


Python用KShape对时间序列进行聚类和肘方法确定最优聚类数k可视化
原文链接:http://tecdat.cn/?p=27078
原文出处:拓端数据部落公众号
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
,时长06:05
时序数据的聚类方法
该算法按照以下流程执行。
- 使用基于互相关测量的距离标度(基于形状的距离:SBD)
- 根据 1 计算时间序列聚类的质心。(一种新的基于质心的聚类算法,可保留时间序列的形状)
- 划分成每个簇的方法和一般的kmeans一样,但是在计算距离尺度和重心的时候使用上面的1和2。
import pandas as pd

-
# 读取数据帧,将其转化为时间序列数组,并将其存储在一个列表中
-
tata = []
-
for i, df in enmee(dfs):
-
-
# 检查每个时间序列数据的最大长度。
-
for ts in tsda:
-
if len(s) > ln_a:
-
lenmx = len(ts)
-
-
# 给出最后一个数据,以调整时间序列数据的长度
-
for i, ts in enumerate(tsdata):
-
dta[i] = ts + [ts[-1]] * n_dd
-
-
-
-
# 转换为矢量
-
stack_list = []
-
for j in range(len(timeseries_dataset)):
-
-
stack_list.append(data)
-
-
# 转换为一维数组
-
trasfome_daa = np.stack(ack_ist, axis=0)
-
return trafoed_data
数据集准备
-
# 文件列表
-
flnes= soted(go.ob('mpldat/smeda*.csv'))
-
# 从文件中加载数据帧并将其存储在一个列表中。
-
for ienme in fiemes:
-
df = pd.read_csv(filnme, indx_cl=one,hadr=0)
-
flt.append(df)
聚类结果的可视化
-
# 为了计算交叉关系,需要对它们进行归一化处理。
-
# TimeSeriesScalerMeanVariance将是对数据进行规范化的类。
-
sac_da = TimeeiesalerMVarne(mu=0.0, std=1.0).fit_trnform(tranfome_data)
-
-
# KShape类的实例化。
-
ks = KShpe(_clusrs=2, n_nit=10, vrboe=True, rano_stte=sed)
-
yprd = ks.ft_reitsak_ata)
-
# 聚类和可视化
-
-
plt.tight_layout()
-
plt.show()
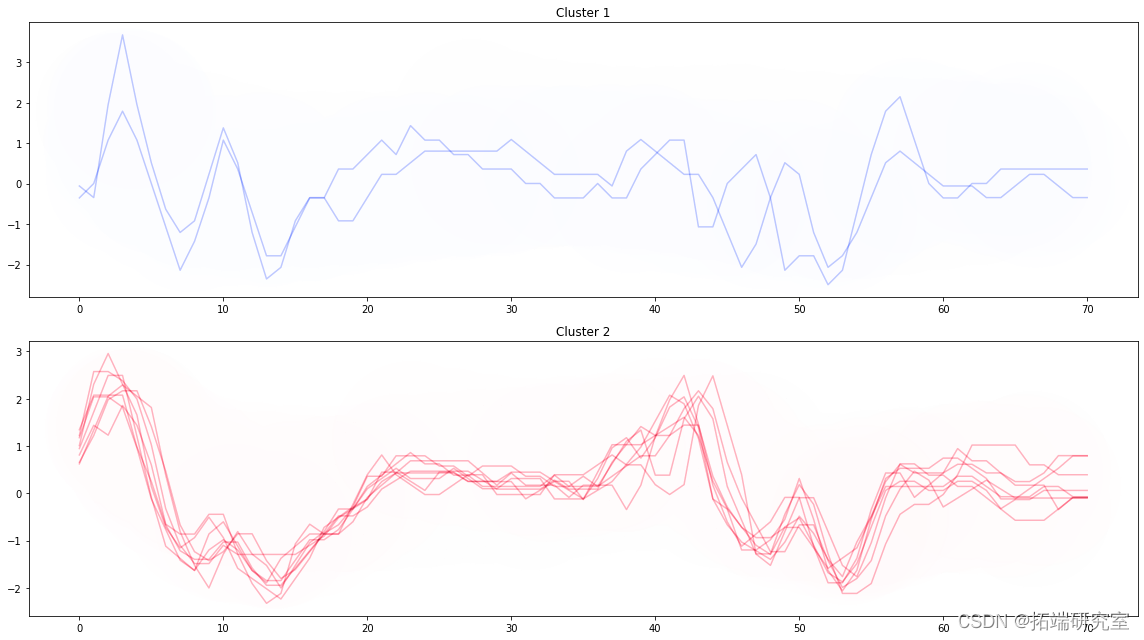
用肘法计算簇数
-
什么是肘法...
- 计算从每个点到簇中心的距离的平方和,指定为簇内误差平方和 (SSE)。
- 它是一种更改簇数,绘制每个 SSE 值,并将像“肘”一样弯曲的点设置为最佳簇数的方法。
-
-
#计算到1~10个群组
-
for i in range(1,11):
-
#进行聚类计算。
-
ks.fit(sacdta)
-
#KS.fit给出KS.inrta_
-
disorons.append(ks.netia_)
-
-
plt.plot(range(1,11), disorins, marker='o')



最受欢迎的见解
3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
5.Python Monte Carlo K-Means聚类实战
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号