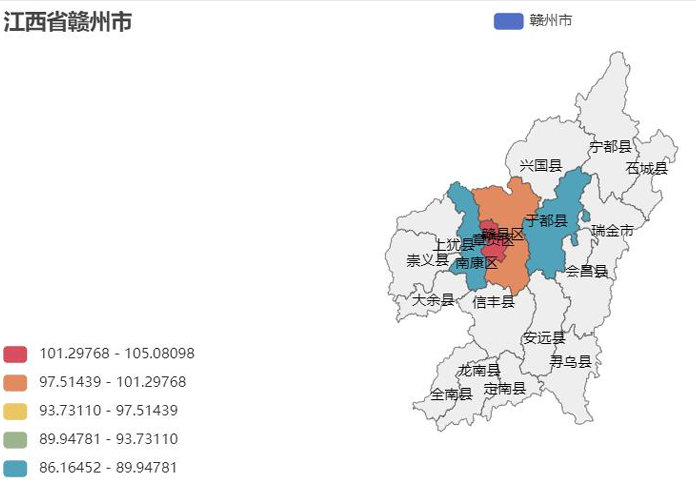
- 各县区平均房价地理图:可视化区域价格差异,直观展示核心城区与郊区的房价梯度。
![]()
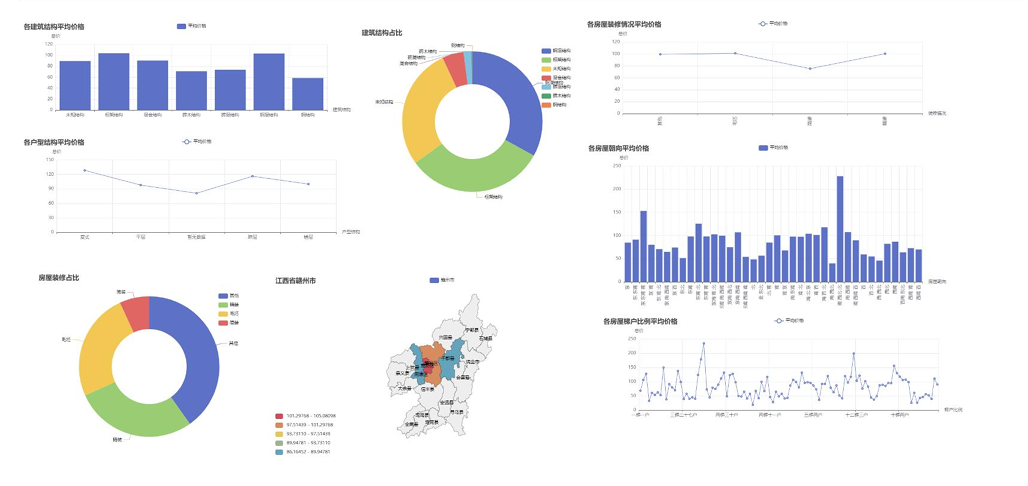
- 数据可视化大屏:整合核心指标(房源数量、均价、户型分布等),全方位展示市场概况。
![]()
南昌数据可视化
南昌市可视化分析逻辑与赣州一致,仅因城市数据差异呈现不同特征,核心可视化结果如下: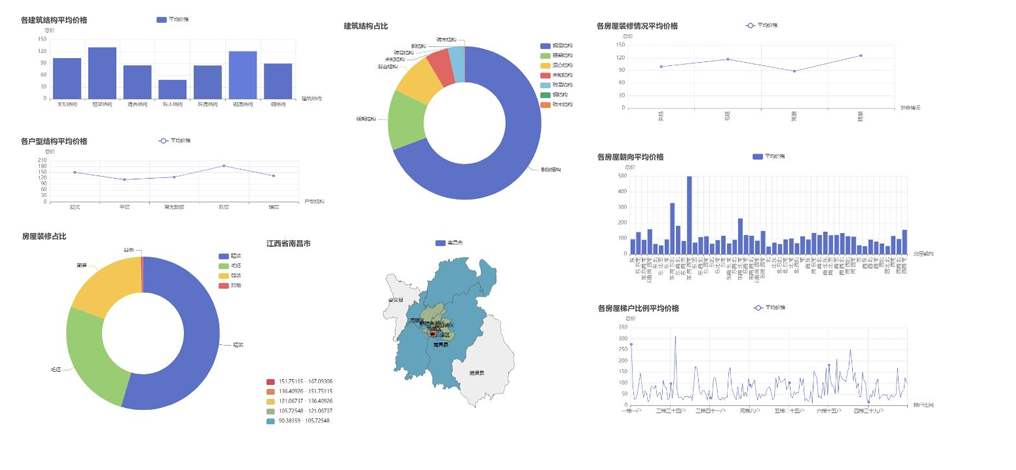
深圳数据可视化
深圳作为一线城市,房价水平与区域差异显著,核心可视化结果如下: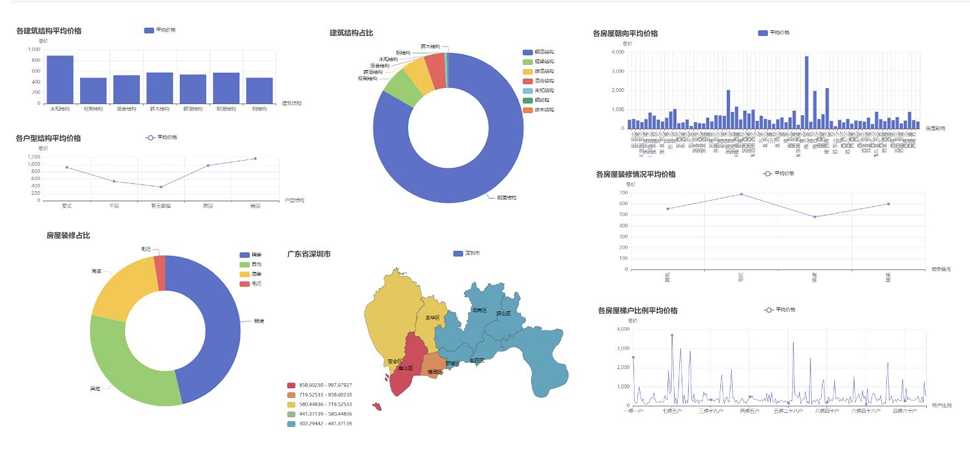
通过跨城市对比发现:深圳二手房价格显著高于赣州、南昌,且异常值较多;赣州、南昌的房价分布更集中,区域差异主要受核心城区与郊区地理位置影响;三地房源均以刚需户型为主,装修情况以简装、中装为主流。
模型设计与优化
数据合并与特征处理
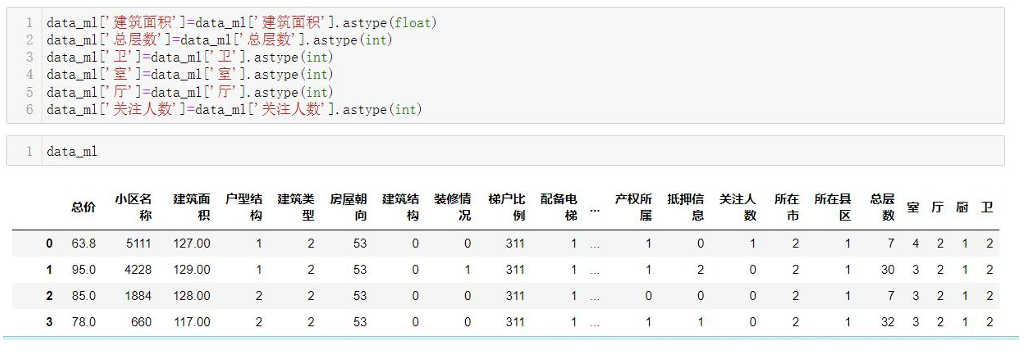
- 数据集合并:将三个城市的清洗后数据纵向拼接,最终得到42640条记录、31个特征的建模数据集,合并过程代码与结果如下。
![]()
核心合并代码(修改后关键片段):
-
import pandas as pd
