


R语言逻辑回归Logisitc逐步回归训练与验证样本估计分析心脏病数据参数可视化
原文链接:http://tecdat.cn/?p=26932
原文出处:拓端数据部落公众号
在进行交叉验证之前,很自然地说“我会预烧 50%(比如说)我的数据来训练一个模型,然后用剩下的来拟合模型”。例如,我们可以使用训练数据进行变量选择(例如,在逻辑回归中使用一些逐步过程),然后,一旦选择了变量,就将模型拟合到剩余的观察集上。一个自然的问题通常是“这真的重要吗?”。
为了可视化这个问题,考虑我的(简单)数据集
使用心脏病数据,预测急诊病人的心肌梗死,包含变量:
- 心脏指数
- 心搏量指数
- 舒张压
- 肺动脉压
- 心室压力
- 肺阻力
- 是否存活
让我们生成 100 个训练样本(我们保留大约 50% 的观察值)。在它们中的每一个上,我们使用逐步过程,并保留剩余变量的估计值(以及它们的标准差)
-
M=matrix(NA,100,ncol(MODE))
-
for(i in 1:100){
-
reg=step(glm(PRO=="CS"~.,dataYE[idx,]))
-
然后,对于 7 个协变量(和常数),我们可以查看拟合在训练样本上的模型中的系数值,以及拟合在验证样本上的模型上的值
-
-
idx=which(!is.na(M[,j]))
-
plot(M[idx,j],M2[idx,j])
-
abline
-
segments
例如,对于截距,我们有以下
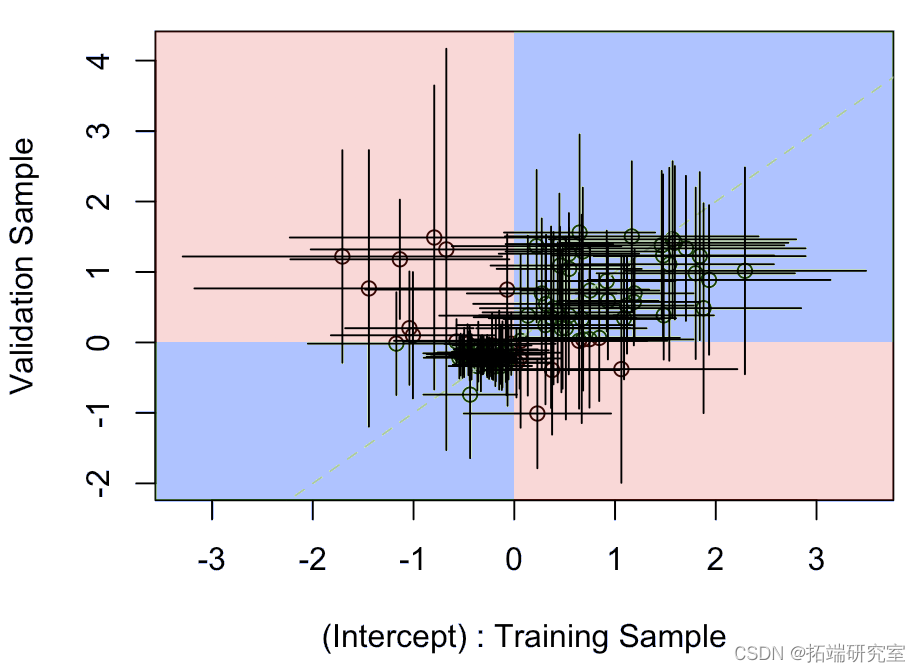
