爬取知音漫客的漫画热度排行榜
选题背景:
漫画作为绘画作品经历了一个发展过程,从最初作为少数人的兴趣爱好,已成为人们的普遍读物,更是深受学生喜爱,有不少人成为了漫画控。漫画,是一种艺术形式,是用简单而夸张的手法来描绘生活或时事的图画。一般运用变形、比喻、象征、暗示、影射的方法。构成幽默诙谐的画面或画面组,以取得讽刺或歌颂的效果。为了分析各类漫画的热门程度,分析当代年轻人对那类漫画更感兴趣。
主题式网络爬虫名称:
爬取知音漫客的漫画热度排行榜
主题式网络爬虫爬取内容与数据特征分析:
知音漫客漫画热度排行榜的漫画名称、热度值,对所得的数据进行分析。
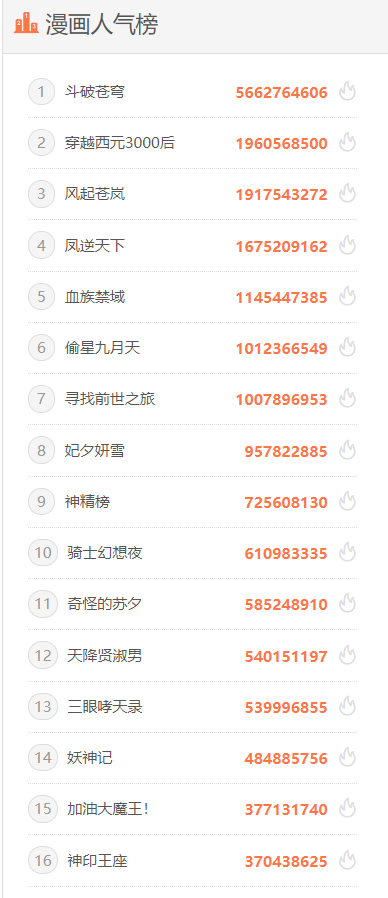
主题式网络爬虫设计方案概述:
访问网页,得到网页源代码;分析网页源代码;找到所需内容的标签;提取内容,保存信息,制成csv文件;读取csv文件,进行数据清洗,数据可视化处理,绘制成折线图、直方图、散点图、饼图、回归图、密度图、小提琴图。
技术难点:进行数据可视化时,数据处理容易出现偏差,图形标签出现重叠;热度数值太大,轴的数值不够的情况。
1 url="https://www.zymk.cn/top/comic_click.html" #填入要请求的服务器地址URL 2 header={ 3 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 4 'Referer': 'http://top.baidu.com/'} 5 #用requests抓取网页信息 6 def getHTMLText(url,timeout=30): 7 try: 8 r=requests.get(url,timeout=30,headers=header) #用requests抓取网页信息 9 r.raise_for_status() #异常捕捉 10 r.encoding=r.apparent_encoding #简化代码 11 return r.text #返回源代码 12 except: 13 return '产生异常' 14 #html.parser表示用BeautifulSoup库解析网页 15 html=getHTMLText(url) 16 soup=BeautifulSoup(html,'html.parser') 17 div=soup.find("div",attrs={"class":"col-8"}) #遍历标签为div的内容 18 li=div.find_all("li") #遍历标签为li的内容 19 n=[] 20 b=[] 21 for i in li: 22 span=i.find("strong") #获取漫画热度 23 s=i.find("a") #获取漫画名称 24 n.append(int(span.string)) 25 b.append(s.string) 26 print('{:^50}'.format('2021年最受欢迎漫画'))
