


Python用Apriori 算法关联规则分析亚马逊购买书籍关联推荐客户和网络图可视化
原文链接:http://tecdat.cn/?p=26999
原文出处:拓端数据部落公众号
Apriori 算法是一个相当新的算法,由 Agrawal 和 Srikant 于 1994 年提出。它是一种用于频繁项集挖掘的算法,允许公司理解和组织向上销售和交叉销售活动。
视频:R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
关联规则模型、Apriori算法及R语言挖掘杂货店交易数据与交互可视化
,时长07:03
最强大的应用程序之一是我们在亚马逊上在线购物时看到的推荐系统 - 以及当今几乎所有电子商务网站上都存在的各种其他版本。
这是为了帮助理解一个非常简单的数据集,其中包含单个国际标准书号 (ISBN),它是一本书的唯一国际出版商标识符号。每行代表购买了所列书籍的唯一客户。
目标是了解基本购买行为,向客户推荐的其他书籍是什么——这样它可以提高公司的收入以及对所提供服务的整体满意度。
我们以网络图结束,该图展示了置信度高于 55% 的关系。
设置和导入数据集
-
import numpy as np
-
import pandas as pd
-
-
data.head()
data.shape ![]()
数据集上的EDA
-
#执行堆叠的步骤,转换为字符串,包括删除索引
-
dt2 = pd.DataFrame
-
dt2 = dt2.reset_index(drop = True)

dt2.nunique() # 总共有4,999本独特的书籍
![]()
-
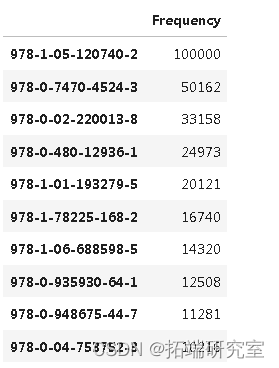
#数据集中购买最多的前10本书
-
top0 = pd.DataFrame(dt2.value_counts(sort= True, ascending=False).head(10))
-
to10
-
-
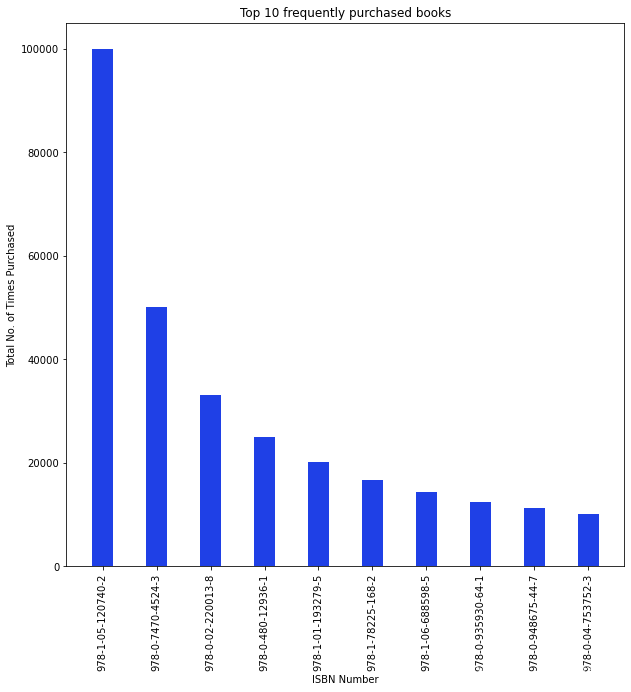
# 创建条形图
-
plt.bar(t0.index, top_10['Frequency'])
预处理
-
-
-
tdf = t.fit(d2).transform(da2)