其中水平段是模型上拟合在训练样本上的参数的置信区间,垂直段是验证样本上的置信区间。蓝色部分表示某种一致性,而红色部分表示实际上,一个模型的系数为负,另一个模型为正。
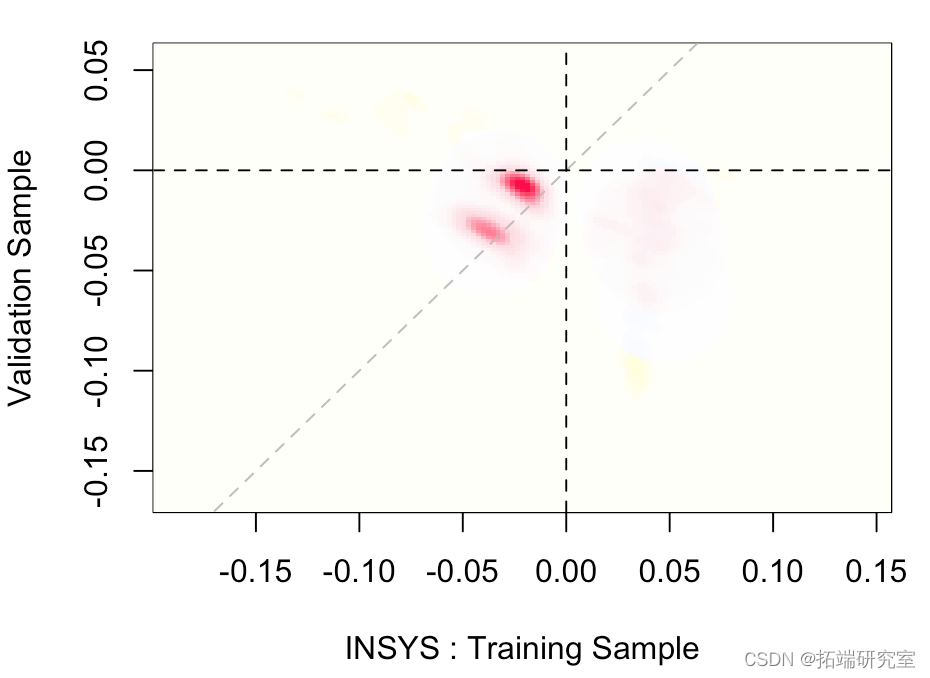
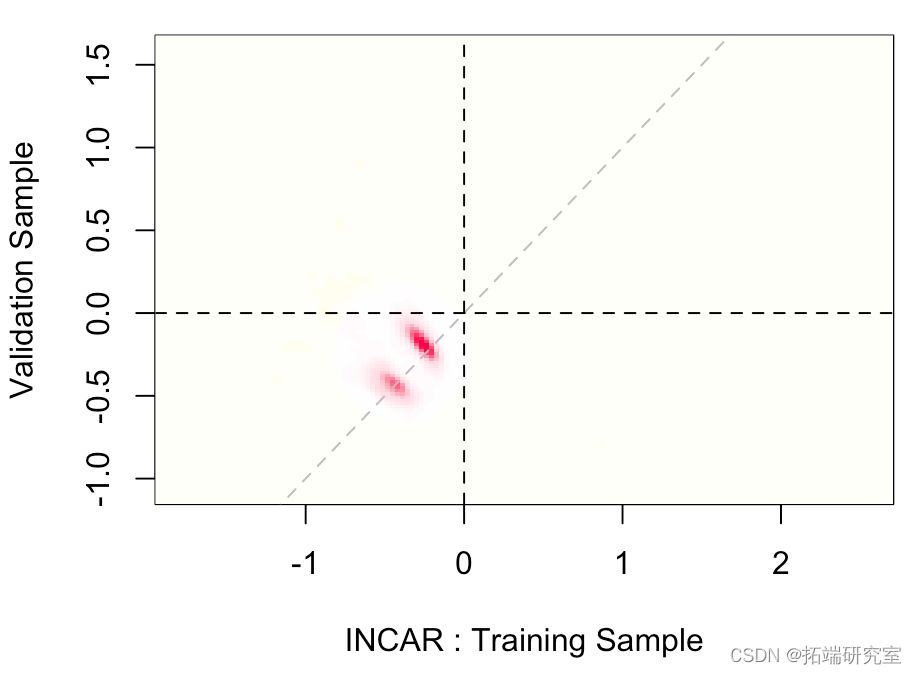
我们还可以可视化两个估计量的联合分布,
-
for(j in 1:8){
-
-
fa = kde(x=Z, H=H)
-
image(fat$eots[[1]],