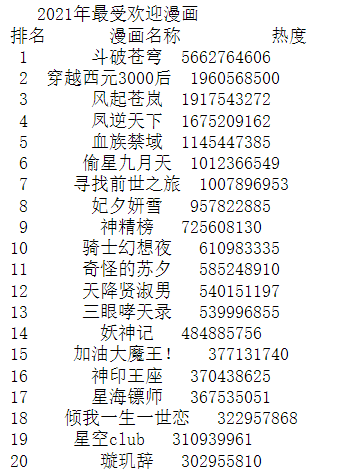
1 #将爬取信息制作成.csv 2 df=pd.DataFrame({'排名':o,'漫画名称':b,'热度':n}) 3 filename="aaa.csv" 4 df.to_csv(filename,encoding="utf_8") 5 ex=pd.DataFrame(pd.read_csv('aaa.csv')) #读取.csv 6 print(ex)

1 #检查是否有重复值 2 print(ex.duplicated()) 3 4 #检查是否有空值 5 print(ex["热度"].isnull().value_counts())

1 #回归系数 2 from sklearn.linear_model import LinearRegression 3 X = ex.drop("漫画名称",axis=1) 4 predict_model = LinearRegression() 5 predict_model.fit(X,ex['热度']) #训练模型 6 print("回归系数为:",predict_model.coef_) #判断相关性
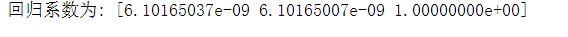
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 plt.figure() #创建figure对象 5 dff=pd.DataFrame([b,n],index=['漫画名称','热度'],columns=o) 6 ddff=pd.Series(n,b) 7 8 #绘制折线图 9 ddff.plot(figsize=(15,10),marker='o',linewidth=3) #宽为15,高为10,线条宽度为3,数据标记为圆圈 10 plt.suptitle('2021年最受欢迎漫画',fontsize=20) 11 plt.xticks(fontsize=20) #x轴字体大小为20 12 plt.yticks(fontsize=20) #y轴字体大小为20 13 plt.xlabel('漫画名称',fontsize=20) #设置y轴标注,并调整字体大小为20 14 plt.ylabel('热度',fontsize=20) #设置y轴标注,并调整字体大小为20 15 plt.show()