-
-
ted = t.fit(r).transform(tr)
-
t_f

-
tdf = df.astype("int")
-
-
t_f

-
-
oks = d.DataFrame(tf, columns=e.columns_)
-
bos.head()
建立Apriori模型
-
-
runets = apriori(o2, min_support=0.01, use_colnames=True)
feqts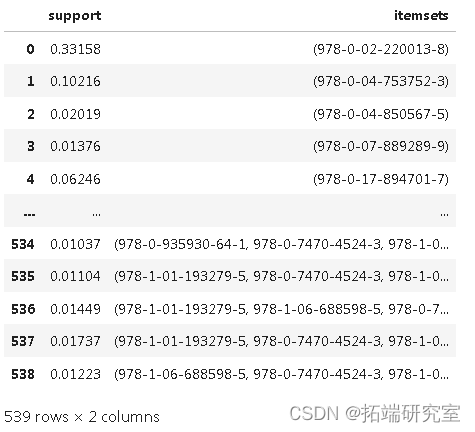
fetes.sort_values( by = ['support'] ,ascending = False)
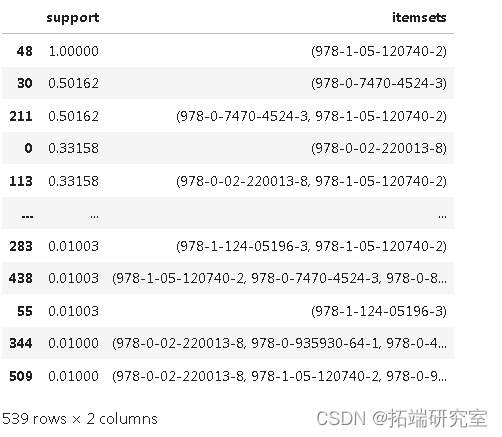
-
-
rls = assoc(fret, metric = "lift", min_threshold = 1)

-
re.solues('confidence', ascending = False)
-
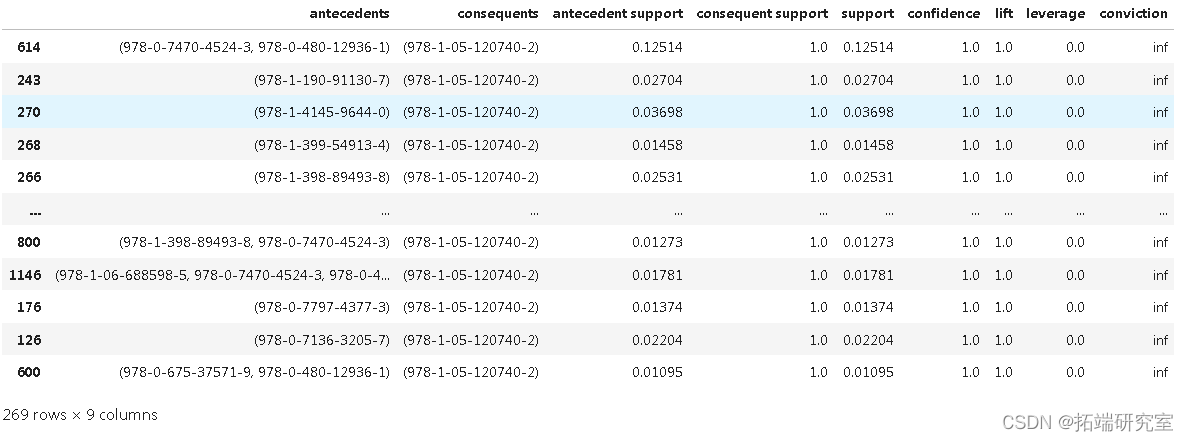
ruls.head()

-
rul = rls[res['confidence'] >= 0.55]
-
rue
结论网络图
-
fig, ax = plt.subplots(figsize = (10,6))
-
G = x.from_pandas_edgelist(ul,source = 'antecedents')
-
n.draw(A)


最受欢迎的见解
1.采用spss-modeler的web复杂网络对所有腧穴进行分析
3.R语言文本挖掘NASA数据网络分析,tf-idf和主题建模
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号