


Python基于ARIMA-LSTM模型的广州市新能源汽车销量预测
全文链接:https://tecdat.cn/?p=43689
原文出处:拓端数据部落公众号
分析师:Bingyi Yan

做新能源汽车市场分析时,你是不是也遇到过这样的问题:用ARIMA预测总抓不住销量的突发波动,换LSTM又容易忽略长期增长趋势?单一模型总在“线性”和“非线性”之间顾此失彼。
但我们最近在广州市新能源汽车销量预测的项目里,把ARIMA和LSTM捏到了一起,结果让人惊喜——预测误差直接从18%砍到了10%!今天就拆解这个组合模型的底层逻辑,原文链接附代码和数据细节。
先说说:为啥单一模型不够用?
新能源汽车销量这东西,太“调皮”了。既有政策推动下的稳步增长(线性趋势),又受充电桩建设速度、市场关注度这些因素的突发影响(非线性波动)。
- 纯ARIMA:像个“老学究”,擅长抓整体增长趋势,但对充电桩突然变多、百度指数猛涨这些“意外”反应慢,预测误差18.35%;
- 纯LSTM:像个“机灵鬼”,能捕捉非线性关系,但容易“忘本”,单独用百度指数时误差16.01%,加了充电桩数据降到14.06%,可还是不如组合起来强。
所以我们想:能不能让“老学究”稳住基本盘,“机灵鬼”搞定突发状况?
组合模型的底层逻辑:1+1>2
ARIMA和LSTM的融合,不是简单拼接,而是“各司其职”:
- ARIMA先上:处理销量数据的线性趋势,算出预测值后,把“没抓到的部分”(残差)甩给LSTM;
- LSTM接棒:拿着残差,再结合充电桩数量、百度指数这些“辅助信息”,把非线性波动补全。
就像先画一条平滑的增长线,再用细节把折线的起伏填进去,最后误差降到10.01%也就不奇怪了。
手把手拆代码:从数据到预测的关键步骤
数据准备:哪些因素真的有用?

我们扒了4类数据(2017.6-2024.2):
- 广州市新能源汽车销量(乘联会)
- 广东省公共充电桩数量(充电联盟)
- 广东省新能源汽车百度指数(百度指数)
- 广东省油价(东方财富网)
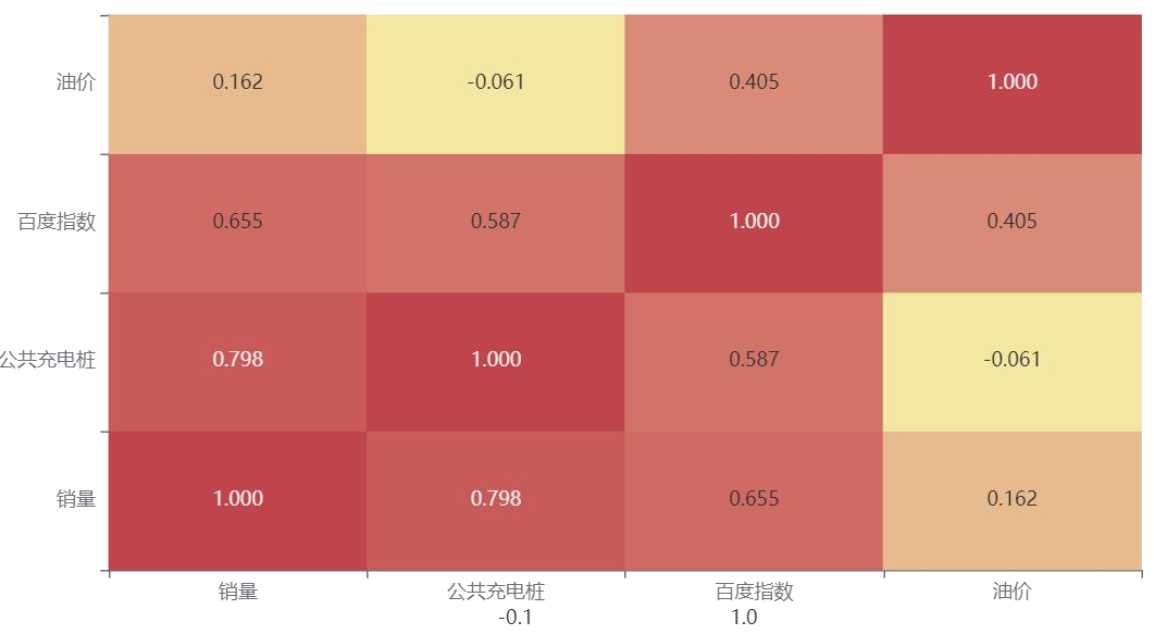