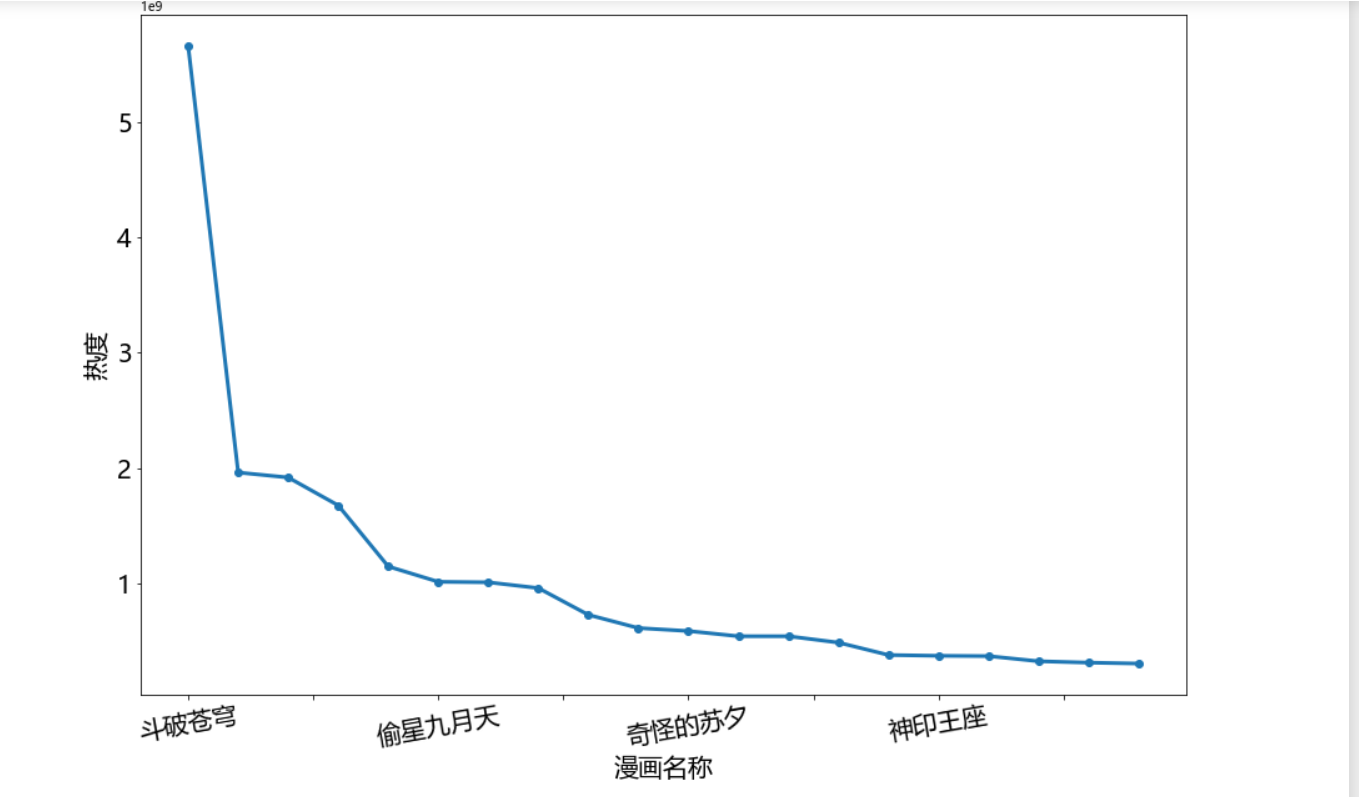
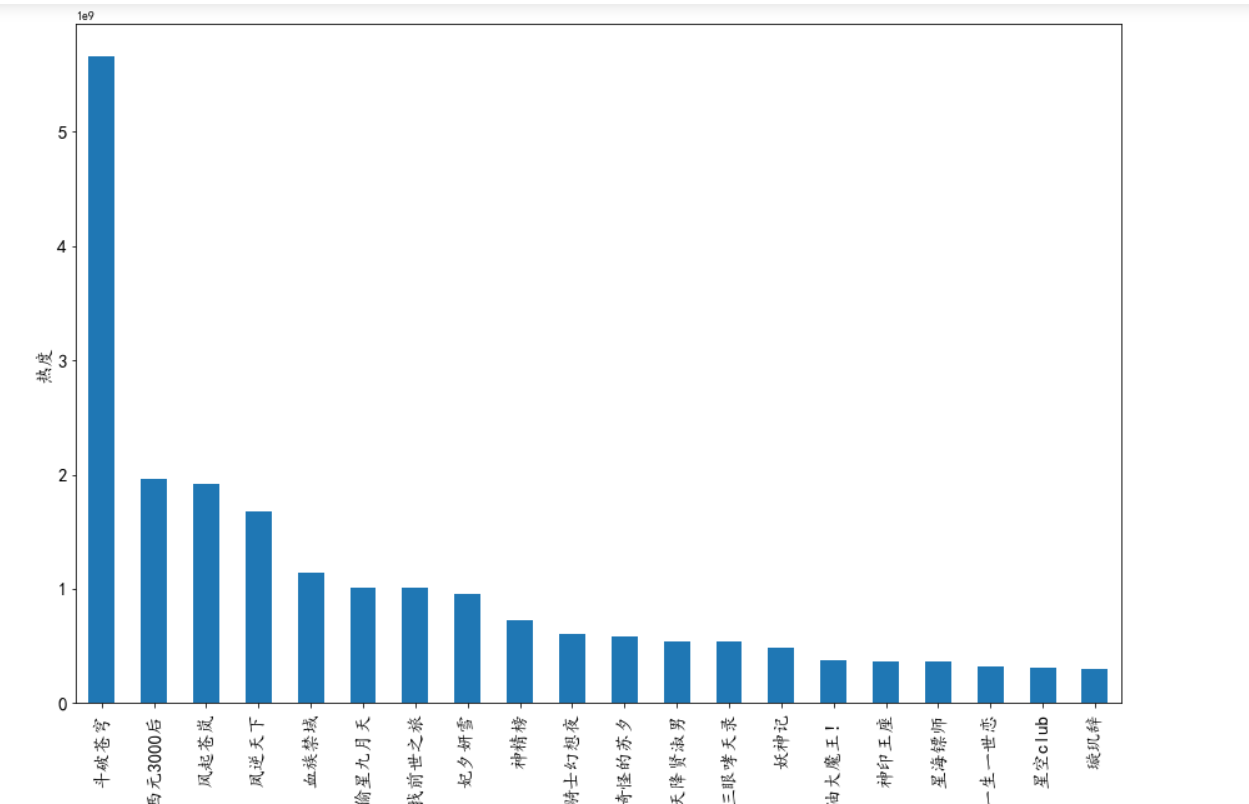
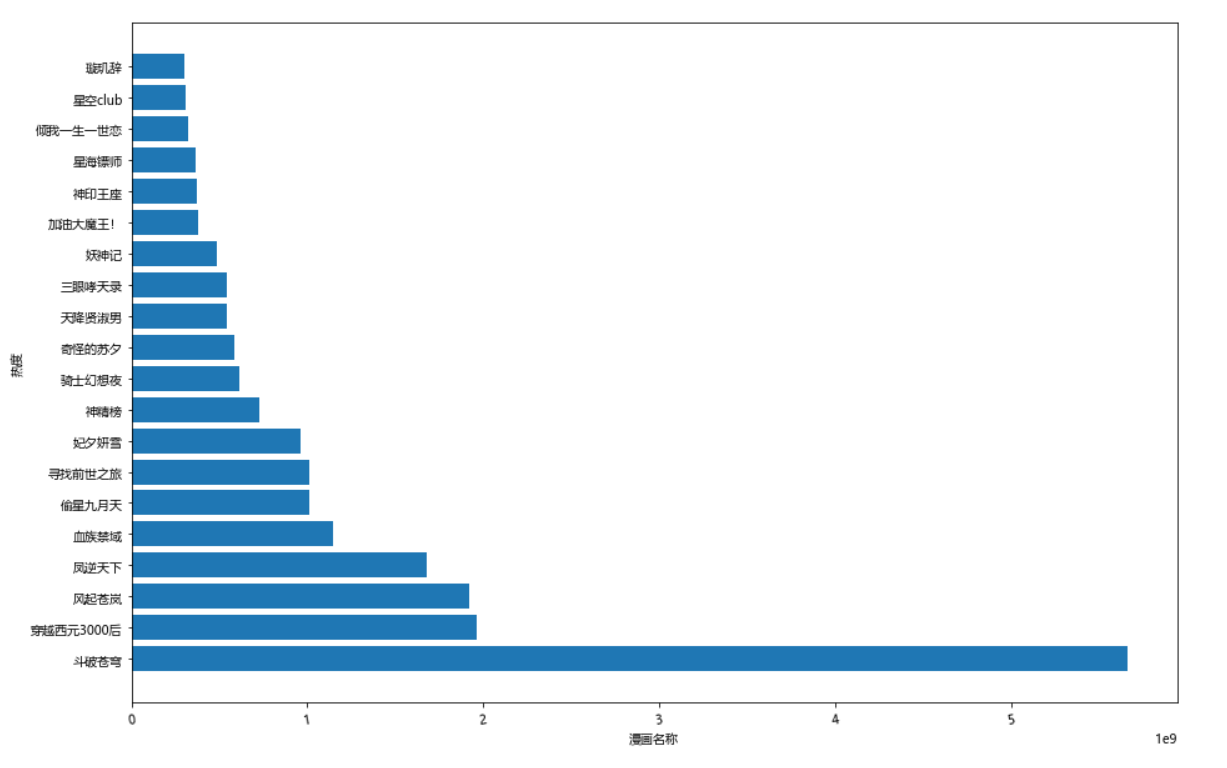
1 #绘制垂直柱状图 2 ddff.plot(kind='bar',figsize=(15,10)) 3 plt.suptitle('2021年最受欢迎漫画',fontsize=15) 4 plt.xlabel('漫画名称',fontsize=15) #设置x轴标注,并调整字体大小为15 5 plt.ylabel('热度',fontsize=15) #设置y轴标注,并调整字体大小为15 6 plt.show() 7 8 #绘制水平柱状图 9 plt.figure(figsize=(15,10)) #创建figure对象,宽为15,高为10 10 plt.barh(b,n,label='2021年最受欢迎漫画') 11 plt.xticks(fontsize=10) #x轴字体大小为10 12 plt.yticks(fontsize=10) #y轴字体大小为10 13 plt.xlabel("漫画名称") #设置x轴标注 14 plt.ylabel("热度") #设置y轴标注 15 plt.show()
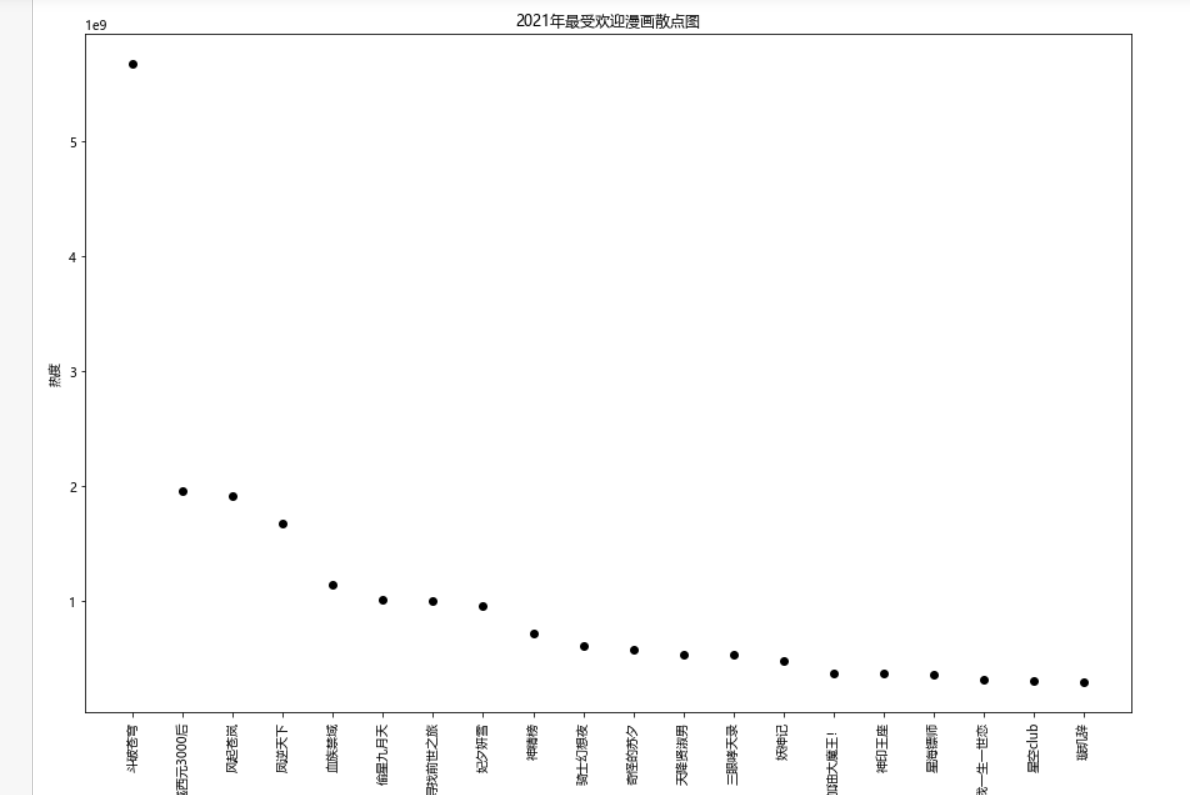
1 # 绘制散点图 2 plt.figure(figsize=(15,10)) #创建figure对象,宽为15,高为10 3 plt.scatter(b,n,color='k',s=25,marker="o",linewidth=2) #线条宽度为2,颜色为黑色,数据标记为圆圈 4 plt.xticks(fontsize=10,rotation=90) #x轴字体大小为10,字体角度为90度 5 plt.yticks(fontsize=10) #y轴字体大小为10 6 plt.xlabel("热度") 7 plt.ylabel("漫画名称") 8 plt.title("2021年最受欢迎漫画散点图") #设置散点图标签 9 plt.show()
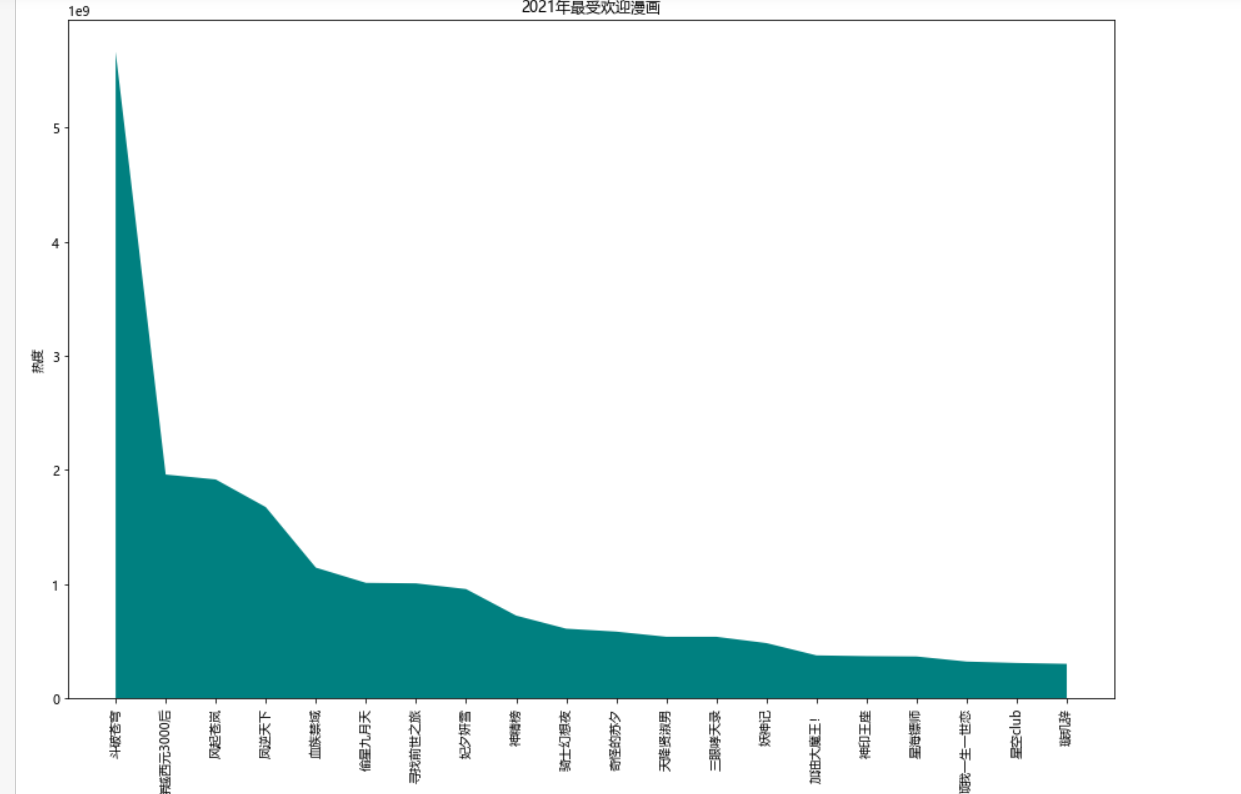
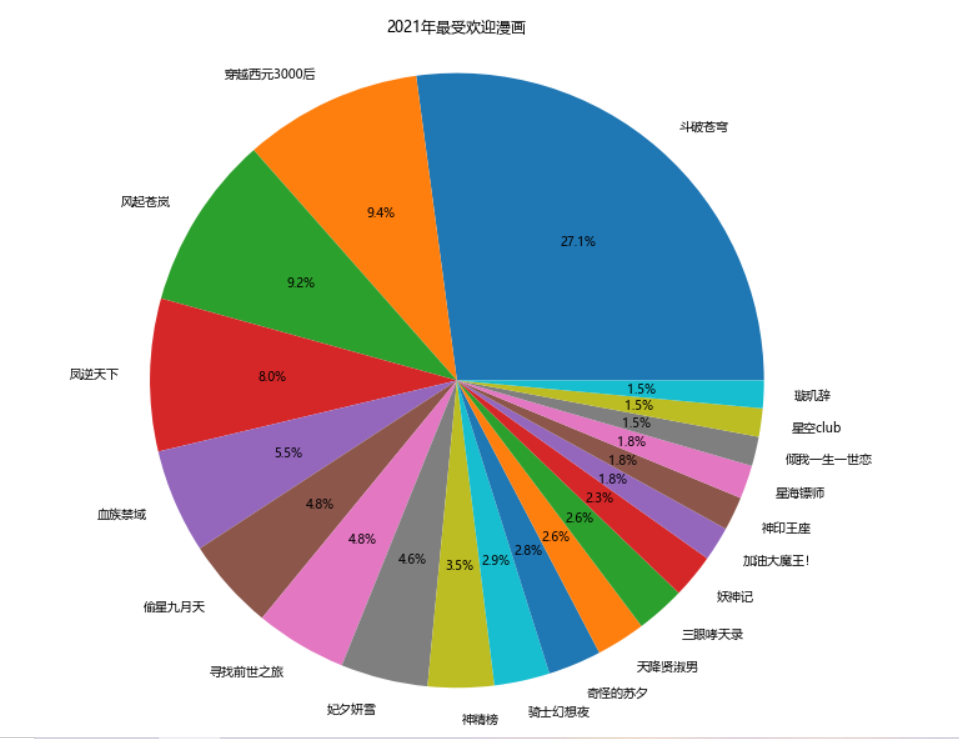
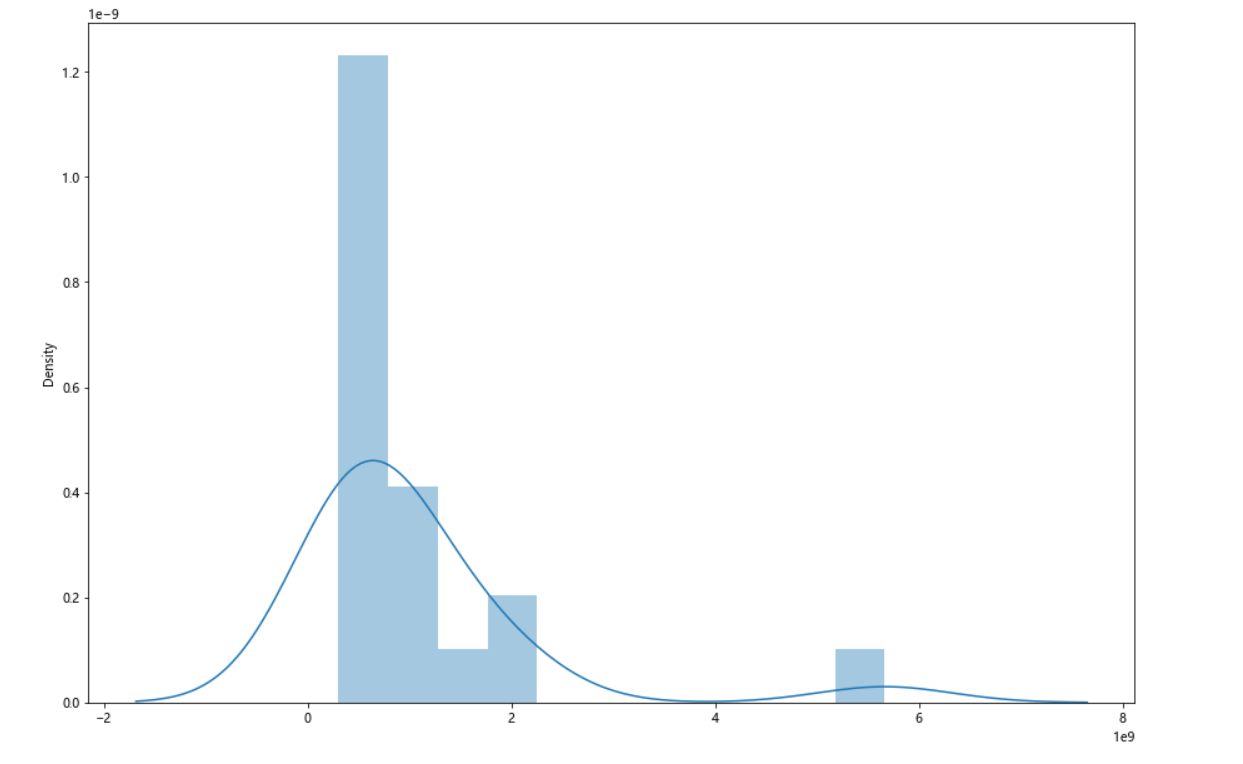