在这里,几乎在对角线上,
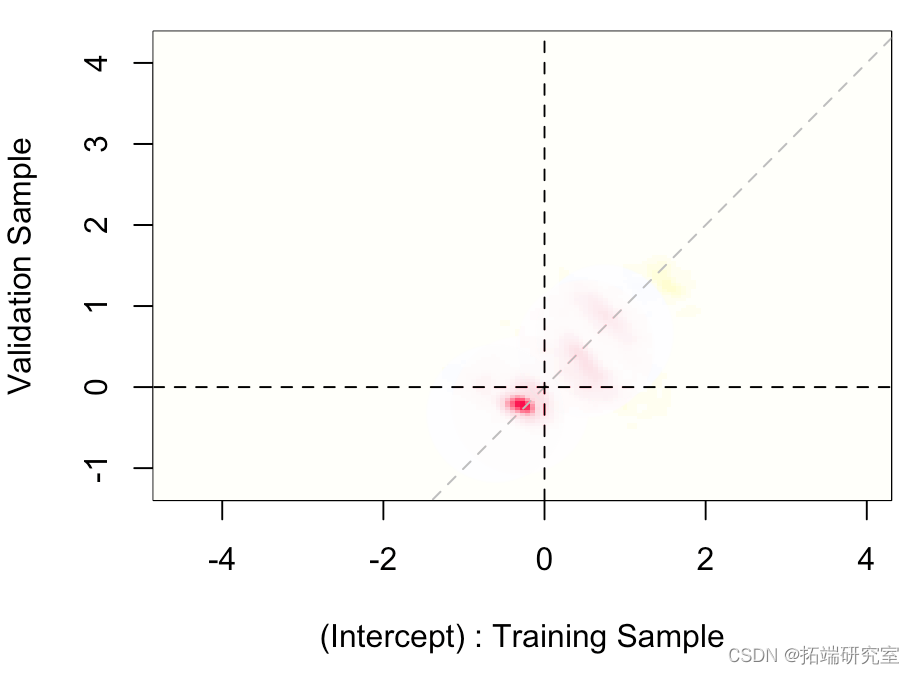
这意味着两个样本的截距(或多或少)相同。然后我们可以查看其他参数。
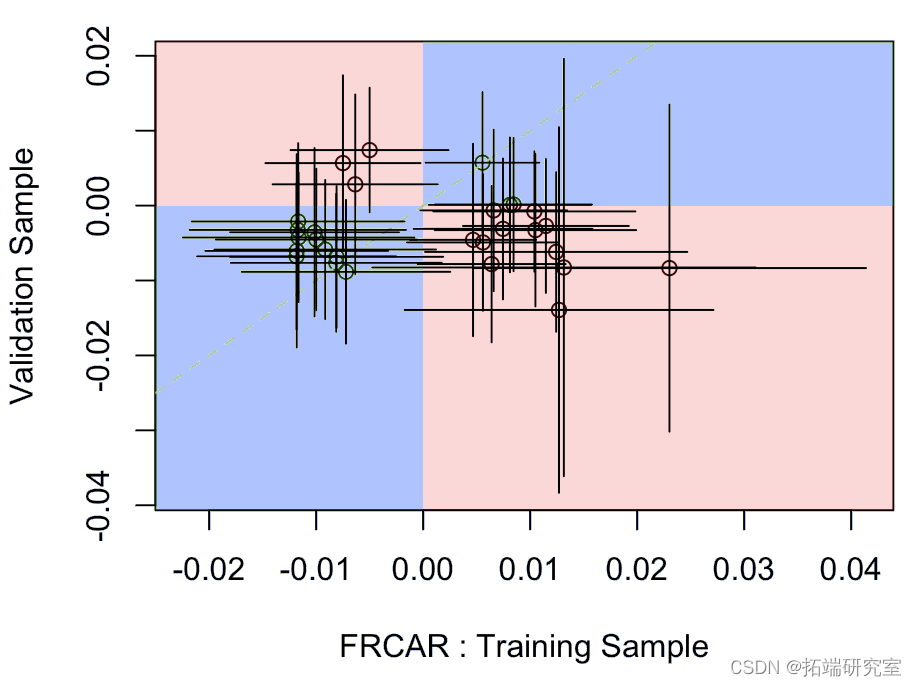
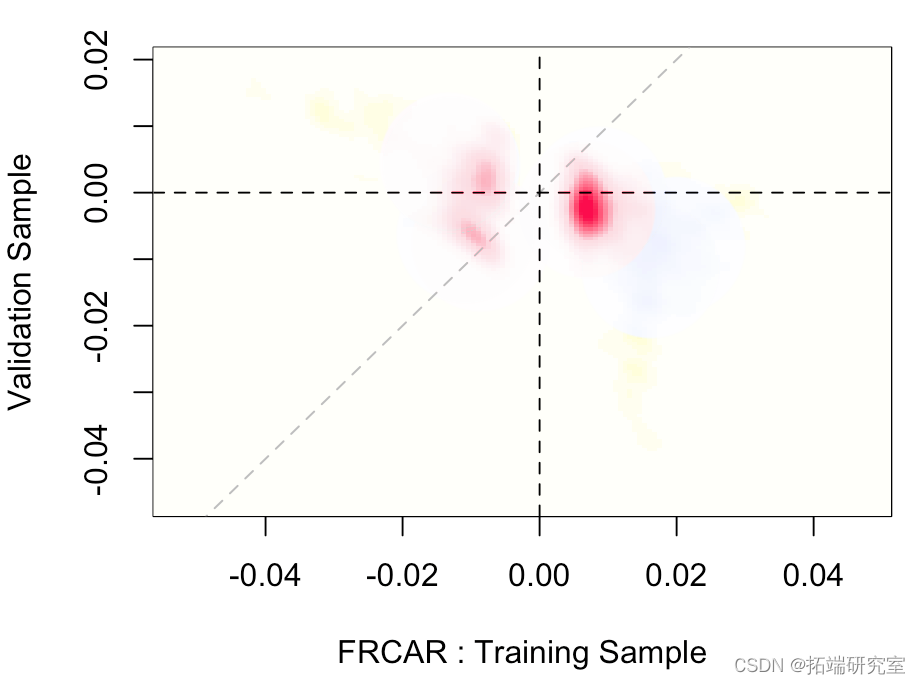
在该变量上,它似乎在训练数据集上很显著(不知何故,这与它在逐步过程之后保留在模型中的事实一致)但在验证样本上不显著(或几乎不显著)。