用Spearman相关性分析筛了下: - 充电桩和销量相关系数0.798(高度正相关)
- 百度指数0.655(较强正相关)
- 油价才0.162(几乎没关系)
果断留前两个当“辅助变量”。![]()
相关文章
金融科技中的量化投资:LSTM、Wavenet与LightGBM的融合策略
原文链接:https://tecdat.cn/?p=37184
分析LSTM、Wavenet和LightGBM在金融时序预测中的优劣,提出动态融合框架以捕捉市场非线性特征,应用于股票收益率预测
搭ARIMA模型:先搞定线性趋势
ARIMA的核心是让数据“变稳”,我们用ADF检验测了下:
- 原始销量数据:p=0.967(不稳)
- 二阶差分后:p<0.001(稳了!)
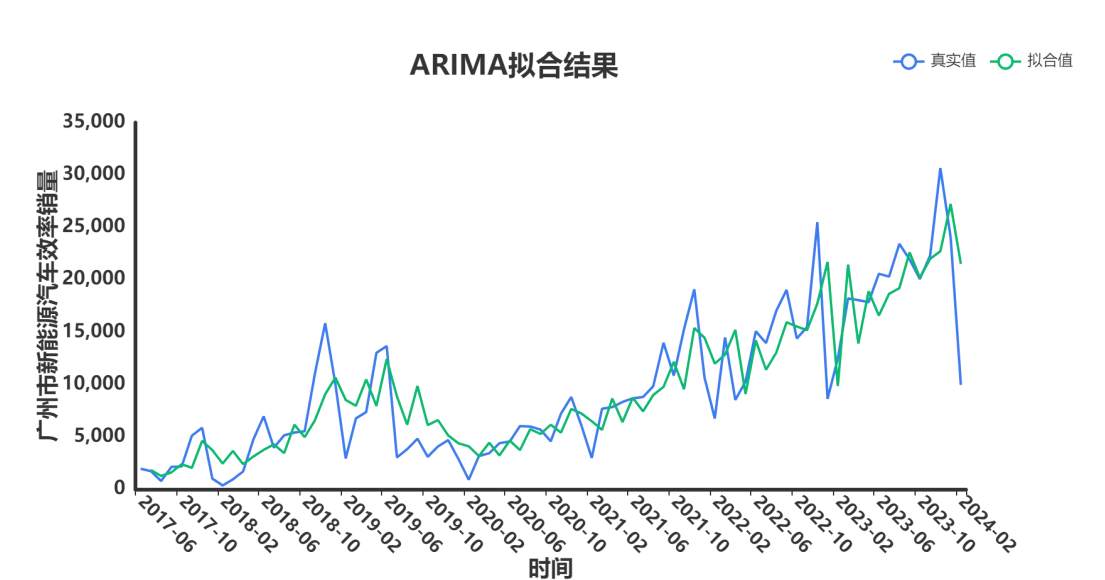
最后选了ARIMA(4,1,0),拟合效果如下:
-
# 关键代码片段
-
from statsmodels.tsa.arima.model import ARIMA
-
# 读数据
-
sales_data = pd.read_csv('guangzhou_ev_sales.csv', parse_dates=['date'], index_col='date')
-
# 二阶差分让数据平稳
-
sales_diff2 = sales_data['sales'].diff(2).dropna()
-
# 建模型
-
model_arima = ARIMA(sales_data['sales'], order=(4, 1, 0))
-
result_arima = model_arima.fit()
搭LSTM模型:抓非线性波动
LSTM的“记忆功能”适合处理复杂波动,我们用过去6个月的数据(销量+充电桩+百度指数)预测下个月:
-
from tensorflow.keras.models import Sequential
-
from tensorflow.keras.layers import LSTM, Dense, Dropout
-
# 数据标准化
-