1 #绘制堆叠图 2 plt.figure(figsize=(15,10)) 3 plt.stackplot(b,n,colors=['teal']) 4 plt.xticks(fontsize=10,rotation=90) #x轴字体大小为10,字体角度为90度 5 plt.yticks(fontsize=10) #y轴字体大小为10 6 plt.xlabel("漫画名称") 7 plt.ylabel("热度") 8 plt.title("2021年最受欢迎漫画") 9 plt.show() 10 11 #绘制饼图 12 plt.figure(figsize=(15,10)) 13 plt.pie(n,labels=b,autopct='%1.1f%%') 14 #设置显示图像为圆形 15 plt.axis('equal') 16 plt.title('2021年最受欢迎漫画') 17 plt.show() 18 19 #查看热度分布 20 import seaborn as sns 21 plt.figure(figsize=(15,10)) 22 sns.distplot(n) 23 plt.show() 24 25 #绘制回归图 26 plt.figure(figsize=(15,10)) 27 sns.regplot(x=o,y=n) 28 plt.show() 29 fig,axes=plt.subplots(2,2) #绘画效果 30 sns.regplot(x=o,y=n,data=ex,ax=axes[0][0]) 31 sns.regplot(x=o,y=n,data=ex,ci=None,ax=axes[0][1]) #ci参数控制显示置信区间 32 sns.regplot(x=o,y=n,data=ex,color='g',marker='*',ax=axes[1][0]) #mark参数设置数据点格式,颜色为绿色 33 sns.regplot(x=o,y=n,data=ex,color='r',marker='+',fit_reg=False,ax=axes[1][1]) #fit_reg参数控制显示拟合的直线 34 plt.show() 35 36 #绘制单变量核密度图 37 plt.figure(figsize=(15,10)) 38 sns.kdeplot(n) 39 plt.show() 40 41 #绘制双变量核密度图 42 plt.figure(figsize=(15,10)) 43 sns.kdeplot(o,n) 44 plt.show() 45 46 #绘制小提琴图 47 plt.figure(figsize=(15,10)) 48 sns.violinplot(n) 49 plt.show()