其他的则更加一致(有一些可能的异常值)
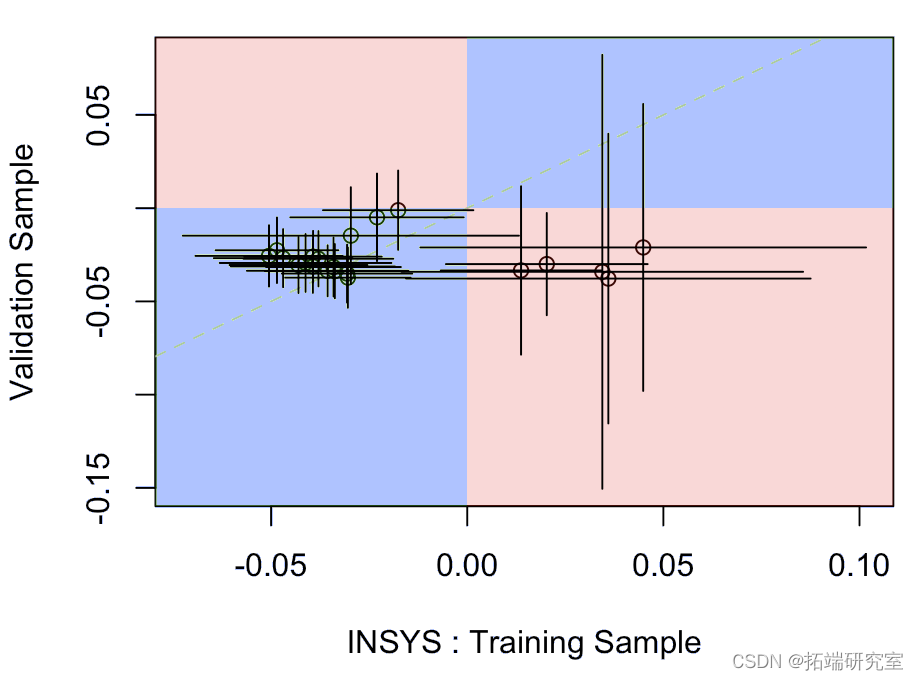
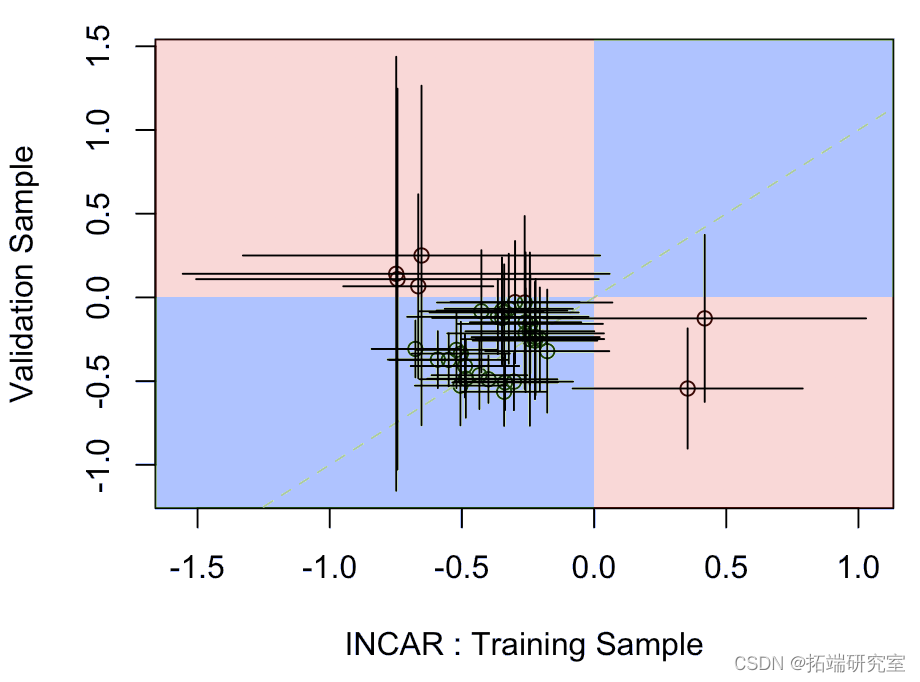
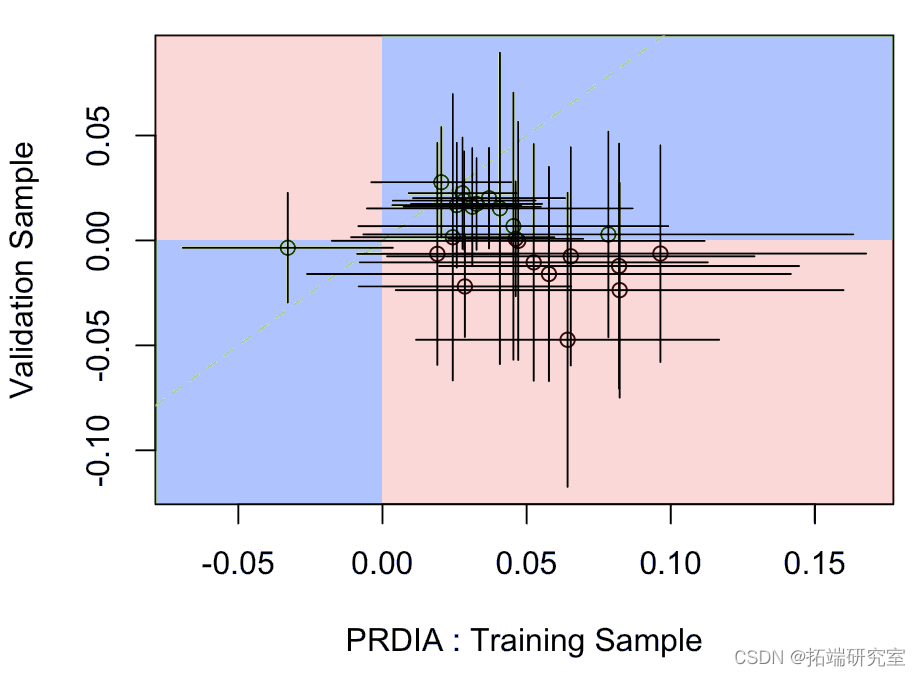
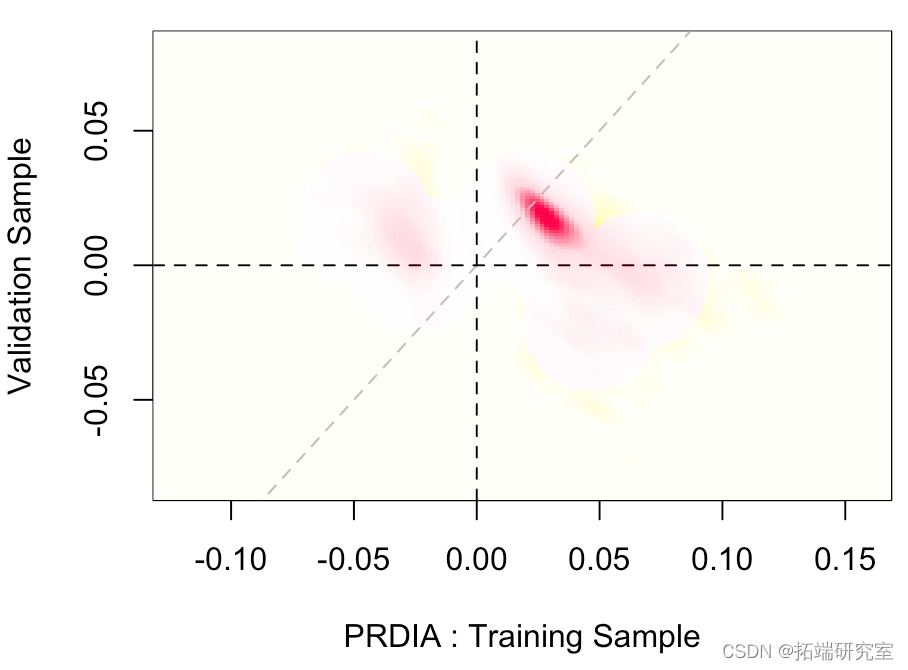
在下一个问题上,我们在训练样本上又有显著性,但在验证样本上没有。