scaler = MinMaxScaler(feature_range=(0, 1))
-
scaled_data = scaler.fit_transform(sales_data[['sales', 'charging_piles', 'baidu_index']])
-
# 建模型
-
model_lstm = Sequential()
-
model_lstm.add(LSTM(64, return_sequences=True, input_shape=(6, 3))) # 6个月数据,3个特征
-
model_lstm.add(LSTM(10, return_sequences=False))
-
model_lstm.add(Dropout(0.2)) # 防过拟合
-
model_lstm.add(Dense(1))
单加百度指数时误差16.01%,单加充电桩14.88%,两个一起加降到14.06%,果然“人多力量大”。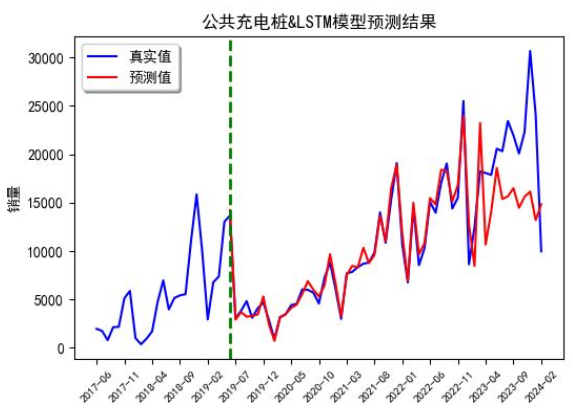
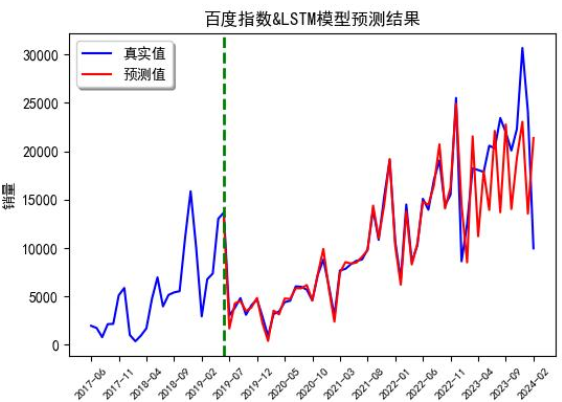
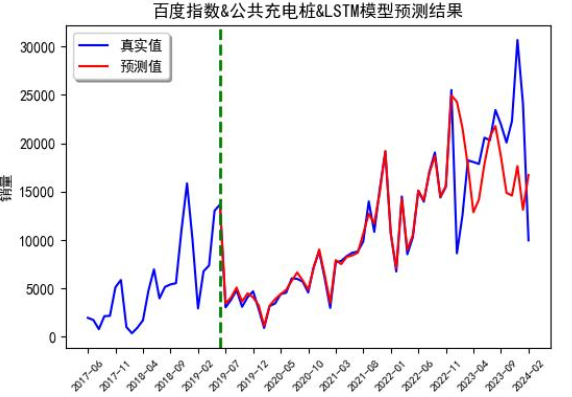
组合模型:ARIMA+LSTM的“王炸”效果
把ARIMA的残差(没抓到的部分)喂给LSTM,相当于“查漏补缺”:
-
# 取ARIMA残差,和其他特征合并
-
arima_residuals = result_arima.resid.values.reshape(-1, 1)
-
combined_features = np.concatenate((scaled_data, arima_residuals), axis=1)
-
# 用新特征训练组合模型
-
model_combined = Sequential()
-
# 结构类似LSTM,输入特征多了1个(残差)
-
model_combined.add(LSTM(64, return_sequences=True, input_shape=(6, 4)))
-
...