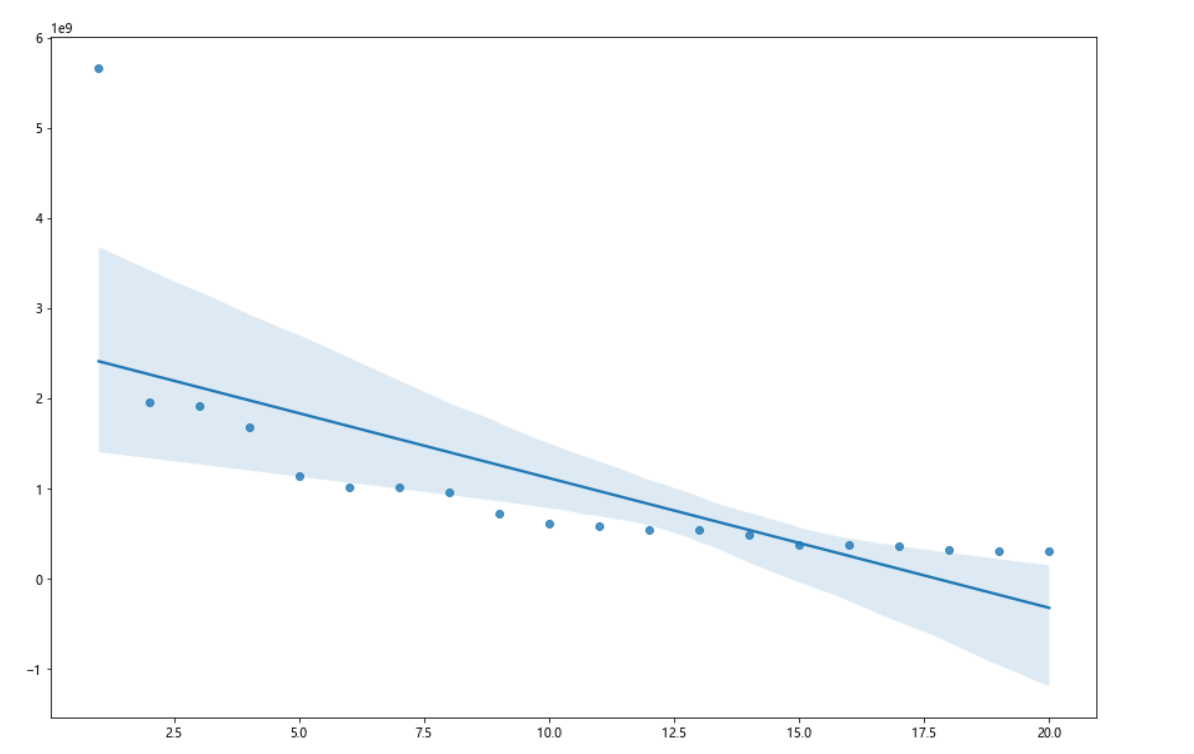
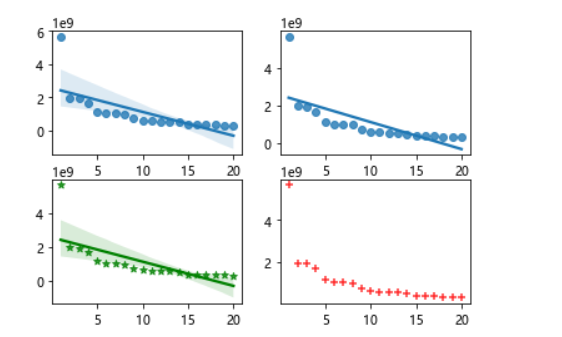
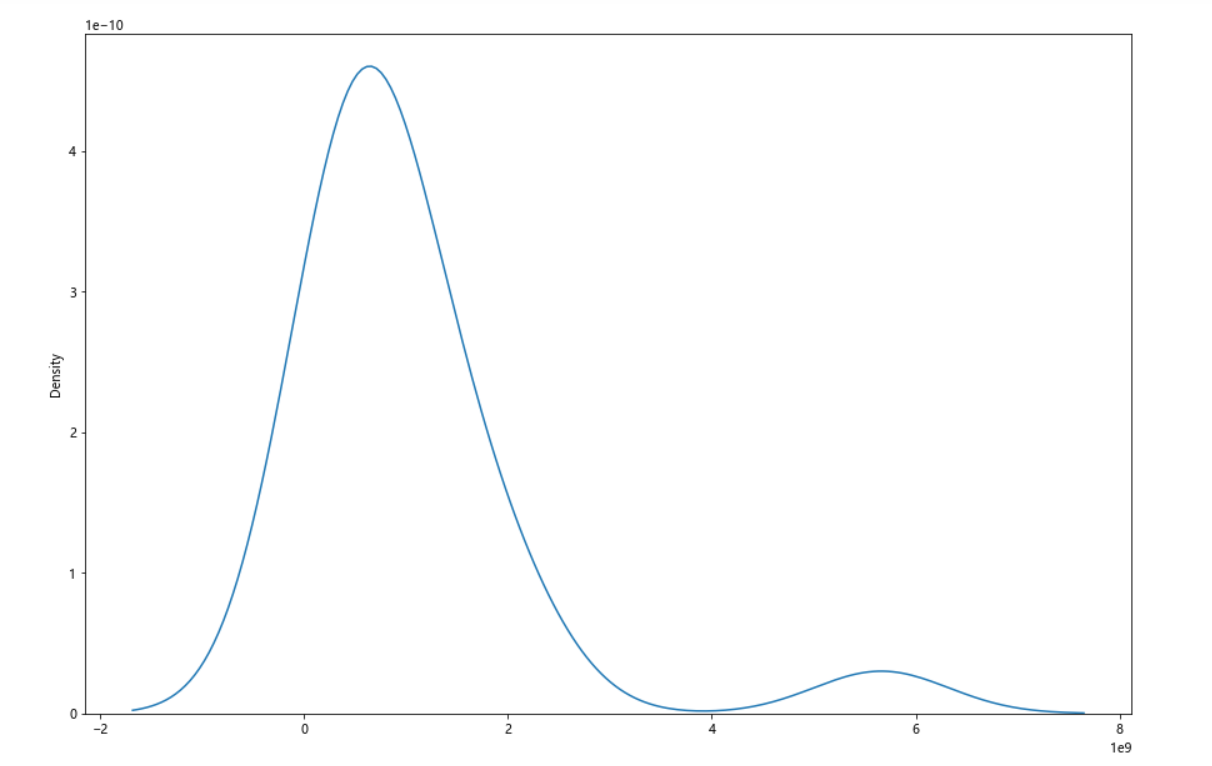

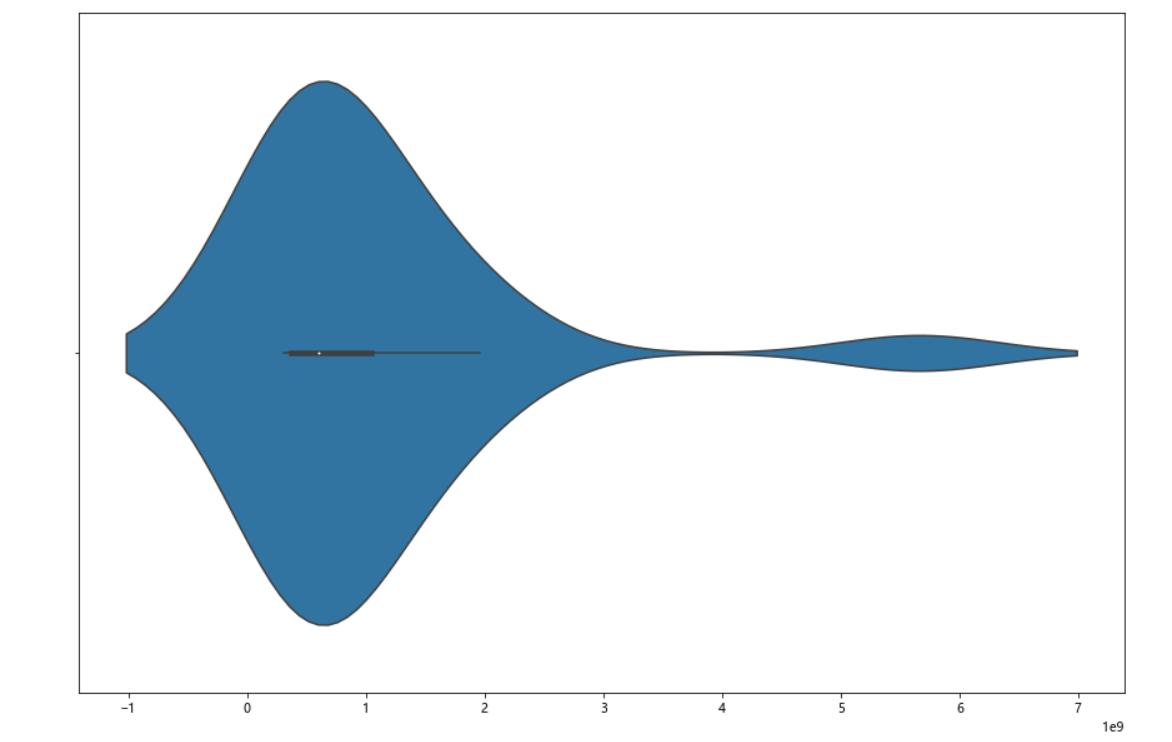
1 #完整代码 2 import requests 3 from bs4 import BeautifulSoup 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 o=[] #排名名次 8 for c in range(1,21): 9 o.append(c) #用for循环 10 11 url="https://www.zymk.cn/top/comic_click.html" #填入要请求的服务器地址URL 12 header={ 13 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 14 'Referer': 'http://top.baidu.com/'} 15 #用requests抓取网页信息 16 def getHTMLText(url,timeout=30): 17 try: 18 r=requests.get(url,timeout=30,headers=header) #用requests抓取网页信息 19 r.raise_for_status() #异常捕捉 20 r.encoding=r.apparent_encoding #简化代码 21 return r.text #返回源代码 22 except: 23 return '产生异常' 24 #html.parser表示用BeautifulSoup库解析网页 25 html=getHTMLText(url) 26 soup=BeautifulSoup(html,'html.parser') 27 div=soup.find("div",attrs={"class":"col-8"}) #遍历标签为div的内容 28 li=div.find_all("li") #遍历标签为li的内容 29 n=[] 30 b=[] 31 for i in li: 32 span=i.find("strong") #获取漫画热度 33 s=i.find("a") #获取漫画名称 34 n.append(int(span.string)) 