-
# 读取三个城市的清洗后数据
-
ganzhou_data = pd.read_csv('清洗后数据/赣州_清洗后.csv', index_col=False)
-
nanchang_data = pd.read_csv('清洗后数据/南昌_清洗后.csv')
-
shenzhen_data = pd.read_csv('清洗后数据/深圳_清洗后.csv')
-
# 纵向合并数据
-
combined_data = pd.concat([ganzhou_data, nanchang_data, shenzhen_data], axis=0)
-
# 去重并重置索引
-
combined_data.drop_duplicates(inplace=True)
-
combined_data = combined_data.reset_index(drop=True)
-
# 保存合并后数据
-
combined_data.to_csv('./合并后数据集.csv', index=False)
- 异常值检测:通过箱线图发现深圳存在较多高价异常值,这些异常值会干扰模型训练,导致预测偏差。
![]()
- 合并后数据分布:查看合并数据的直方图,因价格跨度极大,分高低价展示分布特征,为异常值处理提供依据。
- 特征筛选与编码:
- 剔除标题、挂牌时间等难以量化或相关性低的特征,保留核心特征用于建模。
- 对分类特征(如户型结构、装修情况等)采用LabelEncoder编码,编码代码如下。
![]()
核心编码代码(修改后关键片段):
-
from sklearn.preprocessing import LabelEncoder
-
import joblib
-
# 筛选建模特征
-
model_data = combined_data.drop(['标题', '标题详情', '套内面积', ...], axis=1)
-
# 定义需要编码的分类特征
-
cat_features = ['小区名称', '户型结构', '建筑类型', ..., '所在县区']
-
label_encoders = {}
-
# 对分类特征进行编码
-
for feat in cat_features:
-
le = LabelEncoder()
-
model_data[feat] = le.fit_transform(model_data[feat])
-
label_encoders[feat] = le
-
# 保存编码器
-
joblib.dump(label_encoders, '模型/label_encoders.pkl')
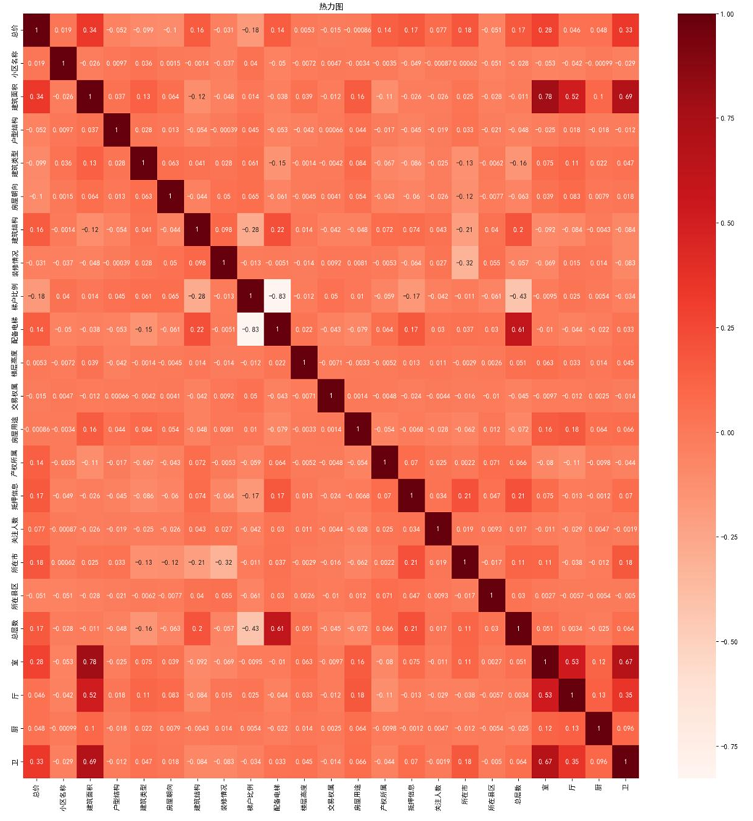
- 特征相关性分析:通过热力图筛选与“总价”相关性较高的特征,剔除小区名称、关注人数等相关性较低的特征,优化建模特征集。