结果误差直接干到10.01%!对比图一目了然: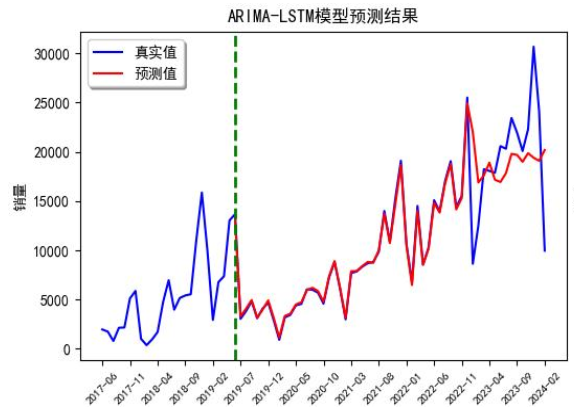
各模型MAPE对比: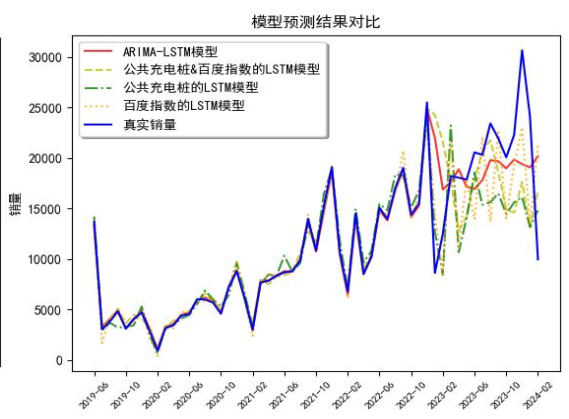
我们还测了下稳健性,Dropout在0.1-0.3之间变,误差波动不到3%,模型够稳。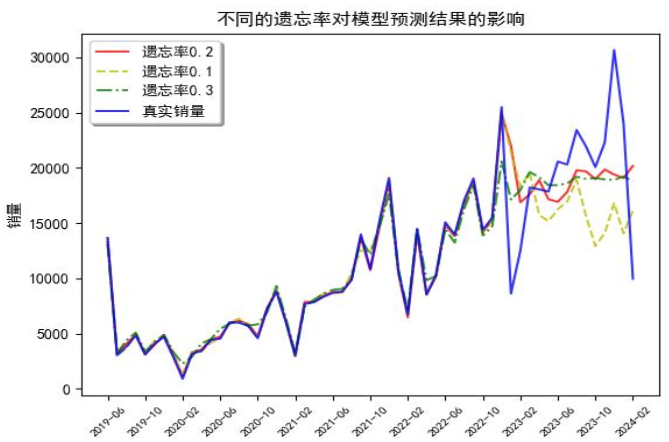
给广州新能源汽车市场的落地建议
从模型结果看,充电桩和市场关注度(百度指数)对销量影响真不小,咱们可以这么干:
- 充电桩赶紧建:居民区、商场多摆点,数据显示这是最直接的“销量助推器”;
- 推广要盯百度指数:搞活动后指数涨了,说明效果到位了;
- 政策得稳:别忽冷忽热,长期支持才能让市场有信心。
下次可以试试加政策文件、电池技术突破这些因素,说不定误差还能降。
(完整代码和数据已放社群,进群领走直接跑~)
关于分析师

在此对 Bingyi Yan 对本文所作的贡献表示诚挚感谢,她在广州大学完成了软件工程专业的学习,现任中国电信广州分公司数据分析师。擅长 Python、深度学习、数学建模、数据处理等。Bingyi Yan 在数据处理与分析领域拥有扎实的专业知识,尤其在结合深度学习技术解决实际业务问题方面具备丰富经验,能够通过数学建模和数据挖掘为行业分析提供科学支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号