35 b.append(s.string) 36 print('{:^50}'.format('2021年最受欢迎漫画')) 37 38 #将爬取信息制作成.csv 39 df=pd.DataFrame({'排名':o,'漫画名称':b,'热度':n}) 40 filename="aaa.csv" 41 df.to_csv(filename,encoding="utf_8") 42 ex=pd.DataFrame(pd.read_csv('aaa.csv')) #读取.csv 43 print(ex) 44 45 #回归系数 46 from sklearn.linear_model import LinearRegression 47 X = ex.drop("漫画名称",axis=1) 48 predict_model = LinearRegression() 49 predict_model.fit(X,ex['热度']) #训练模型 50 print("回归系数为:",predict_model.coef_) #判断相关性 51 52 #检查是否有重复值 53 print(ex.duplicated()) 54 55 #检查是否有空值 56 print(ex["热度"].isnull().value_counts()) 57 58 59 import pandas as pd 60 import numpy as np 61 import matplotlib.pyplot as plt 62 plt.figure() #创建figure对象 63 dff=pd.DataFrame([b,n],index=['漫画名称','热度'],columns=o) 64 ddff=pd.Series(n,b) 65 66 #绘制折线图 67 ddff.plot(figsize=(15,10),marker='o',linewidth=3) #宽为15,高为10,线条宽度为3,数据标记为圆圈 68 plt.suptitle('2021年最受欢迎漫画',fontsize=20) 69 plt.xticks(fontsize=20) #x轴字体大小为20 70 plt.yticks(fontsize=20) #y轴字体大小为20 71 plt.xlabel('漫画名称',fontsize=20) #设置y轴标注,并调整字体大小为20 72 plt.ylabel('热度',fontsize=20) #设置y轴标注,并调整字体大小为20 73 plt.show() 74 75 #绘制垂直柱状图 76 