![]()
模型训练(未处理异常值)
采用8:2比例划分训练集与测试集,分别训练决策树(DT)、梯度提升树(GBT)、随机森林(RF)三种模型,使用R²、MSE、RMSE作为评估指标。
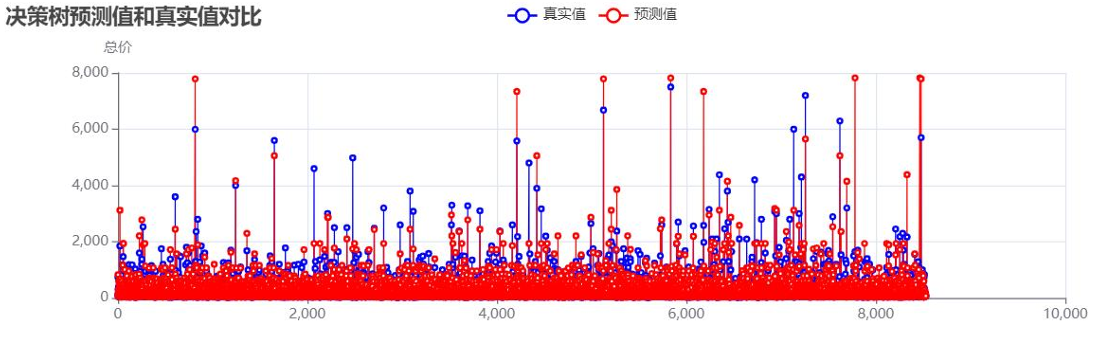
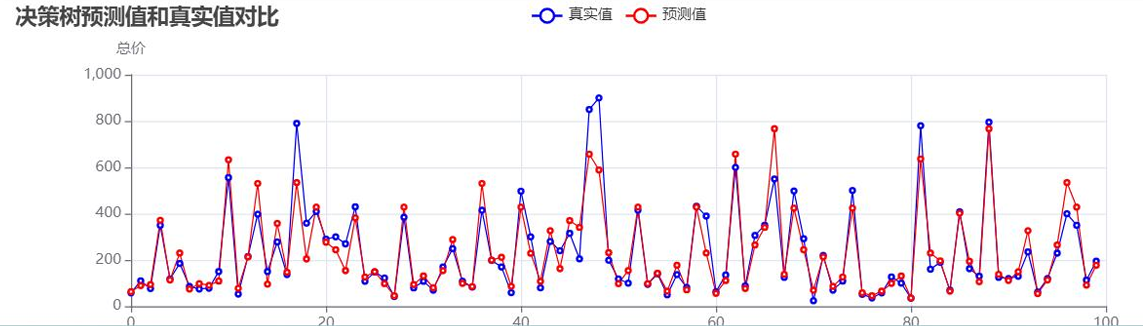
- 决策树模型:
决策树预测值与真实值对比:![]()
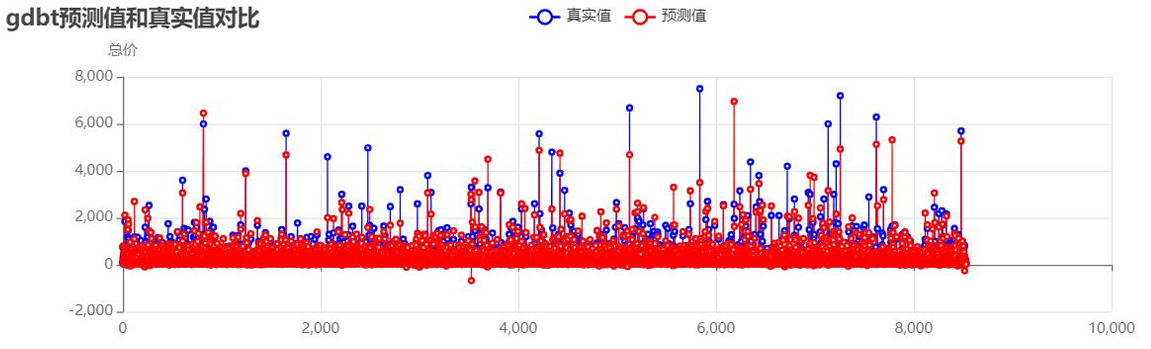
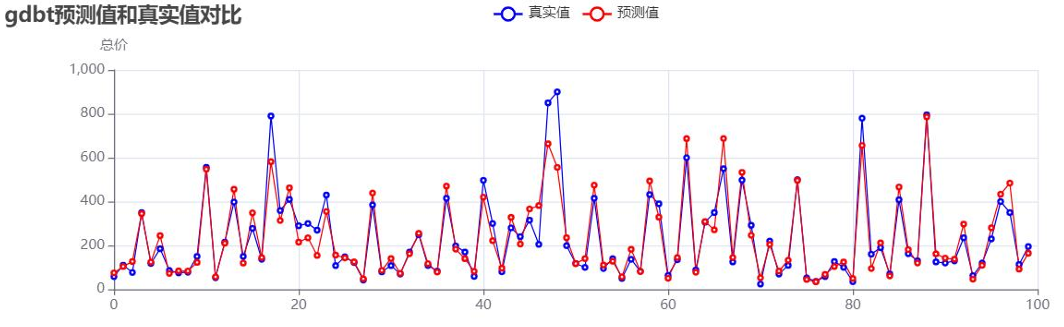
- 梯度提升树模型:
梯度提升树预测值与真实值对比:![]()
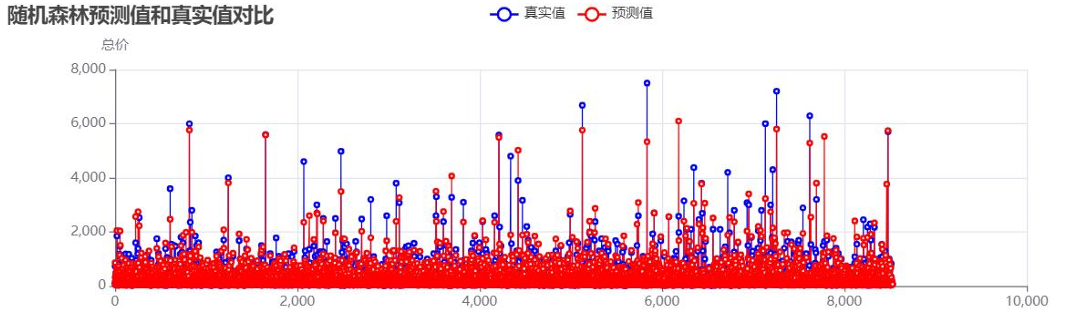
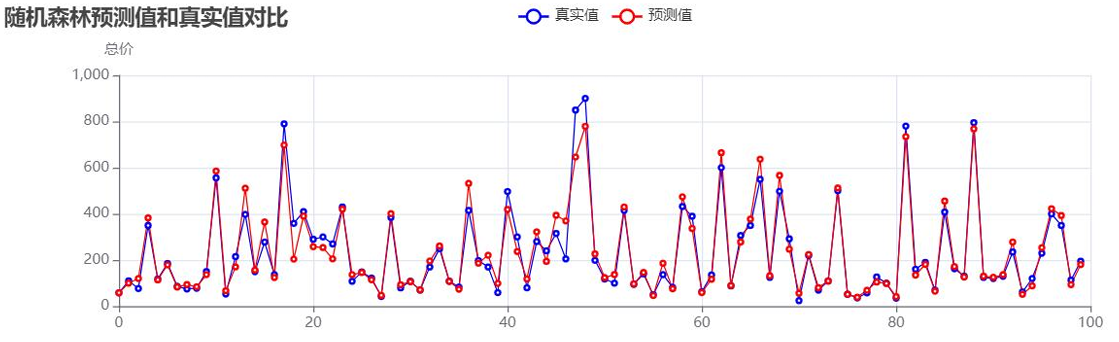
- 随机森林模型:
随机森林预测值与真实值对比:![]()
未处理异常值时的模型性能: - 分析可见:未处理异常值时,模型R²值偏低,高价房源的预测偏差尤为明显,需通过异常值处理与参数优化提升性能。
模型优化
- 异常值处理:采用IQR法则,剔除总价高于Q3+3IQR的异常数据(主要为深圳高价房源),处理代码如下。
核心处理代码(修改后关键片段):
-
# 计算四分位数
-