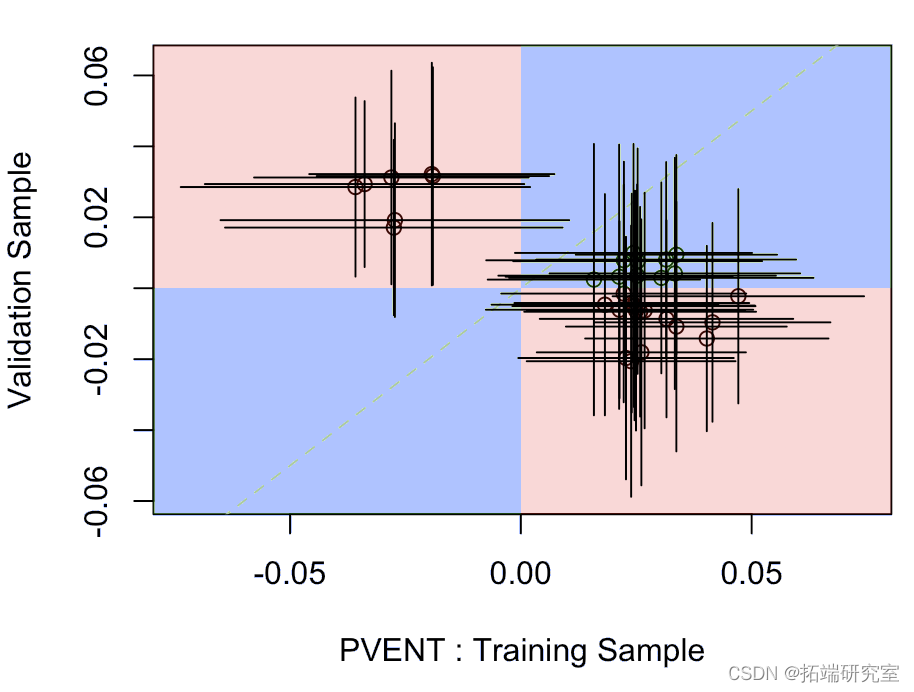
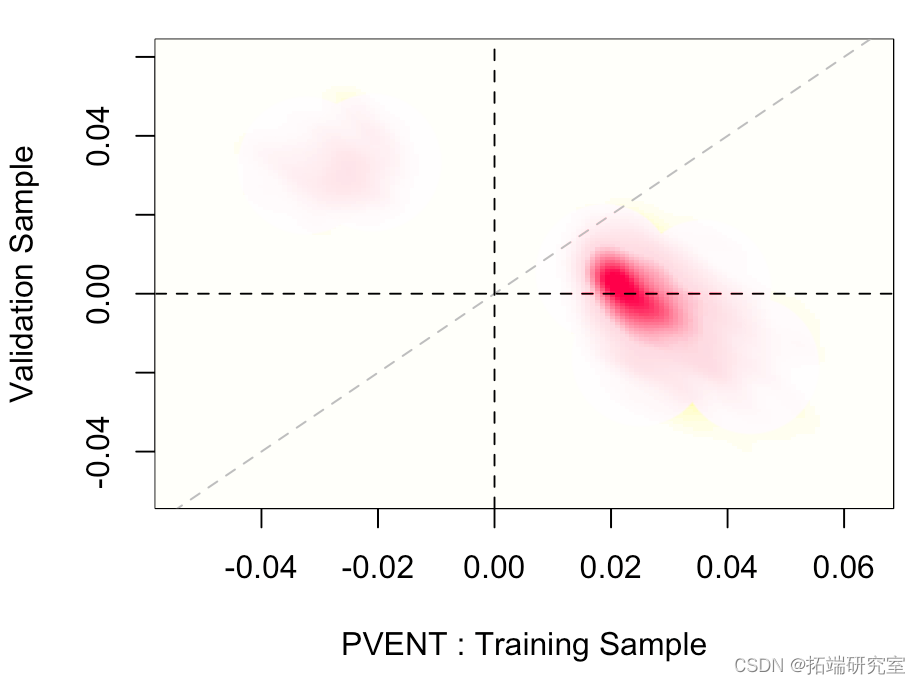
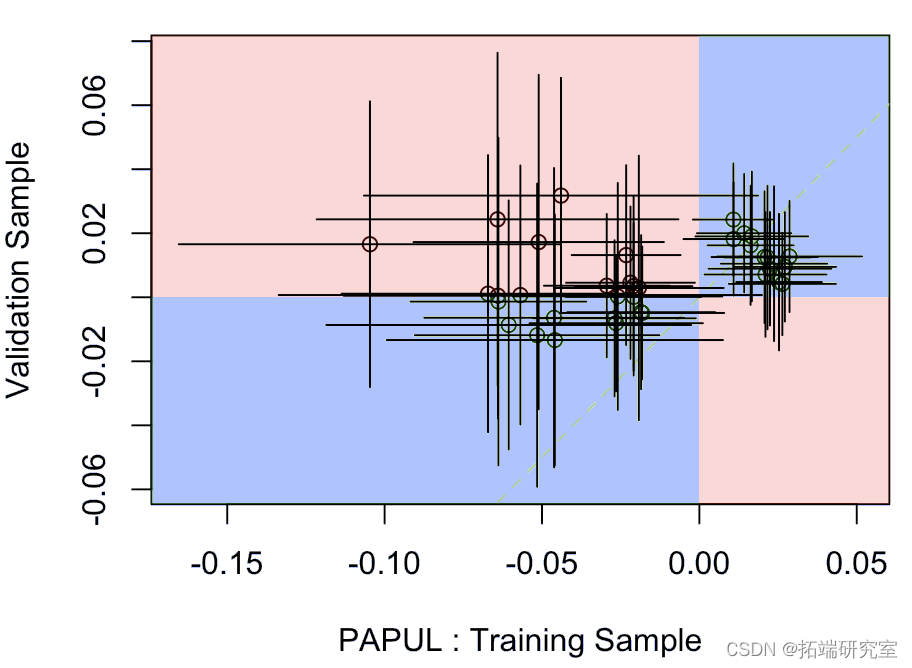
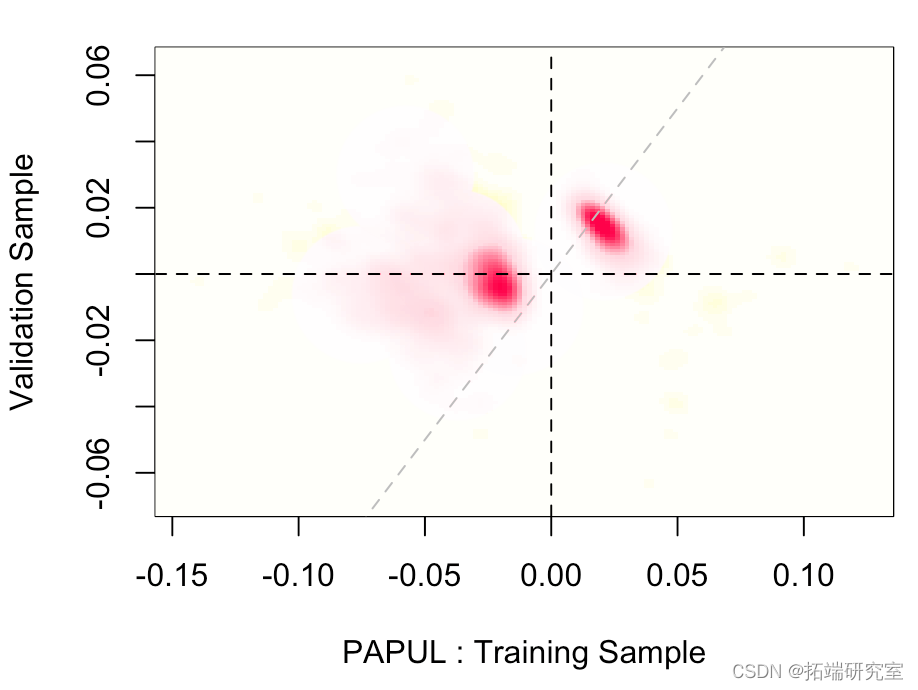
可能更有趣:
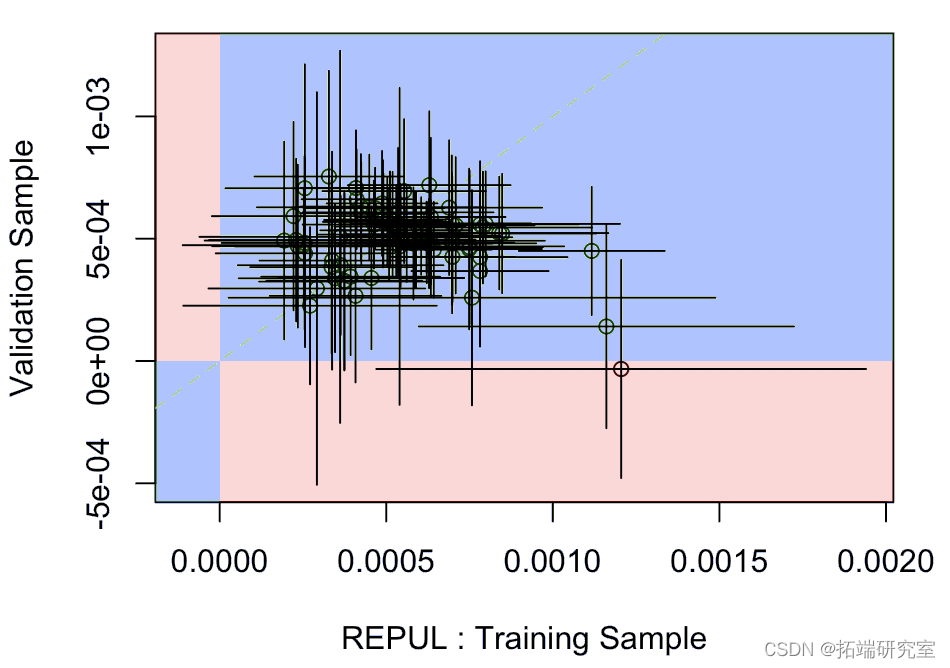
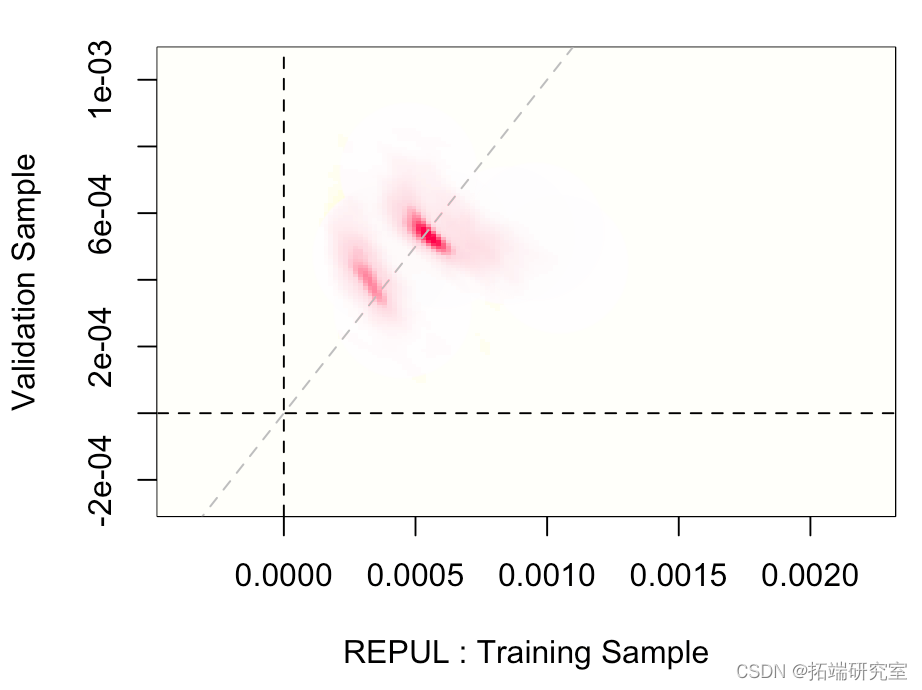
两者非常一致。

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
▍关注我们
【大数据部落】第三方数据服务提供商,提供全面的统计分析与数据挖掘咨询服务,为客户定制个性化的数据解决方案与行业报告等。
▍咨询链接:http://y0.cn/teradat
▍联系邮箱:3025393450@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号