ddff.plot(kind='bar',figsize=(15,10)) 77 plt.suptitle('2021年最受欢迎漫画',fontsize=15) 78 plt.xlabel('漫画名称',fontsize=15) #设置x轴标注,并调整字体大小为15 79 plt.ylabel('热度',fontsize=15) #设置y轴标注,并调整字体大小为15 80 plt.show() 81 82 #绘制水平柱状图 83 plt.figure(figsize=(15,10)) #创建figure对象,宽为15,高为10 84 plt.barh(b,n,label='2021年最受欢迎漫画') 85 plt.xticks(fontsize=10) #x轴字体大小为10 86 plt.yticks(fontsize=10) #y轴字体大小为10 87 plt.xlabel("漫画名称") #设置x轴标注 88 plt.ylabel("热度") #设置y轴标注 89 plt.show() 90 91 # 绘制散点图 92 plt.figure(figsize=(15,10)) #创建figure对象,宽为15,高为10 93 plt.scatter(b,n,color='k',s=25,marker="o",linewidth=2) #线条宽度为2,颜色为黑色,数据标记为圆圈 94 plt.xticks(fontsize=10,rotation=90) #x轴字体大小为10,字体角度为90度 95 plt.yticks(fontsize=10) #y轴字体大小为10 96 plt.xlabel("漫画名称") 97 plt.ylabel("热度") 98 plt.title("2021年最受欢迎漫画散点图") #设置散点图标签 99 plt.show() 100 101 #绘制堆叠图 102 plt.figure(figsize=(15,10)) 103 plt.stackplot(b,n,colors=['teal']) 104 plt.xticks(fontsize=10,rotation=90) #x轴字体大小为10,字体角度为90度 105 plt.yticks(fontsize=10) #y轴字体大小为10 106 plt.xlabel("漫画名称") 107 plt.ylabel("热度") 108 plt.title("2021年最受欢迎漫画") 109 plt.show() 110 111 #绘制饼图 112 plt.figure(figsize=(15,10)) 113 plt.pie(n,labels=b,autopct='%1.1f%%') 