Q1 = model_data['总价'].quantile(0.25)
-
Q3 = model_data['总价'].quantile(0.75)
-
IQR = Q3 - Q1
-
# 定义异常值边界
-
upper_bound = Q3 + 3 * IQR
-
# 剔除异常值
-
optimized_data = model_data[model_data['总价'] <= upper_bound]
-
optimized_data.to_csv('./训练数据.csv', index=False)
- 参数优化:使用网格搜索(GridSearchCV)为各模型寻找最优参数,提升模型泛化能力。
- 决策树网格搜索:
决策树预测值与真实值对比(优化后):![]()
- 梯度提升树优化:
梯度提升树预测值与真实值对比(优化后):![]()
- 随机森林网格搜索:
随机森林预测值与真实值对比(优化后):![]()
- 优化后模型性能:
结果表明:剔除异常值并优化参数后,三种模型的预测精度显著提升,其中随机森林模型表现最佳,R²达到0.911,预测值与真实值拟合度良好,能有效捕捉二手房价格的核心影响因素。
模型 R² MSE RMSE 决策树 0.871 4220.42 64.96 梯度提升树 0.895 3422.84 58.50 随机森林 0.911 2928.50 54.16
结论与服务支持
本次研究通过完整的数据挖掘流程,实现了多城市二手房价格预测与区域差异分析,验证了决策树、梯度提升树、随机森林在房价预测场景的有效性。核心结论包括:地理位置(所在城市、县区)、建筑面积、户型结构是影响二手房价格的关键因素;深圳房价整体偏高且波动较大,赣州、南昌房价分布更集中;随机森林模型经异常值处理与参数优化后,预测精度最优,可为市场参与者提供可靠参考。
核心服务保障
- 应急修复服务:24小时响应“代码运行异常”求助,比学生自行调试效率提升40%,避免因代码问题耽误项目进度。
- 人工创作保障:所有代码与论文内容均经人工优化,直击“代码能运行但怕查重、怕漏洞”的痛点,保障原创性与可靠性。
- 全流程支持:提供从数据爬取到模型落地的全流程答疑,不仅教会“怎么做”,更解释“为什么这么做”,帮助真正掌握数据分析思维。
本文项目完整代码、数据及可视化素材已同步至交流社群,进群即可获取。如需个性化修改、代码调试或润色服务,可联系团队获取一对一支持,让数据分析学习更高效、更省心。
关于分析师
![]()
在此对 Liping Xiao 对本文所作的贡献表示诚挚感谢,其专业方向为数据科学与大数据技术,曾担任北京中电中采数据服务有限公司的数据处理。擅长 Python 编程,在深度学习、数据分析、数据采集等领域具备专业的实践能力与技术储备。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号