114 #设置显示图像为圆形 115 plt.axis('equal') 116 plt.title('2021年最受欢迎漫画') 117 plt.show() 118 119 #查看热度分布 120 import seaborn as sns 121 plt.figure(figsize=(15,10)) 122 sns.distplot(n) 123 plt.show() 124 125 #绘制回归图 126 plt.figure(figsize=(15,10)) 127 sns.regplot(x=o,y=n) 128 plt.show() 129 fig,axes=plt.subplots(2,2) #绘画效果 130 sns.regplot(x=o,y=n,data=ex,ax=axes[0][0]) 131 sns.regplot(x=o,y=n,data=ex,ci=None,ax=axes[0][1]) #ci参数控制显示置信区间 132 sns.regplot(x=o,y=n,data=ex,color='g',marker='*',ax=axes[1][0]) #mark参数设置数据点格式,颜色为绿色 133 sns.regplot(x=o,y=n,data=ex,color='r',marker='+',fit_reg=False,ax=axes[1][1]) #fit_reg参数控制显示拟合的直线 134 plt.show() 135 136 #绘制单变量核密度图 137 plt.figure(figsize=(15,10)) 138 sns.kdeplot(n) 139 plt.show() 140 141 #绘制双变量核密度图 142 plt.figure(figsize=(15,10)) 143 sns.kdeplot(o,n) 144 plt.show() 145 146 #绘制小提琴图 147 plt.figure(figsize=(15,10)) 148 sns.violinplot(n) 149 plt.show()
总结
总结
1、通过网络爬虫爬取的信息中可以看出当代年轻人比较喜欢看斗破苍穹,比较喜欢看偏向于修仙类漫画,经过对数据的处理、分析和可视化,从回归系数、折线图、直方图、散点图、饼图、回归图、密度图、小提琴图也可以看出当代年轻人喜欢看偏向于修仙类漫画。
2、在完成此设计过程中,我学习到了如何去获取并分析网页源代码,如何去从源代码中爬取所需要的信息,再将信息进行数据处理、数据可视化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号